Monad transformers w Scali. This Month We’ve Learned

Bez względu na wiek i doświadczenie, każdy z developerów powinien starać się podnosić poprzeczkę umiejętności. Zastanawialiśmy się, jak zachęcić Was do dzielenia się nowymi skillami i doszliśmy do wniosku, że warto pokazać, jak senior developerzy na co dzień rozwijają się. Poprosiliśmy ich o to, by podzielili się tym, czego nauczyli się w mijającym miesiącu.
W ten sposób powstał nowy cykl w naszym magazynie – inspirowany This Month We’ve Learned stworzonym przez SoftwareMill. Zobaczcie, czego w tym miesiącu nauczyli się zaproszeni developerzy, a Wy w komentarzach dajcie znać, co dopisalibyście do poniższych przykładów.
Wypowiedzi udzielili:

Jacek Kunicki. Senior Software Engineer w SoftwareMill. Zapalony inżynier oprogramowania działający w obszarze JVM – głównie, ale nie tylko. Wierzy, że software craftsmanship jest agnostyczne technologicznie – więc nigdy nie ogranicza swojego portfolio do kilku technologii. Zwykle bawi się elektroniką i sprzętem. Dzieląc się swoją wiedzą na licznych eventach JVM-owych, zawsze pamięta, że przykład z realnego użycia jest wart tysiąca słów, dlatego często zobaczycie go w akcji przy live coding session.

Iwona Jóźwiak. PHP developer w Divante. Od 15 lat „żyję internetem” – pamiętam erę IE 5 . Ostatnie 5 lata ukierunkowałam głównie na backend Magento. Za swoją najmocniejszą stronę uważam umiejętność łączenia technologii i biznesu. Ponadto należę do grupy certyfikowanych developerów „Magento Developer Plus„. Dziś bardziej reprezentuję grupę backend developerów, jednak wciąż, w miarę wolnego czasu lub ciekawych zadań w projekcie, staram się rozszerzać wiedzę frontendową.

Michał Załęcki. Senior Software Engineer w Tooploox. Zajmuje się tematyką blockchain oraz tworzeniem zdecentralizowanych aplikacji. Michał prowadzi warsztaty BlockchainPro oraz organizuje spotkania grupy ReactJS Wrocław. Jeżeli chcesz poczytać więcej na tematy związane z blockchain zajrzyj na bloga michalzalecki.com.
Spis treści
Monad transformers w Scali. Jacek Kunicki, Senior Software Engineer w SoftwareMill:
Po wkroczeniu na ścieżkę programowania funkcyjnego w Scali prędzej czy później dochodzimy do momentu, kiedy pisząc kod czujemy, że coś dałoby się zrobić ładniej, wprowadzając kolejny poziom abstrakcji.
Przykładem takiej sytuacji jest próba użycia for comprehension (które, dla przypomnienia, jest innym sposobem zapisania ciągu wywołań flatMap i na końcu wywołania map (*)), do wykonania kilku powiązanych operacji, z których każda zwraca zagnieżdżone monady (**), np. Future[Option[A]].
Wyobraźmy sobie pobieranie użytkownika za pomocą metody def findUserById(id): Future[Option[User]] oraz jego firmy za pomocą def findCompanyByUser(user): Future[Option[Company]]. Gdybyśmy chcieli połączyć te dwa wywołania w for comprehension w następujący sposób:
for {
user <- findUserById(id)
company <- findCompanyByUser(user)
} yield company
Kompilator zaprotestuje, ponieważ user jest typu Option[User], a nam potrzebna jest wartość, która jest wewnątrz Option. Innymi słowy, mając wartość typu Future[Option[User]], chcielibyśmy wywołać flatMap nie na Future, tylko na znajdującym się wewnątrz Option, żeby dostać w kolejnym kroku wartość typu User.
Do tego właśnie możemy użyć monad transformera — pozwoli on de facto delegować wywołanie flatMap do opakowywanego obiektu. Z pomocą przychodzi biblioteka Cats i dostępny tam transformer OptionT[F, A]. Jak widać ma on dwa parametry generyczne:
Fto monada “zewnętrzna” (u nasFuture),Ato typ opakowanej wartości (u nasUser).
Sam transformer OptionT też jest monadą, więc możemy go używać wewnątrz for comprehension:
for {
user <- OptionT(findUserById(id))
company <- OptionT(findCompanyByUser(user))
} yield company
Powyższy kod się kompiluje i faktycznie w drugiej linii for comprehension dostajemy wartość typu User. Wartość zwracana przez całe wyrażenie jest typu OptionT[Future, Company] i w polu value przechowuje wartość, która prawdopodobnie nas interesuje — Future[Option[Company]].
W tym miejscu dochodzimy do problemu, który był dla mnie zaskakujący, ale po namyśle całkiem uzasadniony. Gdy dodamy odpowiednie importy z Cats (najprościej import cats.implicits._), to próba wywołania OptionT.apply zakończy się błędem kompilacji mówiącym, że brakuje Applicative[Future].
Jest to początkowo dość zaskakujące, ponieważ import cats.implicits._ powinien załatwić m. in. instancję Applicative dla Future, więc dlaczego kompilator twierdzi, że jej brakuje?
Szukając dalej w cats.instances.FutureInstances zauważymy, że do utworzenia instancji odpowiednich type class dla Future potrzebny jest ExecutionContext. Dlaczego? Gdy przypomnimy sobie, że scalowy Future jest eager, więc od razu po wywołaniu metody apply uruchamiany jest nowy wątek, staje się jasne, że chcąc operować na Future’ach, potrzebujemy na dzień dobry puli wątków, czyli właśnie ExecutionContextu.
Okazuje się zatem, że błąd kompilacji mówiący o braku Applicative[Future] jest dość mylący, ponieważ w rzeczywistości chodzi o brak ExecutionContextu. Najprostszym, choć nie zawsze poprawnym rozwiązaniem jest dodanie import scala.concurrent.ExecutionContext.Implicts.global, czyli użycie globalnej puli wątków.
Jak widać pierwsze starcia z Cats mogą być pełne niespodzianek. Jeśli chcesz się dowiedzieć, co jeszcze może Cię zaskoczyć, zajrzyj do artykułu Mikołaja Koziarkiewicza zawierającego kilka cennych wskazówek.
Wyjaśnienie:
(*) jak również operacji foreach, filter i withFilter, jednak nie są one istotne w kontekście tego artykułu.
(**) jeśli pojęcie monady to dla Ciebie nowość, na potrzeby tego artykułu możesz przyjąć w uproszczeniu, że jest to typ opakowujący jakąś wartość i udostępniający metody map, flatMap oraz metodę pozwalającą na opakowanie istniejącej wartości (nazywaną np. apply lub pure).
Import pliku CSV za pomocą PHP w Magento 2. Iwona Jóźwiak, PHP developer w Divante:
Nieustanny rozwój jest wręcz obowiązkiem każdego developera. Naturalną konsekwencją pracy w obrębie jednego/kilku projektów jest to, że w pewnym momencie następuje stagnacja i „niewiele się dzieje nowego”. Czy jest to powód by przestać się rozwijać? Zdecydowanie nie!
Jestem osobą, która stara się wykorzystać każdą wolną chwilę na podnoszenie swoich kompetencji. Ostatnio przede wszystkim rozwijam się w obszarze Magento 2.
Jak wyglądają mechanizmy służące do importu w Magento 2?
W Magento 2 urzekła mnie przede wszystkim architektura silnika i możliwości jakie ze sobą niesie. Niesamowitym jest, jak prosto można zaimportować dane, wykorzystując pliki CSV. Tak naprawdę wystarczy kilka linijek kodu:
$importFile = ‘plik.csv’;
/** @var MagentoImportExportModelImportFactory $importFactory **/
/** @var MagentoImportExportModelImportInterceptor $import **/
$import = $importFactory->create();
$import->setData([
'validation_strategy' => 'validation-stop-on-errors',
'allowed_error_count' => 1,
'entity' => 'customer'
]);
/** @var MagentoImportExportModelImportSourcecsv $sourceModel **/
$sourceModel = MagentoImportExportModelImportAdapter::findAdapterFor(
$importFile,
/** @var MagentoFrameworkFilesystem $filesystem **/
$filesystem->getDirectoryWrite(MagentoFrameworkAppFilesystemDirectoryList::ROOT),
$import->getData('_import_field_separator')
);
$isValid = $import->validateSource($sourceModel);
if ($import->getProcessedRowsCount() === 0 || !$isValid || $import->getErrorAggregator()->getErrorsCount()) {
throw new Exception(‘Plik CSV zawiera błędy.’);}
$import->importSource();
Powyższy kod wykorzystałam w ramach skryptu CLI. Dzięki temu mogłam uruchomić import w konsoli w screenie. Omówmy sobie jednak krok po kroku powyższy skrypt.
Na początku korzystając z fabryki MagentoImportExportModelImportFactory tworzymy obiekt ($import), który jest interceptorem. Wykorzystanie tego wzorca sprawia, że możemy tworzyć pluginy dla naszego importera, które w zależności od potrzeb biznesowych będą mogły wpłynąć na przygotowanie danych, przebieg importu oraz wykonać odpowiednie działania po jego zakończeniu.
Następnie wprowadzamy parametry konfiguracyjne:
$import->setData([ 'validation_strategy' => 'validation-stop-on-errors', 'allowed_error_count' => 1, 'entity' => 'customer' ]);
validation_strategy — przyjmuje wartości:
validation-stop-on-errorszatrzymaj walidację w przypadku wystąpienia błędówvalidation-skip-errorspomiń wiersze, w których znajdziesz błąd
allowed_error_count — domyślna ilość błędów po jakiej magento zatrzyma walidację pliku to 100. Można jednak za pomocą tego parametru zmniejszyć bądź zwiększyć tę liczbę.
entity — wskazujemy jakie dane będą przedmiotem importu:
advanced_pricing— ceny produktów,catalog_product— produkty,customer_composite— klienci wraz z adresami,customer— klienci bez adresów,customer_address–– adresy klientów.
W kolejnym kroku za pomocą adaptera tworzymy obiekt source model:
/** @var MagentoImportExportModelImportSourcecsv $sourceModel **/
$sourceModel = MagentoImportExportModelImportAdapter::findAdapterFor(
$importFile,
/** @var MagentoFrameworkFilesystem $filesystem **/
$filesystem->getDirectoryWrite(MagentoFrameworkAppFilesystemDirectoryList::ROOT),
$import->getData('_import_field_separator')
);
do którego przekazujemy informacje o naszym pliku csv, czyli kolejno:
$importFile— nazwa pliku csv$filesystem ->getDirectoryWrite(MagentoFrameworkAppFilesystemDirectoryList::ROOT)— wskazanie lokalizacji pliku csv, w tym wypadku jest to katalog ROOT projektu$import->getData('_import_field_separator')— separator pól, domyślnie separatorem jest przecinek.
W kolejnej linijce przystępujemy do walidacji pliku:
$isValid = $import->validateSource($sourceModel);
Następnie sprawdzamy czy nie wystąpił jakiś błąd:
if ($import->getProcessedRowsCount() === 0 || !$isValid || $import->getErrorAggregator()->getErrorsCount())
warunek zostanie spełniony jeśli:
$import->getProcessedRowsCount()— nie przetworzono wierszy, ich liczba równa się 0!$isValid— plik nie został zwalidowany poprawnie$import->getErrorAggregator()->getErrorsCount()— walidacja zwróciła błędy
Jeżeli chcemy zwrócić tablicę błędów wraz z numerami wierszy, których dotyczą wystarczy użyć metody:
$import->getErrorAggregator()->getAllErrors();
Poniżej znajduje się przykładowy ”output”:
array(1) {
[0]=>
object(MagentoImportExportModelImportErrorProcessingProcessingError)#1625 (6) {
["errorCode":protected]=>
string(12) "invalidEmail"
["errorMessage":protected]=>
string(27) "Please enter a valid email."
["errorDescription":protected]=>
NULL
["rowNumber":protected]=>
int(5)
["columnName":protected]=>
string(5) "email"
["errorLevel":protected]=>
string(8) "critical"
}
}
Najważniejsze dla nas informacje znajdują się w errorMessage, rowNumber i errorLevel. Oznaczają one bowiem jaki błąd został wykryty, w której linii i kolumnie oraz jak bardzo jest istotny dla importu.
Jeżeli interesuje nas by wygenerować csv wraz z naniesionymi błędami, inspirację do modyfikacji powyższego skryptu znajdziemy w pliku:
vendor/magento/module-import-export/Controller/Adminhtml/ImportResult.php
w metodzie:
/**
* @param ProcessingErrorAggregatorInterface $errorAggregator
* @return string
*/
protected function createErrorReport(ProcessingErrorAggregatorInterface $errorAggregator)
{
$this->historyModel->loadLastInsertItem();
$sourceFile = $this->reportHelper->getReportAbsolutePath($this->historyModel->getImportedFile());
$writeOnlyErrorItems = true;
if ($this->historyModel->getData('execution_time') == ModelHistory::IMPORT_VALIDATION) {
$writeOnlyErrorItems = false;
}
$fileName = $this->reportProcessor->createReport($sourceFile, $errorAggregator, $writeOnlyErrorItems);
$this->historyModel->addErrorReportFile($fileName);
return $fileName;
}
Jak przygotować plik CSV?
Wiemy już jak zaimportować nasz csv, jednak jakie przyjmuje on kolumny i które są wymagane?
Aby dowiedzieć się jakie kolumny powinny się znaleźć w naszym pliku, najprościej wykonać export za pomocą narzędzia znajdującego się w panelu administracyjnym w zakładce: System → Export.
Przykładowe pliki znajdziemy też w samym module w lokalizacji:
vendormagentomodule-import-exportFilesSample
Do importu csv, podobnie jak i do exportu, możemy wykorzystać narzędzie znajdujące się w panelu administracyjnym w ścieżce:
System → Import
Informacje o tym jak przygotować pliki importu i jak z nim pracować, znajdziemy również w dokumentacji użytkownika.
Powyższy przykład obrazuje, w jak relatywnie prosty sposób można zaimportować dane do naszego sklepu bazującego na Magento 2. W zasadzie wystarczy kilka linijek kodu i plik CSV, by zintegrować się z zewnętrznym systemem i zaimportować z niego dane.
Naładowanie baterii. Michał Załęcki, Senior Software Engineer w Tooploox:
Web Bluetooth API pozwala na wyszukiwanie i łączenie się do urządzeń poprzez stanadard Bluetooth 4 z wykorzystaniem Generic Attribute Profile (GATT). Demo, z którym się pobawimy pozwala na znalezienie urządzenia BLE (Bluetooth Low Energy), które udostępnia informacje o poziomie naładowania baterii.
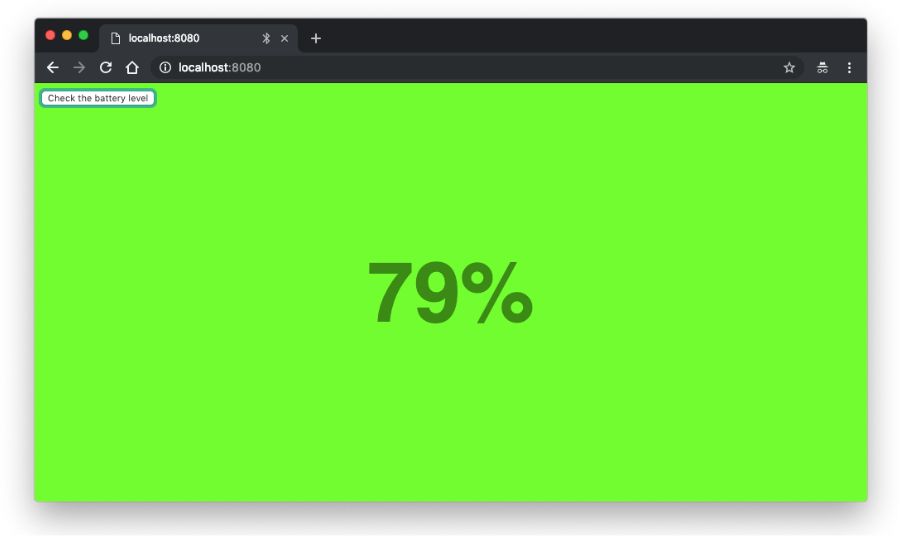
Na obecną chwilę poniższy przykład zadziała tylko w Chrome. Na początek najłatwiej zacząć z emulatorem BLE Peripheral Simulator.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<style>
h1 {
position: absolute;
top: 50%;
left: 50%;
transform: translateX(-50%) translateY(-50%);
margin: 0;
font-size: 20vh;
font-family: Helvetica, sans-serif;
color: #000;
opacity: 0.5;
}
</style>
</head>
<body>
<button id="battery-level">Check the battery level</button>
<h1 id="result"></h1>
<script>
function color(percentage) {
const red = Math.min(2 * 255 * (1 - percentage / 100), 255);
const green = Math.min(2 * 255 * (percentage / 100), 255);
document.body.style.backgroundColor = `rgb(${red}, ${green}, 0)`;
document.querySelector("#result").textContent = `${percentage}%`;
}
async function batteryLevel() {
try {
const device = await navigator.bluetooth.requestDevice({
filters: [{ services: ["battery_service"] }]
});
const server = await device.gatt.connect();
const service = await server.getPrimaryService("battery_service");
const characteristic = await service.getCharacteristic("battery_level");
const value = await characteristic.readValue();
color(value.getUint8(0));
await characteristic.startNotifications();
characteristic.addEventListener("characteristicvaluechanged", async (event) => {
color(event.target.value.getUint8(0));
});
} catch (error) {
alert(error.message);
}
}
document.querySelector("#battery-level").addEventListener("click", batteryLevel);
</script>
</body>
</html>
Przykładowe zastosowanie tej technologii może być ciekawym sposobem na obsługę urządzeń IoT nie wymagającym instalowania dodatkowego oprogramowania na naszym smartfonie. Dostępne są wyspecjalizowane profile urządzeń od zdrowia i sportu do monitorowania rytmu serca (HPR) po generyczne sensory.
Zdjęcie główne artykułu pochodzi z picjumbo.com.
Podobne artykuły

Python podstawy - kursy, tutoriale online - 10 rekomendacji

Data Analytics, Data Science, Machine Learning – co wybrać?

12 wniosków i dobrych praktyk z refaktoryzacji kodu

Nie jesteś przekonany do code review? Oto kilka porad na start
Jak Slack dba o każdego użytkownika? Stosuje accessible technology
6 kroków do przebranżowienia się na programistę. Plan nauki IT

10 rad dla początkujących programistów od seniora
