Jak działa Netflix od środka? Inżynieria chaosu i małpia armia

Czy kiedykolwiek zastanawialiście się, w jaki sposób platforma tak wielka jak Netflix dba o to, by każdy z 200 milionów jej subskrybentów był zadowolony z otrzymywanych usług? Na ogólny poziom zadowolenia wpływa tu oczywiście ilość oraz jakość streamingu filmów i seriali dostępnych na platformie. Kiedy wspominamy o ilości, mamy na myśli imponujące 700 tysięcy godzin treści video udostępnianych subskrybentom w każdej minucie.

Patryk Borowa. Programista w Aspire Systems Poland. Mistrz rozwiązywania problemów. Szczególnie motywują go te najbardziej złożone. Czy to dotyczące projektowania, ulepszania procesów, architektury czy kodowania – jako pierwszy zaproponuje rozwiązanie.
Jednym z istotnych wyzwań z jakim Netflix musi się mierzyć w celu utrzymania satysfakcji użytkownika końcowego jest problem ciągłego dostarczania usługi – bez większych usterek technicznych w postaci nagłego spadku jakości czy zacinającego się obrazu. Osiągnięcie odpowiedniego wysokiego poziomu niezawodności przy skali rozwiązania Netfliksa nie może być dziełem przypadku. Mamy tu do czynienia z przemyślaną architekturą, do której niezawodność została wszczepiona już na poziomie DNA.
Spis treści
Architektura Netfliksa
Rzućmy okiem na grafikę przedstawiającą architekturę mikrousług na platformie Netflix:
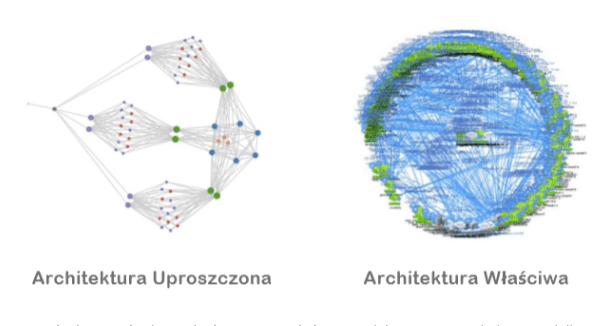
Czy przychodzi wam do głowy jakieś rozwiązanie, które sprawiłoby, że system tak złożony mógłby działać bezawaryjnie na poziomie tak zwanych czterech dziewiątek, czyli bagatela – niecałej godziny niedostępności rocznie? Nie wiem jak wy, ale ja wiem, czego na pewno bym nie zrobił. Na pewno nie dałbym małpie brzytwy, tzn. klawiatury do ręki oczekując, że pomoże mi to zaprowadzić ład i porządek w systemie. Ale kim jestem, by kwestionować decyzje światowej klasy architektów-wyjadaczy z Netfliksa…
Całe przedsięwzięcie, które opiszę w tym artykule miało na celu przestawienie sposobu myślenia programistów czuwających nad niezawodnością platformy – z naiwnego, który zakładał, że wszystko zadziała bezbłędnie na bardziej realistyczny, zgodnie z którym błędy na produkcji są wręcz nieuniknione. Ta prosta wydawałoby się zmiana w podejściu do kodu pozwoliła na to, aby praca w Netfliksie charakteryzowała się swobodą w doborze rozwiązań przez programistów.
Nie narzucano im żadnych konkretnych ram ani nie ograniczano ich poczucia wpływu na implementację oraz efekt finalny tworzonych rozwiązań. Mówiąc inaczej, firma nie chciała zmuszać programistów do rozwijania kodu w żaden konkretny sposób, oczekując jednak, że będzie tworzony on tak, by pozostawał odporny na awarie niezależnie od skali platformy.
Netflix Simian Army i inżynieria chaosu
Netflix miał świadomość tego, że standardowy monitoring wdrożeń – nawet na bardziej zaawansowanym poziomie – po prostu nie wystarczy przy wciąż rosnącej skali platformy. Zapotrzebowanie na zmiany było zbyt częste, a liczba zespołów zaangażowanych w proces wdrożeniowy była zbyt duża. Postawiono więc na… chaos. A mówiąc dokładniej, na destabilizację i zamęt wprowadzany w kontrolowany sposób do procesów CI/CD.
Obecnie taką metodologię wdrażania oraz testowania nazywamy fachowo „inżynierią chaosu” (z ang. Chaos Engineering). Było to wyjątkowo radykalne podejście do procesu ciągłego zautomatyzowanego wdrażania usług, o którym po raz pierwszy wspomniał Greg Orzell, architekt nadzorujący proces migracji Netfliksa do środowiska chmurowego w 2011 roku. Netflix opracował pakiet narzędzi umożliwiających wprowadzanie celowego zamieszania w systemie, prowadzącego do destabilizacji węzłów sieciowych czy do wyłączania losowo wybranych usług – zarówno w środowisku testowym, jak i na produkcji. Pakiet ten rozrósł się z czasem a dziś występuje pod nazwą Simian Army, co można przetłumaczyć jako Małpia Armia.
Armia ta składa się z dziesięciu (pomocnych?) postaci, z których każda stanowi konkretne wyspecjalizowane narzędzie wywołujące określone (nie)pożądane skutki. Poznajmy zatem naszych (anty)bohaterów:
- Chaos Monkey, czyli „podstawowa” Małpa Chaosu – wyłącza pojedyncze losowo wybrane instancje usług,
- Chaos Gorilla, czyli Goryl Chaosu – „siła rażenia” jego ataku potrafi wyłączyć całe grupy usług,
- Chaos Kong, czyli King Kong Chaosu – oczko wyżej od poprzedniego. Jego atak wyłącza usługi w skali regionalnej,
- Latency Monkey, czyli Małpa Latencji – spowalnia działanie sieci oraz symuluje różnego rodzaju problemy komunikacji,
- Conformity Monkey, czyli Małpa Zgodności – sprawdza wdrażane aplikacje pod kątem modyfikowalnych zasad (szczególnie przydatna przy walidacji wszelkiego rodzaju konfiguracji jak np. często modyfikowanych konfiguracji auto skalowania),
- Security Monkey, czyli Małpa Bezpieczeństwa – wykrywa oraz deaktywuje usługi w przypadku wykrycia potencjalnych luk bezpieczeństwa,
- Circus Monkey, czyli Małpa-Cyrkowiec – włącza i wyłącza poszczególne elementy systemu, by zapewnić sprawne rozłożenie obciążenia usług pomiędzy różnymi strefami dostępności (przeprowadzamy tu w zasadzie zaawansowane testy „load balancerów”),
- Doctor Monkey, czyli Małpa-Lekarz – naprawia (nie oszukujmy się… najprawdopodobniej po prostu wyłącza i włącza ponownie) niesprawne usługi,
- Howler Monkey, czyli Wyjec (dosłownie) – oznajmia o przypadkach przekroczenia norm – np. o przekroczeniu ustawionego limitu AWS – w bardzo wyraźny, „głośny” sposób.
- Janitor Monkey, czyli Małpa-Woźny – sprząta nieużywane zasoby.

Jeśli chcielibyście się dowiedzieć nieco więcej na temat Simian Army, polecam lekturę książki „Chaos Monkeys” autorstwa Antonio Garcíi Martíneza. Oto cytat na zachętę:
„Wyobraź sobie małpę wpuszczoną do “centrum danych”, dopuszczoną do “farm” serwerów, na których postawione są wszystkie krytyczne funkcje umożliwiające nam funkcjonowanie online. Małpa wyrywa kable na chybił-trafił, niszczy różne urządzenia, i miota przed siebie wszystkim, co nawinie jej się pod rękę [tj. rzuca odchodami]. Wyzwanie, z jakim muszą zmierzyć się managerowie działów IT, polega na projektowaniu takich systemów, które będą w stanie działać bezawaryjnie pomimo ryzyka wystąpienia tego typu małpich wybryków “za kulisami” systemu. Powinni oni mieć na uwadze pytanie, kiedy do tych wybryków dojdzie i co padnie ich ofiarą.”
Inżynieria chaosu i narzędzia do testowania błędów systemu
Jak myślisz? Czy twój system jest gotowy na tego typu małpie figle? Jeśli wydaje ci się, że nie za bardzo, to prawdopodobnie właśnie tego ci trzeba. Oczywiście nie namawiam do nieprzemyślanych operacji na żywym organizmie. Musisz się jednak liczyć z faktem iż unikanie odrobiny kontrolowanego chaosu przynajmniej na środowisku testowym, skończy się najprawdopodobniej zaproszeniem go do środowiska produkcyjnego – oczywiście ku wątpliwej „uciesze” użytkownika końcowego.
Może jednak warto dać inżynierii chaosu szansę? Poniżej lista kilku interesujących narzędzi, którymi warto się zainteresować:
- Chaos Mesh – narzędzie typu open source, stosowane w środowiskach Kubernetes. Wśród dostępnych funkcji mamy np. awarie sieci, błędy „kapsuł” (z ang. pods) i kontenerów (z ang. containers), błędy w systemie plików, czy nawet poważniejsze błędy jądra systemu operacyjnego (Linux),
- Gremlin – platforma typu „błąd jako usługa” (z ang. failure-as-a-service). Rozwiązanie hostowane, nadające się do zastosowania w infrastrukturze fizycznej, chmurowej, kontenerowej, w środowiskach Kubernetes jak również w tak zwanych aplikacjach „bez serwerowych”,
- ChaosToolkit – narzędzie stworzone z myślą o uproszczeniu inżynierii chaosu. Jest to kolejna platforma typu open source. Wprowadzono tu koncept tak zwanych eksperymentów opartych na deklaratywnym konfigurowaniu sekwencji zadań. Skupiono się tu również na ułatwieniu integracji z systemami CI/CD czy różnego rodzaju usługami hostingowymi,
- Litmus – zestaw narzędzi zaprojektowanych z myślą o generowaniu chaosu w środowiskach Kubernetes. Tu również zachęcani jesteśmy do korzystaniu z konceptu „eksperymentów”, które można z kolei pobrać z przygotowanego dla nas portalu.
A więc dać małpie tę brzytwę do ręki, czy nie? Analiza kosztów i korzyści
Kiedy mamy do czynienia z architekturą systemową, odpowiedź na pytanie, czy warto wprowadzić odrobinę chaosu w celu poprawienia ogólnej jakości systemu, brzmi – jak praktycznie w każdym innym przypadku – „to zależy”. Pomocnym w podjęciu decyzji będzie na pewno zestawienie ze sobą potencjalnych kosztów oraz ewentualnych korzyści wynikających z przyjęcia tego podejścia. W artykule opublikowanym w jednym z czasopism IEEE, eksperci z Netfliksa opisują przypadki zastosowania inżynierii chaosu w biznesie w kontekście którego objaśniają szczegóły przeprowadzonej analizy kosztów i korzyści.
Podsumowując, wszystko sprowadza się do kosztów utworzenia specjalnego zespołu ds. inżynierii chaosu oraz do kosztów ewentualnych konsekwencji celowego wprowadzenia błędów i awarii. Największe korzyści, to z kolei oszczędności poczynione dzięki wdrożonej “profilaktyce”. Unikamy tu potencjalnie bardzo kosztownych przerw w dostarczaniu usług.
Należy mieć tu na uwadze przede wszystkim to, iż błędy i awarie wywoływane celowo nie powinny występować na skalę większą niż te mogące potencjalnie wystąpić „naturalnie” w wyniku chociażby nie stosowania praktyk inżynierii chaosu.
Netflix – wzór matematyczny
Jeśli nie macie nic przeciwko matematyce, poniżej udostępniam przykładowy wzór podany we wspomnianym artykule ekspertów z Netfliksa, przyjęty dla opisywanego teoretycznego scenariusza:
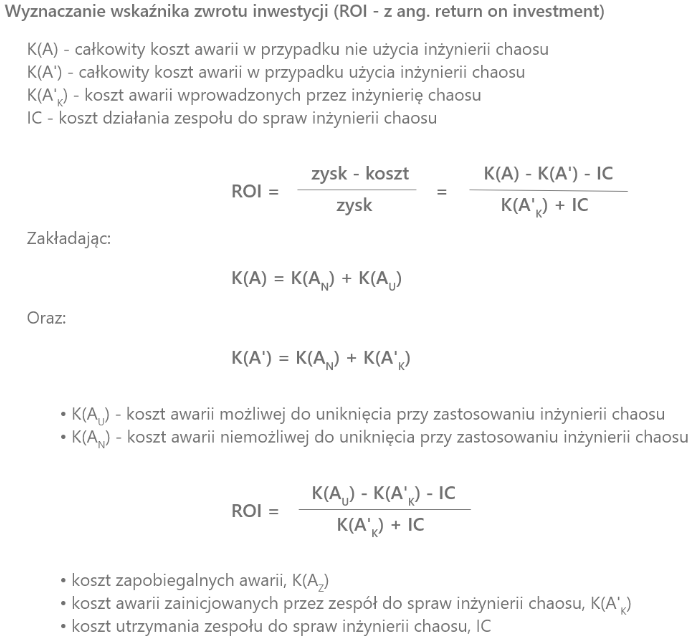
Pozwólmy jeszcze przemówić realnym liczbom:

Jak działa Netflix – podsumowanie
Mam nadzieję, że już mniej więcej wiecie, na czym polega ta cała inżynieria chaosu i w jaki sposób może ona pomóc wam poprawić stabilność i odporność na awarie waszych systemów. Chętnie dowiem się, co myślicie na ten temat, dlatego też zachęcam do zabrania głosu w komentarzach.
Jeżeli chcecie poznać historię Karola Stępniewskiego, Senior Software Engineera w firmie Netflix, przeczytajcie nasz wywiad.
Zdjęcie główne artykułu pochodzi z unsplash.com.







