Electron JS: jak przyspieszyliśmy działanie game launchera

Electron to popularny framework, służący do tworzenia aplikacji desktopowych dla różnych systemów, przy użyciu tej samej bazy kodu. Korzystając z Electrona zbudowano kilka naprawdę popularnych aplikacji, takich jak Microsoft Teams (migrują do Edge Webview2), Signal czy WhatsApp.
Niestety często słyszymy, że Electron jest powolny, zużywa dużo pamięci i tworzy wiele procesów obniżających szybkość całego systemu. To prawda, wymienione wyżej aplikacje nie są idealne, jeśli mowa o zużyciu zasobów, takich jak pamięć RAM i CPU, przez co znacząco wpływają na komfort korzystania z komputera. Na pewno jednak znalazłoby się kilka bardzo dobrych narzędzi, które zaprzeczają tym zarzutom. Takim przykładem jest Visual Studio Code. Czy możemy nazwać go powolnym? Wręcz przeciwnie — jest całkiem wydajny i responsywny.
Najlepiej jednak mówić o przykładach z własnego projektu.
Porozmawiajmy więc o wąskich gardłach aplikacji, którą pisaliśmy przy użyciu Electrona, i o tym jak przyspieszyliśmy jej działanie. Ale to nie wszystko — opisane tu działania możesz zastosować w innych aplikacjach opartych na NodeJS, takich jak serwery API lub inne narzędzia, w których wymagana jest wysoka wydajność. Dlaczego? Bo bardzo często aplikacje napisane za pomocą Electrona muszą radzić sobie z przetwarzaniem wielu (czasem naprawdę dużych) plików. Jeśli zależy ci na podobnej optymalizacji, możesz skorzystać z naszego przykładu.
Spis treści
Rozwijamy game launchera
Jeśli grasz w gry, prawdopodobnie masz kilka podobnych na swoim komputerze. Większość game launcherów pobiera pliki z gry, instaluje aktualizacje i weryfikuje pliki, dzięki czemu gry mogą odpalać się bez żadnego problemu. Istnieją elementy, których nie możemy przyspieszyć — to te, które zależą na przykład od szybkości Internetu. Kiedy jednak mowa o weryfikacji plików pobranych lub po aktualizacji, pojawia się problem — jeśli gra jest sporej wielkości, cały proces może zająć naprawdę dużo czasu. I tak właśnie było w naszym przypadku.
To wszystko nie jest takie proste
Nasza aplikacja jest odpowiedzialna za pobieranie plików i, jeśli to możliwe, wdrożenie aktualizacji binarnych. Kiedy już to zrobi, musimy się upewnić, że nic w procesie nie zostało naruszone. Przyczyny takich naruszeń mogą być różne i nie będziemy się tu na nich skupiać — ostatecznie nie ma znaczenia, co je spowodowało, użytkownicy chcą po prostu grać w swoją grę.
A teraz pozwólcie, że podzielimy się z wami kilkoma liczbami. Gra składa się z 44 plików o łącznej wielkości ok. ~4.7GB. Wszystkie te pliki musimy zweryfikować po pobraniu gry lub jej aktualizacji. Użyliśmy https://www.npmjs.com/package/crc, aby obliczyć CRC każdego pliku i zweryfikować go względem oczekiwanych sum kontrolnych. Aby zobaczyć, jak wydajne jest to podejście, przeprowadziliśmy kilka testów porównawczych (wszystkie były przeprowadzone na MacBooku Pro 14’ M1 Pro, 2021).
Czas na testy!
Będziemy potrzebowali kilku plików do weryfikacji. Możemy utworzyć parę z nich za pomocą polecenia mkfile -n 200m test_200m_1
Ale zaraz, jeśli spojrzymy na zawartość, to zobaczymy same zera!
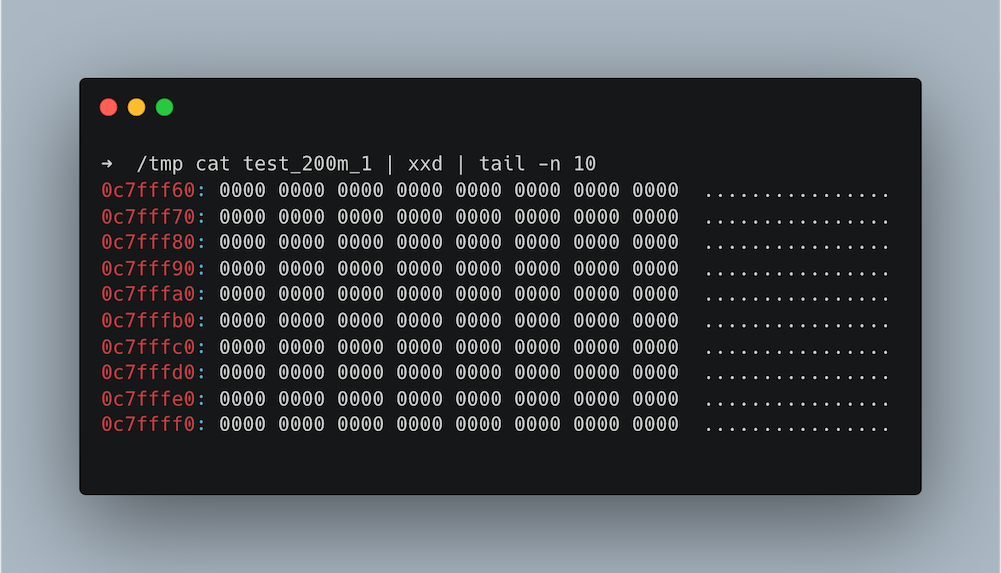
Efektem mogą być zniekształcone wyniki. Zamiast tego, możemy użyć komendy
dd if=/dev/urandom of=test_200m_1 bs=1M count=200
która bierze losowe dane z /dev/urandom
Stworzymy 10 plików, każdy po 200MB, i ponieważ dane w nich zawarte są losowe, powinny mieć różne sumy kontrolne.
Kod benchmarku:
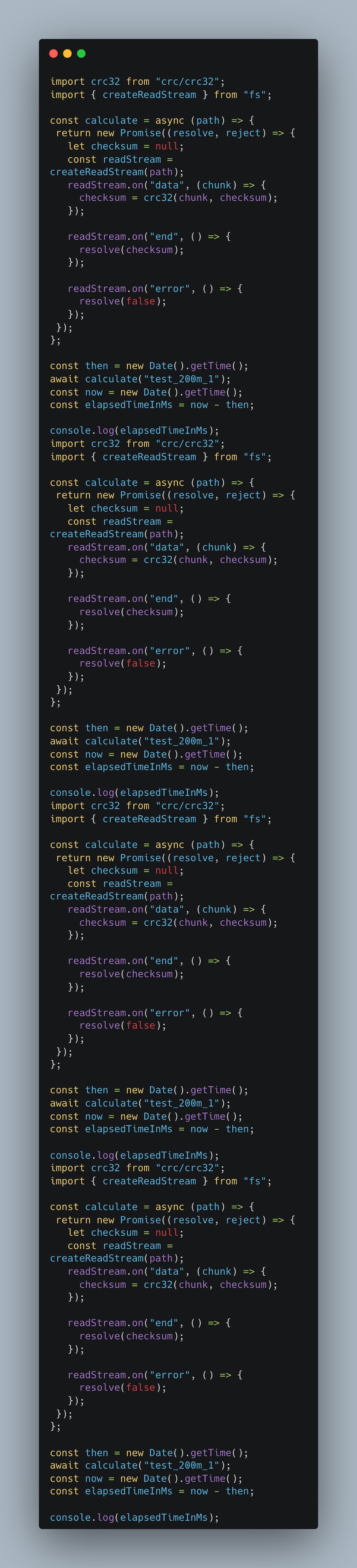
Utworzenie strumienia odczytu i stopniowe obliczenie sumy kontrolnej zajmuje około 800 ms. Preferujemy tutaj strumienie, ponieważ nie możemy sobie pozwolić na ładowanie dużych plików do pamięci systemowej. Jeśli obliczamy CRC32 dla wszystkich plików osobno, wynik wynosi ~16700ms. Zwolnienie następuje po trzecim pliku. Czy jest lepiej, jeśli użyjemy Promise.all, aby uruchomić je jednocześnie? Cóż… Znajdujemy się na granicy błędu pomiarowego, który waha się w okolicach ~16100ms.
Do tej pory więc otrzymujemy takie wyniki:
| Pojedynczy plik | 10 plików pojedynczo | 10 plików przy Promise.all |
| ~800ms | ~16700ms | ~16100ms |
Potencjalne rozwiązania
Prawdopodobnie jest ich dużo więcej, ale tutaj myślimy o:
- NodeJS Worker Threads
- Node-API
- Neon
- Napi-rs
- Inne biblioteki JavaScriptowe, które działają natywnie.
Zdecydowaliśmy się odrzucić Worker Thread, bo choć to rozwiązanie nie jest skomplikowane, to wymaga wielu linii kodu dookoła. Problemy może powodować także sytuacja, gdy baza kodu jest w TypeScript. Z założenia jest to wykonalne, ale wymaga dodatkowych narzędzi, takich jak ts-node lub konfiguracja. Ostatnią sprawą jest to, że nie chcemy tworzyć nie wiadomo ilu wątków roboczych, bo to również byłoby nieefektywne. Problem z wydajnością leży gdzie indziej. Niezależnie od tego, gdzie umieścimy te obliczenia, będą one powolne.
Jeśli chcemy, aby proces przebiegał szybko, Node-API wydaje się być idealnym rozwiązaniem. W końcu biblioteka napisana w C/C++ musi być szybka, prawda? W projekcie mamy już jedną bibliotekę napisaną w C, która spełnia inne zadania, i jesteśmy zadowoleni z jej działania. Istnieje coś o nazwie node-addon-api dla tych, którzy wolą C++ od C. Jest to prawdopodobnie jedno z najlepszych dostępnych rozwiązań, zwłaszcza że jest oficjalnie wspierane przez zespół Node.js. Cechuje je stabilność, ale może być uciążliwe podczas developmentu, a zwracane błędy są często bardzo trudne do zrozumienia. Mówiąc krótko — jeśli nie jesteście ekspertami w C, ta opcja może bardzo łatwo narobić wam problemów.
Jest jeszcze jedna alternatywa, o której nie wspomnieliśmy: Neon Bindings. Rust w NodeJS. Brzmi super, ale czy to nie kolejny buzzword z rozdmuchaną renomą? Choć twórcy Neon Bindings chwalą się, że ich rozwiązanie jest używane przez popularne aplikacje, takie jak 1Password i Signal, my zdecydowaliśmy się na inną opcję opartą na Rust, którą jest NAPI-RS. Gdy sprawdzimy jego dokumentację, wygląda dużo lepiej niż ta z Neon Bindings: przede wszystkim ma zdecydowanie lepiej opisane wspierane typy zmiennych, w tym również dużo przykładów. Dodatkowo jego narzędzie CLI bardzo ułatwia rozpoczęcie pracy z biblioteką NAPI-RS. Wśród sponsorów ma też nazwiska znane w branży. Jeśli porównamy tę dwójkę, NAPI-RS kładzie Neon Bindings na łopatki.
Ale dlaczego Rust?
Nie bez przyczyny jest jednym z najbardziej lubianych języków. Coraz więcej firm przepisuje swoje moduły na Rust z wielu różnych powodów: wydajności, bezpieczeństwa pamięci, społeczności, narzędzi (cargo, rust-analyzer), hype’u. Obszar specjalizacji w naszym projekcie jest na znacznie wyższym poziomie niż C/C++ czy Rust, ale kiedy mamy wybór między C a Rust, druga opcja jest znacznie bezpieczniejsza.
Rozwiązanie problemu
Z pomocą NAPI-RS zbudowaliśmy bibliotekę, wykorzystując paczkę https://crates.io/crates/crc32fast, która ekstremalnie szybko oblicza CRC32. Napi daje nam świetne, gotowe workflowy do tworzenia pakietów NPM, więc ich budowa i integracja z projektem jest bardzo prosta. Wspierają również budowanie gotowych binarnych modułów tak, aby nie było potrzeby instalowania środowiska Rust do ich uruchomienia. Właściwa kompilacja zostanie pobrana i zastosowana. Bez względu na to, czy korzystacie z systemu Windows, Linux czy MacOS, dotyczy to również maszyn Apple M1.
Dzięki bibliotece crc32fast użyjemy instancji Hasher do aktualizacji sumy kontrolnej z odczytanego strumienia, tak jak w implementacji JavaScriptowej:
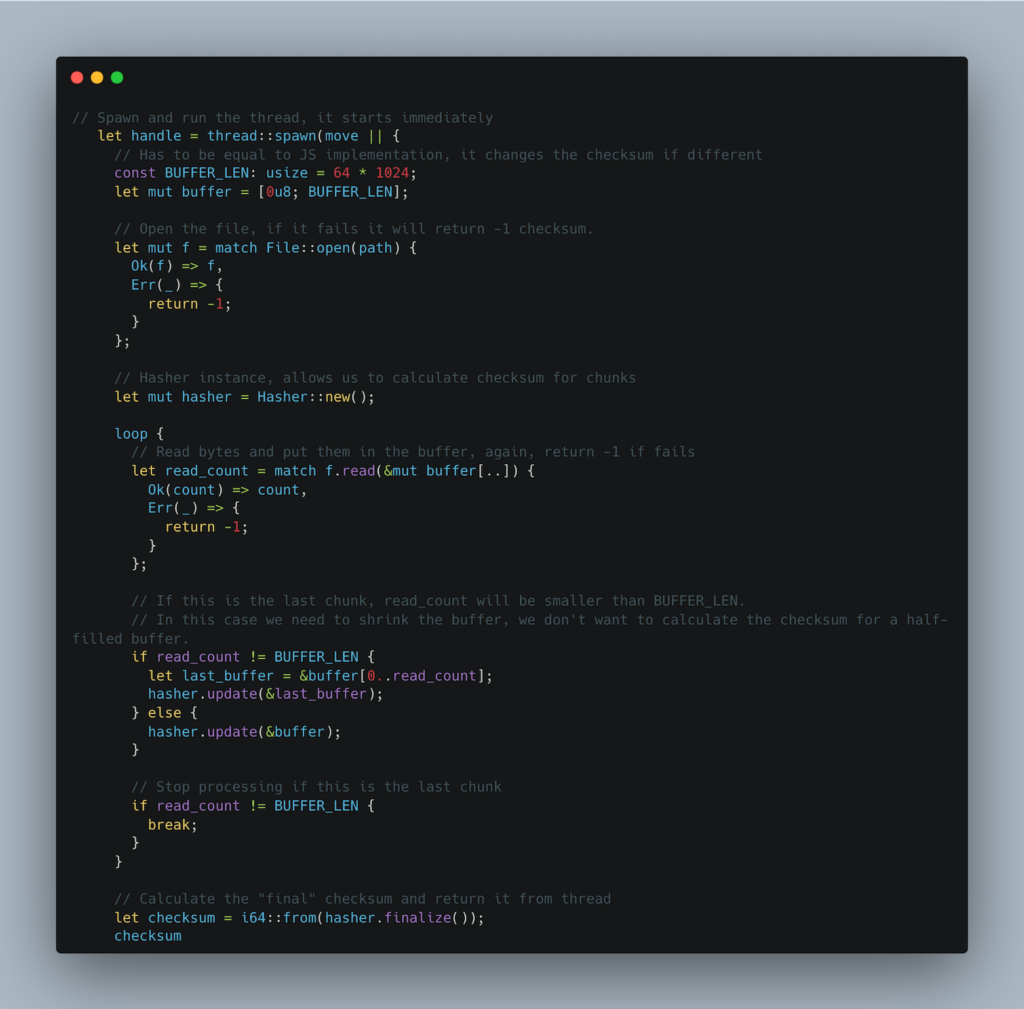
Otrzymane wyniki
Ten wynik może wyglądać nieprawdopodobnie, ale musicie uwierzyć nam na słowo — wynosi on tylko 75 ms dla pojedynczego pliku. To dziesięć razy szybciej niż implementacja JavaScriptowa! Kiedy przetwarzamy wszystkie pliki jeden po drugim, czas wynosi około 730 ms, więc również skaluje się to znacznie lepiej.
Jest jeszcze jedna dość prosta optymalizacja, której możemy dokonać. Zamiast wywoływać natywną bibliotekę N razy (gdzie N to liczba plików), możemy sprawić, by akceptowała tablicę ścieżek i tworzyła wątek dla każdego pliku.
Pamiętajcie, że Rust nie ma limitu liczby wątków, bo są to wątki systemu operacyjnego, zarządzane przez system. Wszystko zależy od systemu, więc jeśli wiecie, ile wątków zostanie utworzonych i nie jest to zbyt duża liczba, powinniście czuć się bezpiecznie. W przeciwnym razie zalecamy wprowadzenie limitu i przetwarzanie plików albo wykonywanie obliczeń w kawałkach.
Spróbujmy więc dla każdego pliku uruchomić jeden wątek tak, aby maksymalnie wykorzystać możliwości naszego procesora. Następnie, gdy wszystkie obliczenia się zakończą, zwracamy wszystkie sumy kontrolne:
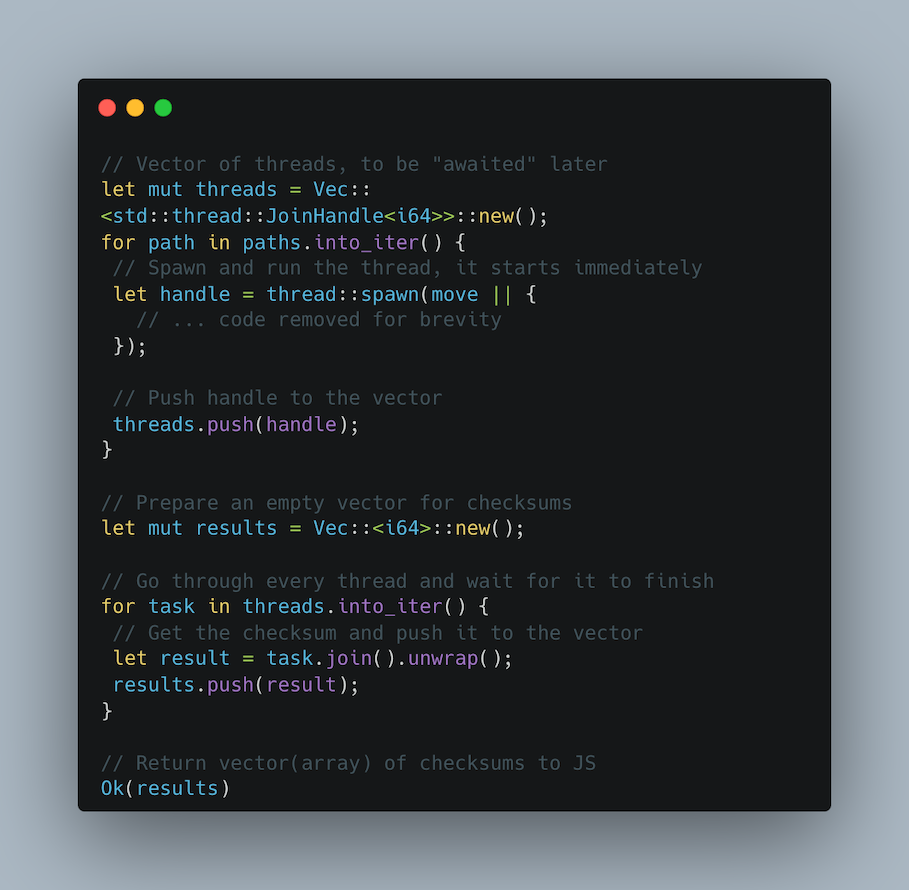
Ile czasu zajmuje wywołanie natywnej funkcji z tablicą ścieżek i wykonanie wszystkich obliczeń?
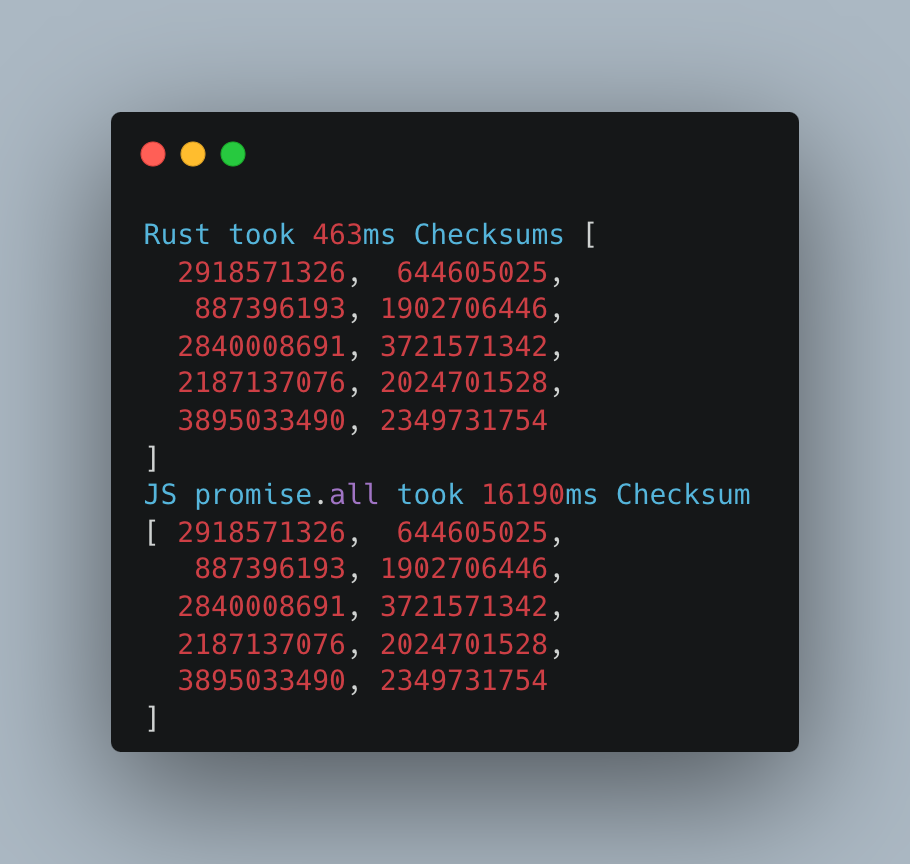
Tylko 150 ms. Serio, tak szybko! Aby mieć sto procent pewności, ponownie uruchomiliśmy MacBooka i wykonaliśmy dwa dodatkowe testy.
Pierwsze uruchomienie:
Drugie uruchomienie:
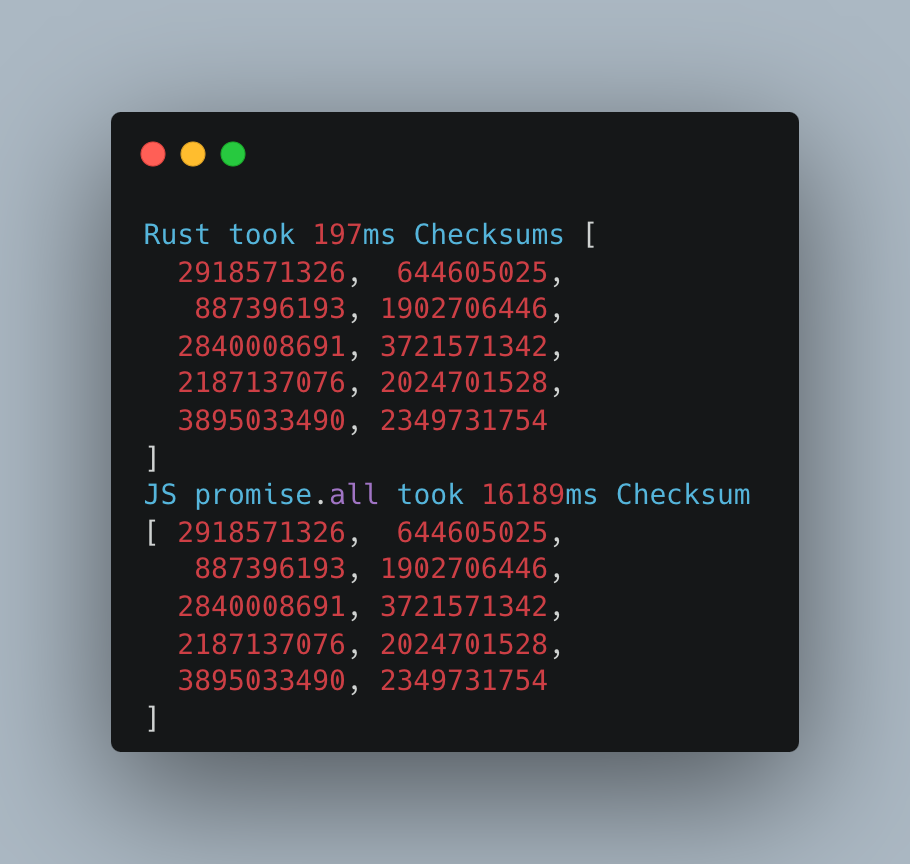
Zbierzmy teraz wszystkie wyniki razem i zobaczmy, jak wypadają w porównaniu:
| JavaScript | Rust | |
| Pojedynczy plik | ~800ms | ~75ms |
| 10 plików jeden po drugim | ~16700ms | ~730ms |
| 10 plików przez Promise.all | ~16100ms | – |
| 10 files w wątkach | – | ~200ms |
Warto zauważyć, że wywołanie natywnej funkcji z pustą tablicą zajmuje 124584 nanosekund, czyli 0,12 ms, więc obciążenie jest bardzo małe.
Wróćmy do Electrona
Przypomnijmy: wszystkie te rozwiązania można zastosować do Web API, narzędzi CLI i Electrona, a więc zasadniczo do wszystkiego, w czym używa się Node.js. W przypadku Electrona jest jeszcze jedna rzecz, o której należy wspomnieć.
Electron pakuje aplikację do archiwum o nazwie app.asar. Niektóre moduły Node muszą zostać rozpakowane, aby mogły zostać załadowane przez środowisko wykonawcze. Większość bundlerów, takich jak Electron Builder lub Forge, automatycznie przechowuje te moduły poza plikiem archiwum, ale może się zdarzyć, że nasza biblioteka pozostanie w pliku Asar. W takim przypadku musisz konkretnie określić, które biblioteki powinny pozostać rozpakowane. Nie jest to obowiązkowe, ale zmniejszy obciążenie związane z rozpakowywaniem i ładowaniem plików .node.
Kilka słów na koniec
Jak widzicie, istnieje wiele sposobów na przyspieszenie części aplikacji Node.js, zwłaszcza jeśli chodzi o wykonywanie ciężkich obliczeń. Najlepsze jest to, że możemy wybierać spośród różnych języków i strategii, dzięki czemu mamy zaopiekowane szerokie spektrum use case’ów.
W naszej aplikacji weryfikacja plików to tylko część całego procesu. Najwolniejsze dla większości graczy jest pobieranie plików, ale na pewno nie może ono przekroczyć limitu określonego przez dostawcę usług internetowych. Co więcej, niektórzy gracze mają starsze maszyny z dyskami HDD, gdzie wąskim gardłem może być IO, a nie procesor.
Jeśli jest coś, co możemy poprawić i zwiększyć przy tym wydajność przy rozsądnych kosztach, powinniśmy to zrobić. Może widzicie jakieś funkcje lub moduły w swojej aplikacji, które można przepisać w Rust lub C, co przyniesie znaczną poprawę wydajności? Jeśli tak, to co stoi na przeszkodzie, aby tego spróbować?
Zdjęcie główne pochodzi z Envato Elements.



