Metryki testów aplikacji w systemach CI/CD

Sposób w jaki wytwarzamy i dostarczamy oprogramowanie w ciągu ostatnich kilku lat bardzo się zmienił. Nowe metodologie, trendy w architekturze systemów czy struktury zespołów to tylko niektóre ze zmian, które mają na celu dostosowanie się do pędzącego świata technologii. Jedno pozostaje niemal niezmienne: skupienie na jakości.

Waldemar Dubiel. Test Engineer w Hyland, dbający o jakość w projekcie R&D. Związany z testowaniem ponad 6 lat, podczas których pracował w obszarach front-end oraz transmisji wideo. Propagator zwinnego podejścia do procesów dostarczania oprogramowania i zapewniania jakości. W życiu prywatnym pasjonat smart home, miłośnik górskich wycieczek i podróży.

Marcin Kubański. Test Engineer w Hyland Poland Sp. z o.o. Entuzjasta nowych technologii z 6 letnim doświadczeniem jako inżynier testów. Zawsze poszukujący nowych, ekscytujących sposobów na zapewnienie wzrostu jakości i rozwoju w każdym projekcie, w którym uczestniczy. Oprócz testowania zajmuje się śledzeniem rozwoju frameworków frontendowych oraz trendów w rozwoju architektury oprogramowania. Prywatnie miłośnik fotografii i gier planszowych.

Paweł Wesołowski. Test Engineer w Hyland Poland Sp. z o.o. pracujący na co dzień przy tworzeniu testów automatycznych oraz rozwijaniu frameworka testowego. W karierze związanej z testowaniem od około 6 lat, począwszy od testera manualnego, QA a skończywszy jako Test Engineer. W ciągu tego czasu pracował w projektach zawierających różne technologie JS, TS, C#, SQL, Angular, Azure portal (Cloud). Doświadczony w testach performance, backendowych oraz frontendowych.
Większość organizacji dalej jest przekonana o tym, że jakość oprogramowania trzeba mierzyć i o tym dzisiaj sobie opowiemy.
Zapewne niektórzy z Was spotkali się z pojęciem metryk. Przewija się ono na różnych forach, w artykułach, czy w książkach. Chcielibyśmy abyście po przeczytaniu artykułu mogli odpowiedzieć sobie na kilka pytań:
- Czym w ogóle są metryki?
- Jakie są wady oraz zalety stosowania metryk?
- Jakimi narzędziami można się posługiwać, by zbierać dane do wykorzystania w nich?
- Jak możemy zacząć je zbierać podczas wdrożeń aplikacji?
Przejdźmy do rzeczy.
Spis treści
Czym są metryki i dlaczego są potrzebne?
Na samym początku zadajmy sobie pytanie: Co to jest metryka, jeśli mówimy o kontekście wytwarzania i testowania oprogramowania? Odwołując się do definicji zawartej w Wikipedii możemy określić to w następujący sposób:
“Miara pewnej własności oprogramowania lub jego specyfikacji. Termin ten nie ma precyzyjnej definicji i może oznaczać właściwie dowolną wartość liczbową charakteryzującą oprogramowanie. Standard IEEE 1061 – 1998 określa metrykę jako funkcję odwzorowującą jednostkę oprogramowania w wartość liczbową. Ta wyliczona wartość jest interpretowana jako stopień spełnienia pewnej własności jakości jednostki oprogramowania(…)”
Źródło: pl.wikipedia.org
Zapytacie: “No dobrze, ale co znaczy tak po ludzku?”. Tak naprawdę metryka to dowolna dana, najczęściej liczba, opisująca zachowanie systemu. Może być rozumiana bardzo szeroko, zarówno jako czas odpowiedzi aplikacji webowej, jak i na przykład ilość potrzebnych kliknięć, aby użytkownik mógł skorzystać z danej funkcjonalności.
Dlaczego metryki są liczbami? Bo chcemy móc nimi manipulować i porównywać je ze sobą. Przede wszystkim chcemy wiedzieć jak zmieniają się w czasie. Czytając ten wstęp, jesteście w stanie sobie wyobrazić kilka zastosowań tego typu wskaźników. Chcemy wiedzieć czy nasza aplikacja w ostatnich dwóch tygodniach nie zaczęła chodzić jak żółw, prawda? Nie mając metryk, a więc tak naprawdę sposobu mierzenia pewnych własności aplikacji, zdajemy się jedynie na sprawdzanie “na oko”. Czyli wprowadzamy pewną uznaniowość, w związku z czym pojawia się więcej miejsca na błąd ludzki.
Nawiązując do słynnego książkowego cytatu “Nie można kontrolować tego, czego nie można zmierzyć” musimy zdać sobie sprawę z kilku rzeczy. Aby kontrolować jakość aplikacji, niezależnie od jej etapu rozwoju, potrzebny jest nam sposób stwierdzenia, czy spełnia ona nasze oczekiwania. Inny niż “wygląda ok, może być”. Najlepiej taki, który jest jak najmniej subiektywny.
Do powyższej weryfikacji potrzebujemy danych na każdy temat związany z działaniem aplikacji, od momentu jej budowania, aż do tego co robi z nią użytkownik. Im więcej, tym lepiej. Duże ilości zebranych danych, różnych typów pozwalają nam na dokonanie burzy mózgów i zadanie sobie pytania: które z tych danych są kluczowe? Co sprawia, że aplikacja działa dobrze? Który element tego, co zmierzyliśmy jest czymś, co nie może się pogorszyć? (Dla przykładu, aplikacja webowa ładująca się 60 sekund nie zostanie ósmym cudem świata.)
W momencie, gdy zidentyfikujemy to, co w morzu zebranych danych jest dla nas najistotniejsze, znaleźliśmy właśnie idealnych kandydatów do stworzenia metryk. Czyli, krótko mówiąc mierzymy to, co się da i mając już jakieś dane decydujemy, które z nich są kluczowe dla działania naszego systemu.
Kiedy zbierzemy dane, metryki pozwalają nam na śledzenie postępów w rozwoju aplikacji oraz monitorowanie zmiany w taki sposób, by upewnić się, że żadna z kluczowych charakterystyk systemu nie zostanie pogorszona. A jeśli coś się stanie i na przykład wzrośnie mocno czas odpowiedzi aplikacji (w tym artykule będziemy się często odnosili do przykładów z aplikacji webowych) to zauważymy to dużo wcześniej, niż użytkownik. Przez to, że śledzimy zachowanie systemu na różnych poziomach, zarówno w trakcie jego działania, jak i podczas wdrożeń, uzyskujemy dużo lepszy obraz tego, co się dzieje z naszą aplikacją i możemy szybko zareagować gdy coś jest nie tak.
Metryki procesu testowego przekazują nam między innymi następujące informacje:
- jak wzrasta / maleje liczba błędów w podziale na przeprowadzone iteracje/fazy,
- jaka jest liczba błędów wykrywanych w aplikacji i ich kategoryzacja,
- jaka jest wydajność uruchamianych testów,
- jakie jest pokrycie kodu aplikacji testami,
- jaki jest średni czas całego wdrożenia aplikacji,
- jakie obszary aplikacji są najbardziej narażone na występowanie błędów.
Opisaliśmy już jak wygląda kwestia definiowania metryk w uogólnieniu, ale co jeśli chcielibyśmy podejść do tego w sposób bardziej systematyczny? Jeśli chcemy formalnie opisać cały proces testowania to definiuje go ISO/IEC/IEEE 29119-2:2013. Standard ten obejmuje opisy elementów, które definiują procesy testowania oprogramowania na poziomie organizacji, poziomie zarządzania testami (projektu) i na poziomie dynamicznego procesu testowego. Dzieje się to zgodnie z następującym diagramem:
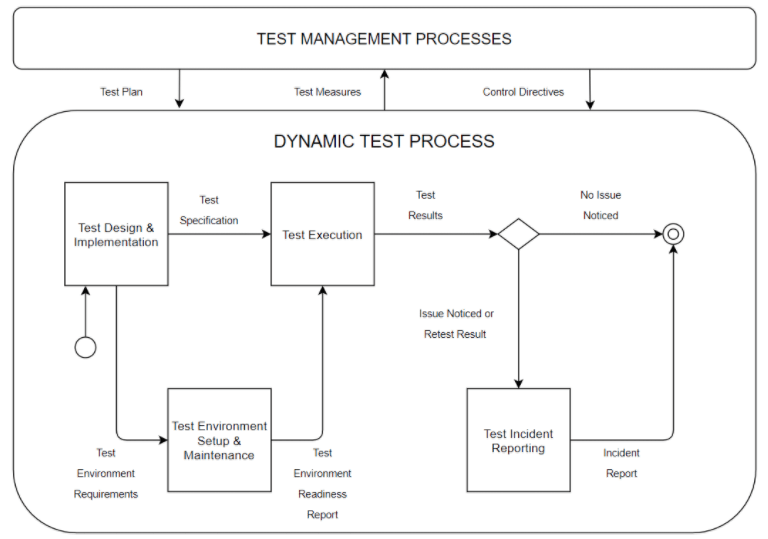
Diagram 1. Ogólny model testowy zgodny ze standardem ISO. Źródło: en.wikipedia.org
Zapytacie: “Ale po co mi ten diagram? Jaki to ma związek z zagadnieniem metryk?”.
To jest drugie podejście, jakie możemy zastosować przy definiowaniu tego, co chcemy mierzyć. Przede wszystkim możemy używać takiej kategoryzacji do grupowania metryk (czyli charakterystyk systemu, nie zapominajmy o tym). Na podstawie tego schematu definiujemy też obszary, w których metryki mogą być dla nas ważne:
- Test Design and Implementation (Projektowanie i implementacja testów) – metryki związane z pokryciem zmian testami, liczbą testów, powiązaniem ich z komponentami aplikacji.
- Test Execution (Wykonanie testów) – metryki związane z szybkością wykonywania suity testowej, czy wydajnością poszczególnych testów itd.
- Test Incident Reporting (Raportowanie błędów) – metryki związane z przyrostem zgłaszanych błędów.
- Test Environment Set-up (testy przygotowania środowiska) – np. metryki określające parametry systemu, na którym działa aplikacja, wyniki testów wydajnościowych itd.
Teraz gdy mamy już ogólne pojęcie, czym są metryki, zanim zaczniemy wchodzić w szczegóły, powinniśmy się zastanowić jakie będziemy mieli konkretne korzyści z ich użycia.
Wady i zalety wprowadzania metryk, czyli “Czy to gryzie?”
W poniższej tabeli staramy się przedstawić najważniejsze zalety wprowadzania różnego rodzaju metryk do projektu i z jakimi wyzwaniami można się zmierzyć w trakcie ich implementacji. Staraliśmy się opisać tę złożoną kwestię w sposób jak najbardziej generyczny, natomiast jest rzeczą kluczową, aby zrozumieć, jakie są potrzeby w danym konkretnym projekcie. Mając taką wiedzę możecie zdecydować, które z zalet i wad odpowiadają mu najbardziej.
| Zalety i szanse | Wady oraz ryzyka |
| Mogą być wykorzystywane w procesie monitoringu aplikacji, co jest szczególnie ważne w przypadku aplikacji webowych, które są ciągle dostępne dla użytkownika. | Nie zawsze istnieje możliwość zautomatyzowanego zbierania metryk w projekcie. Wpływ na to może mieć między innymi rodzaj wytwarzanej aplikacji oraz infrastruktura wymagana do jej funkcjonowania. |
| Możemy potwierdzić lub oszacować, czy nasz produkt spełnia wyznaczone standardy pod względem jakościowym. | Dane zbierane przez pipeline do tworzenia metryk zajmują określone zasoby (np. za każdym razem kiedy generowane są dane – zajmują one coraz więcej przestrzeni na dysku). |
| Możemy potwierdzić jakie są najkorzystniejsze dla działania aplikacji ustawienia, zasoby oraz konfiguracje, w których aplikacja działa optymalnie. | Pozyskiwanie szczegółowych danych zwiększa minimalnie czas budowania aplikacji (im więcej metryk różnego rodzaju generowane jest w procesie CI, tym dłużej trwa cały proces) oraz wymaga od nas stworzenia systemu zarządzania i analizowania metryk. |
| Metryki zbierane w interwałach czasowych mogą nam dostarczyć informacji o tym, czy aplikacja podczas dłuższego działania nie posiada nieprawidłowych odchyleń oraz czy jej zachowanie jest poprawne i zgodne z wymaganiami niefunkcjonalnymi. | Operowanie na dużej ilości metryk bez stworzenia konkretnego planu ich wykorzystania może prowadzić do sytuacji, gdzie nie wiadomo jaka jest hierarchia ważności metryk, lub na co najbardziej powinniśmy zwracać uwagę. |
| Metryki testowe zbierane we wstępnych fazach wytwarzania oprogramowania pozwalają nam na wczesne wykrycie defektów, co korzystnie wpływa na dalszy rozwój projektu poprzez skupienie się na obszarach, w których defekty występowały i zapobieganie im, między innymi poprzez większe pokrycie testami i stałe monitorowanie. | Jeżeli metryki uzyskiwane są manualnie, to istnieje prawdopodobieństwo pomyłki w procesie odczytu danych, co może zafałszować realny obraz aplikacji. |
| Pozwalają określić newralgiczne miejsca produktu, w których mogą wystąpić nieprawidłowości podczas ciągłego jego wytwarzania. Dzięki temu możliwe jest opracowanie strategii testowej w tych obszarach, aby zniwelować możliwość wystąpienia krytycznych błędów. | Niepoprawnie stworzone metryki mogą zaciemniać obraz aplikacji, oraz być trudne w dalszym wykorzystywaniu. |
| Dzięki porównaniu metryk z kilku iteracji możemy oszacować, czy jakość w projekcie wzrasta, czy też maleje. | |
| Metryki agregują w jednym miejscu najważniejsze dla działania produktu dane, które mogą nam posłużyć do analizy, a także obrania strategii dla dalszego rozwoju produktu. |
Jak pewnie zauważyliście benefity z korzystania z metryk pojawiają się na wielu płaszczyznach tworzenia aplikacji, natomiast wady są najczęściej wynikiem albo złej implementacji, albo też pewnych ograniczeń wynikających z infrastruktury.
Ogólny podział metryk powiązanych z testami
Skupiając się na procesie testowania oprogramowania i tworzeniu metryk na jego podstawie, możemy wyłonić metryki związane z wykrywaniem defektów oraz te związane z pokryciem kodu aplikacji testami.
Z całą pewnością przy tak ogólnym podziale, część z tych przykładów nie będzie mieć zastosowania w Waszej aplikacji. To jest ok. Zawsze musicie patrzeć na to, jakie dane są najważniejsze w pewnym konkretnym kontekście, tak jak opowiedzieliśmy o tym we wstępie.
Metryki związane z wykrywaniem defektów:
Liczba wykrytych defektów – te metryki pozwalają nam ocenić jakość wytwarzanego kodu w początkowych etapach jego powstawania. Umożliwiają także ocenę przyrostu jakości kodu poprzez systematyczne wykrywanie oraz usuwanie błędów. Podstawową wartością jaką nam dają jest oszacowanie stopnia efektywności wykrywania błędów, oraz dostarczanie informacji o tym, czy aplikacja staje się bardziej stabilna.
Liczba defektów komponentów – z tej kategorii metryk możemy wywnioskować w jakich komponentach systemu występuje największa liczba znalezionych defektów. Najczęściej będziemy mieć tutaj jedną metrykę per komponent. Pozwala nam to ocenić oraz wyszukać komponenty aplikacji, które są gorszej jakości. Dzięki tej wiedzy można również zaplanować, oraz stworzyć, dodatkowe testy w obszarach krytycznych pod względem występowania defektów, by zapobiec ich ponownemu powstawaniu po wprowadzaniu nowych zmian w kodzie.
Procentowy udział poprawionych defektów – ta metryka określa nam stosunek liczby wykrytych defektów do szacowanej możliwej całkowitej liczby defektów. By oszacować liczbę defektów trzeba w tym przypadku wprowadzić sztuczne defekty (specjalnie spreparowane).
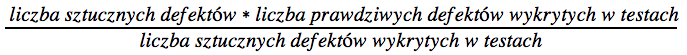
Metryki związane z pokryciem:
Pokrycie wymagań – metryka wyznacza stosunek liczby przetestowanych wymagań do ogólnej puli wszystkich wymagań. Jest przeznaczona do zobrazowania w jakim zakresie występuje pokrycie wymagań w specyfikacji testowanego oprogramowania. Stosuje się ją przede wszystkim w oparciu o testy funkcjonalne.

Pokrycie błędów – metryka sprawdzająca planowe pojawianie się błędów aplikacji. Stosunek liczby wszystkich błędów wykrytych podczas testów do liczby błędów, które miały wystąpić zgodnie z założeniami.

Pokrycie bloków instrukcji – jedna z metryk odnoszących się bezpośrednio do pokrycia kodu aplikacji testami. Dane uzyskane z tej metryki pozwalają oszacować stosunek liczbowy bloków przetestowanych do liczby wszystkich bloków.

Przykład pokrycia bloków instrukcji:

Diagram 2. Przykładowy schemat blokowy instrukcji warunkowej
Jak wynika z powyższego diagramu do pełnego pokrycia bloków instrukcji są wymagane dwa przypadki testowe. Jeden dla każdej widocznej gałęzi (True/False).
Pokrycie ścieżek – metryka obrazująca pokrycie ścieżek ma na celu zobrazowanie, czy zbadana została każda możliwa niezależna ścieżka wykonania programu od startu do zakończenia. Przy tego typu teście każda ścieżka jest sprawdzana w negatywnym i pozytywnym przejściu, co pozwala nam sprawdzić czy wszystkie możliwe stany aplikacji są możliwe do osiągnięcia przez testy. Na podstawie wyników możemy sporządzić metrykę mówiącą jaki procent ścieżek został pokryty testami w danym fragmencie aplikacji.
Przykład pokrycia ścieżek:

Diagram 3. Możliwe ścieżki w aplikacji
Z powyższego diagramu wynikają następujące kombinacje ścieżek:
- 1 -> 2 -> 3 -> 6
- 1 -> 2 -> 4 -> 6
- 1 ->2 -> 3 -> 4 -> 6
- 1 -> 2 -> 3 -> 4 -> 5 -> 2 -> 3 -> 6
- 1 -> 2 -> 3 -> 4 -> 5 -> 2 -> 4 -> 6
- 1 -> 2 -> 3 -> 4 -> 5 -> 2 -> 3 -> 4 -> 6
Pokrycie decyzji – pozwala nam stwierdzić na ile zostały pokryte instrukcje wpływające na przepływ sterowania. Taką metrykę można uzyskać poprzez podzielenie liczby wykonywanych instrukcji pokrytych przez przypadki testowe przez liczbę wszystkich wykonywanych instrukcji w testowanym kodzie.
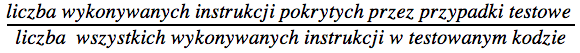
Przykład pokrycia decyzji:
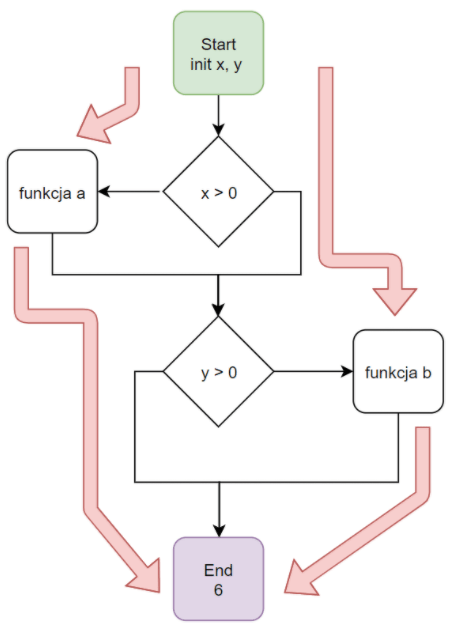
Diagram 4. Pokrycie decyzji przedstawione w schemacie blokowym kodu
Jak wynika z powyższego diagramu do pełnego przetestowana 100% decyzji potrzebujemy dwóch przypadków testowych określonych przez czerwone strzałki.
Pokrycie przypadków użycia – określa jakie jest pokrycie testami obrazującymi interakcje pomiędzy użytkownikiem, a aplikacją (takie testy zazwyczaj są przedstawiane jako sekwencje prostych kroków wykonywanych przez użytkownika). Jako testy przypadków użycia możemy wyróżnić testy sprawdzające jakie wymagania musi spełniać dany system pod względem biznesowym, oraz przypadki systemowe weryfikujące ścieżki stricte techniczne.
Jakimi narzędziami można się posługiwać, by zbierać dane do tworzenia metryk?
Narzędzi, którymi możemy się posłużyć do zbierania danych jest bardzo wiele i wybór zależy przede wszystkim od tego, jakie rodzaje danych chcemy pozyskać. Tak jak już wspominaliśmy, na wybór odpowiedniego z nich będzie mieć też wpływ rodzaj aplikacji nad jaką pracujemy (aplikacja posiadająca interfejs graficzny, API, itd.). Przyjrzyjmy się zatem z jakich narzędzi możemy skorzystać w różnych obszarach funkcjonowania aplikacji.
Metryki pozyskane z testowania Frontendu (GUI)
We frontendowych aplikacjach przedmiotem pozyskiwania danych podczas przeprowadzania testów jest to wszystko, co możemy zaobserwować na ekranie komputera i co jest widoczne gołym okiem (czy interfejs użytkownika jest poprawnie wyświetlany, czy pole tekstowe może być uzupełnione, czy przycisk jest klikalny, itp.). Przykładem takiej aplikacji może być aplikacja napisana w Angularze, składająca się z modułów i komponentów, które oddziaływują między sobą w określony sposób. W tym wypadku do przeprowadzania testów i uzyskiwania w oparciu o nie metryk przydadzą się narzędzia, które “wyklikują” nam pewien schemat ustalony w teście.
Do tego typu narzędzi możemy zaliczyć każdego rodzaju framework pozwalający na symulowanie interakcji użytkownika z aplikacją. Pozostając przy przykładzie aplikacji będzie to na przykład Cypress, czy też frameworki bazujące na Selenium. Do tworzenia metryk będziemy wykorzystywać wyniki testów przeprowadzanych przy pomocy danego frameworka. Jeśli sam framework nie daje nam możliwości pozyskania wystarczająco szczegółowych danych z wyników testów, to możemy korzystać z dodatkowych pluginów rozszerzających jego funkcjonalności.
Mając już zebrane dane, możemy przekazać je do narzędzia, przy pomocy którego możemy je obrabiać i prezentować – takim jest na przykład Grafana. Wspomniane narzędzie daje nam także możliwość monitorowania zebranych danych w czasie, prezentacji ich jako wykresy, tworzenia dashboardów i wiele innych. Umożliwia ono nam również ustawianie alertów w przypadku, gdy jedna z metryk spadnie poniżej jakiegoś ustalonego przez nas poziomu, co zdecydowanie poprawia czas reakcji w przypadku wystąpienia nieoczywistych błędów.
Cypress: cypress.io
Selenium: selenium.dev
Grafana: grafana.com
Metryki pozyskane z testowania Backendu (API)
W backendowych aplikacjach w przeciwieństwie do aplikacji frontendowych skupiamy się na wszystkim, co jest ukryte pod płaszczem zewnętrznym aplikacji (GUI) i nie jest widoczne gołym okiem dla użytkownika. W tych przypadkach możemy na przykład zbierać różnego rodzaju dane powiązane z poprawnością wysyłania lub odbierania zapytań (requestów) do serwera aplikacji. W zależności od tego, czy chcemy badać i pozyskiwać dane z pojedynczych requestów, czy też badać ich szybkość wysyłania oraz pobierania z serwera możemy polecić Wam różne narzędzia.
Pierwszym z nich jest JMeter, który jest przeznaczony głównie do testów performance (testy obciążeniowe). Dzięki temu narzędziu mamy możliwość wysyłania/odbierania requestów, walidowania ich poprawności, a także mierzenia czasów trwania requestów, czy też sprawdzania jak aplikacja zachowuje się przy wysyłaniu dużej ilości zapytań. Dane te możemy zapisać w formie raportu wykorzystywanego przy tworzeniu metryk mówiących nam, czy aplikacja działa w sposób poprawny, czy requesty są wysyłane i odbierane poprawnie, czy czasy odpowiedzi są akceptowalne, itd. Następnym narzędziem przydatnym do zbierania danych powiązanych z testowaniem API jest Postman.
W przeciwieństwie do JMetera to narzędzie jest dedykowane do wysyłania pojedynczych requestów i służy przede wszystkim badaniu poprawności wysyłanych i otrzymywanych danych w formie zapytań. Zawiera jednak wiele wbudowanych funkcji, które ułatwią nam testowanie, jak i pozyskiwanie danych. Podobne funkcjonalności w zakresie manipulacji requestami ma na przykład również Burp Suite, który jest narzędziem najczęściej wykorzystywanym w testowaniu bezpieczeństwa aplikacji webowych.
Apache JMeter: jmeter.apache.org
Postman: postman.com
Burp Suite: portswigger.net/burp
Metryki pozyskane z badania zasobów systemowych (Środowiska operacyjnego)
Każdy system, w którym odbywają się testy, posiada specyficzne dla siebie parametry oraz zasoby systemowe, które np. wraz z działaniem pewnych aplikacji ulegają zmianie. W środowisku operacyjnym możemy wyróżnić następujące dane: zużycie pamięci, obciążenie procesora, przepustowość sieci, zapis na dyskach, procesy powiązane z procesorami graficznymi. Anomalie w tych obszarach mogą spowodować nieprawidłowe działanie czy też całkowite awarie aplikacji, a w najgorszym przypadku zawieszenie serwera, na którym aplikacja pracuje.
Dlatego też jeśli będziemy zbierali dane z tego zakresu w pewnych interwałach czasowych mogą dać nam one obraz czy testowana aplikacja w systemie zachowuje się poprawnie tzn. czy na przykład nie zużywa za dużo zasobów systemowych. Do zbierania tego typu danych do metryk możemy po prostu posłużyć się prostymi narzędziami wbudowanymi w system operacyjny. Dla systemu operacyjnego Windows może być to po prostu menedżer zasobów monitorujący stan wszystkich procesów jakie działają w danej chwili, a dla systemów z rodziny Unix, możemy skorzystać z narzędzi konsolowych: top, htop.
Menedżer zasobów: en.wikipedia.org/wiki/Resource_Monitor
Top: en.wikipedia.org/wiki/Top_(software)
Htop: en.wikipedia.org/wiki/Htop
Metryki pozyskane poprzez badanie sieci
Zbieranie danych odnośnie obciążenia sieci było już wspomniane w podpunkcie metryk systemowych. W tamtym wypadku mogliśmy uzyskać podstawowe dane typu wielkości przepływu danych. Chcąc uzyskać bardziej szczegółowe dane, musimy do tego celu posłużyć się wyspecjalizowanymi narzędziami typu Wireshark lub Fiddler. Oba są dość rozbudowane i możemy dzięki nim zbierać dane odnośnie do szybkości, ilości, zakresu danych, wielkości wysyłanych / odbieranych pakietów danych. Korzystając z filtracji możemy śledzić / nasłuchiwać tylko te pakiety, które ściśle nas interesują. Dzięki tak pozyskanym danym jesteśmy w stanie badać między innymi czy pakiety danych są poprawnie wysłane, czy czasy ich odbierania / wysyłania są poprawne oraz czy treść tych pakietów jest poprawna i umieszczać je w postaci metryk.
Fiddler: telerik.com/fiddler
Wireshark: wireshark.org/
Metryki pozyskane ze środowiska chmurowego (cloud)
Chmury w przestrzeni ostatnich lat zyskują coraz więcej na popularności dzięki oferowanym w jednym miejscu narzędziom do budowania całej infrastruktury, potrzebnej do funkcjonowania aplikacji, więc nic dziwnego, że nowe aplikacje są tworzone specjalnie z myślą o tym by działały w takim środowisku. Wraz ze wzrostem zainteresowania umieszczaniem aplikacji w chmurze różni dostawcy stworzyli własne systemy do zarządzania, wdrażania oraz nadzorowania zasobów w danej chmurze.
W przypadku chmury Microsoftu takim serwisem jest Azure portal, który oprócz dużej liczby różnych narzędzi umożliwia nam na automatyczne monitorowanie oraz zbieranie danych. Dzięki temu, że posiadamy takie dane możemy traktować je jako metryki dla działającej w chmurze aplikacji. Za pomocą filtrów w prosty sposób można wyszukać interesujące nas dane, a za pomocą powiadomień mamy możliwość ustawienia alertów, które będą wysyłane e-mailem po przekroczeniu metryki. Każdy inny dostawca, czy to Google Cloud, czy AWS posiada własny zestaw narzędzi ułatwiających pracę z danymi pochodzącymi z aplikacji.
Azure portal: azure.microsoft.com
AWS: aws.amazon.com
Google Cloud: cloud.google.com
Jak tworzyć i wykorzystywać metryki testowe aplikacji na przykładzie implementacji metryki w pipeline wdrożeniowym
Przejdźmy do bardziej praktycznego przykładu. Bezpieczne wdrażanie kodu do głównych gałęzi w systemie kontroli wersji jest niezwykle ważne ze względu na specyfikę wytwarzania oprogramowania i ewentualne koszty naprawy awarii “na produkcji”. To za sprawą dodawania lub modyfikacji kodu aplikacji jest możliwy jej rozwój. Cały proces dostarczania nowej wersji aplikacji może być zautomatyzowany, od scalania zmian, poprzez testy, a kończąc na wdrożeniu nowej wersji aplikacji na środowisko produkcyjne dostępne dla klientów.
Pozyskanie metryk podczas działania pipeline wdrożeniowego (CI / CD)
CI (continuous integration/ciągła integracja) / CD (continuous delivery/ciągłe dostarczanie) są koncepcjami pochodzącymi z kultury DevOps i mają one na celu wypełnienie luki pomiędzy pracami działu operations oraz developmentem. Dzieje się tak poprzez wykorzystanie automatyzacji procesów budowania, testowania i deploymentu aplikacji. Najczęściej we wprowadzaniu tych praktyk wykorzystuje się tworzenie różnego rodzaju skryptów, oraz pipeline wdrożeniowych wykorzystywanych później w narzędziach ułatwiających pracę z nimi. Takimi narzędziami są na przykład Jenkins, CircleCI, rozwiązania zintegrowane z chmurą jak Azure Devops, lub na przykład z narzędziami do zarządzania repozytorium jak Github Actions.
Ponieważ proces budowania pipeline wdrożeniowego jest kwestią bardzo indywidualną, w końcu tworzymy go przy pomocy pisania kodu, daje nam on możliwość używania w nim różnych pluginów pozwalających nam na przykład na integrację narzędzi monitorujących, czy też przygotowywanie raportów na podstawie danych wygenerowanych w trakcie działania pipeline. Przykładem narzędzia z tej drugiej grupy jest Allure, oferujący nam sposób na generowanie przejrzystych raportów na podstawie wygenerowanych plików z wynikami testów. Fakt, iż pipeline jest implementowany bezpośrednio przez nas i to że mamy pełną kontrolę nad tym procesem umożliwia nam również zbieranie różnych danych w trakcie budowania. Takie dane możemy wykorzystać później, mówimy tu na przykład o wyniku uzyskanym z uruchomienia lintera lub narzędzi do analizy statycznej kodu, czasie jaki zajmuje budowanie aplikacji, czy wykonane testów jednostkowych.
Jenkins: jenkins.io
Github Actions: docs.github.com/en/actions
Allure: allure.qatools.ru
W przykładowym pipeline wdrożeniowym możemy wyróżnić następujące fazy:
Merge Pull Request ze zmianami – w tym etapie zmiany w kodzie, nad którymi pracujemy scalane są z główną gałęzią dla danego repozytorium. Informacja o zmianach zostanie wysłana do pipeline, gdzie zaczyna się cały proces CI/CD.
Budowanie Aplikacji – w tym etapie kompilujemy/transpilujemy naszą aplikację, tworząc jej produkcyjną wersję, w takiej formie w jakiej będzie dostępna dla jej użytkowników. W trakcie tego kroku mogą być zbierane metryki dotyczące czasu budowania aplikacji, czy też jej wielkości. Mogą być one zachowane na przykład w postaci tekstowej, w postaci pliku .json, czy też zapisane w postaci artefaktu.
Testowanie Aplikacji – etap testowania jest tutaj dla nas najważniejszy w kontekście pozyskiwania metryk testowych. W tym etapie uruchamiane są testy automatyczne, z których są zbierane dane, które następnie wykorzystamy tworzeniu metryk.
Wdrażanie Aplikacji – po przejściu poprzednich etapów (Budowa Aplikacji oraz Testowanie Aplikacji) kod jest wdrażany do głównej gałęzi systemu kontroli wersji (najczęściej o nazwie main lub master)
Spójrzmy przez chwilę głębiej na fazę testowania aplikacji. W tej fazie jest możliwe uzyskanie np. metryki pokrycia kodu, pokrycia bloków instrukcji, pokrycia ścieżek, pokrycia błędów etc., poprzez zintegrowanie do pipeline stage (kroku), który uruchomi nasze testy i wygeneruje z nich dane (wyniki). Wyniki testów zostaną umieszczone w raporcie lub innym formacie danych pozwalającym na jego obróbkę. Mając już dane możemy wykorzystać je w tworzeniu metryk i przekazywać dalej do odpowiednich narzędzi pozwalających na ich monitorowanie i prezentowanie.
Teraz postaramy się Wam pokazać dwa przykłady pipeline wdrożeniowego, gdzie na dwa różne sposoby został rozwiązany sposób przechowywania wyników testów, a tym samym danych wykorzystywanych przy pracy z metrykami.
Przykład z użyciem bazy danych:
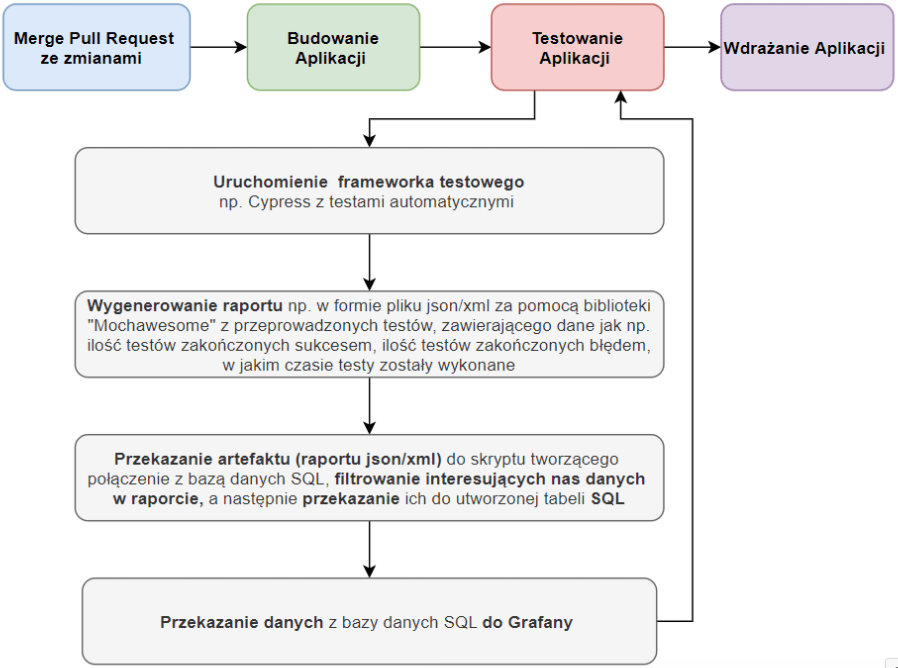
Diagram 5. Proces zbierania metryk testowych z przechowywaniem rezultatów w bazie danych
Przyglądając się poniższemu przykładowi możemy zauważyć, że dane, z których będą tworzone metryki są generowane w formie raportu i bezpośrednio po ich obróbce, przesyłane są do bazy danych. Następnie mając już wypełnioną danymi bazę możemy wykorzystać narzędzie do prezentacji metryk takie jak Grafana i podpiąć tam wyżej wymienioną bazę jako źródło danych. Takie rozwiązanie niesie za sobą plusy, jak i minusy.
Plusy: zabezpieczenie się przed utratą danych, posiadanie danych historycznych oraz możliwość selekcji / segregacji danych według potrzeby
Minusy: konieczność posiadania bazy danych oraz zasobów systemowych do jej obsługi.
Przykład z pominięciem bazy danych:
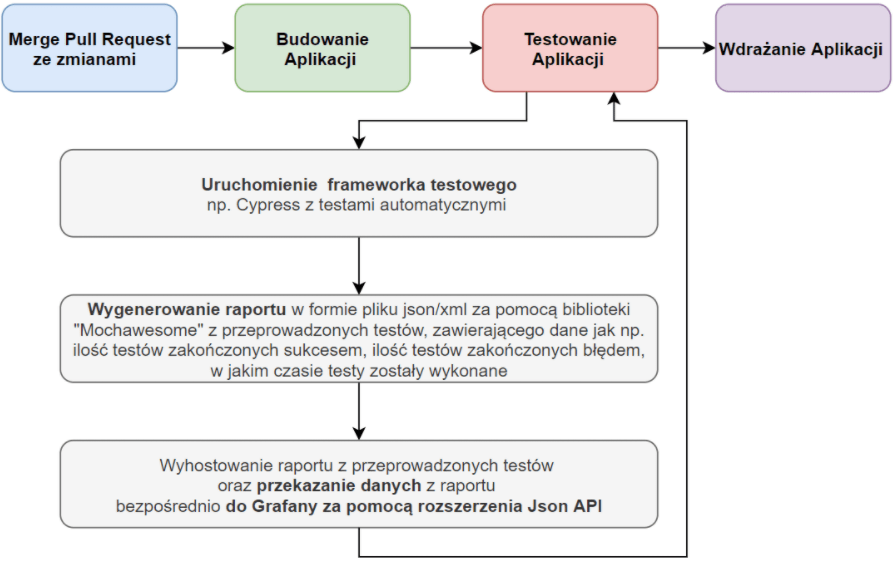
Diagram 6. Proces zbierania metryk testowych bez przechowywania rezultatów w bazie danych
W tym przykładzie rzecz ma się nieco inaczej niż poprzednio. Pomijamy tutaj krok z przekazywaniem danych do bazy danych SQL. Dane są przekazywane za pomocą wtyczki w programie docelowym prezentującym dane z wygenerowanego i hostowanego raportu.
Plusy: Nie musimy posiadać hostowanej bazy danych, prostsza konfiguracja i implementacja rozwiązania z poziomu aplikacji prezentującej dane (na przykład Grafana).
Minusy: Utrudnione agregowanie danych, brak możliwości tworzenia kopii zapasowych danych oraz możliwość utraty danych historycznych, ograniczone możliwości filtrowania z raportu odpowiednich dla nas danych z których budowana jest metryka.
Podsumowanie
W dobie rozkwitu technologii, jak i ciągłego rozwoju kultury testowania, należy podkreślić, że zbieranie metryk testowych jest ważnym aspektem procesu wytwarzania oprogramowania. Dzięki metrykom możemy zbudować sobie obraz testowanej aplikacji, dzięki któremu da się oszacować między innymi jakość produktu, pisanego kodu bądź też samych testów. Metryki potrafią też odpowiedzieć nam na pytanie czy wytwarzany produkt spełnia wymagania użytkownika końcowego, oraz czy działa zgodnie ze specyfikacją. Do zbierania danych do metryk możemy wykorzystać najróżniejsze narzędzia w zależności od naszych potrzeb.
Implementując pozyskiwanie danej metryki testowej w procesie, trzeba wziąć pod uwagę jej wady oraz zalety, aby metryka była dla nas wsparciem w zapewnieniu jakości, a nie zbędnym balastem. Mamy nadzieję, że artykuł ten nakreślił Wam czym są metryki testowe, jak z nich korzystać, jakie mają zalety i wady oraz jak możecie spróbować je zaimplementować w waszym projekcie. Niech przyświeca Wam cytat z Controlling Software Projects, Management Measurement & Estimation, (1982), p. 3.: “You can’t control what you can’t measure”.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
