Co każdy developer powinien wiedzieć o Kubernetesie?

Kubernetes jako technologia i ekosystem od wielu lat rozwija się bardzo dynamicznie. Wiele firm zaczyna wykorzystywać go w rozwijanych przez siebie projektach i produktach. Coraz częściej też znajomość tej technologii jest wymagana przez pracodawców od potencjalnych kandydatów w procesach rekrutacyjnych. Istnieje zatem spora szansa, że Kubernetes pojawi się również – a może i już się pojawił – w Twoim projekcie i będziesz wchodził z nim w interakcję w codziennej pracy.
Ten artykuł jest kierowany przede wszystkim do developerów, którzy chcą otrzymać garść najważniejszych informacji o Kubernetesie. W kilku miejscach wprowadzone są celowe uproszczenia, by ułatwić zrozumienie bez wchodzenia w mniej istotne szczegóły. Mam nadzieję, że lektura da podstawowe pojęcie jak funkcjonuje ta platforma, jak skutecznie z niej korzystać, jakich pułapek unikać i po co ona w ogóle istnieje.
Spis treści
Infrastruktura: Czym jest klaster Kubernetesa?
Wyjaśnienie funkcjonowania Kubernetesa jako warstwy abstrakcji nałożonej na infrastrukturę najlepiej rozpocząć od przyjrzenia się następującemu przykładowi. Przed rozpowszechnieniem się konteneryzacji, do przygotowania infrastruktury używano zwykle wirtualizacji. W tym podejściu fizyczna maszyna zmieniana jest w jedną lub więcej maszyn wirtualnych. Każda z tych maszyn stanowi środowisko, na którym uruchomiona jest aplikacja.
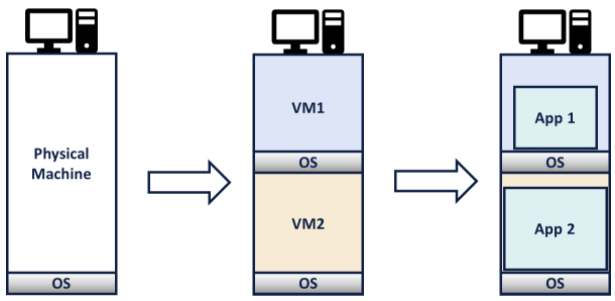
To podejście miało wiele zalet, jednak skupmy się na wadach. Przede wszystkim, każda maszyna wirtualna potrzebuje własnego systemu operacyjnego. System ten zużywa zasoby takie jak CPU, RAM czy pamięć trwała (storage), które mogłyby zostać wykorzystane przez aplikację. VM-ki potrzebują stosunkowo dużo czasu, by się uruchomić i zrestartować. Dodatkowo, każda maszyna musi być skonfigurowana pod uruchomioną na niej aplikację, co utrudnia migrowanie aplikacji pomiędzy maszynami.
Odpowiedzią na większość z tych wad stała się konteneryzacja. W tym podejściu, środowisko wykonawcze jest spakowane razem z aplikacją do tak zwanego obrazu, który jest traktowany jak artefakt. Obraz jest szablonem, który może zostać uruchomiony jako kontener. Jedną z istotnych różnic jest to, że kontenery korzystają z systemu operacyjnego hosta i nie potrzebują tworzenia nowego systemu dla każdego środowiska. Pozwala to na zmniejszenie wykorzystania zasobów przez OS-a. Jedynym wymogiem jest zainstalowanie tzw. container runtime-u, czyli – najczęściej – Dockera.
Dzięki wprowadzeniu konteneryzacji można bezpiecznie uruchamiać wiele aplikacji na jednej maszynie. Kontenery są od siebie wyizolowane („nie wiedzą” o istnieniu innych kontenerów) i zawierają swoje środowisko, przez co dodatkowa konfiguracja maszyny nie jest potrzebna. Dzięki temu przygotowanie infrastruktury może wyglądać następująco:
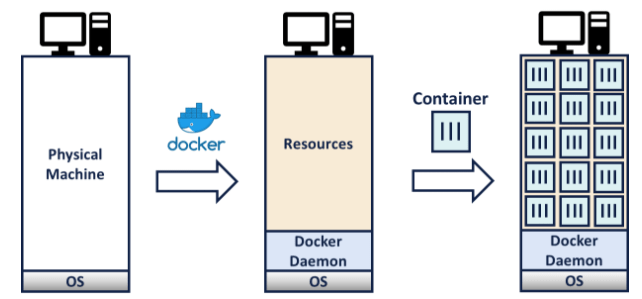
Konteneryzacja zwiększa dynamikę wdrażania aplikacji i upraszcza rozwijanie architektury mikroserwisowej, jednak stawia jednocześnie nowe wyzwania. W jaki sposób monitorować stan kilkudziesięciu czy kilkuset uruchomionych kontenerów? Jak zarządzać środowiskami, konfiguracją aplikacji i sekretami? Jak rozwiązać problemy ze storagem i networkingiem w przypadku kilku maszyn, na których uruchomione są kontenery, które muszą się ze sobą komunikować?
Problemy te rozwiązuje orkiestrator kontenerów – system automatyzujący wdrażanie, zarządzanie i skalowanie skonteneryzowanych środowisk. Najpopularniejszym orkiestratorem jest właśnie Kubernetes. Według jego nazewnictwa, wszystkie należące do niego zasoby tworzą klaster. Maszyny należące do tego klastra nazywa się node-ami – bez względu na to czy są fizyczne czy wirtualne. Co najmniej jeden z tych node-ów jest wyróżniony – nazywamy go masterem i to on będzie odpowiedzialny za zarządzanie Kubernetesem.
Aby dołączyć nową maszynę do klastra, instaluje się na niej aplikację o nazwie kubelet, która jest agentem pozwalającym na uruchamianie kontenerów na danej maszynie. Kubelet rejestruje node-a w klastrze i informuje mastera o stanie tego node-a. Razem z kubeletem node musi mieć zainstalowanego Dockera lub innego container runtime-a. Ilustracje poniżej prezentują klaster w najbardziej ogólnej reprezentacji (po lewej) i w nieco dokładniejszej szczegółowości (po prawej).
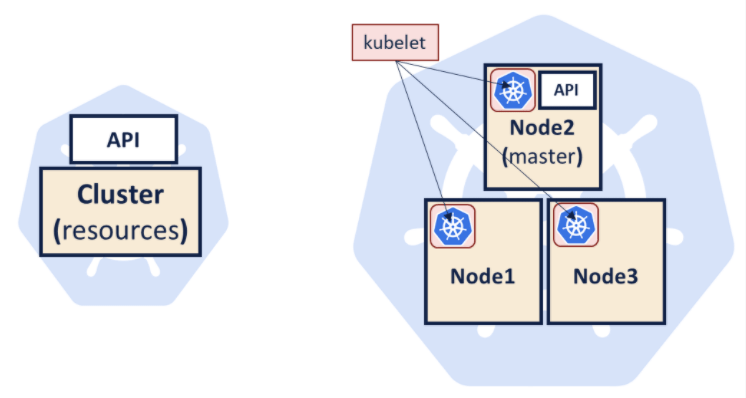
W większości przypadków model poglądowy klastra może przypominać ten po lewej. W codziennej pracy będziemy wchodzić w interakcję z API (kube-api), które jest rozpięte nad zasobami zredukowanymi do abstrakcyjnego „klastra”. Z punktu widzenia developera, nie jest istotne jakie maszyny należą do klastra i ile ich jest. Jeśli w klastrze znajduje się wystarczająco dużo zasobów, aplikacja zostanie na nim uruchomiona. Zanim przejdziemy do opisu komunikacji z Kubernetesem poprzez API, przyjrzyjmy się samemu uruchamianiu aplikacji.
Runtime: W jaki sposób aplikacje są uruchamiane?
Podstawową jednostką, którą można uruchomić na Kubernetesie jest pod. W najprostszym przypadku pod składa się z jednego kontenera i metadanych właściwych dla Kubernetesa. W bardziej zaawansowanych zastosowaniach pod może składać się z kilku kontenerów – zwykle jeden z nich jest wtedy główną aplikacją, a reszta go wspomaga (są to tak zwane sidecar-y).
Cykl życia poda jest analogiczny do cyklu życia kontenera. Jest instancjonowany, działa przez pewien czas, po czym kończy działanie. Jedną z najważniejszych funkcjonalności Kubernetesa jest umiejętność utrzymania stałej liczby podów mimo ich „śmiertelnej” natury. Funkcjonalność ta jest dostarczana przez inny zasób zwany ReplicaSet i obudowujący go zasób Deployment.
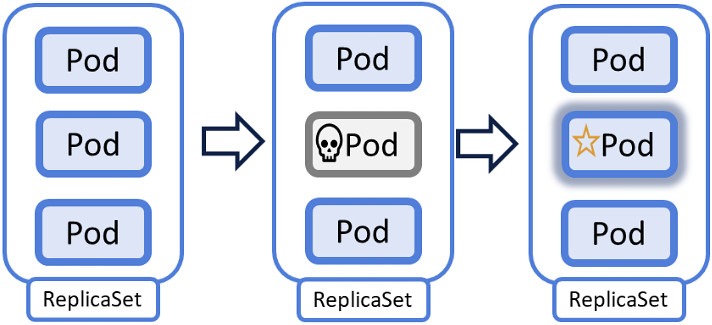
Zadanie ReplicaSet-u jest stosunkowo proste. Obserwuje liczbę replik danego poda i gdy ta odbiega od założonego stanu, uruchamia nowe pody lub terminuje je. ReplicaSet pracuje zatem w ciągłym cyklu obserwacji i dostosowywania stanu faktycznego do stanu zadeklarowanego. Cykl ten nazywa się reconciliation loop albo self-healing loop.
Jednym z częstych nieporozumień wśród osób zaczynających przygodę z Kubernetesem jest próba usunięcia poda, która kończy się ponownym jego uruchomieniem właśnie poprzez działanie ReplicaSet-u. Sposobem na permanentne usunięcie poda jest usunięcie kontrolującego go ReplicaSet-u i Deploymentu – o ile ten drugi istnieje. Funkcjonowanie cyklu ReplicaSet-u obrazuje ilustracja poniżej. Gdy jeden z podów przestanie działać (środkowy obrazek), na jego miejsce powstanie nowa replika.
Deklaratywna natura Kubernetesa ma wiele zalet, na przykład można wdrożyć nową wersję aplikacji poprzez zmianę definicji Deploymentu. Domyślne zachowanie Kubernetesa sprowadzi się do wykonania tak zwanego Rolling Update-u czyli aplikacje starej wersji będą jedna po drugiej wyłączane a te z nowej wersji będą uruchamiane stopniowo. Zapewnia to płynne wdrożenie nowej wersji bez downtime-u.
Wartą wspomnienia kwestią jest konfigurowanie kontenerów uruchomionych w podach. Obrazy, które startujemy w podach są artefaktami, które powinny być uruchamialne na każdym środowisku. Specyficzna dla danego środowiska konfiguracja może być przechowana na Kubernetesie w postaci zasobu ConfigMap. Jest to lista par klucz:wartość, która może być wstrzyknięta do kontenera podczas uruchamiania. Należy zauważyć, że credentiale, tokeny, certyfikaty i inne sekrety powinny być przechowane w analogicznym do ConfigMap-y zasobie Secret, który również można podłączyć do poda podczas jego uruchamiania.
Powyższe omówienie funkcjonowania aplikacji na Kubernetesie powinno wystarczyć do dobrego startu w pracy z tą technologią. Ostatnim aspektem wymagającym wyjaśnienia jest jak z Kubernetesem „rozmawiać”.
Komunikacja: Jak obsługiwać Kubernetesa?
Jak wspominałem wcześniej, klaster wystawia API do komunikowania się z nim. Jest to zwykłe API REST-owe, które pozwala na wykonywanie wszystkich operacji potrzebnych do obsługi Kubernetesa.
Do komunikacji używane jest narzędzie kubectl. Po odpowiednim skonfigurowaniu pozwala wchodzić w interakcję z Kubernetesem przy użyciu linii komend. Wywoływane komendy zmieniane są w zapytania HTTP i wysyłane do API, odpowiedzi zaś wyświetlane w terminalu. Konfiguracja tego narzędzia przechowywana jest w pliku konfiguracyjnym i może być ustawiana zarówno w terminalu, jak i bezpośrednio w tym pliku.
Narzędzie jest używane według składni kubectl <czasownik> <zasób>. Na przykład, by wylistować wszystkie pody w danym kontekście, piszemy kubectl get pods. Warto dodać, że samo narzędzie jest bardzo dobrze udokumentowane. Wywołanie flagi –help albo użycie polecenia kubectl explain na zasobie pozwala łatwo znaleźć poszukiwaną składnię.
Należy zwrócić uwagę na warstwę izolacji zasobów zwaną namespace. Klaster podzielony jest na wiele namespace-ów i do wywołania komendy dla danego namespace-a (na przykład wylistowania podów) należy dodać flagę -n <nazwa_namespace-a>. W praktyce stosuje się zwykle relację jeden namespace = jedno środowisko lub wiele namespace-ów = jedno środowisko.
Ostatnią istotną kwestią jest reprezentacja zasobów w kodzie. Wszystkie zasoby, które można wdrożyć na Kubernetesa (pody, deploymenty, configmapy i tak dalej) można zapisać w postaci YAML-a. Plik ten jest następnie użyty przez narzędzie kubectl do utworzenia (lub zmienienia istniejącego) zasobu. Jego zawartość jest wczytana, zmieniona w JSON-a i wysłana do API Kubernetesa metodą HTTP POST. Przykład pliku YAML definiującego prostego poda z Nginx-em wygląda następująco:
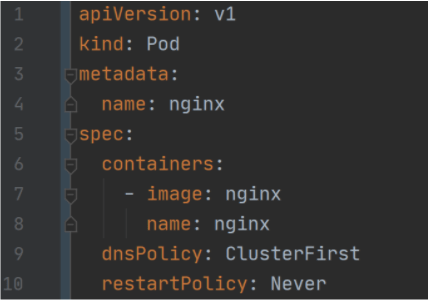
Powyższy plik zawiera informacje o typie zasobu (kind: Pod), podaje metadane (w tym przypadku jedynie nazwę poda) i definiuje specyfikację poda. Z linijek 7 i 8 wynika, że uruchomiony zostanie jeden kontener o nazwie nginx, w którym uruchomiony zostanie obraz nginx. Plik ten można wygenerować używając kubectl, wyeksportować z Kubernetesa lub po prostu napisać. Warto jednak zwrócić uwagę na częsty błąd występujący przy pracy z YAML-ami, czyli błąd w formatowaniu – jedna spacja za mało potrafi sprawić, że plik będzie nieczytelny dla Kubernetesa.
Podsumowanie: jak dowiedzieć się więcej o Kubernetesie?
W artykule poruszonych zostało wiele tematów, większość z nich jedynie w dość wąskim, ale potrzebnym z praktycznego punktu widzenia, zakresie. Dla chętnych do rozszerzenia tej wiedzy zostawiam kilka różnorodnych źródeł na dobry start:
- Książka Kubernetes Up and Running, wydawnictwo O’Reilly
- Cykl Kubernetes Basics opublikowanych na koncie YouTube Microsoft Azure
- Kubernetes Podcast from Google
Na zakończenie dodam, że Kubernetes to nie tylko technologia, ale też gigantyczna społeczność, która stworzyła mnóstwo narzędzi pomagających z nim pracować. Istnieją świetne narzędzia pomagające wdrażać, monitorować, debuggować czy zabezpieczać aplikacje na Kubernetesie i każde z nich jest warte dokładnego omówienia i zrozumienia. Ale to już materiał na inny artykuł.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Jak wygląda praca na stanowisku Senior Principal DevOps? Wywiad z Małgorzatą Rembas

Wykorzystanie chmury stało się standardem. O czym pamiętać przy wyborze dostawcy?

Od czego zacząć poznawanie metodyki DevOps?

5 powodów, dlaczego publiczne rozwiązania chmurowe nie zawsze są dobrym wyborem

Na czym polega praca z DevOps? Wywiad z Aleksandrem Czarnołęskim i Michałem Piotrowiczem

Ansible w małych i dużych projektach

Za duży popyt, za mała podaż, czyli dlaczego na rynku brakuje DevOpsów?
