Jak usprawnić deployment i ograniczyć downtime w kilku prostych krokach

Pracując nad projektem, prędzej czy później musimy przedstawić efekty klientowi. Nie da się ukryć, że wiąże się to z aktualizacją plików, usług i schematów w bazie danych. A to oznacza tylko jedno – nadszedł czas deploymentu!

Paweł Rychlewski. Doświadczony PHP Developer na drodze do kariery Software Architecta w The Software House. Zajmuje się zarówno backendem jak i frontendem. „Rychu” wznosi się na wyżyny nie tylko w trakcie programowania, ale i przy okazji podniebnych wypraw dronem lub zdobywając kolejne górskie szczyty. Czasami sięga jeszcze dalej – do kosmosu – czytając literaturę sci-fi.
Proces ten bywa stresujący dla wielu programistów. A to usługa nie działa poprawnie, a to posypie się baza danych lub jakaś migracja. Klienci również nie czynią naszego życia lżejszym. Zazwyczaj chcą, by deployment przebiegał bezproblemowo, zajmował jak najmniej czasu, a najlepiej pozostał niezauważony przez użytkowników. Niestety, w rzeczywistości różnie z tym bywa. Zdarza się, że deploy kolejnych wersji zajmuje sporo czasu lub powoduje chwilowe wyłączenie usługi dla użytkowników. W takich sytuacjach możemy poprosić o pomoc zespół DevOps. Problem w tym, że jego członkowie są na ogół bardzo zajęci i rzadko kiedy mogą zagwarantować przebudowę całego procesu od ręki.
Możemy się jednak zdecydować na wprowadzenie kilku prostych zmian w samym projekcie. Pozwolą nam one na skrócenie czasu procesu i ewentualnego przestoju w funkcjonowaniu aplikacji. Poniżej znajdziecie kilka koncepcji i rozwiązań, które każdy developer powinien móc bez większych problemów zaadaptować do swojego projektu.

Spis treści
Podróż do przeszłości – deployment dawniej i dziś
Zdecydowana większość programistów z pewnością doskonale pamięta początki swojej kariery i pierwsze deploye. Pracując samodzielnie nad niewielkim projektem z reguły tworzyliśmy aplikację w całości lokalnie. Dołączaliśmy (lub sami budowaliśmy) biblioteki, pobieraliśmy różnego rodzaju zasoby (np. obrazy, fonty czy style) i gotową aplikację wysyłaliśmy na serwer, korzystając z klienta FTP. Większość przygotowań odbywała się lokalnie.

Wraz z rozwojem technologicznym i powstaniem nowych standardów sposób deploymentu również uległ zmianie. Teraz, w większości przypadków, developer loguje się zdalnie na serwer produkcyjny/testowy, pobiera z repozytorium aktualną wersję projektu, a następnie uruchamia proces budowania aplikacji. W rezultacie otrzymuje kompletną aplikację wraz z niezbędnymi zależnościami. Jak łatwo zauważyć, cały proces przeniósł się na działającą zdalnie maszynę, dając możliwość automatyzacji zadań i ułatwiając zarządzanie.

Szybsze deploymenty frontendu przy użyciu narzędzi do budowania
Budowanie frontendowej aplikacji najczęściej wygląda następująco:
1. Czyścimy folder z aktualnym buildem aplikacji.
2. Łączymy skrypty.
3. Usuwamy nieużywany kod.
4. Tłumaczymy aplikację, aby mogła działać na różnych przeglądarkach.
5. Ładujemy zmienne środowiskowe.
6. Kompresujemy i minimalizujemy kod, aby uzyskać jak najmniejsze pliki.
7. Kopiujemy dodatkowe zasoby (assets).
8. Gotowe.
Czas potrzebny na zbudowanie całej aplikacji stanowi znaczący problem. W przypadku dużego projektu, można go liczyć w minutach. Ponieważ czyścimy całą zawartość folderu z aktualnym buildem (aby pozbyć się starych, niepotrzebnych plików) – użytkownicy tracą dostęp do aplikacji. W celu uniknięcia takiej sytuacji, możemy zbudować aplikację w innym folderze niż ten, który serwujemy klientom, a na samym końcu umieścić w nim pliki.

Takie rozwiązanie wprawdzie skraca czas, w którym aplikacja jest niedostępna dla klientów, lecz generuje dwa zasadnicze problemy:
1. Posiadamy zduplikowane pliki.
2. Gdy chcemy wrócić do poprzedniej wersji, tracimy dane.
Zamiast kopiować pliki, możemy stworzyć symboliczne linki, a kolejne buildy trzymać w osobnych folderach (opisanych tagami lub znacznikami czasu).

Przykładowe zadanie z linkowaniem
gulp.task('link-buld', function () {
return vfs.src(fullPath.concat('/*'), {followSymlinks: false})
.pipe(vfs.symlink(buildPath, {relativeSymlinks: true}));
});
W razie potrzeby, powrót do poprzedniego buildu będzie wymagał jedynie podlinkowania plików z innego folderu.
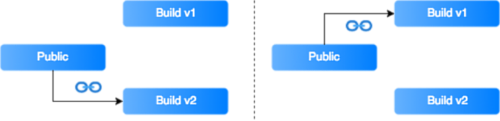
Ostatnią rzeczą, o której należy pamiętać jest to, że symboliczne linki muszą być relatywne, a folder z poprzednimi buildami powinien być dostępny na serwerze.
Przykład ścieżki
load-balancer:
image: dockercloud/haproxy
links:
- api
volumes:
- /var/run/docker.sock:/var/run/docker.sock
ports:
- 80:80
Dodatkowo, aby uniknąć problemów z cache’em przeglądarki, warto opatrzyć pliki losowym hashtagiem.
Backend deployment
HAProxy
Od dłuższego czasu wszystkie aplikacje w The Software House opieramy na rozwiązaniach z zastosowaniem konteneryzacji Dockera. Zwiększa to elastyczność projektu poprzez umożliwienie łatwej podmiany różnych elementów aplikacji. Jeśli jednak chcemy wymieniać elementy w sposób niewidoczny dla użytkowników, musimy rozszerzyć naszą architekturę o tzw. load balancer. Jest on w stanie przekierować ruch między starymi a aktualizowanymi kontenerami. Z pomocą przychodzi nam HAProxy (High Availability Proxy). Łatwo go zintegrować z projektem – wystarczy dodanie kilku linijek do naszego pliku w Dockerze.
docker-compose.yml
load-balancer:
image: dockercloud/haproxy
links:
- api
volumes:
- /var/run/docker.sock:/var/run/docker.sock
ports:
- 80:80
Aktualizacja API
Aktualizacja części backendowej w dużej mierze sprowadza się do zbudowania nowego kontenera dla aktualnej wersji API oraz przekierowania całego ruchu z jednego kontenera do drugiego. Zastosowanie HAProxy sprawia, że cały proces staje się niemal bezproblemowy. Usystematyzujmy jednak naszą wiedzę na ten temat.
Na serwerze uruchomiliśmy wersję API v1, która jest połączona z load balancerem (w naszym przypadku: HAProxy).

Budujemy wersję API v2 i dodajemy ją do aktualnie uruchomionych kontenerów. Aby to zrobić musimy skorzystać z komendy docker-compose scale api=2, następnie HAProxy sam doda go do konfiguracji i przekieruje na niego ruch (domyślnie ruch rozdzielany jest równomiernie między wszystkie kontenery w konfiguracji).

Teraz pozostaje jedynie usunąć wersję v1 i przekierować cały ruch na v2. Niestety, zmiana skalowania API na wartość 1 spowoduje usunięcie ostatnio dodanego kontenera (innymi słowy: naszej aktualnej wersji API). Dlatego też musimy pamiętać o zatrzymaniu i usunięciu starego kontenera przed zmianą skalowania. Problem ten można rozwiązać za pomocą prostego skryptu bash.
deploy.sh
#!/bin/bash
get_first_container_num() {
echo `docker inspect --format='{{.Name}}' $(docker ps -q) | grep "$1" | awk -F "_" '{print $NF}' | sort -r | head -1`
}
APP_FOLDER="dockerzerodowntime"
APP_NAME="api" # from docker-compose
APP_CONTAINER_NAME="$APP_FOLDER"_"$APP_NAME"
LB_NAME="lb" # from docker-compose
LB_CONTAINER_NAME="$APP_FOLDER"_"$LB_NAME"
APP_CONTAINER_NUM=`get_first_container_num $APP_CONTAINER_NAME`
LB_CONTAINER_NUM=`get_first_container_num $LB_CONTAINER_NAME`
docker-compose build $APP_NAME
docker-compose scale $APP_NAME=2
print "nPreparing new container..."
sleep 5; # Allow container to fully start
printf "Draining traffic from old container"
docker exec -it "$LB_CONTAINER_NAME"_"$LB_CONTAINER_NUM" sh -c "echo set weight default_service/"$APP_CONTAINER_NAME"_"$APP_CONTAINER_NUM" 0 | socat stdio /var/run/haproxy.sock"
sleep 5; # Wait for connections to drain
printf "Stopping container: "
docker stop "$APP_CONTAINER_NAME"_"$APP_CONTAINER_NUM"
printf "Removing old container: "
docker rm "$APP_CONTAINER_NAME"_"$APP_CONTAINER_NUM"
printf "Done!"
Uruchomienie skryptu spowoduje, że jedynie kontener API v2 pozostanie aktywny, a cały ruch będzie kierowany bezpośrednio na niego.

Baza danych
Ostatnim elementem do przeanalizowania jest baza danych. W zależności od tego, co chcemy zmienić, może to być jeden z najprostszych lub najtrudniejszych elementów systemu. Aby zapewnić sprawny przebieg tej procedury, możemy zastosować jedno z prezentowanych poniżej rozwiązań. Ponadto warto wspomnieć, że należy modyfikować API stopniowo, na przemian z bazą danych.
Dodawanie nowej kolumny
1. Tworzymy migrację, aby dodać nową kolumnę.
2. Wdrażamy kod z migracją.
3. Wgrywamy tę wersję API, która używa nową kolumnę.
Usuwanie kolumny
1. Modyfikujemy kod w taki sposób, by nie używał wybranej kolumny.
2. Przygotowujemy migrację dodając do nazwy kolumny sufiks _deprecated:
- jeżeli nowa funkcjonalność się sprawdza i mamy pewność, że dane nie będą nam już potrzebne, możemy usunąć kolumnę;
- jeżeli napotkamy jakiś problem, możemy w łatwy sposób powrócić do poprzedniej wersji bazy danych poprzez usunięcie sufiksu.
Zmiana nazwy kolumny
1. Przygotowujemy migrację tworzącą kolumnę z nową nazwą.
2. Dodajemy event dbający o to, żeby zaktualizowane dane były kopiowane do nowo utworzonej kolumny.
3. Migrujemy dane ze starej kolumny do nowej (najlepiej podzielić rekordy na części).
4. Modyfikujemy kod tak, aby używał tylko nowej kolumny.
5. Usuwamy starą kolumnę (patrz: przykład powyżej).
Zmiana typu kolumny
1. Tworzymy migrację, która zawiera nową kolumnę o zmienionym typie. Do nazwy dodajemy sufiks z typem kolumny, aby łatwiej było je rozróżnić: nazwa_kolumny_typ.
2. Dodajemy event dbający o to, żeby aktualizowane dane były kopiowane do nowo utworzonej kolumny.
3. Migrujemy dane ze starej kolumny do nowej.
4. W modelu wprowadzamy nazwę kolumny nowego typu (warto zadbać w tym miejscu o kompatybilność; jeśli nie odnajdziemy kolumny nazwa_kolumny_typ, użyjemy oryginalnej nazwy kolumny; możemy je pobrać korzystając ze Schema-Managera).
5. Tworzymy migrację, która dopisuje do oryginalnej kolumny sufiks _deprecated, z nowej natomiast usuwamy sufiks z typem.
6. Czyścimy model z logiki do odgadywania nazwy kolumny.
7. Usuwamy starą kolumnę (patrz: przykład powyżej).
Analizując powyższe przykłady, możemy zauważyć, że przemyślane migracje pozwolą nam na aktualizację lub modyfikację bazy danych w sposób praktycznie niezauważalny dla użytkowników.

Niewielki nakład pracy, znaczące usprawnienie
Podsumowując: względnie niewielkim nakładem pracy możemy znacznie skrócić czas deploymentu. Należy jednak pamiętać, że jest to proces, który wymaga odpowiedniego przygotowania, zachowania ostrożności i należytej dyscypliny w trakcie implementacji. Poprawnie zastosowany może nam jednak oszczędzić niepotrzebnego stresu i spowoduje, że nasi klienci będą bardziej zadowoleni z rezultatu.
Artykuł został pierwotnie opublikowany na blogu tsh.io. Zdjęcie główne artykułu pochodzi z stocksnap.io.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
