Poddałem ocenie kod naszego czytelnika. Miał problem z obozami kodu

Do sprawdzenia dostałem kod gry webowej, którego autorem jest użytkownik kmph. Bardzo dziękuję mu za podzielenie się swoim projektem. Jest on o tyle ciekawy, że na pierwszy rzut oka wygląda przyzwoicie, jednak zagłębiając się w szczegóły można dostrzec coraz więcej problemów z „czystością”. Dodatkowo ma problemy na poziomie architektury.
Repozytorium dostępne pod tym adresem. Ocenie poddaję gałąź dev, dlatego że zawiera aktualny kod.

Marek Zając. Pracę w zawodzie zaczął od wakacyjnego stażu w roku 2013 w firmie Comarch (co ciekawe korzystałem tam z języka Java). Samym programowaniem interesuje się od końca szkoły podstawowej/początku gimnazjum, kiedy to poznawałem podstawy języka C++. Aktualnie rozwija swoją wiedzę głównie pod kątem architektury, czystego kodu i technologii frontendowych.
Spis treści
Co by tu ocenić?
Jak napisałem na wstępie, projekt ten można analizować na dwóch płaszczyznach – pojedynczych plików i architektury. Z racji, że jest on rozbudowany, to w tym wpisie pokażę po jednym przykładzie wszystkiego.
Długo. Za długo
Pierwsza rzecz jaką można dosyć łatwo znaleźć to obecność kilku plików, które zawierają mnóstwo kodu. Zresztą od tych plików powstał tytuł tego artykułu. Są to swego rodzaju obozy kodu, w których kod aplikacji zgromadził się i w nim siedzi. Przykładowo plik z akcjami zawiera ponad 900 linii kodu.
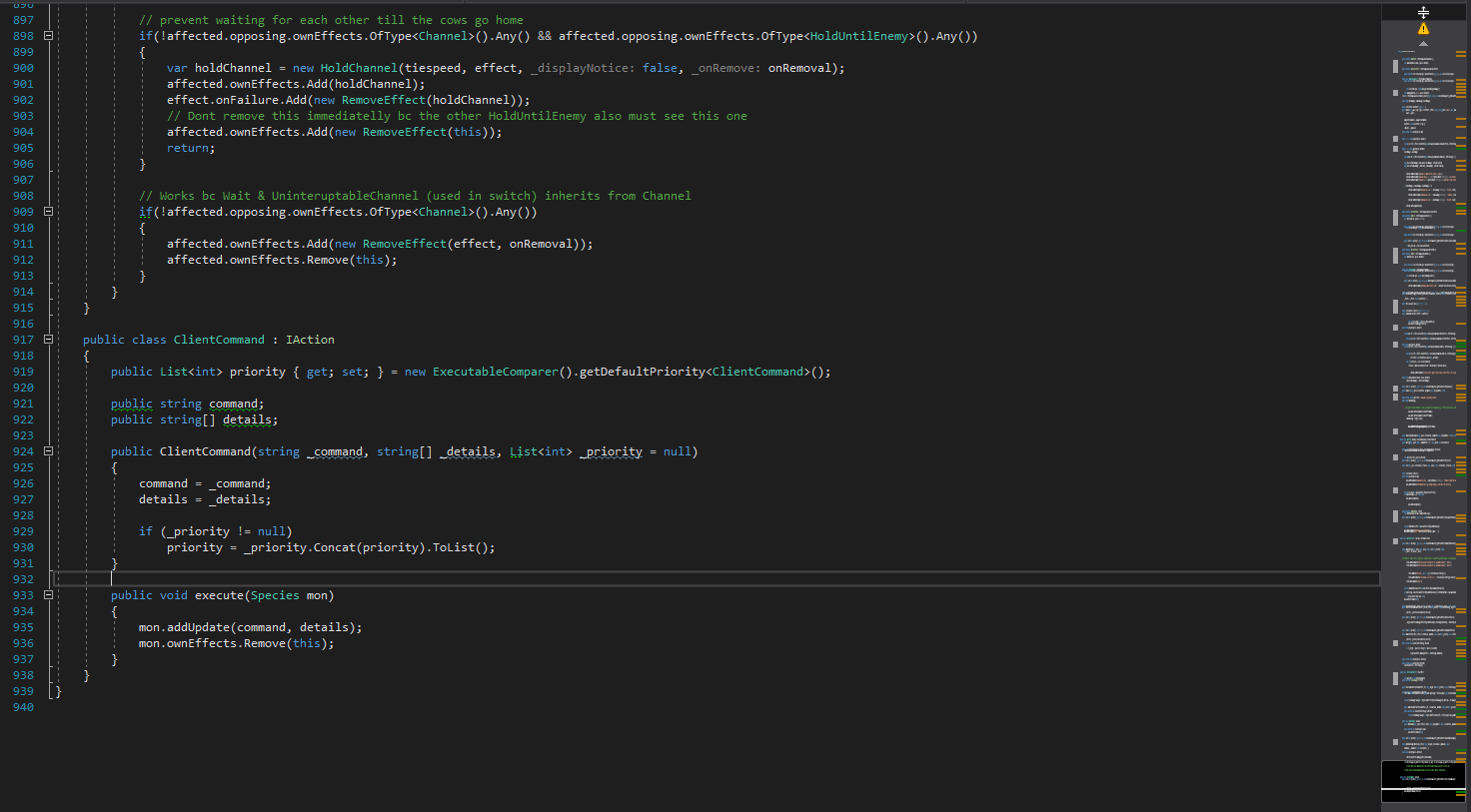
Obszerność plików nie jest największym problemem. Większy jest taki, że zawierają mnóstwo klas. Dlatego w tym miejscu mam sugestię do autora, aby nie bał się większej ilości plików. Wbrew pozorom ułatwiają one czytanie.
Najprostszy przykład. Chciałem sprawdzić, co zawiera klasa, której obiekt spotkałem. Odruchowo zacząłem szukać pliku z nazwą klasy — nie znalazłem takiego. Musiałem przebijać się przez jeden duży plik, w dodatku zgadując najpierw o jaki plik chodzi. Wiem, że w Visual Studio mam funkcję „Go to definition…„. Jednak patrząc bardziej ogólnie taka funkcja niekoniecznie musi być dostępna.
Dlatego tutaj porada jest taka, aby dać trochę przestrzeni tym wszystkim klasom. Nawet jeśli zajmują one kilkanaście linijek to niech dostaną swoje pliki. Pozwoli to lepiej uporządkować kod i ekstremalnie ułatwi przeglądanie go. W tym momencie ciężko stwierdzić, gdzie kończy się jedna klasa, a zaczyna druga. Jeżeli autor korzysta z Resharpera to jest tam funkcja „Refactor this -> Move to another file„. Dzięki temu można wydzielić klasy do osobnych plików za pomocą dwóch kliknięć.
Dodatkowy plus takiego podejścia to uniknięcie problemu z nazwami plików – będą się one nazywać tak jak klasy. W tym momencie plik OtherParticularEffects.cs nie mówi za wiele.

Przywrócić nawiasy
Jeżeli chodzi o kod to pierwszą rzeczą na jaką zwróciłem uwagę jest brak nawiasów przy niektórych instrukcjach warunkowych.
if (stored.Count == 0)
return addNewAttack();
else return stored.Last().ifSuccess[0] as Attack;
O ile sam C# jak najbardziej obsługuje takie konstrukcje, to jednak nie wpływają one pozytywnie na czytelność i utrzymywalność kodu. Przy pierwszym rzucie oka przeszło mi przez głowę, że ten if nie zawiera żadnego kodu, który wykona się w przypadku spełnienia warunku.
Jednak większy problem robi się, kiedy w takim kodzie będziemy cokolwiek zmieniać. Stosowanie zapisu bez nawiasów klamrowych jest chyba jedną z częstszych przyczyn spędzania godziny na debugowaniu, by sprawdzić dlaczego nowo dodany kod nie wykonuje się w ogóle albo wykonuje się zawsze, mimo że nie powinien.
Jeszcze większym potencjalnym źródłem problemów może być instrukcja else zapisana w tej samej linijce co kod, który się w jej ramach wykona. Jeszcze mocniej zaciemnia to kod i, mimo że C# pozwala na takie zabawy, to jednak unikałbym tego praktycznie zawsze. Kod przede wszystkim powinien być prosty do czytania dla programisty, bo maszyna sobie z nim zawsze poradzi.
Mam wrażenie, że autor obawia się zbyt długiego kodu. Jednak patrząc na punkt poprzedni widzę, że szuka oszczędności nie tam, gdzie trzeba. Jestem przekonany, że każdy programista C# zwróciłby uwagę na taki zapis i zapytał „dlaczego?”.
Jednak nawet pomijając kwestie czytelności to zastosowanie w kilku miejscach takiego zapisu łamie dobrą praktykę, aby kod w aplikacji był spójny. W tym momencie trzeba dobrze wczytać się, żeby znaleźć takie pozbawione nawiasów bloki kodu w przypadku, kiedy w innych miejscach nawiasy już spotykamy.
Podobne uwagi dotyczą np. niektórych instrukcji foreach.
Fabryka klas
Na koniec ciekawszy przypadek, który znajduje się w pliku ParticularSpecies.cs. Mamy tutaj klasy, które tak naprawdę reprezentują jedną klasę z różnymi parametrami. Fragment pliku wygląda w ten sposób:
public class Shamage : Species
{
public Shamage(List<Move> _availableMoves = null) : base(_availableMoves) { }
public override List<Type> types => new List<Type> { new Beast() };
public override long baseMaxHealth => 800;
public override long baseMaxStamina => 4000;
public override long baseMaxShield => 2000;
public override long baseSpeed => 30;
public override long basePower => 40;
public override List<Move> baseAvailableMoves => new List<Move>
{
new Switch(), new ScudAway(), new Disappear(),
new Jab(), new ForceBeam(), new Hurricane(), new BlowOut(), new Fireball(), /*new ToxicSpores(), new BurningSpores(),*/
new BackOff(), new CatchUp(), new TeleportAway(), new TeleportIn(),
new RollAround(), new Quench(), new CalmTheWinds(),
new Frenzy(),
new Dodge(), new Vanish(), new Block(),
new Wait()
};
}
public class Brchutamp : Species
{
public Brchutamp(List<Move> _availableMoves = null) : base(_availableMoves) { }
public override List<Type> types => new List<Type> { new Beast() };
public override long baseMaxHealth => 5000;
public override long baseMaxStamina => 4000;
public override long baseMaxShield => 4500;
public override long baseSpeed => 60;
public override long basePower => 80;
public override List<Move> baseAvailableMoves => new List<Move>
{
new Switch(),
new Jab(), new Hook(), new Cross(), new LowBlow(), new SupermanPunch(), new BodyAvalanche(), new PushKick(),
new CatchUp(), new ForwardRoll(), new BackOff(), new BackwardRoll(), new CautiousBackOff(),
new RollAround(), new Welter(),
new Frenzy(),
new Dodge(), new Block(), new Parry(),
new Wait()
};
}
Widzicie od razu, co się tutaj stało i jakie jest rozwiązanie problemu?
Jedyne co się tutaj zmienia to wartości przypisywane do pól. W pliku jest 16 takich klas. W przypadku gdyby trzeba było dodać kolejny typ, autor musiałby dodać koleją klasę, która miałaby tylko inne parametry.
Rozwiązaniem jest zastosowanie wzorca typu fabryka i dodanie jedynie enuma z dostępnymi typami (kombinując mocniej nawet jego można by się pewnie pozbyć). Do tego niech klasa Species posiada konstruktor przyjmujący wszystkie potrzebne wartości i już możemy te 340 linii zamienić na coś tego typu:
class Factory
{
public void Create(Type type)
{
switch(type)
{
case Type_1:
return new Species(3000,1111,3333,4444,6566,
listOfBaseMovesForType1, listOfAvaliableMovesForType1);
case Type_2:
return new Species(3000,1111,3333,4444,6566,
listOfBaseMovesForType2, listOfAvaliableMovesForType2);
case Type_3:
return new Species(6000,333,3333,4444,111,
listOfBaseMovesForType3, listOfAvaliableMovesForType3);
// ...
}
Taka zmiana daje również dodatkowy potencjalny profit – autor będzie mógł bardzo łatwo dodać tworzenie tych obiektów na podstawie wartości zapisanych poza kodem aplikacji, np. w bazie danych albo pliku. Taka zmiana będzie dużo prostsza, niż w pierwotnej wersji i będzie wymagała modyfikacji niewielkiego kawałka kodu.
W kodzie z tego pliku można wykonać jeszcze kilka ulepszeń. Jednak te zostawiam na kolejne części, o których dowiesz się śledząc bloga na bieżąco albo lajkując mój fanpage na Facebooku.
Podsumowanie
Bardzo dziękuję autorowi za zgłoszenie się ze swoim projektem. Mimo świadomości, że kod nie był idealny, to miał odwagę zgodzić się na publiczną ocenę. Zapraszam do dyskusji w komentarzach na temat omawianego kodu.
Artykuł został pierwotnie opublikowany na blogu autora: zajacmarek.com. Zdjęcie główne artykułu pochodzi z pexels.com.
Podobne artykuły

PIN-UP.TECH: innowacyjny zespół wyznacza trendy w branży iGaming i rośnie z każdym dniem

Sztuczna inteligencja w grach - o rozwoju i największych wyzwaniach. Wywiad z Rafałem Tylem

Oto dlaczego naprawdę musisz nauczyć się Unreal Engine 5 w 2023 roku. Wywiad z Volodymyrem Ivanovem

Wgląd w animację gier wideo i rolę kombinezonu Xsens. Wywiad z Mykołą Kozak

Jak deweloperzy z Room 8 Studio pomogli stworzyć Metal: Hellsinger, jedną z najbardziej niezwykłych gier wydanych w 2022 roku

Dlaczego wszyscy przesiadają się na Unreal Engine 5 i Ty też powinieneś

Jak wygląda codzienność w studiu, które pracowało nad Call of Duty? Wywiad z Oleną Kycha
