Elm. Poznaj podstawy i architekturę tego funkcyjnego języka
Elm jest funkcyjnym językiem programowania, który kompilujemy do JavaScriptu. Jego początki sięgają 2012 roku, jednak większą uwagę zaczął zyskiwać dopiero niedawno, wraz z falą ogólnego zainteresowania programowaniem funkcyjnym. Jeśli nie mieliście do tej pory styczności z programowaniem funkcyjnym lub słyszeliście o nim i wydało wam się trudne, niech was to nie odstrasza!
Aby efektywnie używać Elma nie trzeba znać teorii kategorii, język jest tworzony z myślą o łatwym i szybkim starcie również dla początkujących programistów. Cała teoretyczna otoczka wokół programowania funkcyjnego została przekuta w praktyczne elementy języka.

Mateusz Pokora. Programista pasjonat, frontend developmentem zajmuje się od 6 lat. Uwielbia poznawać nowe technologie i języki programowania. Od niedawna szczególnie zainteresowany programowaniem funkcyjnym. Chętnie dzieli się zdobytą wiedzą, aktywnie udzielając się w łódzkiej scenie IT. W życiu prywatnym, lubi muzykę jazzową, tańce swingowe oraz twórczość Terry’ego Pratchetta.
To co odróżnia Elma od innych języków kompilowanych do JS, to główne założenia oraz motywacje, które wpływały na jego konstrukcję. Jeśli spojrzymy na języki takie jak ClojureScript czy ScalaJS, miały one na celu umożliwić tworzenie interfejsu do aplikacji w języku, który już dobrze znamy (język, w którym mamy napisany backend), języku, który ma składnię oraz bibliotekę standardową bogatszą niż sam JavaScript. Elm zastosował jednak zupełnie inne podejście. Zamiast przenosić funkcje innego języka, został on stworzony jako nowy język oparty na składni Haskella, a jego jedynym przeznaczeniem ma być tworzenie interfejsów użytkownika. Co za tym idzie konstrukcje języka są dobrze dopasowane do rozwiązywania problemów, które stawia przed nami frontend, np. tworzenia i edytowania elementów HTML oraz obsługi zdarzeń.
Zaczynając nowy projekt z Elmem dostajemy pełny pakiet pozwalający na efektywną pracę nad aplikacją webową. Porównując to z ekosystemem JS-a byłoby to równoważne z instalacją React, Redux, TypeScript, ImmutableJS, Prettier.
Spis treści
Składnia języka Elm
Składnia Elma została oparta na Haskellu i na pierwszy rzut oka może wydać się toporna. Jednak jej elementy są ograniczane do minimum i szybko można się do nich przyzwyczaić. Jeśli chodzi o formatowanie samego kodu z pomocą przychodzi nam elm-format, który dba za nas o wszelkie szczegóły formatowania. Po napisaniu kawałka kodu zostaną za nas poprawione wszystkie wcięcia i odstępy tworząc bardzo czytelny kod. Formater posiada wbudowaną konfigurację opartą na najlepszych praktykach wyznaczonych przez społeczność, nie mamy możliwości ustalania własnych reguł. Sprawia to iż każdy kod Elma będzie wyglądał tak samo. Nigdy więcej kłótni, który nawias jest najlepszy, lub czy średniki są potrzebne na końcu linii!
doubleEvenValues : List Int -> List Int
doubleEvenValues values =
values
|> List.map
(val ->
if val % 2 == 0 then
val * 2
else
val
)
Kompilator i statyczny system typów
Jedną z najważniejszych korzyści jakie daje nam używanie Elma jest zapewnienie braku runtime exceptions! Czy potrafisz sobie wyobrazić świat bez “null” oraz “undefined is not a function”? Osiem z dziesięciu błędów wymienionych w tym artykule możemy wyeliminować samym posiadaniem kompilatora. Jeśli tylko kod się skompiluje, mamy pewność, że w aplikacji nie zobaczymy żadnego runtime exception. Pozwala nam to znacznie zredukować liczbę testów jednostkowych i ograniczyć je jedynie do sprawdzania poprawności funkcji, bez konieczności sprawdzania przypadków, kiedy do funkcji przekażemy niepoprawne parametry.
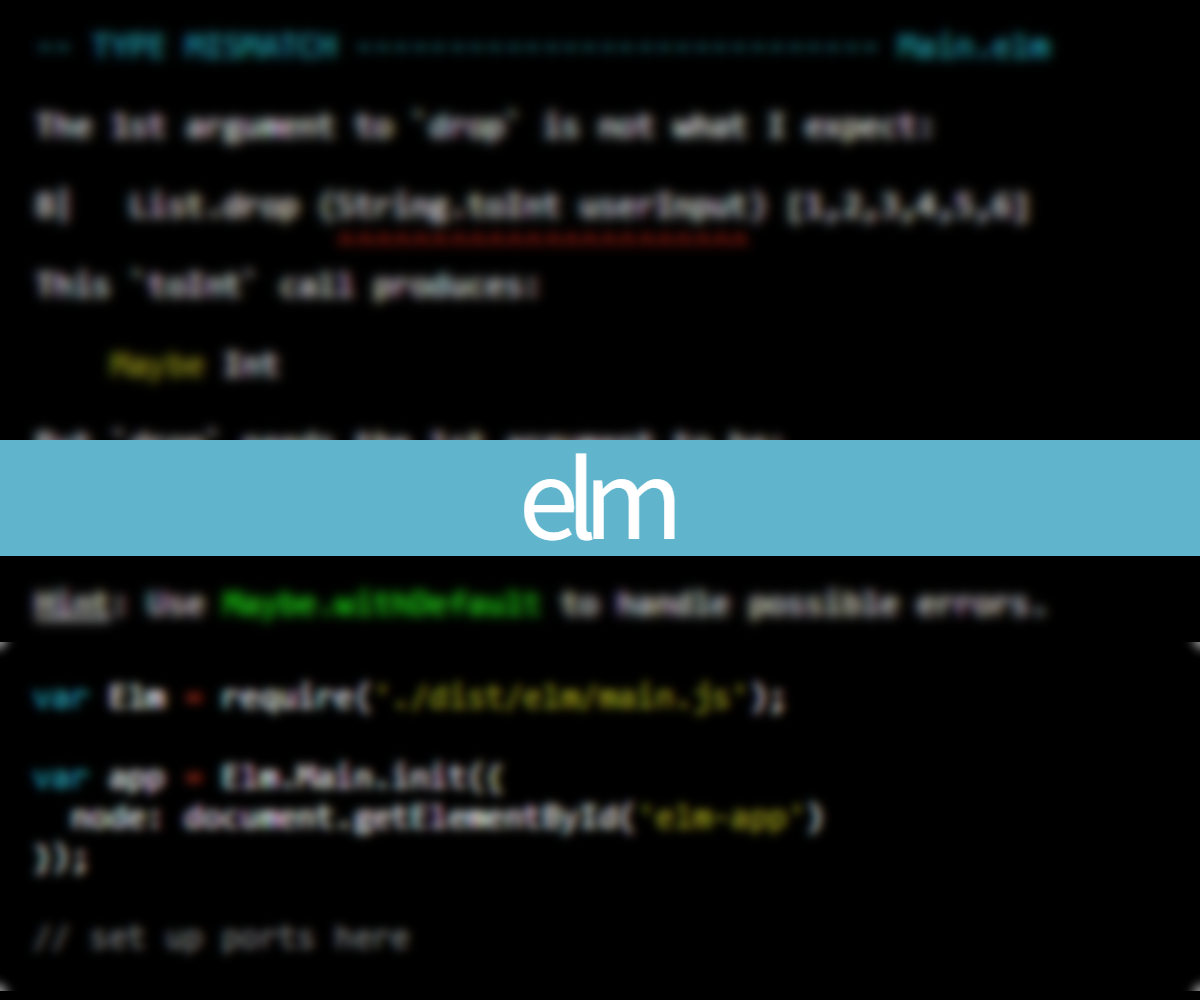
Oprócz szczegółowego sprawdzania poprawności kodu kompilator Elma charakteryzuje się również przyjaznymi wiadomościami dla błędów. Kiedy takowe się pojawią dostajemy wyraźną informację, co i w którym miejscu się popsuło, jak również podpowiedź na temat potencjalnego rozwiązania. Kompilator sprawdza również, czy w instrukcjach warunkowych obsługujemy wszystkie możliwości. Przykładowo dla poniższego kodu, kompilator zwróci nam błąd, informując o nieuwzględnionej możliwości Disabled.
type ButtonState
= Enabled
| Disabled
buttonLabel : ButtonState -> String
buttonLabel buttonState =
case buttonState of
Enabled ->
"Przycisk odblokowany"
-----------------------------
This `case` does not have branches for all possibilities.
43|> case buttonState of
44|> Enabled ->
45|> "Przycisk odblokowany"
You need to account for the following values:
Disabled
Add a branch to cover this pattern!
Niemutowalne struktury danych
Elm posiada niemutowalne struktury danych, to znaczy jeśli raz zdefiniujemy jakiś obiekt lub tablicę, zawartość nie moża zostać zmodyfikowana. Daje nam to gwarancję, że dany element w każdym miejscu w kodzie będzie miał tą samą wartość, którą nadaliśmy mu w momencie utworzenia. Nie ma możliwości, aby do naszej aplikacji wkradły się błędy wynikające z nieumyślnych modyfikacji obiektów w pamięci.
Jeśli mamy potrzebę modyfikacji istniejących struktur możemy to zrobić poprzez utworzenie nowej struktury przepisując wszystkie wartości ze starej oraz nadpisując interesujące nas pola, lub dodając nowy element na koniec tablicy.
array1 = [1, 2, 3, 4] array2 = List.concat [ array1, [5] ]
Pure functions
Tak jak w większości funkcyjnych języków programowania, funkcje w Elmie muszą być ”pure”. Znaczy to, że funkcja wywołana z tym samym argumentem powinna zwrócić nam zawsze taki sam wynik, efekty uboczne powinny być z niej wyizolowane. Weźmy na przykład dwie funkcje:
const add = (a, b) => {
return a + b;
}
const getTime = () => {
return new Date().getTime();
}
Pierwsza funkcja “add” wykonuje proste dodawanie. Niezależnie ile razy i w jakim kontekście wywołamy add(2, 2), wynikiem zawsze będzie 4. Żadne czynniki zewnętrzne nie mogą wpłynąć na wynik dodawania. Sytuacja wygląda inaczej w przypadku drugiego przykładu, funkcji “getTime”. Wynik funkcji jest ściśle zależny od czasu i każde kolejne wywołanie zwróci nam inny wynik. Utrudnia to analizowanie oraz testowanie kodu. Mamy tu do czynienia z tzw. “side effect”, funkcja ma efekt uboczny, komunikuje się ze światem zewnętrznym. Elm wymaga od nas abyśmy wywoływali takie funkcje w bardziej kontrolowany sposób. Zamiast pobierać czas bezpośrednio w naszej funkcji, będzie ona jedynie tworzyła opis efektu, który chcemy wywołać. Następnie taki opis musimy przekazać do Elm runtime, który wykona operacje za nas oraz zwróci rezultat do funkcji update (o której więcej w The Elm Architecture).
init : ( Model, Cmd Msg )
init =
( {}, Time.now |> Task.perform (always NoOp) CurrentTime )
type Msg
= NoOp
| CurrentTime Time.Time
update : Msg -> Model -> (Model, Cmd Msg)
update msg model =
case msg of
CurrentTime time ->
// zapis aktualnego czasu
Współdziałanie z Javascript
Elm posiada również możliwość komunikacji z kodem JS. Dzięki temu możemy bez problemu wypróbować go tworząc pojedynczy widok w istniejącej aplikacji napisanej np. w React. Działa to także w drugą stronę, jeśli cała nasza aplikacja napisana jest w Elmie, w zależności od potrzeb możemy dołączyć do niej i korzystać z bibliotek dostępnych w ekosystemie JS.
The Elm Architecture
Nieodłącznym elementem aplikacji napisanych w Elmie jest The Elm Architecture (TEA). Ci z was, którzy mieli okazję pracować z popularną biblioteką Redux znają już to doskonale, gdyż pomysł został zaczerpnięty właśnie z Elma. Architektura ta dzieli aplikację na trzy główne elementy: Model, View i Update.
Model
Model reprezentuje stan aplikacji. Przechowuje on wszystkie dane potrzebne do wyświetlenia oraz działania aplikacji, na przykład lista użytkowników, którą pobraliśmy z serwera lub wartość pola w formularzu. Aplikacja posiada jeden główny model, co za tym idzie wszystkie dane przechowywane są jako jeden obiekt. Początkowy stan ustawiany jest przez nas, a wszystkie kolejne zmiany mogą zadziać się jedynie w funkcji Update.
type alias Model = {
users : List String
, appTitle : String
}
initialModel = {
appTitle = "Tytuł naszej aplikacji"
, users = []
}
Update
Update jest logiką naszej aplikacji. To funkcja, która definiuje jak aplikacja ma się zachowywać w odpowiedzi na działania użytkownika, przykładowo wciskanie klawiszy, kliknięcia myszką, ale również zdarzenia czasowe (setTimeout, setInterval). Jako dwa argumenty dostajemy zdarzenie oraz aktualny stan aplikacji. Na tej podstawie możemy określić jak powinien wyglądać nowy stan.
update : Msg -> Model -> Model update msg model = case msg of UsersLoaded -> // obsługa załadowania użytkowników UpdateAppTitle -> // obsługa zmiany tytułu
View
Ostatni element, View to nic innego jak wygląd naszej aplikacji, określa on reprezentacje modelu jako HTML i jest częścią widoczną bezpośrednio dla użytkownika. View jest funkcją, która dostanie obiekt aktualnego stanu jako argument i zwraca HTML, który zostanie następnie wyrenderowany przez Elma.
view : Model -> H.Html Msg view model = div [] [ text model.appTitle ]
Elm runtime
Te trzy elementy połączone są ze sobą poprzez runtime Elm-a. Odpowiada on za przesyłanie zdarzeń do Update, a następnie odświeżanie widoku po każdej zmianie stanu. Wygląda to tak:
1. Renderujemy aplikacje na podstawie początkowego stanu.
2. Akcje użytkownika przesyłane są do funkcji Update.
3. Następuje wyliczenie nowego stanu.
4. Po zmianie stanu ponownie renderujemy aplikacje.
Takie podejście ułatwia nam debugowanie aplikacji. Dzięki podziale odpowiedzialności oraz statycznemu typowaniu możemy szybko określić, w której części aplikacji znajduje się poszukiwany problem. Jeśli otrzymujemy niepoprawny stan po jakiejś akcji, mamy błąd w funkcji Update. Jeśli natomiast akcja, którą wysłaliśmy jest inna, niż być powinna będzie to na pewno problem w funkcji View.
Dodatkowo dzięki pojedynczemu, niemutowalnemu obiektowi stanu oraz pojedynczej funkcji Update, jesteśmy w stanie śledzić każdą akcję oraz zmianę stanu, która zachodzi w aplikacji. Ponadto jeśli aktualny stan jest wyliczony na podstawie serii występujących po sobie zdarzeń, mając stan początkowy i zapisane zdarzenie możemy w dowolny sposób odtwarzać je i modyfikować w trakcie działania aplikacji! (tzw. Time travel debugging). Pozwala nam to na monitorowanie zmian krok po kroku i bez konieczności używania debuggera javascript i breakpointów.
Podsumowanie
W tym krótkim artykule starałem się opisać jedynie najważniejsze elementy i korzyści jakie daje nam używanie Elma. Najlepszym sposobem do zapoznania się z resztą jest oczywiście wypróbowanie języka samemu, do czego gorąco zachęcam. Nawet jeśli nie przekona was to do dalszego używania, będzie to na pewno wartościowe chociażby ze względu na ilość elementów funkcyjnego programowania, które przenikają do JS i stają się jego stałą częścią.
Aby wypróbować sam język możemy skorzystać z edytora online, oszczędzi nam to instalacji środowiska lokalnie. Jeśli zdecydujemy się na wypróbowanie projektu na lokalnej maszynie możemy skorzystać z oficjalnego tutoriala. Niezwykle pomocnym miejscem jest również zbiór artykułów, oraz wszelkich innych materiałów dotyczących Elma, prowadzony przez społeczność — https://github.com/isRuslan/awesome-elm.
Źródła:

Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
