Alternatywa dla JMeter, czyli testowanie wydajności z Locust. Cz.1

Nie ma zbyt wielkiego popytu na testy wydajnościowe, dlatego nie są aż tak popularne, jak inne techniki testowania oprogramowania. Na rynku znajdziemy niewiele narzędzi do przeprowadzania takich testów, a już na pewno ciężko będzie o te proste i wygodne.

Oleksii Ostapov. Software Test Lead w Infopulse. Absolwent National Aviation University Kiev na kierunku Informatyka. Ma ponad jedenaście lat doświadczenia w branży IT, w tym ponad pięć lat jako QA trainer, a ponad dwa lata na stanowisku Test Leada. Oleksii posiada certyfikat ISTQB, jest także autorem tekstów eksperckich firmowego bloga.
Gdy mowa o testowaniu wydajności, pierwsze na myśl przychodzi narzędzie JMeter – niewątpliwie najbardziej znane narzędzie z największą liczbą wtyczek. Jeśli o mnie chodzi, nigdy nie lubiłem JMeter ze względu na nieprzyjazny interfejs i wysoką krzywą uczenia, z którą trzeba się mierzyć za każdym razem, gdy trzeba przetestować coś bardziej skomplikowanego niż aplikacja „Hello World”.
Zainspirowany pomyślnymi testami przeprowadzanymi w ramach dwóch różnych projektów, chciałbym opisać stosunkowo proste i wygodnie oprogramowanie — Locust, czyli z angielskiego „szarańcza”.
Spis treści
Czym jest Locust?
Locust to narzędzie testowe open-source, które tworzy scenariusze obciążenia przy użyciu Pythona oraz obsługuje obciążenie rozproszone, a według autorów używane jest też w testach obciążenia Battlelog dla serii gier Battlefield (które natychmiast pokochasz).
Zalety:
- Prosta dokumentacja, w tym przykładowe kopiuj-wklej. Testy można rozpocząć, mając jedynie podstawowe umiejętności programowania.
- Wykorzystywanie biblioteki requests (dla ludzi HTTP). Dokumentację można wykorzystać jako szczegółowy monit do debugowania testów.
- Obsługa Pythona — po prostu preferuję ten język.
- Poprzedni element umożliwia wykorzystywanie różnych platform do uruchamiania testów.
- Dedykowany serwer WWW w Flask do prezentacji wyników testów.
Wady:
- Brak funkcji „Capture & Replay” – sterowanie całkowicie ręczne.
- Dlatego właśnie cały czas trzeba myśleć. Podobnie jak w przypadku korzystania z Postmana, niezbędna jest znajomość mechanizmów HTTP.
- Wymagane są wtedy podstawowe umiejętności programowania.
- Model obciążenia liniowego — natychmiastowe rozczarowanie dla fanów generowania obciążenia „według Gaussa”.
Proces testowania
Każdy proces testowania jest złożonym zadaniem wymagającym szczegółowego planowania, przygotowania, kontroli wydajności i analizy wyników. Przy testach wydajnościowych konieczne jest zebranie wszystkich danych (w miarę możliwości), które mogą wpłynąć na wynik:
- Serwery sprzętowe (CPU, RAM, ROM);
- Serwery oprogramowania (OS, wersja serwera, JAVA, .NET i inne, baza danych i ilość danych, serwery i przetestowane dzienniki aplikacji);
- Szerokość pasma;
- Serwery proxy, load balancery i osłona DDOS;
- Dane testowania wydajności (liczba użytkowników, średni czas odpowiedzi, ilość zapytań na sekundę).
Opisane poniżej przykłady można sklasyfikować jako testy wydajności funkcjonalnej black-box. Możemy mierzyć wydajność nie posiadając nawet informacji o testowanej aplikacji oraz bez dostępu do dzienników.
Przed uruchomieniem
Do sprawdzenia testów wydajności w praktyce wykorzystałem lokalny, prosty serwer WWW. Zaprezentujemy na nim prawie wszystkie poniższe przykłady. Pobrałem dane serwera z przykładu dostępnego online. Do uruchomienia niezbędny jest nodeJS.
Oczywisty spoiler: eksperymenty z testowaniem wydajności lepiej przeprowadza się lokalnie i bez usług obciążenia online, żeby nie dostać bana.
Do uruchomienia potrzebny jest Python – we wszystkich przykładach użyję wersji 3.6 i samego Locusta (w chwili pisania tego artykułu – wersja 0.9.0). Można przeprowadzić instalację wpisując następujące polecenie:
python -m pip install locustio
Szczegóły instalacji opisano w oficjalnej dokumentacji.
Analiza przykładu
Potrzebujemy też pliku testowego. Zaczerpnąłem bardzo prosty i przejrzysty przykład z dokumentacji:
from locust import HttpLocust, TaskSet
def login(l):
l.client.post("/login", {"username":"ellen_key", "password":"education"})
def logout(l):
l.client.post("/logout", {"username":"ellen_key", "password":"education"})
def index(l):
l.client.get("/")
def profile(l):
l.client.get("/profile")
class UserBehavior(TaskSet):
tasks = {index: 2, profile: 1}
def on_start(self):
login(self)
def on_stop(self):
logout(self)
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000
Powyższy kod wystarczy do rozpoczęcia testu! Przeanalizujmy powyższy przykład, zanim przejdziemy do samego testowania.
Pomijając początkową część „importowania”, widzimy dwie niemal identyczne funkcje logowania i wylogowania w jednej linii. l.client to obiekt sesji HTTP, którego użyjemy do utworzenia obciążenia. Użyjemy metody POST, prawie takiej samej jak biblioteka requests. „Prawie”, gdyż w tym przykładzie jako pierwszy argument nie wpisujemy adresu URL pełnej ścieżki, ale tylko jego część, tj. dany serwis.
Dane są przesyłane jako drugi argument i muszę przyznać, że słowniki Pythona to spore ułatwienie, ponieważ są automatycznie konwertowane na json.
Warto również zauważyć, że nie przetwarzamy wyniku żądania — jeśli się powiedzie, wyniki (np. pliki cookie) zostaną zapisane w tej sesji. Błąd zostanie zarejestrowany i dodany do statystyki obciążenia.
Jeśli chcemy sprawdzić poprawność naszego żądania, jest na to prosty sposób:
import requests as r
response=r.post(base_url+”/login”,{“username”:”ellen_key”,”password”:”education”})
print(response.status_code)
Dodałem tylko zmienną base_url, która musi zawierać pełny adres testowanego zasobu.
Następne kilka funkcji to żądania tworzące obciążenie. Tutaj też nie ma potrzeby przetwarzania odpowiedzi serwera — wyniki natychmiast pojawią się w statystykach.
Następnie mamy klasę UserBehavior (można dowolnie nazwać klasę). Jak sama nazwa wskazuje, klasa ta opisuje zachowanie użytkownika sferycznego w próżni testowanej aplikacji. Właściwość zadań zaczerpniemy ze słownika metod wywoływanych przez użytkownika, a także częstotliwości wywołań. Chociaż nie znamy uruchamianych przez każdego użytkownika funkcji ani ich kolejności (wybór losowy), możemy zagwarantować, że funkcja indeksu będzie wywoływana średnio dwa razy częściej niż funkcja profilu.
Oprócz opisu zachowania klasa macierzysta TaskSet umożliwia przypisanie czterech funkcji, które można wykorzystać przed i po testach. Kolejność wywoływań będzie następująca:
- setup wywoływany raz przy starcie UserBehavior (TaskSet)/span> – nie podano w przykładzie.
- on_start wywoływany raz przez każdego nowego użytkownika wywołującego obciążenie na początku pracy.
- tasks to wykonywanie samych zadań.
- on_stop jest wywoływany raz przez każdego użytkownika po zakończeniu pracy testu.
- teardown jest wywoływany raz po zakończeniu pracy TaskSet – również nie podano w tym przykładzie.
Warto przypomnieć, że istnieją dwa sposoby określenia zachowania użytkownika: pierwszy wymieniono w poprzednim przykładzie – funkcje określone z góry. Natomiast drugi sposób to określenie metod w klasie UserBehavior:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
self.client.post("/login", {"username":"ellen_key", "password":"education"})
def on_stop(self):
self.client.post("/logout", {"username":"ellen_key", "password":"education"})
@task(2)
def index(self):
self.client.get("/")
@task(1)
def profile(self):
self.client.get("/profile")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000
W tym przykładzie funkcje użytkownika i ich częstotliwość wywoływania ustawiane są przez adnotację zadania. Pod względem funkcjonowania nic się nie zmieniło.
Ostatnia klasa podana w tym przykładzie to WebsiteUser (można dowolnie nazwać klasę). W tej klasie ustawiamy model zachowania użytkownika UserBehavior oraz minimalny i maksymalny czas oczekiwania między wywołaniami poszczególnych zadań każdego użytkownika. Dla wyjaśnienia możemy to zwizualizować w następujący sposób:
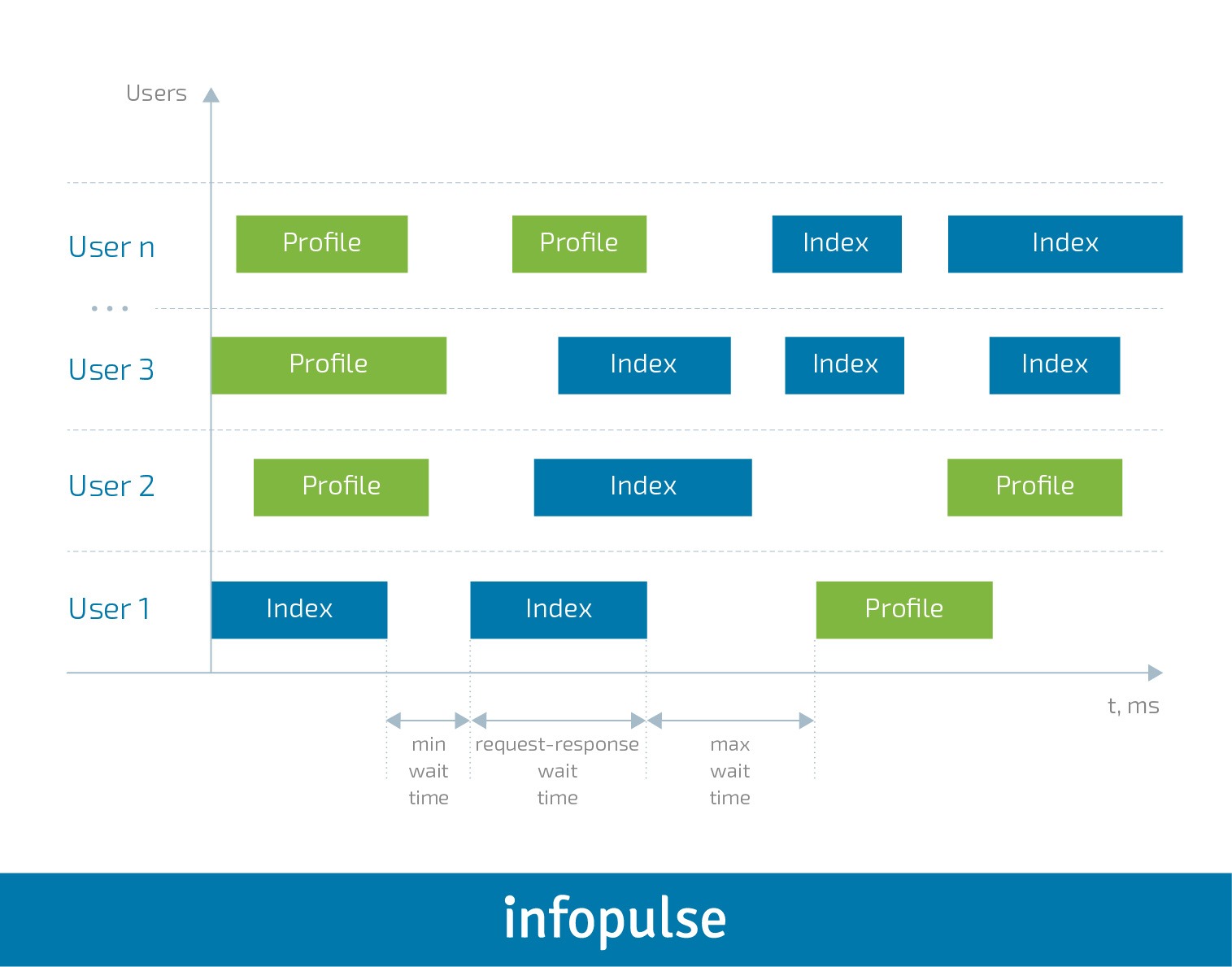
Rozpoczęcie testów
Funkcja „Uruchom serwer” jest wciąż w fazie testów:
json-server --watch sample_server/db.json
Zmodyfikujmy też przykładowy plik, aby odpowiadał testowanemu serwisowi. Logujemy, wylogowujemy się i ustawiamy zachowanie użytkownika:
- Po rozpoczęciu pracy otwórz stronę główną.
- Otrzymaj listę wszystkich postów х2.
- Skomentuj pierwszy post х1.
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
self.client.get("/")
@task(2)
def posts(self):
self.client.get("/posts")
@task(1)
def comment(self):
data = {
"postId": 1,
"name": "my comment",
"email": "test@user.habr",
"body": "Author is cool. Some text. Hello world!"
}
self.client.post("/comments", data)
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
Wpisz następujące polecenie do uruchomienia w wierszu polecenia:
locust -f my_locust_file.py --host=http://localhost:3000
host jest tutaj adresem testowanego zasobu. Adresy serwisu określone w teście posłużą jako uzupełnienie.
Jeśli w teście nie wystąpią żadne błędy, serwer obciążenia uruchomi się i będzie dostępny pod adresem http://localhost:8089/.
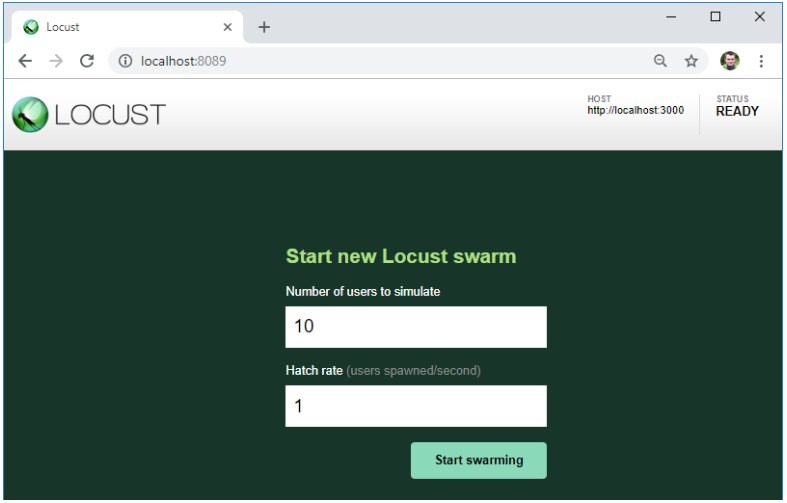
Jak widać, wymieniony jest testowany serwer, a adresy z pliku testowego dodaliśmy do tego konkretnego adresu URL.
Tutaj możemy również ustawić liczbę użytkowników potrzebnych do stworzenia obciążenia, a także ich przyrost na sekundę.
Rozpocznij test, klikając przycisk „Rozpocznij swarming”.

Wyniki
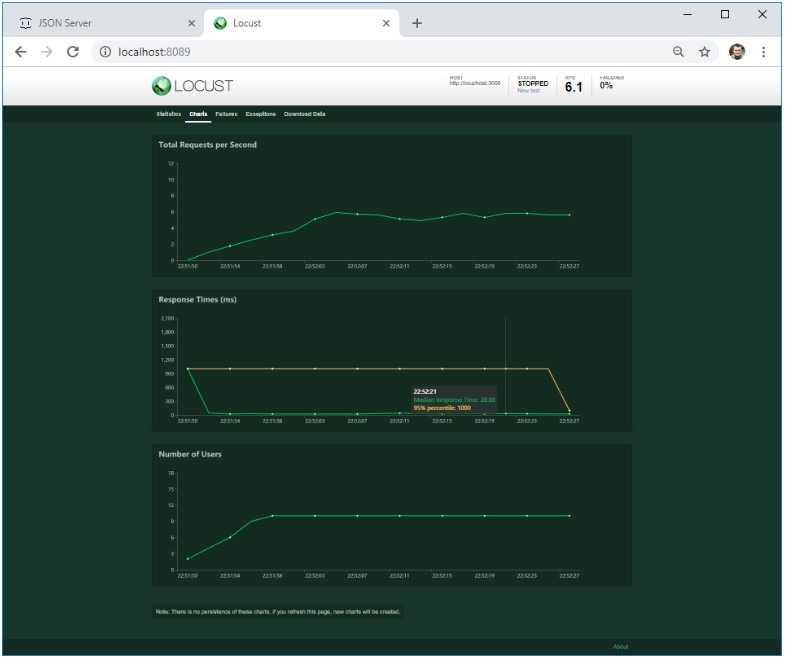
Po pewnym czasie zatrzymajmy test i spójrzmy na pierwsze wyniki:
- Zgodnie z oczekiwaniami, każdy z 10 utworzonych użytkowników już na samym początku wyświetlił się na stronie głównej.
- Lista postów była otwierana średnio dwa razy częściej niż pisano komentarze.
- Mamy również dostęp do średniej i mediany czasu reakcji dla każdego działania oraz liczby operacji na sekundę, co już stanowi przydatną informację, którą można wykorzystać do porównania rzeczywistej wydajności z oczekiwanym wynikiem.
W drugiej zakładce znajdują się wykresy ładowania w czasie rzeczywistym. Jeśli serwer padnie pod określonym obciążeniem lub zmieni się jego zachowanie, zostanie to natychmiast uwzględnione na wykresie.
Trzecia zakładka ukazuje błędy. W moim przypadku jest to błąd klienta. Jeżeli jednak serwer zwróci błędy 4ХХ lub 5ХХ – ich tekst zostanie tutaj zapisany.
Błędy w kodzie tekstowym zostaną przeniesione do zakładki Wyjątki. Jak dotąd mój najczęściej popełniany błąd związany jest z poleceniem print () w kodzie — nie jest to najlepsza technika logowania.
Ostatnia zakładka pozwala nam załadować wszystkie wyniki testu w formacie CSV.
Czy te wyniki są istotne? Zastanówmy się. Najczęściej wymagania dotyczące wydajności (jeśli w ogóle są) obejmują mniej więcej: średni czas ładowania strony (odpowiedź serwera), który musi być krótszy niż N sekund pod obciążeniem M użytkowników, bez określania działania użytkowników. I za to właśnie lubię naszego Locusta — tworzy aktywność określonej liczby użytkowników, którzy w losowej kolejności wykonują czynności tak, jak normalni użytkownicy.
Jeśli konieczne jest przeprowadzenie testu porównawczego, tj. w celu zmierzenia zachowania systemu pod różnymi obciążeniami, można utworzyć kilka klas zachowania i przeprowadzić kilka testów pod różnymi obciążeniami.
Na razie to w zupełności wystarczy. Jeśli spodobał ci się ten artykuł, w najbliższej przyszłości planuję kolejny post na temat:
- skomplikowanych scenariuszy testowych, w których wyniki pierwszego etapu wykorzystywane są w kolejnych etapach;
- przetwarzania odpowiedzi serwera, gdyż może być niepoprawna nawet przy HTTP 200 OK;
- nieoczywistych komplikacji, które mogą wystąpić oraz jak je przezwyciężyć;
- testowania bez interfejsu użytkownika;
- rozproszonych testów wydajnościowych.
Artykuł został przetłumaczony za zgodą autora, pierwotnie opublikowany na infopulse.com. Zdjęcie główne artykułu pochodzi z burst.shopify.com.
Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
