Kubernetes i niestandardowe logi. Co z nimi zrobić?

Wszyscy lubimy logi. Przydają się na przykład, gdy musimy wyśledzić jakiś błąd w naszych aplikacjach. Ale jak poradzić sobie z niestandardowymi logami, pracując z Kubernetesem? Przekonajmy się.
 Przemek Malak. AWS Architect (Development) oaz Instruktor w Szkole Chmury. Ponad 18 lat w branży IT. Architekt rozwiązań chmurowych i mobilnych oraz Programista (przez duże P). Entuzjasta rozwiązań Serverless, posiadacz kilku certyfikacji AWS (Architect, Developer, SysOps).
Przemek Malak. AWS Architect (Development) oaz Instruktor w Szkole Chmury. Ponad 18 lat w branży IT. Architekt rozwiązań chmurowych i mobilnych oraz Programista (przez duże P). Entuzjasta rozwiązań Serverless, posiadacz kilku certyfikacji AWS (Architect, Developer, SysOps).
Spis treści
Logi w Kubernetesie: na początek klasycznie
Gdy uruchamiamy aplikację za pomocą Dockera i Kubernetesa, najlepiej, jeżeli nasze logi zrzucane są na standardowe wyjścia stdout i stderr. Platforma potrafi takie logi zagregować i udostępnić je nam za pomocą standardowego polecenia kubectl logs. Zobaczmy, jak to działa.
Uruchomimy sobie prostego poda, który co sekundę napisze nam coś na konsoli:

Możemy teraz łatwo zobaczyć, co też nasz pod ma nam do powiedzenia:
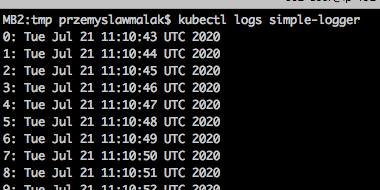
Niestandardowe logi – co z nimi począć?
Na pewno część z Was spotkała się jednak z aplikacjami, które zapisują logi i informacje o błędach w sobie tylko znanym miejscu, bez możliwości zmiany lokalizacji.
Być może na przykład ktoś zakodował kiedyś ścieżkę do pliku z logiem, a teraz my nie możemy zmienić tych ustawień. Ciężko nam będzie dostać się do danych przechowywanych w takim miejscu jak /var/log/mojaaplikacja/plik.log.
Mamy więc taką definicję poda:

Aby pobrać logi z takiej aplikacji, musimy dostać się do środka kontenera i je odczytać. Da się? Ano, da się:
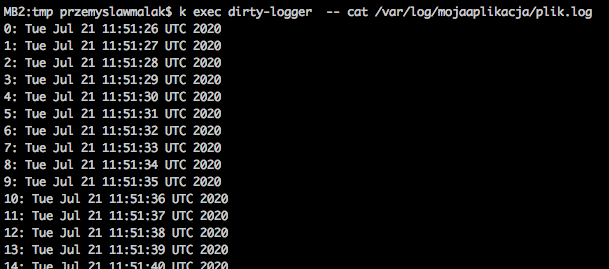
Jak widzicie, jest to jednak mało wygodne. No i w przypadku usunięcia poda tracimy dostęp do naszych logów.
Pokażę Wam zatem, jak sobie z takim problemem poradzić.
Pomocny pod
Kubernetes to dość elastyczna platforma. A pod to niekoniecznie tylko uruchomiony kontener. W podzie możemy uruchomić także kilka kontenerów, czy dołączyć do niego jakiś wolumin jako storage. I te cechy poda pozwolą nam wybrnąć z kłopotu i „wyeksportować” logi na stdout.
Gdzie siedzą logi?
Poza kontenerem, w którym pracuje nasza krnąbrna aplikacja, do poda dodamy wolumin, na którym będą zapisywane logi. Dodatkowo dojdzie także pomocniczy kontener, który będzie nasze logi odczytywał z tego samego woluminu i wypisywał na standardowe wyjście:

Mamy więc:
- Aplikację pracującą w głównym kontenerze.
- Aplikację pomocniczą, pracującą w dodatkowym kontenerze, odczytującą na bieżąco logi i „wyświetlającą” je na konsoli.
- Wolumin wewnątrz poda. Podmontowany zarówno do głównego kontenera, jak i do aplikacji pomocniczej.
Manifest dla takiego rozwiązania może wyglądać na przykład tak:
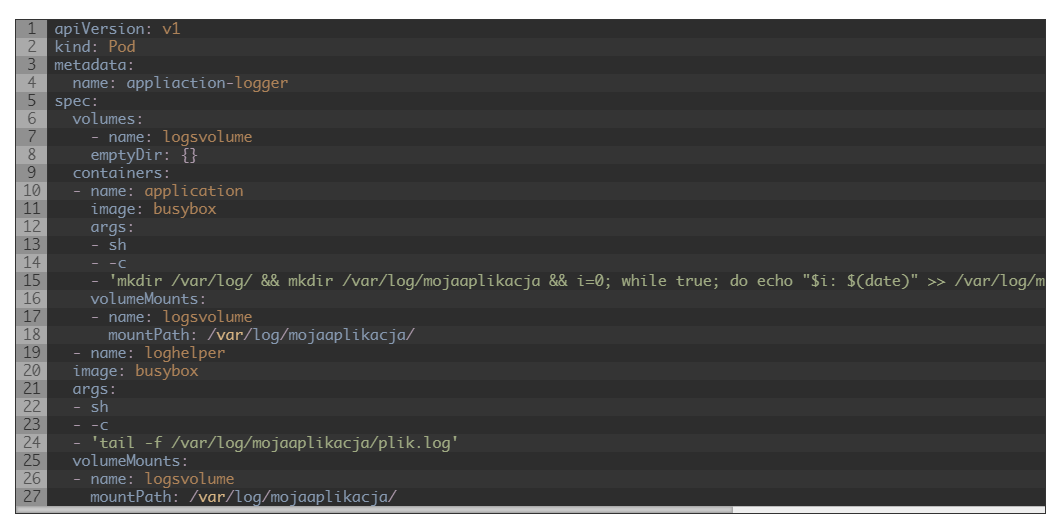
Przyjrzyjmy się poszczególnym elementom naszego rozwiązania:

- 1 – to główna aplikacja
- 2 – to aplikacja pomocnicza, odczytująca logi
- 3 – fragment zaznaczony jako 3 to wolumin wewnątrz poda, czyli miejsce, w którym główna aplikacja będzie zapisywała logi
- 4 i 5 – to punkty montowania woluminu 1 do poszczególnych kontenerów wewnątrz poda
Teraz nic nie stoi już na przeszkodzie, abyśmy dostali się do logów naszej aplikacji za pomocą standardowego polecenia kubectl logs. Musimy tylko oczywiście sięgnąć do kontenera, który nasze logi udostępnia:
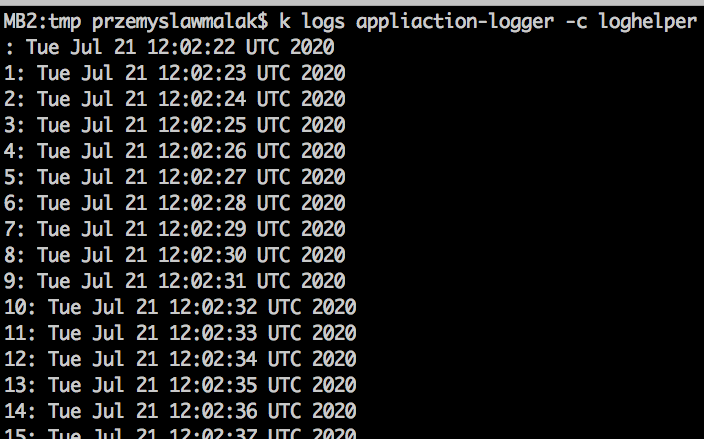
Gotowe!
Podsumowanie
Uruchamianie dwóch lub więcej kontenerów w jednym podzie nie jest podejściem, które powinniśmy zawsze stosować. Na przykład umieszczanie razem WordPressa i MySQL-a jest bardzo złym pomysłem.
Istnieją jednak przypadki, gdzie taki dodatkowy kontener może nas wspomóc w realizacji zadań. I wtedy warto go zastosować.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
