Jak zaoszczędziliśmy $84.000 rocznie przenosząc aplikację Ruby on Rails z Heroku na AWS
Oszczędności rzędu $84 tysięcy rocznie? Tak jest, o tyle właśnie udało nam się zmniejszyć koszty infrastruktury naszego klienta. Wymagało to zmigrowania aplikacji z Heroku do AWS oraz rekonfiguracji kodu — wszystko po to, żeby zoptymalizować wydajność produktu. Morał z tego taki, że pisanie aplikacji należy zlecić zespołowi, który zna się na rzeczy. W innym przypadku można skończyć tak, jak nasz klient — z pilnym zapotrzebowaniem na specjalistów DevOps i programistów, którzy naprawią błędy poprzedników.

Cyprian Kowalczyk. Założyciel i CEO firmy iRonin.IT, dostarczającej usługi programowania i DevOps klientom na całym świecie. Programista i pasjonat IT z 18-letnim doświadczeniem. Zwolennik nowoczesnych rozwiązań i innowacji, zaangażowany w świat biznesu i ekosystem startupowy. Prywatnie ojciec i zapalony kiteboarder. Członek Founders Kite Club. Uczestniczył w opisanym poniżej projekcie w latach 2014-2017.
Spis treści
Uwielbiamy Heroku, ale trzeba wiedzieć, jak z niego korzystać
Heroku to wspaniałe narzędzie PaaS (Platform as a Service) i nie powiemy o nim złego słowa. Świetnie się z nim pracuje, bo pozwala szybko uruchomić aplikacje webowe i oddać je użytkownikom. Wystarczy podpiąć swoje repozytorium kodu do Heroku i jednym kliknięciem można zdeployować apkę. Kontenery Heroku (Dynos) pozwalają na szybkie i proste skalowanie produktu — wystarczy dostosować odpowiedni suwak do aktualnych potrzeb, albo zautomatyzować ten proces przez zewnętrzny (lub wewnętrzny) serwis pozwalający na autoskalowanie. Heroku pozwala na łatwy deploy, łatwe skalowanie (przy założeniu, że wymagania projektowe i zastosowanie tego narzędzia odpowiadają jego możliwościom) — i nie wymaga do tego skomplikowanej konfiguracji. Życie programistów Ruby on Rails jest dzięki temu o wiele łatwiejsze (Heroku zbudowano z myślą o Ruby), a developerzy preferujący inne technologie, takie jak Java czy Node.js, mogą teraz skorzystać z tych samych benefitów.

Jedną z cech charakterystycznych Heroku jest to, że poprawne korzystanie z niego wymaga dyscypliny — bez niej koszty będą rosnąć niewspółmiernie do wzrostu hostowanej platformy i mogą wymknąć się spod kontroli. Dodatkowo ograniczenia Heroku (takie jak limit czasu trwania pojedynczego zapytania webowego, wynoszący 30 sekund, który powoduje, że przesył większych plików musi przechodzić bezpośrednio przez S3) oznaczają, że w niektórych sytuacjach (np. w przypadku wolnego połączenia sieciowego) aplikacja będzie przerywać przesył pliku i nie dostarczy użytkownikom pełnego doświadczenia.
Na szczęście istnieją inne platformy, które oferują dodatkową kontrolę nad parametrami przez bardziej niskopoziomowy dostęp do infrastruktury — należy do nich Amazon Web Services (AWS). AWS pozwala na przykład ustawić limit czasu trwania zapytań, co eliminuje wspomniany wcześniej problem i może prowadzić do sporych oszczędności.
Szybko rosnąca aplikacja do zarządzania nieruchomościami
Jeden z naszych klientów działa na rynku nieruchomości i posiada aplikację zbudowaną w Ruby on Rails. Pozwala ona użytkownikom — czyli pracownikom innych firm z tej samej branży, którzy mają pod opieką dziesiątki, a nawet setki nieruchomości — zarządzać inspekcjami, wycenami i zlecaniem prac podwykonawcom, a wszystko to w czasie rzeczywistym, z komputera lub telefonu.
Platforma pomaga im też śledzić przebieg napraw i prac służących utrzymaniu nieruchomości w dobrym stanie, co z kolei prowadzi do optymalizacji wykorzystania zasobów firmy, czyli samych nieruchomości i czasu ich pracowników. Zespół iRonin nie zbudował aplikacji, zostaliśmy później zaangażowani w pracę nad nią.
Zajęliśmy się wspieraniem projektu w zakresie:
- Tworzenia nowych funkcjonalności
- Codziennego utrzymania
- Poprawiania jakości kodu
- Uruchomienia i utrzymania infrastruktury w AWS (DevOps)
- Ogólnej poprawy wydajności
- Audytu bezpieczeństwa
Niestety aplikacja miała za sobą długą historię i zbyt wielu programistów, którzy nie zwracali wiele uwagi na kod, z którym pracowali — ani na stan, w jakim go zostawiali. Dobre praktyki programowania nie były stosowane w ogóle, co sprawiło, że utrzymywanie kodu i rozwijanie aplikacji stało się trudne i kosztowne — pomimo faktu, że dobre praktyki są mocno wpisane w filozofię Ruby. Dodatkowo wersje Ruby i Ruby on Rails były nieaktualne, co prowadziło do poważnych trudności w zastosowaniu nowszych wersji najważniejszych bibliotek. Historia jak z horroru! Ale największym popełnionym błędem było kompletne zignorowanie limitów Heroku i wytycznych dla tworzenia aplikacji webowych o wysokiej wydajności.
Kiedy aplikacja zaczęła szybko się rozwijać i pewien próg liczby użytkowników i ilości danych został przekroczony, utrzymywanie hostingu w Heroku prowadziło do utrudnień i niepotrzebnych kosztów w skalowaniu aplikacji. Sednem problemu było to, że niektóre zapytania były zbyt długie dla Heroku. Należała do nich jedna z najważniejszych czynności, jakie użytkownicy wykonywali w aplikacji. W efekcie zapytania były odrzucane, co powodowało bardzo nieprzyjemne doświadczenie dla użytkownika.
Problem pojawił się po kilku tygodniach prac związanych z przepisywaniem i usprawnianiem kodu — prac, które mieliśmy już rozplanowane na kilka miesięcy. Dodatkowo na co dzień musieliśmy radzić sobie z napływającymi zgłoszeniami w sprawie konkretnych funkcjonalności czy błędów. Przez źle napisany, stary kod i krytyczny stan, w jakim znalazł się system, wprowadzenie szybkich zmian i poradzenie sobie z odrzucanymi zapytaniami w krótkim czasie nie było możliwe.
Podsumowując: W tej chwili platforma ma ponad milion użytkowników. Codziennie korzysta z niej ponad tysiąc firm — zarządzają z jej pomocą całym procesem wynajmu ich nieruchomości. Kiedy trzeba było szybko przeskalować aplikację, okazało się, że zapytania webowe są zbyt długie i zostają odrzucone przez Heroku, powodując stres i frustrację wśród użytkowników.
Amazon Web Services też lubimy — i wiemy jak poprawnie korzystać z tej platformy
Heroku świetnie sprawdza się w wielu przypadkach, więc regularnie z niego korzystamy, ale wiemy, że czasami Amazon Web Services to lepsza opcja. AWS jest naprawdę dobrą alternatywą kiedy chcemy dostosować infrastrukturę do potrzeb aplikacji. Wsparcie dla takiego grzebania w systemie i wprowadzania drobnych zmian jest w AWS o wiele lepsze. Heroku skupia się na prostocie, a AWS daje pełną kontrolę nad infrastrukturą.
AWS to IaaS (Infrastructure as a Service), czyli infrastruktura jako usługa (w przeciwieństwie do PaaS — platformy jako usługi). Wymaga większej wiedzy i doświadczenia, aby efektywnie przygotować i uruchomić infrastrukturę dla aplikacji. Dla kontrastu, w Heroku większość tego procesu odbywa się automatycznie. AWS dostarcza ogrom usług dla twórców aplikacji — przechowywanie plików (czego brakuje w Heroku), bazy danych (relacyjne, dokumentowe, klucz-wartość), hosting witryn i powiadomienia dla użytkownika.
Prawda jest taka, że Heroku hostuje część swojej infrastruktury w AWS. Amazon pozwala nawet na budowanie platform z podejściem serverless, co daje wysoką skalowalność zasobów.
Krok 1: Dostrajanie Heroku Dynos dla wydajności równoległych procesów webowych i procesów w tle
Kiedy aplikacja do zarządzania nieruchomościami w czasie rzeczywistym, o której mowa w tym artykule, zaczęła gwałtownie rosnąć, stawała się coraz wolniejsza i wymagała dodatkowej, ręcznej pracy ze strony administratorów, utrzymujących system w dobrym stanie (np. restartowanie usług, które przytykały się pod napływem dużej liczby użytkowników). Zapytania webowe były odrzucane, kolejki procesów w tle szybko się zapełniały, a zdenerwowani użytkownicy platformy szukali odpowiedzi na napotkane problemy dzwoniąc na infolinię klienta. Musieliśmy działać szybko.
Zazwyczaj w przypadku problemów z wydajnością, Heroku daje kilka opcji na ich rozwiązanie. Przeważnie polega to na zwiększeniu liczby Dynos (a tym samym podniesieniu kwoty na fakturze). Dyno to kontener, w którym uruchamiane są procesy aplikacji. Może się to odbywać na współdzielonych hostach, jak w przypadku Standard-1x i Standard-2x Dynos, lub na dedykowanych hostach, z użyciem Performance-M i Performance-L. Każda z tych opcji oznacza inny koszt, zależny od ich specyfikacji technicznych. Można wykupić nawet 100 Dynos dla aplikacji, ale tylko 10 z rodzaju Performance-M lub Performance-L.
Taką strategię obraliśmy na początku — zmianę konfiguracji Dynos. Ponieważ architektura aplikacji składała się z kilku dodatkowych warstw usługowych z 6-7 składnikami klasy BackgroundWorker (gdzie jeden z nich delegował zadania do pozostałych), musieliśmy upewnić się, że skalowanie jednej warstwy nie spowolniłoby lub zablokowało innych.
Osiągnęliśmy częściowy sukces przez dopracowanie parametrów i liczby Dynos. Ruby on Rails do odpowiedzi na zapytanie webowe wymaga serwera aplikacji (jak Webrick, Passenger, Puma, Thin czy Unicorn). Niektóre serwery wspierają wiele zapytań jednocześnie (Puma, Thin, lub Passenger za pomącą wątków), a inne nie (Puma, Unicorn, Passenger za pomocą wielu procesów). To samo można powiedzieć o bibliotece Sidekiq, stworzonej do kierowania procesami w tle, której pojedynczy proces radzi sobie z wieloma workerami. Niestety kod, który zastaliśmy w aplikacji, nie był bezpieczny dla wątków, więc nie mogliśmy nawet skorzystać z serwerów wykorzystujących wątki.
Kluczową okazała się być konfiguracja. Ile workerów powinno być przypisanych do jednego procesu? Trzeba przyjrzeć się liczbie procesorów (i rdzeni) wykorzystywanych przez każde Dyno, oraz wykorzystaniu pamięci i blokowaniu I/O dla każdego workera, aby ocenić, ile można uruchomić na jednym Dyno.

Krok 2: Przeniesienie bazy danych PostgreSQL z Heroku do Amazon Relational Database Service (RDS)
Z czasem pojawił się nowy problem — nie mogliśmy w nieskończoność dodawać kolejnych Dynos, które wspierałyby kolejne workery. Baza danych Heroku przewiduje do 500 jednoczesnych połączeń. Im więcej mieliśmy background workerów, tym więcej połączeń otwierały.
Próbowaliśmy rozwiązać ten problem przy pomocy pgbouncer buildpack, ale nawet wyłączenie prepared statements nie pomogło w naszym przypadku (występowały błędy ActiveRecord::StatementInvalid dla pól array). Na tym etapie zderzyliśmy się ze ścianą. Kiedy skalowaliśmy Dynos, dobijaliśmy do 500 połączeń. Kiedy zmniejszaliśmy ich liczbę, aplikacja zwalniała. Do tego musieliśmy działać szybko, żeby utrzymać aplikację w działaniu pomimo wysokiego obciążenia.
Wtedy właśnie zdecydowaliśmy przenieść bazę danych z Heroku — to było coś, co mogliśmy zrobić szybko, bo baza była połączona dość luźno z pozostałymi elementami infrastruktury. Co ciekawe, bazy danych Heroku są hostowane w AWS i jedyne, co musieliśmy zrobić, to zmienić URL i uprawnienia bazy danych. Natychmiast zdecydowaliśmy się na Amazon RDS z ciągłą replikacją (żeby utrzymywać back-up w czasie rzeczywistym, na wypadek poważnej awarii) i zautomatyzowanym procesem wykonywania całościowych kopii zapasowych każdego dnia.
Niestety nie było sposobu na szybką migrację przez skopiowanie danych z serwera master w Heroku na serwer slave w AWS RDS. Heroku po prostu nie pozwala zewnętrznym bazom danych na takie połączenia. Ponieważ szybka i łatwa opcja była niewykonalna, musieliśmy zrobić dump danych w Heroku i manualnie przenieść je do AWS — co oznaczało 6 godzin przestoju aplikacji. Zaplanowaliśmy jednak cały proces z wyprzedzeniem i przygotowaliśmy się na tę sytuację. Uruchomiliśmy nocne maintenance mode i przenieśliśmy dane. Jako że członkowie zespołu iRonin pracują z różnych stref czasowych, wykonaliśmy tę pracę w okresie niskiego ruchu w aplikacji bez utrudniania życia zespołowi.
Stworzyliśmy potężną instancję (16 rdzeni, 64GB pamięci RAM), żeby dograć ustawienia workerów i nie przejmować się, że baza danych mogłaby być wąskim gardłem. Przy takich parametrach mogliśmy uruchomić ponad 5000 równoległych połączeń bez żadnego problemu .
Funkcja Amazon RDS’s Multi Availability-Zone pozwoliła nam skalować instancję w górę i w dół bez przestojów. Dzięki temu mogliśmy się skupić na poprawianiu samej aplikacji i workerów. Amazon RDS dał nam dostęp do parametrów bazy danych, które normalnie znalazłyby się w lokalnym pliku postgresql.conf. To pozwoliło nam usprawniać niskopoziomowe ustawienia Postgresa, kiedy pojawiała się potrzeba.
Krok 3: Migracja aplikacji z Heroku do Amazon Web Services
Po migracji mogliśmy wprowadzić więcej połączeń do bazy danych, ale nie uzyskaliśmy oczekiwanej wydajności — i tu z pomocą przyszło nam AWS.
W Heroku, Dynos są umieszczane w instancjach współdzielonych z innymi Dynos różnych aplikacji (chyba, że używamy Dyno performance). Jeśli mamy akurat pecha i nasze Dyno znajduje się w instancji z innymi Dynos o wysokim zapotrzebowaniu na zasoby, wydajność naszego Dyno może być niższa. Natomiast w AWS możemy mieć 1-2 instancje z wieloma równoległymi procesami i w pełni wykorzystać zasoby każdej instancji.
Kolejnym problemem, który musieliśmy rozwiązać, były zapytania z synchronicznym przesyłem plików. Przy 30-sekundowych timeoutach w naszej aplikacji hostowanej na Heroku, użytkownicy z wolniejszym połączeniem sieciowym spotykali się z błędem. Aplikacja powinna była przesyłać pliki prosto do S3 bez angażowania w to naszego back-endu — ale nie została napisana w ten sposób zanim zajęliśmy się projektem.
Naprawienie tego problemu jak najszybciej było ważne dla klienta. Przez przedłużenie zapytań i ugaszenie “pożaru”, daliśmy sobie możliwość przepisania fragmentu kodu, który zajmował się przesyłem plików. W AWS, mogliśmy zwiększyć długość zapytań bez problemu — ponieważ mieliśmy bezpośredni dostęp do konfiguracji nginx. Było to tymczasowe rozwiązanie, ale odblokowanie aplikacji dało naszemu klientowi czas na udobruchanie zdenerwowanych użytkowników — a nam na pracę nad dalszymi usprawnieniami. Programowanie idzie szybciej w mniej stresującym środowisku!
Ponieważ przeniesienie infrastruktury do AWS pomogło upiec dwie pieczenie przy jednym ogniu, zaczęliśmy eksperymentować. Ustawiliśmy background workery w AWS Opsworks żeby sprawdzić, czy byłyby bardziej wydajne niż te, które uruchomiliśmy w Heroku. Różnica między nimi była znaczna. Nasza instancja w AWS była w stanie wykonać ok. 80,000 zadań aplikacji (w tym sporo procesowania plików PDF) w kilka godzin — w przeciwieństwie do Heroku, w którym ten sam efekt osiągnęliśmy w kilka dni (pojedyncza instancja r4.2xlarge EC2 kontra 40x “Standard-2X dynos” i 2x 4 “Performance-M Dynos”). W tym momencie nie było już odwrotu. Przygotowaliśmy stack produkcyjny z dwiema instancjami webowymi (z load-balancingiem) i pojedynczą instancję dla workerów. Musieliśmy też zmigrować Redisa i ElasticSearch. Nie było to skomplikowane — wystarczyło wrzucić snapshot bazy Redisa na S3 (wykonaliśmy tam tylko dump Redisa), a do reindeksacji Elastica mieliśmy już napisane skrypty, więc to też nie stanowiło problemu.
Po migracji wreszcie mieliśmy całą infrastrukturę w AWS: bazę danych, Redis i aplikację z warstwami dla workerów. Żeby przygotować instancje w AWS Opsworks, nasz zespół przygotował niezbędne cookbooki i skrypty do deploymentu, automatyzujące ustawianie parametrów serwerów i wypuszczanie nowych wersji aplikacji.
Oszczędności i poprawa wydajności
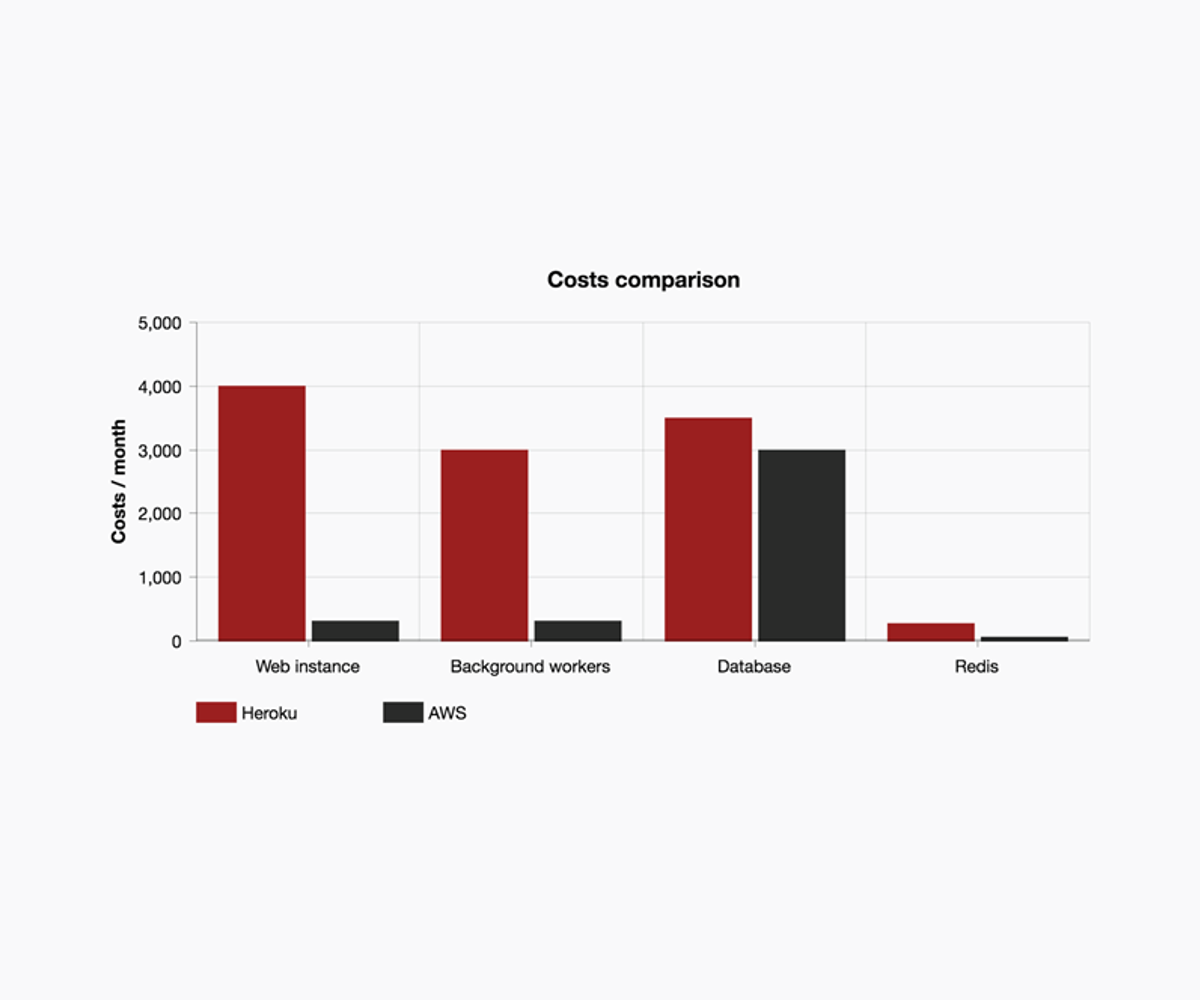
Zanim rozpoczęliśmy migrację do AWS, rachunki z Heroku wyglądały następująco:
- Standard 2x ($50 miesięcznie za sztukę): 40 = $2000 na miesiąc
- Performance-L ($500 miesięcznie za sztukę): 8 dynos = $4000 na miesiąc
- Performance-M ($250 miesięcznie za sztukę): 4 dynos = $1000 na miesiąc
- RedisGreen $269 na miesiąc
- Postgres Premium6 $3500 na miesiąc
Czyli w sumie $10,769 miesięcznie.
Po migracji, koszty utrzymania infrastruktury w AWS były znacznie niższe:
- m4.xlarge ($157 miesięcznie): 2 = $314 miesięcznie (web instances)
- c3.2xlarge ($307 miesięcznie: 1 = $307 miesięcznie (za wszystkie background workery)
- cache.m3.medium $65 miesięcznie
- Postgres db4.mx10.large (40 vCPU i 160GB RAM z Multi A-Z i dedykowany dysk SSD do 2000 IOPS) $5875 miesięcznie
Co w sumie dało $6561 miesięcznie — i to przy większej wydajności! To oszczędność $50,500 rocznie! Wow!
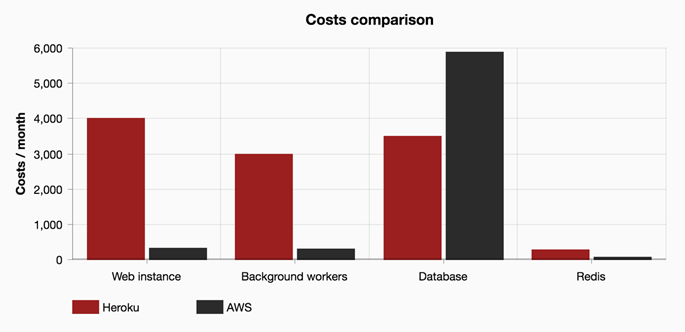
Po utrzymaniu zaprezentowane wyżej konfiguracji w AWS przez kilka miesięcy zauważyliśmy, że nie wykorzystaliśmy wszystkich dostępnych zasobów:
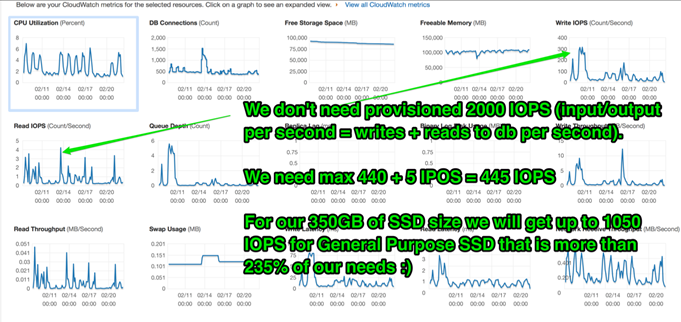
Po paru tygodniach udało nam się wyskalować instancje bazy danych w dół i uzyskać kolejne:
- Zmiana z dedykowanego SSD na zwykłe SSD — potrzebowaliśmy tylko 415 IOPS, a zwykły dysk SSD 350GB dostarcza 1050 IOPS)
- Zmiana instancji na db.r3.4xlarge (16 vCPU 122GB RAM z Multi A-Z)
Cena całego stacka produkcyjnego powinna wynieść około $3717 miesięcznie. W ten sposób oszczędzamy kolejne $2850 na miesiąc — czyli $34,200 rocznie!

Odkąd wdrożyliśmy nową implementację, otrzymujemy tylko pozytywny feedback od użytkowników na temat działania aplikacji! To nie wszystko. Liczba nowych użytkowników, rozpoczynających swoją przygodę z aplikacją, wzrosła. A kiedy użytkownicy są szczęśliwi, a ich liczba rośnie, wiadomo, że wszystko zmierza w dobrym kierunku.
Wnioski — $84,000 oszczędności rocznie i szczęśliwi użytkownicy!
Lubimy wszystkie platformy hostingowe, z którymi pracujemy i uważamy, że wszystkie firmy oferujące takie usługi — Amazon Web Services, Heroku, DigitalOcean czy Linode — mają swoje zalety. Ich funkcjonalności różnią się od siebie i powodują, że ich koszt i najlepsze przypadki wykorzystania też są różne.
Jeśli czujesz, że koszty infrastruktury dla twojej aplikacji webowej są zbyt wysokie, nie czekaj i skontaktuj się z nami. Chętnie pomożemy ci ocenić, ile możesz zaoszczędzić. Przypadek opisany w tym artykule jest dość skrajny, bo udało nam się oszczędzić zatrważającą kwotę $84,000 rocznie i znacznie poprawić wydajność aplikacji w krytycznym dla niej momencie, nie spędzając długich tygodni na przepisywaniu całego kodu (wciąż pracujemy nad refaktoringiem).
Zachęcamy do skontaktowania się z nami w celu oceny jakości kodu i audytu bezpieczeństwa aplikacji — obydwie te sprawy traktujemy bardzo poważnie i możemy pokazać, dlaczego warto się nimi zainteresować. Słabej jakości kod może spowodować katastrofę w odległej przyszłości, albo nawet jutro.
Artykuł został pierwotnie opublikowany na iRonin.it.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
