Alternatywa dla JMeter, czyli testowanie wydajności z Locust. Cz.2

W poniższym artykule chciałbym zilustrować korzyści z napisania testu obciążeniowego w Pythonie, którego wygoda umożliwia zarówno przygotowanie danych do testu, jak i analizę wyników.

Oleksii Ostapov. Software Test Lead w Infopulse. Absolwent National Aviation University Kiev na kierunku Informatyka. Ma ponad jedenaście lat doświadczenia w branży IT, w tym ponad pięć lat jako QA trainer, a ponad dwa lata na stanowisku Test Leada. Oleksii posiada certyfikat ISTQB, jest także autorem tekstów eksperckich firmowego bloga. Pierwszą część artykułu o Locust znajdziesz pod tym adresem.
Spis treści
Obsługa odpowiedzi serwera
Czasami w testach wydajnościowych nie wystarczy jedynie otrzymać 200 OK z serwera HTTP; konieczne jest też sprawdzenie treści odpowiedzi, aby upewnić się, że serwer pod obciążeniem wysyła prawidłowe dane lub wykonuje prawidłowe obliczenia. W takich przypadkach Locust oferuje możliwość skonfigurowania kryteriów pomyślnej odpowiedzi. Posłużę się następującym przykładem:
from locust import HttpLocust, TaskSet, task
import random as rnd
class UserBehavior(TaskSet):
@task(1)
def check_albums(self):
photo_id = rnd.randint(1, 5000)
with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response:
if response.status_code == 200:
album_id = response.json().get('albumId')
if album_id % 10 != 0:
response.success()
else:
response.failure(f'album id cannot be {album_id}')
else:
response.failure(f'status code is {response.status_code}')
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
Powyższy przykład ma pojedyncze żądanie mające na celu utworzenie obciążenia zgodnie z następującym scenariuszem:
Na serwer o losowym id wysłano żądania dotyczące obiektów zdjęć w przedziale od 1 do 5000. Sprawdzany jest identyfikator albumu w tych obiektach przy założeniu, że jest niepodzielny przez 10.
Możemy tu zastosować kilka wyjaśnień:
- konstrukcja z request () jako odpowiedzią: można zastąpić response = request () do pracy z obiektem odpowiedzi.
- Adres URL tworzony jest zgodnie ze składnią formatu ciągu; funkcja ta została dodana do Pythona 3.6, — f’/photos/{photo_id}’. Konstrukcja taka nie istnieje w poprzednich wersjach!
- new argument catch_response=True, dla Locust oznacza to, że sami określimy czym jest pomyślna odpowiedź serwera. W przeciwnym razie nadal otrzymamy obiekt odpowiedzi i będziemy mogli przetwarzać jego dane, ale nie będziemy w stanie z góry ustalić wyników testu. Dalej mamy szczegóły przykładu.
- jeszcze jeden argument, name=’/photos/[id]’, jest niezbędny do grupowania żądań w statystykach. W nazwie można zastosować dowolny tekst, nie musimy powtarzać adresu URL. Bez tego każde żądanie z unikalnym adresem lub parametrami będzie rejestrowane jako osobny zapis statystyczny. Działa to w następujący sposób:
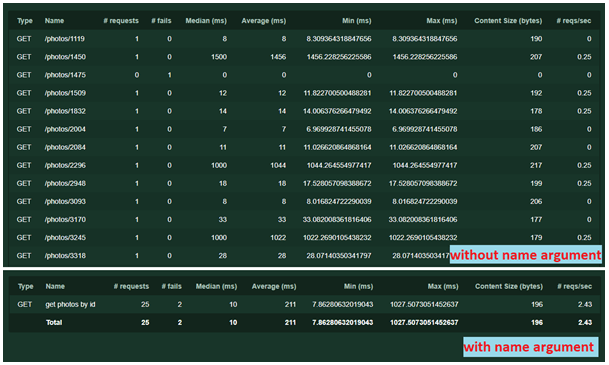
Za pomocą tego argumentu można wykonać inną sztuczkę — czasem jeden serwis z różnymi parametrami (np. z inną treścią żądań POST) charakteryzuje się inną logiką. Aby uniknąć pomieszanych wyników testu, można napisać kilka zadań, podając dla każdego oddzielną nazwę argumentu.
Następnie czas na kontrolę. Poniżej zaprezentowano dwa procesy. Na początku sprawdziłem, czy serwer zwraca nam odpowiedź: if response.status_code == 200:
Jeśli odpowiedź jest prawidłowa, sprawdzam, czy identyfikator albumu jest podzielny przez 10. Jeśli nie, odpowiedź tą oznaczamy jako pomyślną: response.success().
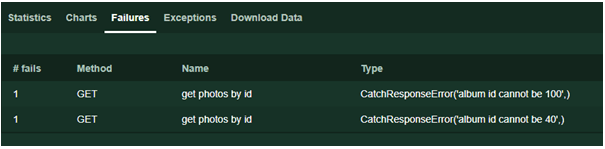
W innych przypadkach zwróciłem uwagę na przyczynę niepowodzenia: response.failure („opis błędu”). Poniższy tekst wyświetlany jest na stronie Awarie podczas przeprowadzania testu.
Uważni czytelnicy mogą zauważyć brak obsługi wyjątków (Wyjątki), co jest typowe w kodzie działającym z interfejsami sieciowymi. W przypadku przekroczenia limitu czasu, błędu połączenia i innych nieoczekiwanych wyjątków Locust przetwarza je samodzielnie i zawsze zwraca obiekt odpowiedzi, ustawiając kod statusu odpowiedzi na 0.
Jeśli kod generuje Wyjątki, zapisują się one w zakładce Wyjątki podczas testu, abyśmy mogli to sprawdzić. Najbardziej typowa sytuacja występuje, gdy odpowiedź json nie zwraca oczekiwanej wartości, ale już wykonujemy/wykonaliśmy dane działania.
Zanim przejdziemy dalej, chciałbym zauważyć, że używam serwera json do zilustrowania przykładów, ponieważ w ten sposób łatwiej obsługiwać odpowiedzi. Niemniej w ten sam sposób możemy pracować z HTML, XML, FormData, załączonymi plikami i innymi danymi wykorzystywanymi przez protokoły wykorzystujące HTTP.
Praca ze skomplikowanymi scenariuszami
Prawie za każdym razem, gdy aplikacja sieci Web ma być poddana testom obciążenia, szybko staje się jasne, że nie można wszystkiego dokładnie uwzględnić za pomocą GET, gdzie dane są po prostu zwracane.
Klasyczny przykład: w celu przetestowania sklepu internetowego żąda się, aby użytkownik:
1. Otworzył główną stronę sklepu.
2. Szukał towaru.
3. Kliknął w szczegóły produktu.
4. Dodał produkt do koszyka.
5. Zapłacił.
Z przykładu jasno wynika, że wywoływanie usług w losowej kolejności jest niemożliwe i można to zrobić tylko w odpowiedniej kolejności. Co więcej, towary, koszyk i metoda płatności mogą mieć unikalne identyfikatory dla każdego użytkownika.
Na poprzednim przykładzie można zauważyć, że małe aktualizacje mogą ułatwić nam przeprowadzenie testu takiego scenariusza. Dostosujmy przykład do naszego serwera testowego:
1. Użytkownik pisze nowy post.
2. Użytkownik pisze komentarz pod nowym postem.
3. Użytkownik czyta komentarz.
from locust import HttpLocust, TaskSet, task
class FlowException(Exception):
pass
class UserBehavior(TaskSet):
@task(1)
def check_flow(self):
# step 1
new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'}
post_response = self.client.post('/posts', json=new_post)
if post_response.status_code != 201:
raise FlowException('post not created')
post_id = post_response.json().get('id')
# step 2
new_comment = {
"postId": post_id,
"name": "my comment",
"email": "test@user.habr",
"body": "Author is cool. Some text. Hello world!"
}
comment_response = self.client.post('/comments', json=new_comment)
if comment_response.status_code != 201:
raise FlowException('comment not created')
comment_id = comment_response.json().get('id')
# step 3
self.client.get(f'/comments/{comment_id}', name='/comments/[id]')
if comment_response.status_code != 200:
raise FlowException('comment not read')
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
W tym przykładzie dodałem nową klasę FlowException. Po każdym kroku (jeśli został wykonany w nieoczekiwany sposób) uruchamiam tę klasę wyjątków, aby zakończyć scenariusz — jeśli utworzenie postu jest niemożliwe, nie ma nic do skomentowania itp. Konstrukcję można zastąpić zwykłym zwrotem, ale w tym przypadku w trakcie testów i analizy wyników, w zakładce Wyjątków nie zostanie wyraźnie ukazane, gdzie dokładnie nie powiódł się wykonany scenariusz. Dlatego właśnie poza konstrukcją raczej unikam używania tej opcji.
Wiarygodność obciążenia
Można powiedzieć, że w powyższym przykładzie sklepu internetowego wszystko jest w istocie linearne, ale przykład z postami i komentarzami jest lekko naciągany — posty są czytane co najmniej 10 razy częściej, niż są pisane. To rzeczywiście rozsądne spostrzeżenie, więc przystosujmy ten przykład bardziej do prawdziwego życia. Mamy co najmniej dwa podejścia:
- „Hardcoding” listy postów czytanych przez użytkowników i upraszczanie kodu tekstowego, jeżeli jest to możliwe i jeśli funkcja zaplecza nie jest zależna od konkretnych postów.
- Zapisywanie utworzonych postów i czytanie ich, jeśli nie jest możliwe określenie listy postów lub jeśli realistyczne ładowanie krytycznie zależy od tego, które posty są czytane (Usunąłem komentarze z przykładu, aby kod zajmował mniej miejsca i był bardziej przejrzysty)
from locust import HttpLocust, TaskSet, task
import random as r
class UserBehavior(TaskSet):
created_posts = []
@task(1)
def create_post(self):
new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'}
post_response = self.client.post('/posts', json=new_post)
if post_response.status_code != 201:
return
post_id = post_response.json().get('id')
self.created_posts.append(post_id)
@task(10)
def read_post(self):
if len(self.created_posts) == 0:
return
post_id = r.choice(self.created_posts)
self.client.get(f'/posts/{post_id}', name='read post')
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
Utworzyłem listę created_posts w klasie UserBehavior. Należy pamiętać, że jest to obiekt, który nie był tworzony w konstruktorze klasy __init__(). W związku z tym, w przeciwieństwie do sesji użytkownika, powyższa lista jest wspólna dla wszystkich użytkowników. Pierwsze zadanie tworzy post i zapisuje jego id na liście. Drugie ma zwiększoną 10 razy częstotliwość i czyta jeden losowo wybrany post z listy. Dodatkowy warunek dla drugiego zadania to sprawdzenie, czy utworzono niektóre posty.
Jeśli każdy użytkownik ma obsługiwać własne dane, można je zdefiniować w konstruktorze w następujący sposób:
class UserBehavior(TaskSet):
def __init__(self, parent):
super(UserBehavior, self).__init__(parent)
self.created_posts = list()
Dodatkowa funkcjonalność
Aby konsekwentnie uruchamiać zadania, oficjalna dokumentacja sugeruje użycie adnotacji zadań @seq_task(1), określając w argumencie numer zadania
class MyTaskSequence(TaskSequence):
@seq_task(1)
def first_task(self):
pass
@seq_task(2)
def second_task(self):
pass
@seq_task(3)
@task(10)
def third_task(self):
pass
W powyższym przykładzie każdy użytkownik wykonuje najpierw first_task, następnie second_task, a potem third_task 10 razy.
Bardzo przypadła mi do gustu ta funkcja, ale w przeciwieństwie do poprzednich przykładów, w razie konieczności przeniesienie wyników z pierwszego do drugiego zadania jest niejasne.
Innej funkcji można użyć w przypadku bardzo skomplikowanych scenariuszy. Umożliwia to tworzenie osadzonych zestawów zadań — tworzenie kilku klas TaskSet i łączenie ich.
from locust import HttpLocust, TaskSet, task
class Todo(TaskSet):
@task(3)
def index(self):
self.client.get("/todos")
@task(1)
def stop(self):
self.interrupt()
class UserBehavior(TaskSet):
tasks = {Todo: 1}
@task(3)
def index(self):
self.client.get("/")
@task(2)
def posts(self):
self.client.get("/posts")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
W powyższym przykładzie scenariusz Todo zostanie uruchomiony z prawdopodobieństwem od 1 do 6 i będzie wykonywany, dopóki nie zostanie przerwany przez scenariusz UserBehavior z prawdopodobieństwem od 1 do 4. Kluczową rolę odgrywa tutaj self.interrupt(), ponieważ jeśli go zabraknie, test utknie w podzadaniu.
Dziękuję za uwagę. W ostatnim artykule na ten temat skupię się na testach rozproszonych i testowaniu bez interfejsu użytkownika. Omówię także trudności napotkane podczas testowania za pomocą Locust oraz jak je przezwyciężyć. Bądź na bieżąco!
Artykuł został przetłumaczony za zgodą autora, pierwotnie opublikowany na infopulse.com.
Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
