Jak zbudować własną Infurę na AWS używając frameworku serverless
W jednym z naszych firmowych artykułów, pokazaliśmy jak uruchomić pojedynczy node Parity na AWS. Dla większości zastosowań posiadanie jednego własnego node’a Parity to z pewnością lepszy pomysł, niż poleganie na niezawodności zewnętrznej publicznej infrastruktury, np. Infury. Dziś pokażemy, jak zbudować własną Infurę na AWS.

Marek Kowalski. Współzałożyciel i CTO w Rumble Fish Blockchain Development. Marek jest przodującym programistą w zakresie technologii Blockchain. Podczas swojej ponad dziesięcioletniej kariery w IT pracował między innymi w software housach we Włoszech, Hiszpanii i Stanach Zjednoczonych. Doświadczenie, zainteresowanie innowacyjnymi rozwiązaniami oraz wnikliwość sprawiły, że jest teraz jednym z wiodących programistów Blockchain w Europie. Pod jego kierownictwem zespół Rumble Fish prowadzi pomyślną współpracę z klientami, wprowadzając nowe produkty oraz osiągając doskonałe wyniki.
Spis treści
Wady posiadania pojedynczego node’a Parity
Dla wielu przypadków posiadanie jednego własnego node’a Parity w zupełności wystarczy. Mimo to można wyobrazić sobie sytuację, kiedy będzie to za mało. Kilka przykładów:
1. Prace serwisowe. Jeśli z dowolnego powodu wystąpi konieczność wyłączenia/restartu node’a ze względu na prace administratorskie, aplikacja, która od niego zależy nie będzie mogła działać. Przykładem takiej sytuacji jest upgrade wersji Parity.
2. Opóźnienie synchronizacji bloków. Parity jest świetne, ale nie jest doskonałe. Od czasu do czasu zdarza mu się losowo wpaść w opóźnienie w stosunku do reszty sieci. Posiadanie więcej niż jednego node’a pozwala wykryć taką sytuację i przekierować ruch na node’y, które są zsynchronizowane.
3. Rozdzielenie ruchu. Pojedynczy node może udźwignąć pewien określony poziom ruchu na interfejsie json-rpc. Powyżej tego poziomu interfejs json-rpc staje się powolny i node zaczyna mieć problem z utrzymaniem synchronizacji z resztą sieci.
Struktura json-rpc proxy
Zgrubny obraz elementów, z których składa się nasze rozwiązanie:
1. Serwis utrzymuje listę urli naszych node’ów Parity w DynamoDB. Jeden URL jest specjalny i oznaczony jako leader. W naszej konfiguracji jako leadera używamy publicznego node’a Infury.
2. Co 60 sekund wszystkie node’y na liście odpytywane są poprzez interfejs json-rpc metodą eth_getBlockNumber. Rezultat tego wywołania porównywany jest z leaderem. Node uznawany jest jako „zdrowy”, jeśli odpowie i jest opóźniony o nie więcej niż 10 bloków za leaderem. Health status każdego node’a jest zapisywany w DynamoDB.
3. W przypadku wykrycia zmiany statusu node’a, regenerowana jest konfiguracja proxy. Konfiguracja proxy jest prostym plikiem .conf w formacie nginx, konfigurującym serwis upstream, który rozkłada ruch pomiędzy naszymi node’ami. Jeśli wszystkie nasze node’y zostałyby uznane za niezdrowe jako fallback, ruch jest przekierowywany do leadera, czyli do Infury. Plik konfiguracyjny jest ładowany do bucketu S3.
4. Załadowanie nowego pliku konfiguracyjnego na S3 wywołuje lambdę, uaktualnia ona definicję serwisu ECS Service, który uruchamia naszego nginx z konfiguracją podaną jako ścieżka na S3.
Monitorowowanie node’ów
AWS sam z siebie bez dodatkowej konfiguracji dostarcza kilku ciekawych metryk na temat każdego serwisu, który uruchamia. Poniżej przykłady.
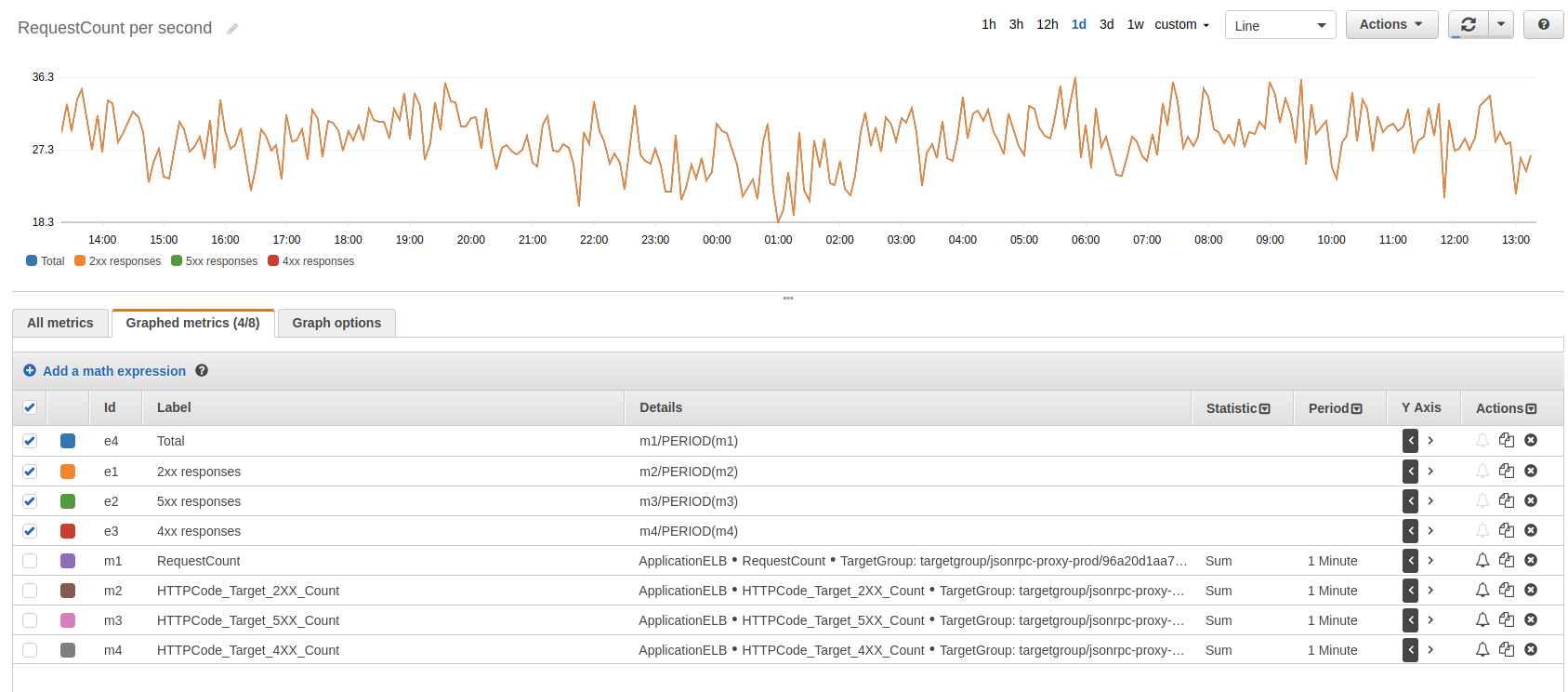
Ilość zapytań na sekundę
Nasz nginx podpięty jest do Elastic Load Balancer (ELB) i w metrykach tej usługi możemy znaleźć rozkład zapytań na jednostkę czasu i status code odpowiedzi. Ten wykres dobrze mieć na dashboardzie dla każdego serwisu, który uruchamiamy, bo mówi o poziomie utrzymywanego ruchu.
Opóźnienie w stosunku do Infury
Dodatkowo json-rpc proxy wypycha do CloudWatcha własne metryki, które pozwalają obserwować, jak zachowuje się nasz klaster. Poniżej opóźnienie każdego z node’ów w stosunku do Infury.

Ilość zdrowych node’ów
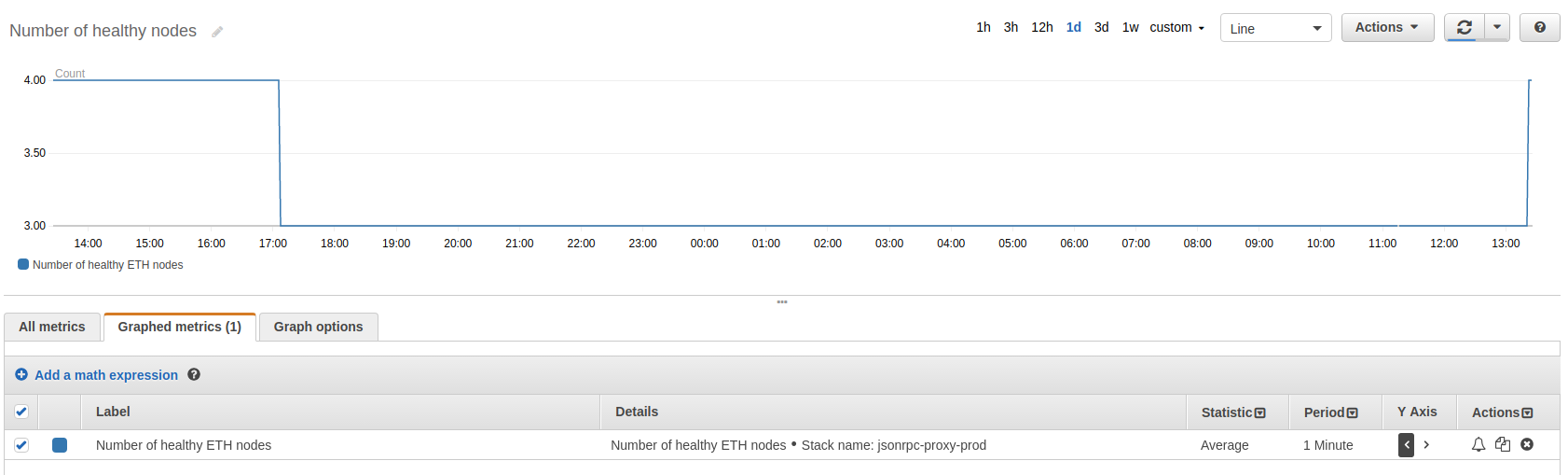
Kolejna metryka pokazuje, ile node’ów w danym momencie jest zdrowych. Tej metryki używamy do ustawienia alarmu, który powiadamia nas na Slacku, że dzieje się coś niedobrego.
Jak stworzyć własną instancję na swoim koncie AWS
Kod naszego rozwiązania znajduje się w repozytorium.
Wypchnij kontener dla nginx do repozytorium ECR
Nasz serwis uruchamia nginx w kontenerze na istniejącym klastrze ECS. Używamy w tym celu publicznego obrazu z dockerhuba i odrobinę modyfikujemy go, żeby przy starcie pobierał konfigurację ze ścieżki na S3, którą przekazujemy jako zmienną środowiskową. Obraz budowany i wypychany jest przy użyciu następujących komend:
$ cd docker $ AWS_DEFAULT_PROFILE=yourProfileName bash -x build_and_upload.sh
Komenda powyżej utworzy repozytorium ECR, zbuduje obraz i go wypchnie. W odpowiedzi zwróci ARN utworzonego repozytorium, który należy wstawić do pliku konfiguracyjnego opisanego poniżej.

Utwórz plik konfiguracyjny
Nasz serwis działa tak, żeby używać podanych wspólnych zasobów na Twoim koncie AWS. Przykładowo, nie tworzymy własnego load balancera, ponieważ to koszt kilkudziesięciu dolarów miesięcznie i jeden w zupełności wystarczy.
Plik konfiguracyjny tworzy się z przykładu zamieszczonego w repozytorium:
$ cd services $ cp config.yml.sample config.dev.yml # this assumes `dev` as stage name to be used later
Edytuj nowoutworzony plik i wstaw tam:
- Identyfikator Twojego VPC wraz z identyfikatorami prywatnych podsieci.
- Listę security group, które musi mieć lambda, żeby móc wykonać request do każdego z indywidualnych node’ów.
- Identyfikator klastra ECS, na którym odpalony będzie nginx oraz Application Load Balancer.
Ważne: ECS cluster też musi być skonfigurowany tak, żeby można z niego wykonywać request do każdego z node’ów. Jeśli do postawienia node’ów użyłeś naszego template’u z poprzedniego artykułu będą uruchomione w prywatnej podsieci. Musisz dodać security grupy przez nie utworzone do listy grup klastra ECS.
- ARN repozytorium ECR utworzony w poprzednim korku.
Uruchom serwis
Potrzebujesz mieć bibliotekę serverless zainstalowaną globalnie w systemie.
npm install -g serverless
Zainstaluj zależności naszego stacku:
cd services npm install
Kiedy skończy się instalować to wszystko jest gotowe, żeby uruchomić serwis na klastrze.
$ AWS_DEFAULT_PROFILE=yourProfileName sls deploy -s dev
Ostatnim krokiem jest konfiguracja DNS, tak żeby nazwa po której chcesz się odwoływać do proxy wskazywała jako CNAME na Application Load Balancer. Ten krok musisz wykonać w panelu administracyjnym Twojej domeny.
Konfiguracja urli monitorowanych node’ów
Kolejnym krokiem jest powiedzenie proxy, które node’y ma monitorować:
$ DATA='{"body":"{"url":"https://kovan.infura.io/kb56QStVQWIFv1n5fRfn","is_leader":true}"}'
$ sls invoke -f add_backend -d $DATA -s dev
{
"statusCode": 201,
"body": "{"url": "https://kovan.infura.io/kb56QStVQWIFv1n5fRfn", "is_leader": true, "is_healthy": false, "when_added": "2018-07-02T11:50:47.762447"}"
}
$ DATA='{"body":"{"url":"http://kovan-parity-1.rumblefishdev.com:8545","is_leader":false}"}'
$ sls invoke -f add_backend -d $DATA -s dev
{
"statusCode": 201,
"body": "{"url": "http://kovan-parity-1.rumblefishdev.com:8545", "is_leader": true, "is_healthy": false, "when_added": "2018-07-02T11:50:49.281928"}"
}
Jeśli wszystko działa prawidłowo, za ~5 minut powinieneś zobaczyć, że monitoring zadziałał i że skonfigurowane node’y są teraz zdrowe.
$ sls invoke -f list_backends | python -c "import sys,json; print(json.loads(sys.stdin.read())['body'])" | python -m "json.tool"
[
{
"block_number": 7849400.0,
"url": "http://kovan-parity-1.rumblefishdev.com:8545",
"is_healthy": true,
"is_leader": false,
"when_added": "2018-07-02T11:50:49.281928"
},
{
"block_number": 7849400.0,
"url": "https://kovan.infura.io/kb56QStVQWIFv1n5fRfn",
"is_healthy": true,
"is_leader": true,
"when_added": "2018-07-02T11:50:47.762447"
}
]
Artykuł został pierwotnie opublikowany na github.com/rumblefishdev.
Podobne artykuły

Piszesz smart kontrakty na EVM? Pokochasz to darmowe narzędzie!

Czy łatwo o pracę na obecnym rynku kryptowalut?

Budowa sieci blockchain w celu śledzenia pełnego cyklu życia produktów rolnych

W jaki sposób Wirex - firma działająca na rynku kryptowalut testuje transakcje finansowe Visa i Mastercard?

Przewodnik blockchain development – języki programowania i sieci

Blockchain Security Researcher to taki uczciwy haker, który znajduje dziury w systemie, nim zrobią to atakujący. Wywiad z Pawłem Rejkowiczem

Od programisty do Blockchain Developera. Polski software house opracował kurs dla przyszłych Blockchain Developerów
