SAFe okiem developera: Scrum na sterydach dla projektów klasy enterprise

Gdy podczas zajęć z metodologii budowania oprogramowania pada pytanie: „Jak myślicie, jak dziś się to robi?”, w pierwszej chwili wszyscy milkną (czasem gdzieś na końcu sali ktoś zarechocze). Po kilku sekundach jedna z bardziej świadomych osób czasem nieśmiało odpowiada: „Scrum?”.
Tak, to prawda, ale o co tu chodzi? Po co to komu? Nie można tak po prostu usiąść i zacząć pisać kod? Jakiego typu potrzeby on zaspokaja, czy ma jakieś ograniczenia? I w ogóle czy można jego zasady skalować również dla projektów z kilkudziesięcioma deweloperami? A z kilkuset? Idąc dalej, co jeśli projekty domeny są od siebie zależne?
Poniższy artykuł nie jest wykładem, a lekkim i pełnym uproszczeń (takim w sam raz do porannej kawy) potokiem myśli próbującym odpowiedzieć na potrzebę, której istnienie autor zauważył zarówno na sali wykładowej, jak również u programistów z doświadczeniem zawodowym, ale dopiero zaczynających pracę w metodykach zwinnych. Tą potrzebą jest nadanie kontekstu i odpowiedź na pytanie: “ALE PO CO mi to” w taki sposób, aby nie tylko usłyszeć: „bo tak”, ale faktycznie owe „bo tak” zrozumieć. A to wszystko w kontekście dużych projektów i stricte z punktu widzenia programisty.

Spis treści
Co to i po co mi Scrum?
No więc ab ovo – co to i po co mi scrum?
Scrum to ramy postępowania mające na celu usprawnienie procesu dostarczania oprogramowania. To budowanie odpowiedzialności teamu. W idealnym podejściu scrumowym nikt nikomu niczego nie narzuca, a to, co team weźmie na siebie, jest jego własnym krzyżem do niesienia. To team się do czegoś zobligował, i to team będzie ze swojego zobowiązania rozliczony, ergo to teamowi zależy na tym, aby być słownym. Czy chodzi o wydajność? Też, ale przede wszystkim o przewidywalność. Biznes potrzebuje przewidywalności. Czy podjeżdżając pod stację paliw chcielibyśmy w poniedziałek widzieć kartkę „limit 15 litrów per klient”, w czwartek „limit 40 litrów per klient”, a w sobotę „dziś tylko 5 litrów”? Brak przewidywalności to brak wiarygodności, która z kolei uderza w zaufanie, a brak zaufania klienta to szybka droga do braku klienta.
Reasumując, pierwsze słowo-klucz odpowiadające na pytanie: „po co mi skalowalny scrum” to przewidywalność.
A po co mi SAFe? SAFe to wyciągnięcie idei scruma w strefę projektów klasy enterprise w rejon, gdzie deweloperów mamy przynajmniej kilkudziesięciu, gdzie nasz codebase jest dynamiczny, i gdzie fakt dużego ruchu w kodzie zwiększa prawdopodobieństwo dużych problemów ze współzależnościami między funkcjonalnościami czy projektami. SAFe nie jest jedyną drogą postępowania, jednak na pewno jest drogą, o której istnieniu warto wiedzieć. Podnosi też widoczność i wyrazistość wszystkich zalet i wad scruma.
Na wyjątkowo przerażającym obrazku rozwinięcie scruma o nazwie SAFe wygląda tak:
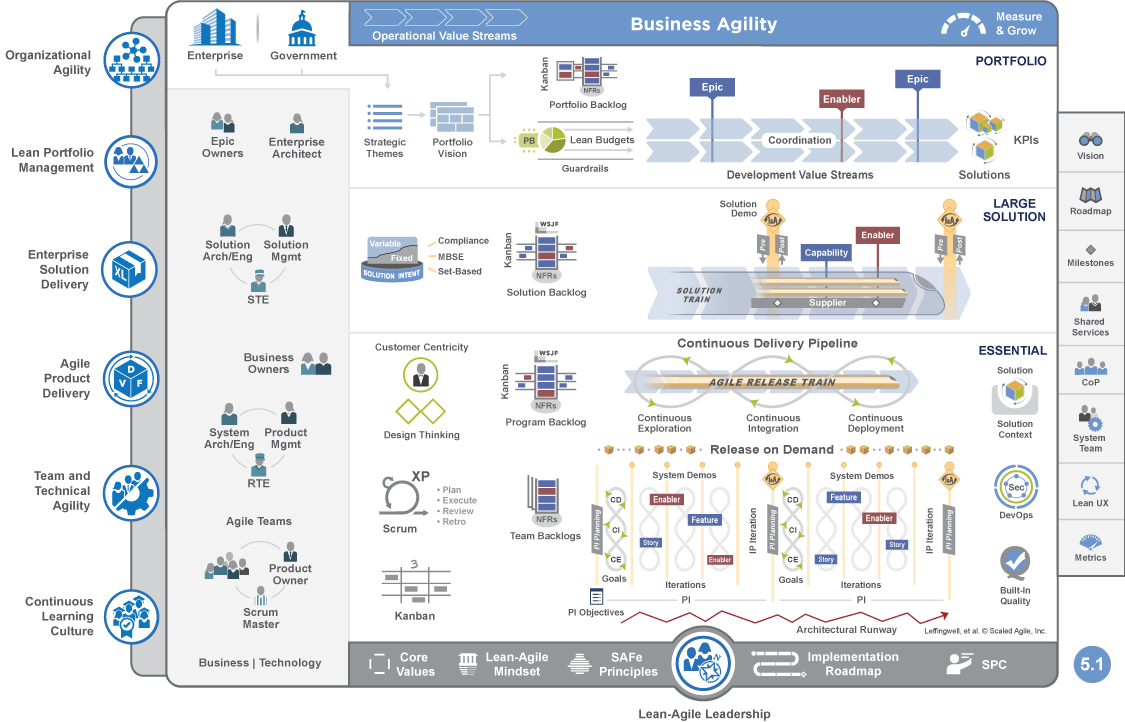
Źródło: www.scaledagileframework.com
– Uhmmm Filip, a można na jakimś przykładzie? – w tym miejscu można zadać to pytanie.
Jasne, wyobraźmy sobie projekt strony internetowej linii lotniczej. Jest to CMS na sterydach (taki uber-wordpress), i budujemy dla niego różnego rodzaju SPA (np. funkcjonalność sprawdzania certyfikatów covidowych), które potem są przez edytorów osadzane w obrębie portalu.
Dlaczego CMS, a nie po prostu strona? Bo to projekt nie dla jednej linii lotniczej, ale ich grupy (np pięciu różnych), i musi dać się nim zarządzać. Każda linia lotnicza ma wsparcie dla n-krajów / n-języków plus istnieje tam potrzeba funkcjonalnego dopasowywania konkretnych SPA dla kraju i/lub linii lotniczej. To wszystko w oparciu o backendowe endpointy API, które z kolei są ograniczeniami dla warstwy prezentacji z konfigurowalnymi 3rd party końcówkami dla funkcjonalności budowanych w obrębie rozwiązań mobilnych (co istotne – różnych od tych występujących dla desktopów). Do tego mamy potrzebę ekspozycji na specyficzne dla linii X lub Y zachowania utrzymywane w środowiskach „legacy”, i współosadzanie połączonych semantycznie (sub) projektów w taki sposób, aby między nimi następowała wymiana danych (powiedzmy że np. projekt AI jest realizowany przez inną grupę deweloperów i że takich semantycznie zależnych projektów jest pięć).
Mało? Ok, to niech jeszcze każdy z tych projektów ma po cztery scrumowe teamy po ~9 osób w każdym, i po +/- 10 osób z tzw. managementu projektu w każdym.
Przykład powyżej daje 230 osób samego „core teamu”, który w teorii powinien wiedzieć o wszystkim, co się dzieje w tzw “kodzie”. Wszyscy. W trybie ciągłym. A gdzie utrzymanie/devops? A gdzie security? A gdzie testerzy, WCAG, architekci, UX czy po prostu ludzie tworzący designy? Ilość osób zaangażowanych rośnie w dramatyczny sposób i bez współpracy i ciągłej komunikacji między zainteresowanymi mamy przepis na tragedię.
Drugie słowo odpowiadające na pytanie: „PO CO?” wynikające z powyższego to synchronizacja.
SAFe
SAFe to framework starający się ogarnąć powyższe problemy, który do standardowych elementów scruma (daily, refinement, planowanie, retrospektywa etc.) dodaje dodatkowe ramy służące synchronizacji pomiędzy teamami, ale również (opcjonalnie) między innymi produktami w portfolio.
W prostym scrumie mamy sprinty i… w zasadzie tyle, w SAFe mamy „PI” (product increment) i co kolejny PI fajnie byłoby móc dostarczyć jakąś większą wartość (np. duży feature). PI to zazwyczaj 5 iteracji (co w naszym rozumieniu oznacza 5 sprintów), i to ten odcinek czasu powinien być zsynchronizowany pomiędzy produktami.
Co PI (+/-3 miesiące przy założeniu dwutygodniowych sprintów) ma miejsce kilkudniowe (najczęściej trzydniowe) wydarzenie o nazwie PI planning, gdzie wszystkie zaangażowane osoby traina (kolejne nowe pojęcie to ART => Agile Release Train, tzn. wszyscy, którzy mają związek z produktem) spotykają się i ustalają, co będą robić przez kolejne trzy miesiące.
Tak, 3 dni ciągłego gadania. Serio. Wszystkie teamy ART-u w jednym miejscu debatują, co dalej.

Źródło: baloise.com
Czy takie planowanie jest potrzebne? Stety/niestety tak. W momencie, gdy każda nowa funkcjonalność to potrzeba angażowania minimum kilkunastu deweloperów z potencjalnymi zależnościami do innych teamów / funkcjonalności, to nie dość, że każdy team może mieć własne ograniczenia (np. zadanie stylowania raczej nie ma jak wystąpić przed stworzeniem markupu), to jeśli team A wie, że nie skończy zadania umożliwiającego teamowi B pracę w pierwszym sprincie, to może team B niech o tym z góry wie i zaplanuje swoje zadanie na kolejny? Albo jeszcze kolejny? Dodatkowo jeśli wiadomo, że mamy zewnętrzne ograniczenie (np. firma XYZ nie ma gotowego backendu, twierdzi jednak, że będzie gotowy za miesiąc), to można z góry zaplanować jego implementację w późniejszym czasie (…albo temat w ogóle odrzucić jako nie gotowy przed planowaniem, i opisać jako kandydata do wzięcia na kolejną iterację – tzn. na kolejny PI).
Jednym zdaniem: idea kolektywnego umysłu działa lepiej i jest bardziej wiarygodna niż odgórnie narzucane przez management deadline’y, stąd potrzeba komunikacji jest tym bardziej istotna – zwiększa wiarygodność.
Tak trochę na marginesie, lecz w relacji do powyższego: elementem integralnym, który w wypadku pracy w dużym projekcie zyskuje na wartości to demo. Nie chodzi jednak o sprint demo, gdzie chwalimy się osiągnięciami sprintu, lecz system-demo odbywające się jako część PI-planningu pokazujące osiągnięcia całego PI. Na tym spotkaniu przedstawiciele klienta naprawdę mocno nadstawiają uszu oglądając to, za co zapłacili w akcji.
A co w wypadku, gdy wszystko jest niby na swoim miejscu, ale jednak nie działa? Czy ktoś dogląda procesu „z góry”? Cóż, SAFe jako struktura jest też i na to przygotowany poprzez wprowadzanie dodatkowych ról, m.in. scrum mastera scrum masterów, który nie ma zadania „być przełożonym”, lecz kimś na zasadzie servant-leadera, którego rolą jest pomoc i reagowanie na potencjalne problemy.
A największa wada i zaleta SAFe?
Co nam daje aż taka formalizacja procesu? Przede wszystkim bezpieczeństwo. Dzięki wstępnemu zaplanowaniu trzech miesięcy mamy pewność, że nikt nie wrzuci dev-teamowi niczego pilnego, co zmiecie dotychczasowe priorytety.

Źródło: external-preview.redd.it
Jeśli zaś z doświadczenia wiemy, że takie rzeczy, jak „krytyczny bug na produkcji” w naszym wypadku się zdarzają, zaplanujmy to! Czy 10 proc. per sprint na łatanie wystarczy? A może 20 proc.? Teraz mamy ku temu i możliwość, i narzędzia.
Z doświadczeniem przyjdzie wiedza, że 30 proc. buforu na bugi + maintenance to wcale nie tak dużo, a zaraz potem okaże się że naturalne i organiczne fluktuacje pracowników (chleb powszedni naszego rynku) to coś, co też można zaplanować. Swoją drogą można też z tego zrobić wartość i sprzedawać jako atut miejsca pracy – czy np. 20 proc. czasu na tzw. sesje “knowledge transfer” nie brzmi dobrze? Dzięki temu nie dość, że tworzymy kulturę dzielenia się wiedzą, to jednocześnie zwiększamy kompetencje i dojrzałość wszystkich dookoła. I to wszystko nie „przy okazji” i „w wolnym czasie”, ale dlatego, że jesteśmy świadomi potrzeby ciągłego doskonalenia.
Olbrzymią zaletą podejścia SAFe jest transparencja wyniesiona do rangi religii – jeśli się komunikujemy i mamy wspólny cel, to gdy wystąpią jakieś przeszkody, nie będzie to ukrywane, a to znaczy, że będzie można szybko zareagować. Brzmi fajnie, jednak w rzeczywistości to może być też wadą – jeśli wszystko jest aż tak przejrzyste i klarowne, to znaczy, że od zarządzających projektem wymagamy dojrzałości podejścia – dev-team to ludzie, więc jeśli świadomie upychamy im zawsze „pod korek”, w dłuższej perspektywie deweloperzy się wypalą, a to nie przysłuży się nikomu.

Źródło: https://media.makeameme.org/
Bezpieczeństwo skalowanego procesu to też jego największa wada – proces ma potencjał do usztywniania się, a to może powodować dysfunkcje typu:
- „potrzebuję planów urlopowych wszystkich na kolejne trzy miesiące, bo muszę wyliczyć capacity teamu”,
- „dlaczego team X dostarczył mniej niż obiecał? pan X zachorował? hmm… nie można było tego zaplanować? Przez to pozostałe trzy teamy będą mieć spillovery”,
- „mamy low-prio buga na produkcji, ale nasz ‘train’ nie może się nim zająć przez najbliższe 10 tygodni – niech ktoś spoza ARTu zrobi łatkę poza procesem. Taką ‘best effort’”.
Jeśli chodzi o coś najbardziej charakterystycznego dla pracy w SAFe, to jest to cecha, którą można by określić mianem „spotkanioza”. Jedną z najważniejszych wartości procesu jest tu synchronizacja (zaraz potem planowanie i przygotowywanie do kolejnych kroków w przyszłości), tak więc twardą lekcją dla każdego dewelopera jest zaakceptowanie tego, że spotkania są integralną częścią pracy. Nie dodatkiem, lecz czymś tak samo ważnym, jak pisanie kodu.
…i że trzeba się do nich przygotować.
…i mieć to na uwadze, planując PI/sprint.
…i w międzyczasie mieć czas na kodowanie.
Przykład z życia wzięty – w poprzednim tygodniu i w obrębie 40h (8h * 5 dni) pracy, spotkania stricte procesowe (a oczywiście, że są też i inne) zajęły autorowi ~10h, a przygotowania do nich – 6h. Czy to źle czy dobrze? Nijak:) Ot, cecha charakterystyczna potrzeby ciągłej synchronizacji i dbania o bycie na bieżąco.
Wymagania SAFe
Najtrudniejsze w podejściu opartym na potrzebie przewidywalności i oczekiwaniu dojrzałości jest jej budowanie u wszystkich zaangażowanych. Co jednak ciekawe, nie w oparciu o te oczekiwania, lecz o szczerość względem wszystkich dookoła:

Źródło: images.squarespace-cdn.com
– Dobra Filip, a konkretnie? – tu też można spytać. A więc odpowiadam:
- deweloperzy muszą nauczyć się szczerości względem siebie samych w szacowaniu i rozumieniu zadań, które są w kolejce (nie zostawiając niczego na „a to dowiem się gdy już to wezmę”),
- deweloperzy muszą poznać własne komfortowe tempo pracy – SAFe jeszcze bardziej niż scrum pokazuje, że określenie “sprint” nie jest przypadkowe, i że jeśli nie weźmie się pod uwagę potrzeby zjedzenia w ciągu tygodnia choćby jednego obiadu, to po prostu nie będzie się miało na to przestrzeni,
- scrum master musi być świadomy tego, że nie jest menedżerem, a opiekunem, którego rolą jest aktywne słuchanie i reagowanie w formie pomocowej, a nie zarządzającej,
- product owner musi mieć twardy kręgosłup, aby na poziomie programu mówić „NIE” w sytuacji, gdy ktoś chce coś ugrać / iść wbrew procesowi,
- na poziomie managementu ART-u musimy mieć na tyle dużą empatię, aby nie prowokować micro-managementu na poziomie teamu, lecz cały czas forsować ideę organicznego wzrostu i być wrażliwym na głosy deweloperów,
- musimy dbać o ciągłe bycie na bieżąco i zaakceptować fakt, że spotkania to nasza codzienność, i że bardzo istotnym jest, aby być w nich aktywną częścią,
- …i że musimy być komunikatywni. Tak, nawet wtedy, gdy identyfikujemy się z żartem: “nie po to poszedłem na IT, żeby rozmawiać z ludźmi”.

Źródło: https://koszulkowy.pl/
W jaki sposób wszystko, co powyższe zinterpretujemy, jest naszą indywidualną sprawą, lecz choć brzmi to w pierwszej chwili przerażająco, daje naprawdę dużo frajdy – koniec końców chodzi o nasz własny rozwój i stawanie się lepszym w tym, co robimy, a proces ma za zadanie jedynie katalizować coś, na czym nam zależy i choć jest wymagający, to też zadziwiająco sprawny i skuteczny.
Podsumowanie
Na zakończenie, jest jeszcze jedna krytyczna sprawa, która w zderzeniu z ideą SAFe urasta w swojej randze istotności – mianowicie potrzeba wypracowania w sobie wysokiej uważności na wszystko, co dzieje się dookoła. Poczucie sprawczości dane przez proces na pierwszy rzut oka jest cudowne, upewnijmy się jednak od czasu do czasu, czy aby nie przepoczwarza się w mechanizm służący tylko ślepemu zwiększaniu produktywności.
Jeśli bierzemy za coś odpowiedzialność, zaczynamy traktować to emocjonalnie, przywiązanie zaś na poziomie emocji to niebezpieczne narzędzie i miecz obosieczny – jeśli komuś zależy, w naturalny sposób stara się bardziej, a jeśli stara się bardziej, to bez wypracowania w sobie zdrowego dystansu i świadomości własnych granic szybko może się wypalić …a chyba nie o to chodzi w szukaniu swojego własnego work-life balance, prawda?
Życząc nam wszystkim właśnie tego – smacznej kawusi 🙂

Źródło: https://encrypted-tbn0.gstatic.com/

Podobne artykuły

Nie odpowiadaj za błędy własnym majątkiem, czyli krok po kroku do zabezpieczenia swojej pracy

Najważniejsze wskazówki dla liderów w 2024. Jak stworzyć zdrową atmosferę w miejscu pracy?

Od kodowania do budowania relacji — rola komunikacji w pracy projektowej
Jak napisać własny emulator Chip-8?

Jak wygrać konkurs dla programistów w 5 krokach?

Poznaj 5 najbardziej docenianych umiejętności w branży IT

Testy integracyjne z wykorzystaniem WireMock w Spring Boot
