Wszystko zaczyna się od Engineering Capacity. Testy wydajnościowe w chmurze

Jak powszechnie wiadomo programiści nie przepadają za testowaniem i najchętniej skończyliby swoją przygodę z tą materią na poziomie testów jednostkowych. Zapewnienie jakości nie zaczyna i nie kończy się jednak na tym poziomie. Testy wydajnościowe to obszerna grupa testów – rozpoczniemy więc od zapoznania się z dwoma najpopularniejszymi ich rodzajami, czyli testami load test oraz stress test.
Jak zwykle wszystko zaczyna się od myślenia i dokumentacji. Na początku warto zadać sobie pytanie: – „co właściwie powinno zostać przetestowane?”. Oczywiście jest to bardzo ogólne pytanie i w zależności od poziomu testowania odpowiedź może, a nawet powinna być inna. Na etapie testów wydajnościowych uwaga skupia się na badaniu systemu, jako całości. W związku z tym, że są one typowymi testami czarnoskrzynkowymi, nie sprawdza się odrębnie działania każdego z modułów.
Wszystkie przemyślenia, a właściwie ich finalny rezultat powinny zostać udokumentowane w postaci pliku o nazwie test plan. Warto jednak przy tej okazji spojrzeć w inny równie ważny artefakt, jakim jest test strategy, aby nasze zamiary nie odbiegały znacząco od ogólnie przyjętej, najczęściej na poziomie organizacji, strategii testowania oprogramowania.
Spis treści
System bankowości online, czyli nasz SUT
Załóżmy, że mamy do przetestowania system bankowości online. Takie rozwiązanie udostępnia bardzo szeroki wachlarz funkcjonalności, wymaga integracji wielu niezależnych systemów, tworząc przy tym skomplikowaną wewnętrzną architekturę. Wprowadźmy więc pewne uproszczenie – nasz SUT (ang. System Under Test) będzie obsługiwał logowanie do bankowości elektronicznej, umożliwiał pobranie historii wybranego konta oraz zlecenie przelewu. Kolejnym ułatwieniem, będzie potraktowanie wszystkich innych podsystemów i architektury, jako czarnych skrzynek, z którymi komunikujemy się poprzez API.
Upraszczanie jest dość częstą praktyką, ponieważ podczas testowania nie zawsze można skorzystać z prawdziwych modułów – na przykład: kiedy część z nich dostarczana jest przez zewnętrznego dostawcę, nie są jeszcze dostępne na środowiskach testowych, czy też spotykamy się z innymi ograniczeniami sprzętowymi, czy finansowymi. Wyobraźmy sobie system, w którym pewne dane zapisywane są zdalnie na chipie fizycznego urządzenia, a całe rozwiązanie musi obsłużyć kilka milionów operacji na sekundę.
Oczywiście nikt nie będzie testował na tak ogromną skalę, a nawet ograniczone, przeprowadzenie rzetelnych testów wymagałoby dostępu do przynajmniej kilkuset egzemplarzy wspomnianego urządzenia. Jest to oczywiście nieopłacalne z ekonomicznego i logistycznego punktu widzenia.
Rozwiązaniem jest programowe symulowanie takich elementów. Stąd zazwyczaj podczas testów wydajnościowych operuje się na emulowanych urządzeniach klienckich oraz podmodułach. Podsystemy same w sobie mogę mieć również rozbudowaną architekturę i mogą korzystać z zasobów innych systemów zależnych, które dla naszego SUT są po prostu nie widoczne.
W takim przypadku nie pozostaje nam nic innego jak stworzenie elementów mock, wybranych modułów oraz ich interakcji z testowanym systemem. Tutaj z pomocą przychodzą różnego rodzaju narzędzia, jednym z nich może być SoapUI – za pomocą, którego bez większego problemu zasymulujemy API – może zostać wygenerowane na podstawie WSDL lub też stworzone manualnie. Nic nie stoi na przeszkodzie, aby napisać coś podobnego samodzielnie, jednak wykorzystanie gotowego i sprawdzonego narzędzia zaoszczędzi czas oraz pozwoli uniknąć innych potencjalnych problemów.
Poniższy rysunek przedstawia przykładową, bardzo uproszczoną strukturę hipotetycznego systemu bankowego, który będzie testowany w dalszej części. SUT to typowy backend wystawiający dwa rodzaje API: jedno dla użytkowników indywidualnych, drugie dla operatorów komercyjnych, którzy mogą mieć dostęp do zasobów klienta, dzięki dyrektywie PSD2. Z drugiej strony aplikacja z wykorzystaniem asynchronicznego API łączy się z dwoma wewnętrznymi systemami oraz jednym zewnętrznym. W naszych testach podsystemy te będą symulowane.
Struktura testowanego systemu – SUT
Środowiskiem uruchomieniowym będzie chmura. Z perspektywy testowania, w dużym uproszczeniu oczywiście, warto pamiętać o tym, że bez względu na wybranego dostawcę, konfiguracja taka charakteryzuje się automatycznym skalowaniem oraz występowaniem wielu identycznych instancji danej aplikacji, połączonych przez load balancer. Mimo że z zewnątrz taka architektura jest typową czarną skrzynką, należy mieć cały czas z tyłu głowy, że system w rzeczywistości składa się z wielu instancji, co trzeba wziąć pod uwagę chociażby podczas sprawdzania logów, czy też określania przepustowości całego rozwiązania, ale o tym za chwilę.
Generowanie obciążenia w testach wydajnościowych
Kolejnym elementem niezbędnym do wykonania testów wydajnościowych jest obciążenie (ang. load) generowane przez zapytania odbierane API wystawiane na świat. Wykonanie testów z udziałem prawdziwych użytkowników jest praktycznie niemożliwe, ich działania muszą zostać, więc zasymulowane. Na rynku dostępnych jest wiele darmowych, jak i komercyjnych narzędzi umożliwiających generowanie obciążenia, symulując przy tym zachowania prawdziwych użytkowników.
Sprawdzi się tutaj wcześniej już wymieniony SoapUI, ale nie wypada zapomnieć o kultowym już, znienawidzonym przez niektórych, programie JMeter. Oba narzędzia posiadają UI, który ułatwi pracę podczas przygotowywania symulacji oraz wspierają uruchamianie poprzez wiersz poleceń, co z pewnością docenią osoby, które chciałby przeprowadzać automatycznie uruchamiane testy w procesie CI/CD. Obok tak popularnych narzędzi jak SoapUI i JMeter, warto wspomnieć o mniej popularnych, ale niezwykle funkcjonalnych rozwiązaniach jak komercyjny Tricentis, czy darmowy Gatling – coś dla sympatyków języka Scala.

Będąc przy temacie generowania ruchu użytkowników, warto zastanowić się jak statystycznie będzie wyglądała taka aktywność. Najprościej mówiąc należy dobrać odpowiednie proporcje wszystkich możliwych operacji. Częstą praktyką jest stosowanie różnych proporcji w różnych testach. Warto przygotować tzw. Traffic Mix, czyli predefiniowane profile ruchu sieciowego różniące się proporcją możliwych zapytań. Oprócz tego, że znacząco ułatwi to sam proces testowania, da również wszystkim zainteresowanym ten sam poziom zrozumienia.
Przygotujmy przykładowy profil, patrząc na to bardziej praktycznie, na przykładzie naszego SUT. Nasz mini system obsługuje 3 operacje: logowanie, pobieranie historii oraz wykonanie przelewu. Załóżmy, że jeden statystyczny użytkownik loguje się do aplikacji zazwyczaj raz, kilkukrotnie przegląda historię i zleca 2-3 przelewy. W tym przypadku w takim profilu przeważać powinny operacje związane z wyświetlaniem historii, następnie związane z przelewami, kończąc na pojedynczym logowaniu – przykład przedstawiono poniżej.
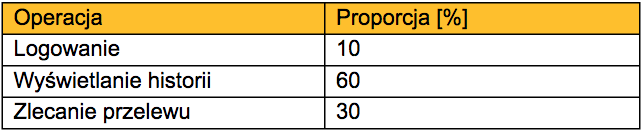
Przykładowy profil sieciowy – Traffic Mix
W praktyce oznacza to, że jeśli podczas testów ma zostać wygenerowanych 100k operacji to 10k będą to operacje logowania, 60k wyświetlania historii, a 30k to zlecenia przelewu. Projektując test warto zastanowić się, ilu użytkowników chcemy zasymulować i dobrać ilość generowanych zapytań adekwatnie do ich liczby. Oczywiście powyższy profil nie obsługuje wszystkich możliwych przypadków, warto wziąć po uwagę to, że proporcje operacji mogą się zmieniać w zależności od regionu, godziny, dnia tygodnia, czy nawet konkretnej daty – odczuwają to dla przykładu operatorzy komórkowi w noc sylwestrową, kiedy to wykorzystanie sieci jest znacząco wyższe.
Nie należy też przesadzić z ilością profili Traffic Mix, ponieważ zbyt duża ilość może zamiast pomóc, wprowadzić problemy z doborem odpowiedniego profilu do testu i wprowadzić jeszcze większy chaos. Wskazane jest podejście zdroworozsądkowe, definiując nie mniej i nie więcej profili niż potrzeba. Jeśli praca wykonywana jest na istniejącym systemie warto spojrzeć w statystyki zapytań. W przypadku nowotworzonych rozwiązań jest to nieco trudniejsze zadanie – tutaj z pomocą przychodzi szacowanie lub też próba skorzystania z doświadczeń innych, podobnych rozwiązań.
Projektując rozwiązania chmurowe zaleca się, aby zasoby wykorzystywane przez pojedynczą instancję aplikacji były ograniczone do najniższego możliwego poziomu. Absolutne minimum to ustawienie limitu wykorzystania CPU, pamięci instancji oraz wielkości JVM Heap memory. Takie ograniczenia wspierają łatwiejsze skalowanie całego rozwiązania. Przed przystąpieniem do testów warto ustalić z zespołem developerskim oraz specjalistami DevOps, jakie wartości będą adekwatne dla testowanego systemu. Testy powinny zostać wykonane z wykorzystaniem najmniejszym możliwym zestawem wyżej wymienionych parametrów, zwłaszcza podczas wyznaczania tzw. EC, ale o tym za moment.
… bo wszystko zaczyna się od EC
Zanim przystąpimy do wykonania właściwych testów wydajnościowych należy wyznaczyć tzw. Engineering Capacity (EC). Jest to pewnego rodzaju wskaźnik, który będzie wskazywał nam nominalne parametry działania systemu. Mówiąc jeszcze inaczej określamy próg, po przekroczeniu którego nasz architektura może zacząć działać niestabilnie, mogą pojawiać się błędy, zmniejszy się jego przepustowość itd. Zanim przystąpimy do wykonania testów EC trzeba się zastanowić, które parametry są kluczowe dla jego poprawnego działania, nie można tutaj zapomnieć o wymaganiach biznesowych. Przykładem parametrów nominalnych EC dla systemu bankowego wspomnianego wyżej może być liczba jednocześnie zalogowanych użytkowników wykonujących operacje zgodnie z Traffic Mix.
Kolejnym krokiem jest wyznaczenie elementów, które będą monitorowane oraz będą informować o tym, że rozwiązanie zaczyna działać niestabilnie – załóżmy, że dla systemu bankowego będzie to przepustowość, mierzona w liczbie zapytań na sekundę. Dodatkowo zawsze warto monitorować obciążenie procesora oraz wykorzystanie pamięci RAM. Niezbędnym w tym przypadku parametrem jest współczynnik błędów, przedstawiający procentowo, ile zapytań użytkowników zakończyło się błędem lub nie zostało przetworzonych (np. zakończonych przez timeout). Zawsze warto wykonać kilka testów, aby mieć, co najmniej 3 próbki, które mogą zostać uśrednione, oczywiście pod warunkiem, że wyniki poszczególnych testów znacząco nie odbiegają od siebie.
Testy EC, jak wszystkie inne testy wydajnościowe powinny rozpocząć się od tzw. rozgrzewania systemu, czyli uruchomienia aplikacji oraz wygenerowania ruchu do naszego systemu, po to, aby zbliżyć się do stanu, w którym system będzie znajdował się podczas normalnego działania. W uproszczeniu chodzi o to, aby nie testować aplikacji bezpośrednio po jej uruchomieniu, kiedy to np. JVM zużywa dużo więcej zasobów, czy też niektóre stany aplikacji nadal mają przypisaną wartość początkową. Test w takich warunkach po prostu nie ma sensu, ponieważ zachowanie aplikacji w momencie startu może być inne niż jej zachowanie w warunkach produkcyjnych. Tak, więc, rozgrzewanie należy wykonywać przed każdym pojedynczym wykonaniem przypadku testowego, aby nie zaburzyć wiarygodności wyników.
Pojawia się kluczowe pytanie jak określić EC systemu pracującego w chmurze, który może się automatycznie skalować – otóż odpowiedź nie jest prosta i jednoznaczna. Zależy to tak naprawdę od zasobów, z których możemy skorzystać podczas testów, które niestety zazwyczaj są ograniczone. W takim przypadku pozostaje nam wykonania testu z wykorzystaniem jednej instancji, wykonanie testów skalowalności, a następnie określenie jak zmienia się EC podczas skalowania rozwiązania. Załóżmy, że nasz system będzie składał się minimalnie z 3 instancji, tak więc EC wyznaczone zostanie dla klastra składającego się z 3 identycznych instancji.
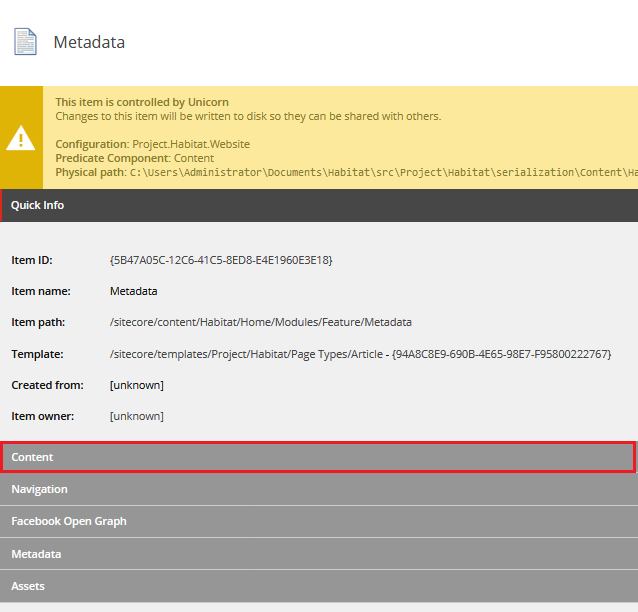
Wykonanie testów EC to dopiero połowa sukcesu. Kluczowe jest tutaj zinterpretowanie otrzymanych wyników oraz wybranie nominalnych wartości wybranych parametrów, w zakresie których system działa stabilnie. Poniżej zaprezentowano przykładowe wyniki testów, oczywiście czysto hipotetyczne, jak cały nasz badany system. EC takiego rozwiązania zostanie wyznaczone poprzez skorelowanie wartości dwóch parametrów – liczby jednoczesnej liczby użytkowników oraz współczynnika błędów, pozostałe pomiary to pola pomocnicze.
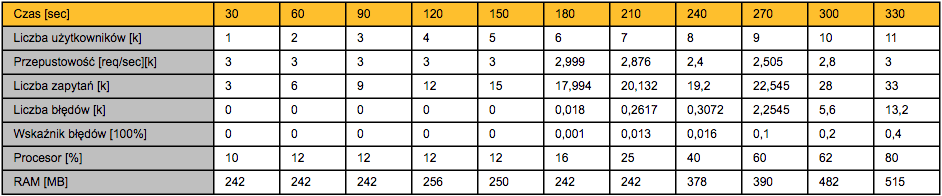
Przykładowe wyniki testów EC
Przykładowe wyniki testu EC systemu bankowego
Z powyższego wykresu wynika, że system zaczyna działać niestabilnie, gdzie definicją niestabilności jest tutaj wzrastająca liczba błędów, w 210 sekundzie testów. Można więc przyjąć, że 7k użytkowników to EC naszego systemu. Oczywiście jest to pewne uproszczenie, w rzeczywistości trzeba wykonać kilka dodatkowych testów zwiększając ich precyzję – dla powyższego oznacza to bardziej drobnoziarniste sprawdzenie zachowania aplikacji, gdy liczba użytkowników oscyluje w zakresie 6k – 8k użytkowników, tak aby określić wartość nominalną jak najdokładniej.
Na tym etapie przyjmijmy, że 7k użytkowników to EC dla naszego hipotetycznego systemu bankowego składającego się z 3 instancji. Co możemy, a nawet powinniśmy, dalej zrobić z tą informacją – wykorzystać jako ustawienie nominalne do kolejnych testów.
Wydajność pod lupą, czyli słów kilka na temat load i stress test
Load test jest to rodzaj testu, w którym sprawdzamy, jak system zachowuje się w warunkach normalnego, spodziewanego obciążenia, czyli nie przekraczającego wartości, dla których aplikacja została zaprojektowana, inaczej mówiąc – jej Engineering Capacity. Sam load test nie różni się tutaj znacząco od testu obciążenia wykonanego dla klasycznych aplikacji.
Jedyną różnicą jest fakt istnienia kilku jednakowych instancji danego systemu, które koniec końców są traktowane jak czarna skrzynka, ponieważ ruch sieciowy obsługiwany jest przez jeden interfejs wejściowy. Test rozpoczynamy do rozgrzewania środowiska, powiedzmy 15 minutowego, a następnie przystępujemy do testu właściwego. Ile powinien trwać sam test?
Zależy to od wielu czynników, ale generalnie im dłużej tym lepiej. Osobiście, o ile to możliwe, wybieram rozwiązanie, w którym, krótki test wykonywany jest po każdym dostarczeniu kodu do gałęzi deweloperskiej w systemie kontroli wersji, następnie codziennie w nocy wykonywany jest test 8h, a raz w tygodniu – w weekend – test trwający 48h.
Test uznajemy za zakończony sukcesem, jeśli po określonym czasie nasza aplikacja nadal działa, w jego trakcie żadna z instancji nie została ponownie uruchomiona, nie wygenerowała niespodziewanego błędu, zapytania zostały obsłużone w niemalże w 100%, a logi nie zawierają znaczących błędów.
Kolejną grupa testów to stress test, czyli testy bardzo zbliżone do wcześniej opisywanych testów obciążeniowych – różnica jest minimalna, ale jak dość znacząca. Otóż zwykły load test wykonywany jest dla parametrów nominalnych (EC), stress test natomiast sprawdza natomiast zachowanie systemu, kiedy próg ten zostaje przekroczony i jest wyższy niż Engineering Capacity. Celem tego testu jest sprawdzenie czy zostaną wygenerowane spodziewane błędy, jednocześnie zapewniając ich prawidłową obsługę oraz czy nie następni jego niespodziewane wyłączenie.
Są różnego rodzaju podejścia do tego rodzaju testów. Ja zazwyczaj wybieram rozwiązanie, w którym generowane obciążenie zwiększa się stopniowo, przekraczając EC nawet trzykrotnie, osiągając 300% wartości nominalnych. Sytuację wzorcową, a można by było wręcz powiedzieć idealną, przedstawia poniższy wykres.
Wzorcowy przebieg zmiany obciążenia stress test
Warto zwrócić uwagę, że poziom zapytań docierających do naszego systemu, a tak naprawdę ich liczbę symulowana przez generator obciążenia, przez pewien czas, nawet kilka godzin, pozostaje na określonym poziomie i to właśnie w tych przedziałach powinno zbierać się logi i dane do dalszej obróbki. Taki test powinien trwać kilka godzin, idealnie 24-48h, zmieniając wartość obciążenia co kilka godzin – oczywiście tempo zmian powinno być dostosowane do dynamiki testowanej aplikacji. Przy tej okazji warto przyjrzeć się aplikacji Gatling, która oferuje funkcjonalność dynamicznej zmiany liczby zapytań w czasie trwania testu.
Poniższy rysunek przedstawia przykładowy rozkład obciążenia, który można byłoby wykonać na naszym SUT, czyli mikrosystemie bankowym. EC zwiększa się stopniowo o 10%, co 4h, finalnie osiągając wartość 300EC po 48 godzinach trwania testu.
Charakterystyka obciążania testu Stress Test trwającego 48h
Podsumowanie
Zrozumienie oraz prawidłowe przeprowadzenie testów wydajnościowych jest kluczowe dla wykonania dalszych testów, ponieważ wiele z nich opiera się na procedurze i rezultatach load test. Przykładem mogą być chociażby HA, czyli high availability, których celem jest sprawdzenie jak system zareaguje na niespodziewane wyłączenie jednego lub kilku jego elementów podczas obsługiwania ruchu. W praktyce taki test rozpoczyna się od powtórzenia kroków z procedury load test oraz losowe wyłączanie instancji aplikacji. To już jednak temat na odrębny artykuł.
Zdjęcie główne artykułu pochodzi z unsplash.com.

Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
