Big Data – klęska urodzaju czy złoty Graal? Praktyczne metody wykorzystania potencjału danych

Na rynku przybywa firm, które doceniają znaczenie informacji i znakomicie radzą sobie z gromadzeniem bardzo dużych ilości danych. Niestety, zaskakująco często wyzwaniem okazuje się ich poprawne wykorzystanie. Jak pokonać trudności w zbieraniu i wykorzystywaniu danych?
Big data to pojęcie, które w ostatnich latach zaistniało w świadomości niemal każdej branży, a wykorzystanie informacji do zwiększania konkurencyjności i produktywności firmy coraz częściej znajduje się na liście celów strategicznych. Wiele firm podeszło do gromadzenia danych bardzo poważnie i obecnie znajdują się już w posiadaniu potężnych zbiorów wartościowych danych – jednak nie jest to jednoznaczne z umiejętnością wykorzystania ich potencjału.
Spis treści
Utrudnienia w eksploatacji danych
Współczesne organizacje, które już zgromadziły pokaźne zbiory danych, często napotykają na ścianę, która utrudnia im przekucie informacji w pomocne wnioski i wskazówki służące rozwojowi firmy – wynika to zazwyczaj z braku struktury i organizacji danych na różnych poziomach.
Klęska urodzaju
Jednym z problemów, z którymi mierzą się firmy, jest coś, co można byłoby nazwać klęską urodzaju: biznes posiada wiele źródeł danych, z których wszystkie zawierają podobny zakres informacji, jednak dane są na tyle niespójne, że uniemożliwia to ich poprawne wykorzystanie. Podobnym problemem, który znacząco wpływa na użyteczność danych jest brak udokumentowanej i dostępnej logiki zawartej w surowych danych, albo brak spójnej terminologii i definicji charakterystyk opisujących podstawowe metryki biznesowe.
Kultura organizacji
Inny aspekt, który istotnie obniża potencjalne zyski z posiadanych danych, leży w kulturze organizacji. Jeśli firma nie wymusza potwierdzania podejmowanych decyzji i działań poprzez rzetelną analizę danych, lub też osoby decyzyjne nie posiadają wystarczających umiejętności i odpowiedniej ‘higieny’ pracy z danymi, to można być niemal pewnym, że biznes nie wykorzystuje w pełni możliwości, jakie leżą w jego bazach danych.
Każdy z tych problemów osobno może powodować poważne trudności, a niejednokrotnie firmy zmagają się nawet z kilkoma z nich w tym samym czasie. Im dłużej pozostają nierozwiązane, tym bardziej mogą grozić nieprzyjemnymi konsekwencjami, a nawet utratą przewagi rynkowej na rzecz firm, które w efektywny i wydajny sposób zarządzają i wykorzystują zgromadzone informacje. Brak organizacji danych prowadzi też do nieskoordynowanego lub wzajemnie sprzecznego zrozumienia efektywności i poprawności podejmowanych decyzji, potrzeb klientów czy też kierunku rozwoju rynku, a w efekcie do niespójnych działań podejmowanych przez niezależne jednostki firmy, które w ekstremalnych przypadkach mogą wzajemnie działać na swoją szkodę. Wszystkie te trudności prowadzą ostatecznie do załamania w kulturze organizacji i błędnego koła – problemy skutkują utratą zaufania do danych, a to z kolei prowadzi do pogłębiania dotkliwości wymienionych problemów.

Rozwiązywanie problemów z zarządzaniem danymi
Podstawowym krokiem, który znacząco poprawia sposób, w jaki firma wykorzystuje zgromadzone informacje, jest stworzenie i udostępnienie kompleksowego i łatwo dostępnego modelu danych. Tworzenie strategii rozwoju firmy, rozbudowa czy usprawnienie dostarczanych funkcjonalności produktu i odkrywanie nowych ścieżek pozyskiwania klientów to tylko niektóre z obszarów, które mogą zyskać na wydajnym i efektywnym zarządzaniu zgromadzonymi informacjami. Ponadto wsparcie procesów decyzyjnych poprzez dostarczanie spójnych wniosków biznesowych jest niezbędne dla stworzenia efektywnej strategii i synchronizacji działań w różnych obszarach działalności firmy.
Organizacje, które chcą w pełni wykorzystać potencjał gromadzonych informacji, zredukować czas potrzebny do budowy wniosków biznesowych na podstawie danych i dążą do bycia w pełni data-driven będą zmuszone skupić swoją uwagę na modelowaniu dostępnych informacji. Proces ich gromadzenia i strukturyzacji możemy podzielić na cztery kluczowe etapy, które w istotny sposób pomagają w efektywnej organizacji przepływu danych.
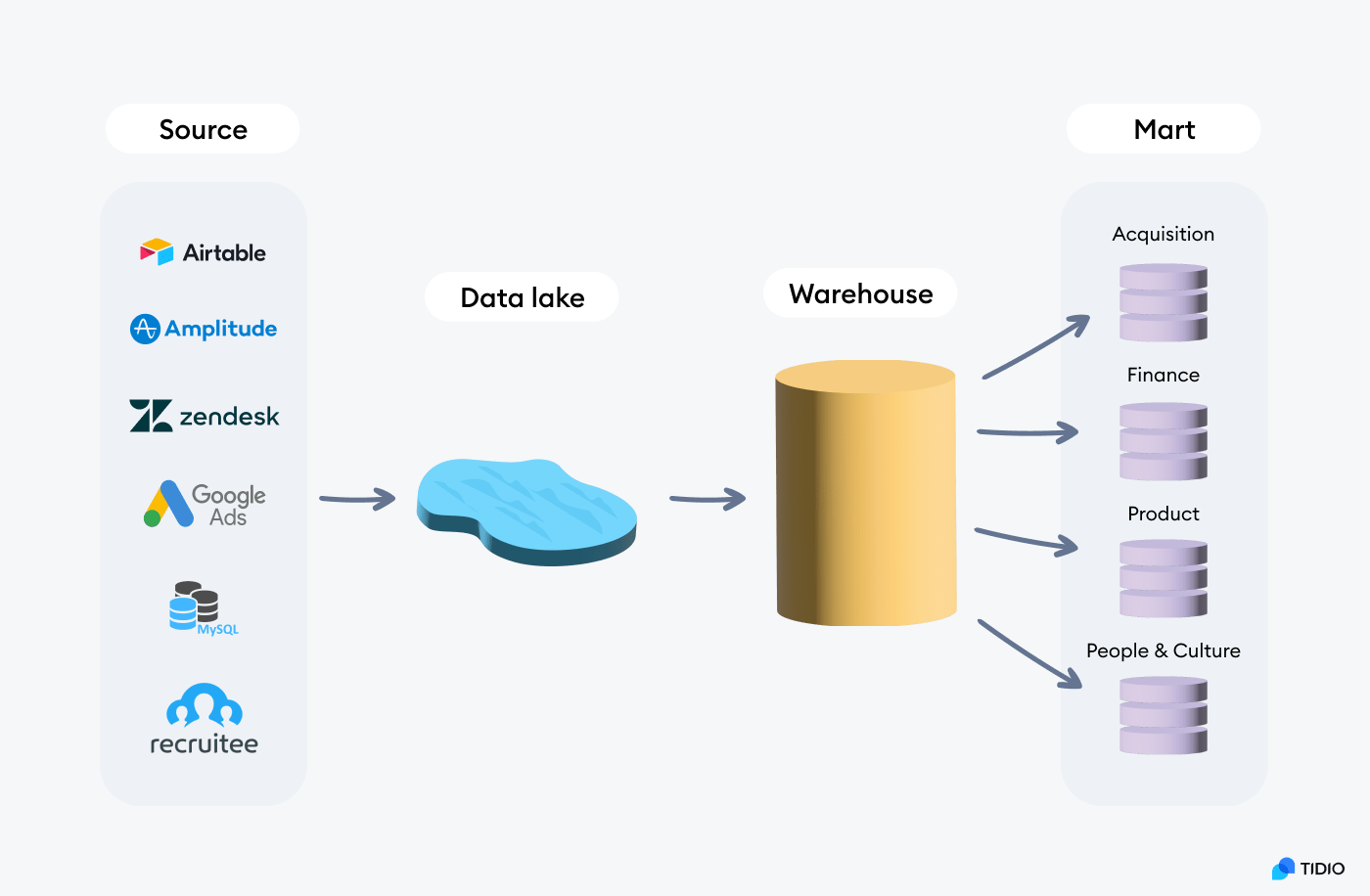
- Data Source: W zależności od typu organizacji i rodzaju świadczonych usług, a także zdefiniowanych potrzeb analitycznych, może istnieć potrzeba użycia rozmaitych źródeł danych. Bardzo często organizacje pozyskują kluczową część danych z bazy produktowej lub bazy transakcyjnej (e.g. MySQL, PostgreSQL). Niejednokrotnie istnieje potrzeba integracji z danymi behawioralnymi (e.g. Amplitude, Mixpanel) czy pozyskania surowych danych dostępnych w wykorzystywanych oprogramowaniach typu SaaS (Software as a service) poprzez stworzenie integracji z API.
- Data Lake: Dla skutecznego zarządzania danymi pozyskanymi z różnych źródeł o niespójnej charakterystyce (tj. zakres i przeznaczenie danych, inna rozdzielczość czasowa, poziom agregacji, zmienność danych w czasie itd.) niezbędne jest miejsce, które umożliwi gromadzenie danych w jednym miejscu. Istotna jest elastyczność środowiska (tj. łatwe zwiększanie ilości dostępnego miejsca), a także możliwość wstępnej strukturyzacji i partycjonowania danych. Warto zaznaczyć, że w ramach Data Lake gromadzi się surowe dane, bez zastosowania jakichkolwiek transformacji po ich ekstrakcji ze źródła w ramach podejścia ‘schema-on-read’.
- Data Warehouse: Zgromadzenie wszystkich danych w etapie Data Lake pozwala na dostęp do niezbędnych informacji z jednolitego interfejsu. Wciąż jednak dane wymagają strukturyzacji schematów, uspójnienia nazw zmiennych i charakterystyk, rozwiązania problemów jakości danych, a także budowy jednolitego i spójnego modelu. Kluczowym celem tego etapu jest scentralizowanie założeń i unifikacja metody liczenia najczęściej wykorzystywanych charakterystyk. Najważniejszą rolą tego etapu jest ułatwienie dostępu do danych dla użytkowników biznesowych bez istotnych doświadczeń w pracy z SQL – zredukowanie potrzeby łączenia, filtrowania i agregacji danych – docelowo budowanie analityki ‘self-service’. W przypadku zmieniających się definicji biznesowych zyskujemy możliwość dostosowania założeń w jednym miejscu i aktualizacji oraz dystrybucji spójnych informacji dla wszystkich użytkowników i aplikacji.
- Data Mart: W wielu przypadkach dobrze ustrukturyzowany i udokumentowany Data Warehouse, który stanowi ‘single source of truth’ jest w stanie zaspokoić potrzeby analityczne wszystkich zespołów w firmie. Często jednak wraz ze wzrostem dostępności i zapotrzebowania, a także świadomości danych, rozmiar Data Warehouse może być przytłaczający dla odbiorców końcowych. Dodatkowo w wielu jednostkach firmy może rodzić się potrzeba wykorzystania dostępnych już danych w odmiennej postaci (specyficznej dla danej jednostki) lub w zestawieniu z innym kompletem danych (które nie mają zastosowania dla pozostałych departamentów). Może to rodzić potrzebę tworzenia dedykowanych przestrzeni analitycznych na potrzeby poszczególnych jednostek firmy.
Każdy ze wskazanych powyżej etapów wymaga wykorzystania odpowiednio dobranych narzędzi, które ułatwiają proces przetwarzania, strukturyzacji, testowania czy też dokumentacji zgromadzonych danych. Na szczególną uwagę zasługuje wydajna implementacja Data Warehouse. Kluczowe kwestie, które należy rozważyć podczas jej projektowania to:
- Wybór narzędzia, które pozwala w efektywny sposób rozwijać, dokumentować oraz testować tworzony model danych. Warte rozważenia jest na przykład DBT.
- Uspójnienie założeń dotyczących struktury projektu, terminologii nazewnictwa obiektów czy też formatowania kodu SQL. Wartościowe źródło wiedzy na ten temat jest dostępne TUTAJ.
- Zadbanie o stworzenie środowiska deweloperskiego, które umożliwia testowanie poprawności wprowadzanych zmian bez zbędnej interakcji z danymi produkcyjnymi.
- Wybór wydajnej i wygodnej formy strukturyzacji danych przeznaczonych dla narzędzia Business Intelligence. Bardzo często spotkać można model wymiarów oraz tabel faktów, a także bazującą na nim strukturę OLAP. W przypadkach dynamicznie zmieniających się wymagań biznesowych oraz potrzeb analitycznych nie zawsze opłacalna może okazać się inwestycja w budowę złożonej struktury danych końcowych. W takich przypadkach rozwiązaniem może okazać się podejście ‘wide table’.
- Z uwagi na różnorodne potrzeby odbiorców końcowych dla analityki BI, niejednokrotnie wymagana jest swoboda w zakresie końcowej modyfikacji danych przez analityków BI. Wykorzystywane narzędzia BI są w naturalny sposób zdolne do wdrożenia takich modyfikacji, ale bardzo często modyfikacja danych na poziomie SQL jest znacznie mniej pracochłonna. Dla narzędzi BI warto więc udostępniać dane w formie widoku.
- Widoki z których korzysta analityka BI, bazujące na wcześniej już przygotowanych tabelach w Data Warehouse nie mają istotnych problemów z wydajnością. W przypadku bardzo dużych zbiorów danych, pomocna może się okazać materializacja widoku jako widok zmaterializowany lub tabela.
- Szczególne wątpliwości może budzić wydajność zapytań generowanych przez narzędzia BI w przypadku wykorzystania podejścia ‘wide table’ w porównaniu do struktury OLAP. W zestawieniu z coraz częściej wykorzystywanymi bazami danych (Snowflake, Bigquery) podejście ‘wide table’ może okazać się do 25-50% szybsze od standardowo wykorzystywanego modelu wymiarów i tabel faktów. (https://www.fivetran.com/blog/star-schema-vs-obt).
Podsumowanie
Modelowanie danych i ich organizacja to temat rozległy, nieco przytłaczający i wymagający dużego nakładu planowania i pracy – jednak ignorowanie konieczności przeprowadzenia tego procesu bardzo często jest głównym źródłem problemów, z którymi zmagają się organizacje na swojej drodze do pełnej dojrzałości. Dlatego inwestycja zasobów w dobrą, przemyślaną strukturyzację i modelowanie dostępnych danych niemal zawsze zwróci się firmie z nawiązką.

Podobne artykuły
Podejście do zmniejszania kosztów przetwarzania danych na przykładzie Azure Databricks

Data management, data governance i data modernization - jak okiełznać proces zarządzania danymi w organizacji
Dane 1,3 mln użytkowników Clubhouse do pobrania? To nie wyciek, to data scraping

Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Migracja do chmury? Wypełnij ankietę i sprawdź, jak wygląda ten proces u innych!

Analiza infrastruktury i danych IoT. Wybór bazy

Kiedy warto wdrożyć grafową bazę danych?
