Computer Vision – rozpoznawanie treści na obrazach tak, jak robi to ludzki mózg

Przed Wami eksperyment – krok po kroku będziemy analizowali obraz, którego na początku w pełnej krasie nie będzie widać, i zobaczymy, jak wiedza nasza oraz naszej aplikacji o nim będzie się pogłębiała z każdą przeprowadzoną operacją. Wszystko to za pomocą Computer Vision – działu nauki, który nieustannie pracuje nad tym, by umożliwić maszynom rozpoznawanie treści na obrazach oraz filmach podobnie do tego, jak robi to nasz mózg.
Spis treści
Jak patrzy człowiek, a jak aplikacja?
Funkcjonowanie większości z nas w dużej mierze opiera się na analizie obrazów. Doskonalimy tę umiejętność przez całe życie. Rozpoznajemy ludzi, zwierzęta, obiekty, przedmioty, miejsca, jesteśmy w stanie ocenić odległości, prędkość, nadawać znaczenie pozornie niezwiązanym ze sobą elementom, wnioskować, rozpoznawać wzorce, potrafimy odczytać napisy nawet wtedy, jeśli litery są zniekształcone lub ledwo widoczne.
Ewolucyjnie jesteśmy tak mocno ukierunkowani na rozpoznawanie twarzy, że potrafimy zobaczyć je nawet tam, gdzie ich nie ma. Na korze drzewa, w mroku nocy czy w liściastym krzewie.
Kiedy spojrzymy na zdjęcie:

W 13 milisekund jesteśmy w stanie dostrzec, że przedstawia młodą kobietę oraz psa, którzy stoją przy drodze w lesie. Kobieta wydaje się radosna, pogoda jest piękna, a sam las — urzekający. Dłuższe oględziny pozwoliłyby nam na ustalenie rasy psa, nazw drzew i krzewów. Jeżeli to zdjęcie kogoś z kręgu znajomych lub sławnej osobistości, dodatkowo możliwe byłoby ustalenie danych personalnych. Wszystko na podstawie jednego obrazu z nieocenioną pomocą naszego mózgu oraz internetu i książek.
Gdybyśmy jednak zrobili eksperyment i spojrzeli na ten sam obraz w taki sposób, w jaki widzą go nasze aplikacje, nie zobaczylibyśmy niczego. Dzieje się tak dlatego, że człowiek tak naprawdę nie widzi za pomocą oczu. Nasze oczy odbierają bodźce wzrokowe, które następnie przetwarzane są na impulsy nerwowe, a te są przekazywane do mózgu. To nasz mózg interpretuje te informacje i pozwala nam widzieć i rozumieć to, co odbieramy. Więcej informacji na ten temat można znaleźć tutaj.
W dużym uproszczeniu moglibyśmy powiedzieć, że większość aplikacji jest w stanie odebrać/odczytać obraz, podobnie jak nasze oczy, ale brakuje im naszego mózgu, aby go zinterpretować.
Dla aplikacji zdjęcie to tylko duża ilość danych uszeregowanych w konkretnej sekwencji, która odpowiednio przedstawiona na ekranie jest zrozumiała dla użytkownika, ale nie dla samej aplikacji. To, czy na wyświetlonym zdjęciu znajduje się człowiek, pies, pejzaż czy burza z błyskawicami, pozostaje niewiadomą.
Czym jest Computer Vision?
Tak przynajmniej było kiedyś, bo już od pewnego czasu trwają prace nad umożliwieniem aplikacjom dostępu do pewnych funkcji, które do tej pory zarezerwowane były wyłącznie dla człowieka. Właśnie w tym celu powstał Computer Vision. W skrócie Computer Vision to dział nauki, który pracuje nad tym, żeby umożliwić maszynom rozpoznawanie treści na obrazach oraz filmach podobnie do tego, jak robi to nasz mózg.
Piszę aplikacje na iOS, więc skupię się na tym, jak Computer Vision działa w systemie od Apple, który od iOS 11 udostępnia i ciągle rozwija framework Vision, dzięki czemu możemy korzystać z mocy Computer Vision w naszych aplikacjach.
U podstaw funkcjonowania Vision leży Machine Learning i wbudowane, odpowiednio wytrenowane modele do wykonywania różnych zadań. Bazowa obsługa analizy obrazów i video jest współdzielona przez wszystkie dostępne operacje, a różnice przejawiają się głównie przy procesowaniu otrzymanych wyników:
- analizując sylwetki ludzi, dostaniemy informacje o wykrytych punktach (joints) ciała,
- analizując twarze, informacja zwrotna będzie zawierała punkty opisujące usta, brwi, owal twarzy czy oczy,
- klasyfikacja obrazu zwróci listę rzeczowników, które opisują dany obraz,
- Analiza istotności (saliency) elementów na obrazie zwraca heatmap (mapę ciepła) oznaczającą najbardziej istotne elementy.
Vision przenosi na nowy poziom spojrzenie na obrazy z perspektywy aplikacji i otwiera możliwości do tej pory zamknięte. Bez wiedzy o zawartości obrazu zakres pomocy, jaki jesteśmy w stanie zaoferować użytkownikowi, jest bardzo ograniczony. Jeśli użytkownik będzie zainteresowany zdjęciami psów na plaży, albo zawierającymi więcej niż cztery osoby — nie będziemy w stanie nic zrobić.
Czas najwyższy to zmienić.
Analiza obrazu za pomocą Computer Vision
Chciałbym zaproponować eksperyment. Krok po kroku będziemy analizowali obraz, którego w pełnej krasie jeszcze nie zaprezentuję, i zobaczymy, jak wiedza nasza oraz naszej aplikacji o nim będzie się pogłębiała z każdą przeprowadzoną operacją.
Wiemy, że nasz mózg jest zorientowany na interakcje międzyludzkie i rozpoznawanie twarzy, a rodzaj ludzki ma silny instynkt stadny. Spróbujmy więc w pierwszej kolejności przeanalizować obraz pod kątem obecności ludzi.
VNDetectHumanBodyPoseRequest odpowiada za detekcję sylwetek ludzkich, wynikowo zwracając listę punktów opisujących wykryte ciała na obrazie. Przy pomocy tej operacji jesteśmy w stanie nie tylko wykryć, ile osób znajduje się na obrazie, ale także w jaki sposób ułożone są ich ciała:
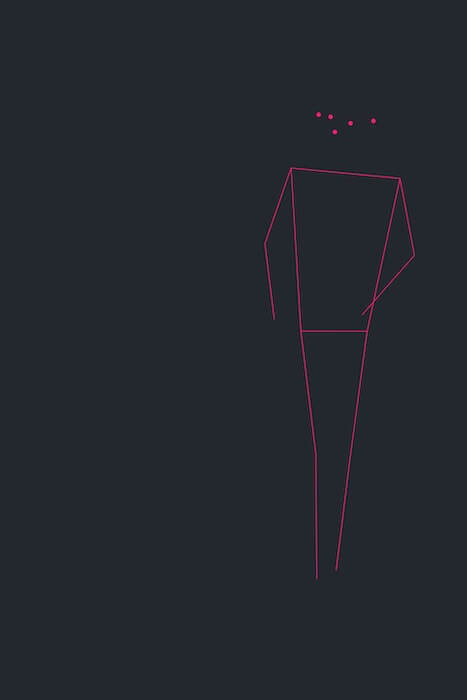
Na obrazie znajduje się jedna stojąca osoba. Kropki na górze oznaczają oczy, nos i uszy. Ich układ sugeruje, że głowa nie jest skierowana w stronę obiektywu, a patrzy raczej na coś znajdującego się obok.
Nie jest to może wiele w porównaniu do tego, ile bylibyśmy w stanie wywnioskować w 13 milisekund, gdybym zaprezentował od razu pełny obraz, ale w porównaniu do poprzedniego braku danych nawet ta (wydawałoby się) niewielka ich ilość pozwala na wiele. Możemy wnioskować o tym, co osoby na obrazach robią, w jakiej znajdują się sytuacji, ile ich jest. W efekcie możemy odróżnić zdjęcia, na których ludzie biegają, od tych, na których stoją czy siedzą, możemy też grupować zdjęcia pod względem ilości osób. A to dopiero początek.
Mowa ciała i gesty potrafią wiele powiedzieć o kontekście i bieżącej sytuacji, dlatego następnym, co zrobimy będzie użycie VNDetectHumanHandPoseRequest, aby odczytać dokładną pozycję dłoni i palców:
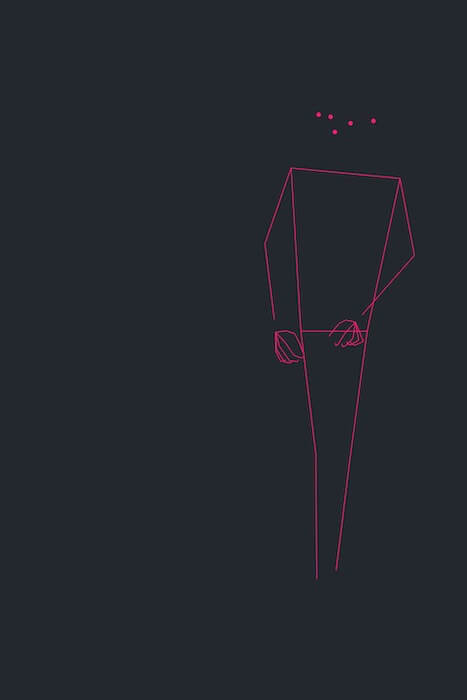
Obie dłonie są widoczne, czyli osoba widoczna na zdjęciu nie trzyma ich w kieszeniach. Układ palców może sugerować, że coś w nich trzyma, ale nie możemy być tego pewni. Nie widać tu żadnego standardowego OK, zaciśniętych pięści czy gestu wiktorii, co ułatwiłoby sprawę, więc idźmy dalej.
Mózg skupia się na twarzach, ponieważ niezwykle ważne dla nas jest poprawne odczytywanie reakcji innych ludzi. Spróbujmy w takim razie użyć VNDetectFaceLandmarksRequest, który służy do analizy cech twarzy. Jako wynik powinniśmy dostać owal twarzy, układ brwi, oczy ust i nosa:

Oczy są albo zamknięte lub (co już poprzednio zaczęliśmy podejrzewać) ta osoba skupia wzrok na czymś, co znajduje się obok i jest dosyć nisko. Mina wydaje się neutralna. Patrząc na układ brwi, oczy i ust nie widać typowych znamion zdziwienia, radości czy strachu.
Wiemy już całkiem sporo, ale dalej brakuje nam pewnych kluczowych informacji. Spróbujmy wykryć tzw. „istotne” obiekty tego obrazu przy pomocy VNGenerateObjectnessBasedSaliencyImageRequest. Istotne elementy to elementy znajdujące się na pierwszym planie zdjęcia:

Mamy wyraźne potwierdzenie obecności człowieka. Potwierdziło się także nasze przypuszczenie, że obok postaci coś się znajduje. Z kształtu przypomina zwierzę, więc spróbujmy zweryfikować nasze podejrzenie za pomocą VNRecognizeAnimalsRequest, który co prawda jest w tej chwili w stanie wykrywać tylko psy i koty, ale biorąc pod uwagę, że to popularne zwierzęta, szansa, że uzyskamy trafienie, wydaje się wysoka:
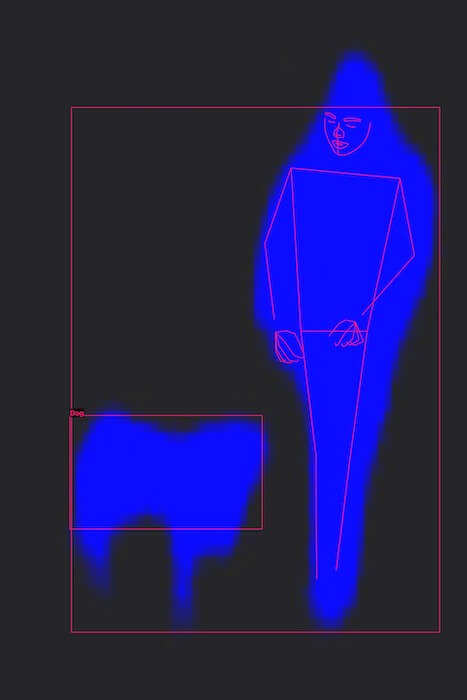
Otrzymaliśmy potwierdzenie, że na zdjęciu znajduje się człowiek oraz pies. Najprawdopodobniej są w trakcie zabawy lub spaceru. Niestety nie wiemy nic o kontekście zdjęcia. Czy to letni spacer w lesie czy zimowa zabawa w górach? Dlatego jako ostatnią operację przeprowadzimy VNClassifyImageRequest, który zwraca listę rzeczowników opisujących obraz:
- cord – 90%
- leash – 90%
- clothing – 81%
- jacket – 81%
- frozen – 77%
- liquid – 77%
- snow – 77%
- water – 77%
- animal – 71%
- canine – 71%
- dog – 71%
- mammal – 71%
Każdy wynik oprócz identyfikatora posiada również informację o pewności (confidence) modelu co do trafności. Smycz ma 90 proc., więc wszystko wskazuje, że (jak podejrzewaliśmy) jest to zdjęcie ze spaceru. Osoba ma na sobie kurtkę (81 proc. pewności) co w połączeniu z zaobserwowanym śniegiem (77 proc.) i lodem (77 proc.) pozwala przypuszczać, że zdjęcie przedstawia zimowy krajobraz. Potwierdzenie znajduje także informacja, że na obrazie znajduje się pies.
Na koniec — jak wygląda obraz w całości?
Zaprezentowane przeze mnie operacje to tylko część możliwości oferowanych przez Vision na iOS, ale nawet to robi wrażenie i jest bardzo użyteczne. Filtrowanie zdjęć, inteligentne kadrowanie, analiza sylwetek, znajdowanie ludzi i twarzy, zwierząt to tylko kropla w morzu nowych możliwości, które otwiera przed nami Vision w iOS, a Computer Vision w ogólności.
W tym artykule skupiłem się na analizie zdjęć, ale wszystko, o czym pisałem, można wykorzystać również w analizie video i to nie tylko w post processingu, ale i w czasie rzeczywistym. Oczywiście z racji wymagań obliczeniowych płynne procesowanie w czasie rzeczywistym wymaga mocniejszych urządzeń.
Na sam koniec zostawiłem prezentację obrazu, który analizowaliśmy. Jak trafnie udało się nam go zrozumieć, korzystając z informacji dostarczonych przez Vision, pozostawiam do indywidualnej oceny.

Zdjęcia pochodzą z unsplash.com.
Podobne artykuły
Ile zarabiają Android/iOS Developerzy? Porównujemy kwoty z ofert pracy z realnymi zarobkami w 2022 roku

Jak wygląda praca iOS developera tworzącego aplikację dla jednego z topowych klubów piłkarskich? Wywiad z Robertem Ignasiakiem

Jak zwiększyć swoją produktywność z Bluetoothem na iOS’ie? 4 praktyczne porady
