Zalety i wady korzystania z TensorFlow w środowisku produkcyjnym

Wraz ze wzrostem popularności głębokich sieci neuronowych pojawiło się wiele bibliotek i frameworków, które mają na celu usprawnienie pracy w tym obszarze. Miałem okazję korzystać z niektórych narzędzi, dlatego chciałbym się z Wami podzielić swoją opinią i obserwacjami na temat pracy z nimi. Zacznijmy od Tensorflow.

Tomasz Bonus. Deep Learning Researcher w NeuroSYS. Pasjonuje się sztuczną inteligencją, data science i przyszłością technologii. Absolwent Uniwersytetu Wrocławskiego, gdzie ukończył studia na kierunku Fizyka komputerowa. Od prawie dwóch lat zajmuje się deep learningiem w NeuroSYS.
Jedną (często uważaną za najlepszą) z bibliotek, którą możecie wykorzystać w uczeniu maszynowym i sieciach neuronowych, jest Tensorflow. Tensorflow to open-source’owy framework stworzony przez Google’a do obliczeń numerycznych. Oferuje on zestaw narzędzi służących do projektowania, trenowania oraz douczania (ang. fine-tuning) sieci neuronowych.
W NeuroSYS używamy go do rozwiązywania problemów związanych z przetwarzaniem i rozpoznawaniem obrazów, m.in. do klasyfikacji i generowania sztucznych próbek, a także do detekcji obiektów w czasie rzeczywistym (więcej o wczesnych etapach projektu związanego z klasyfikacją bakterii możecie dowiedzieć się tutaj).

Spis treści
Zalety
1. TensorBoard
TensorBoard to narzędzie służące do wizualizacji danych. Pozwala prezentować w czytelny sposób m.in. grafy obliczeniowe sieci neuronowych (ang. computational graph), dane wejściowe, dane wyjściowe czy postęp treningu. Dzięki temu ułatwia ono znajdowanie błędów w architekturze oraz optymalizację sieci neuronowych. A wszystko to przy użyciu zaledwie kilku linijek kodu.
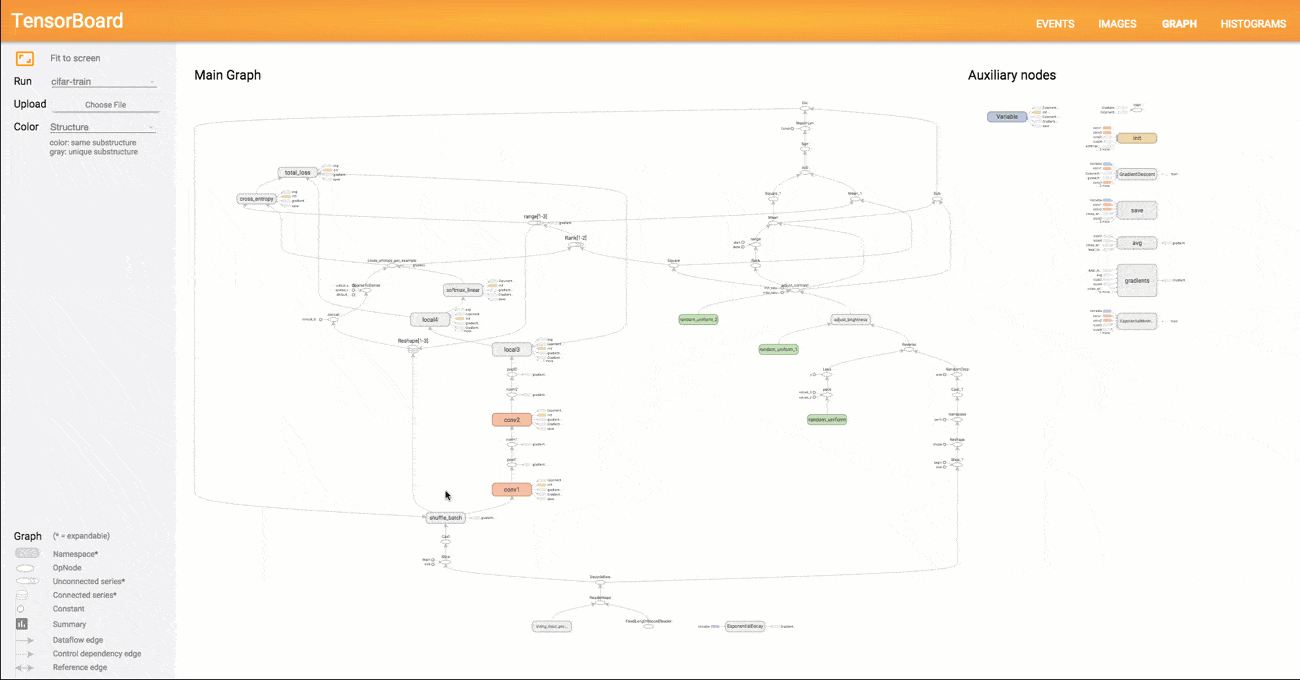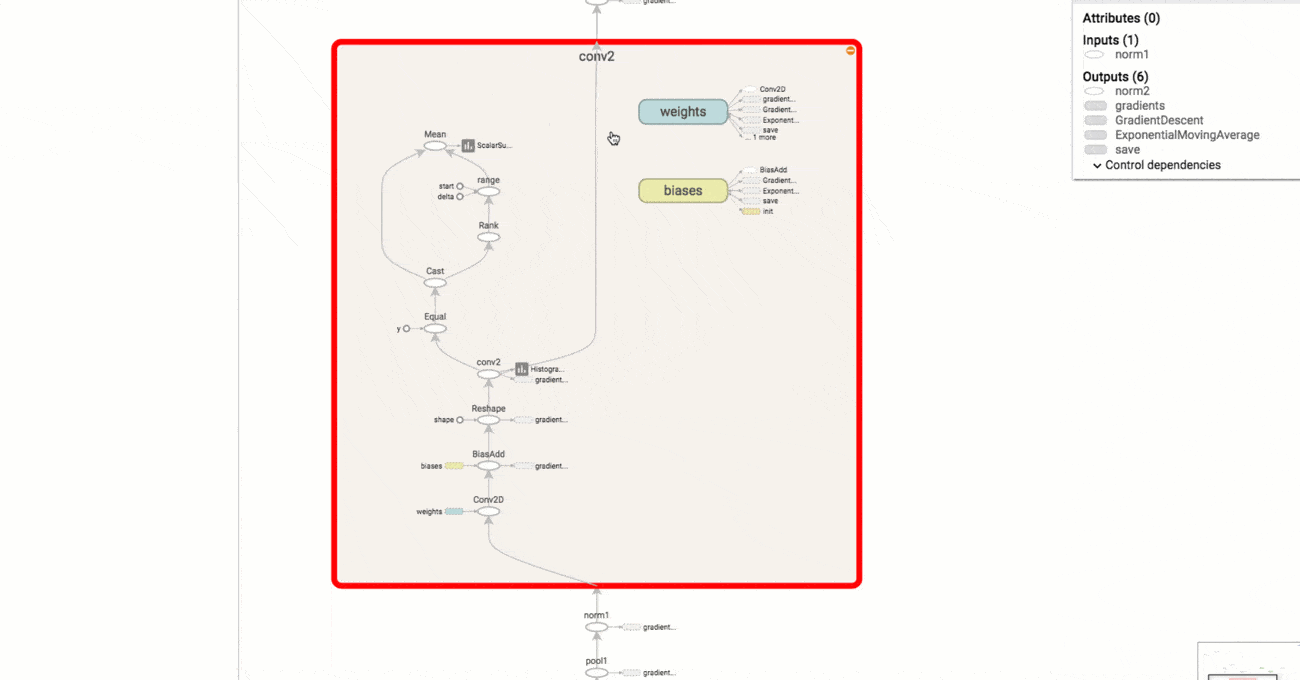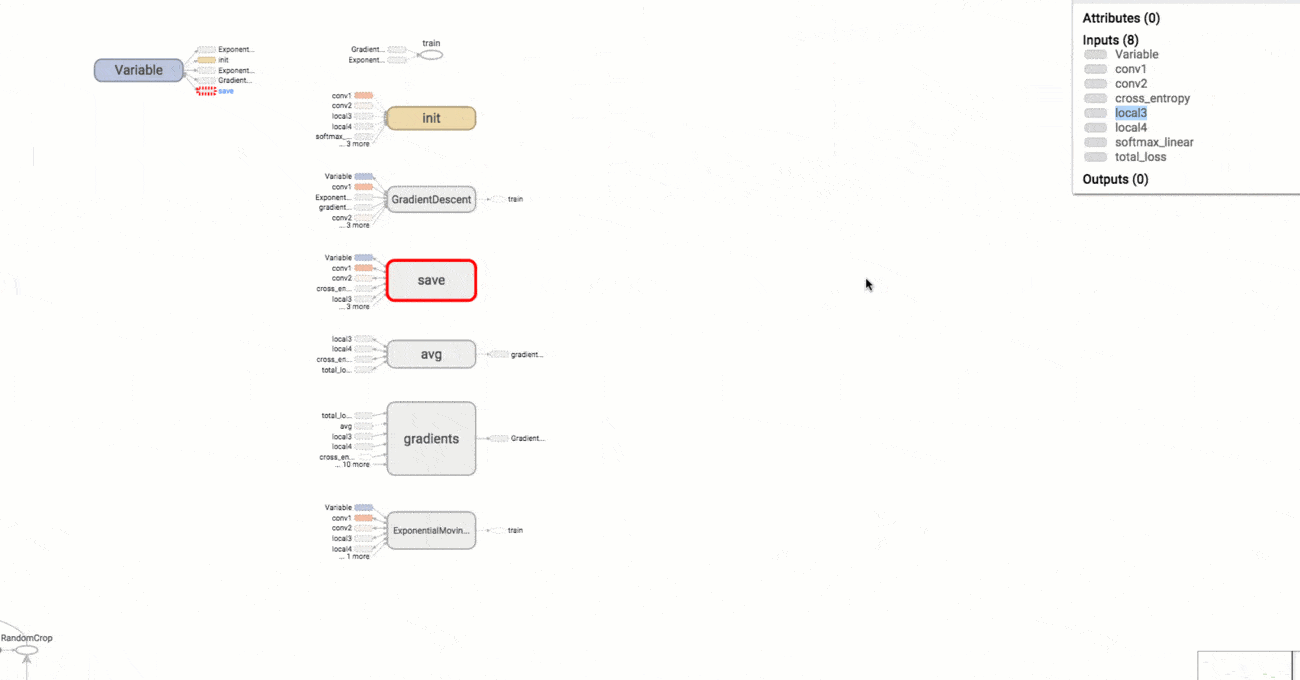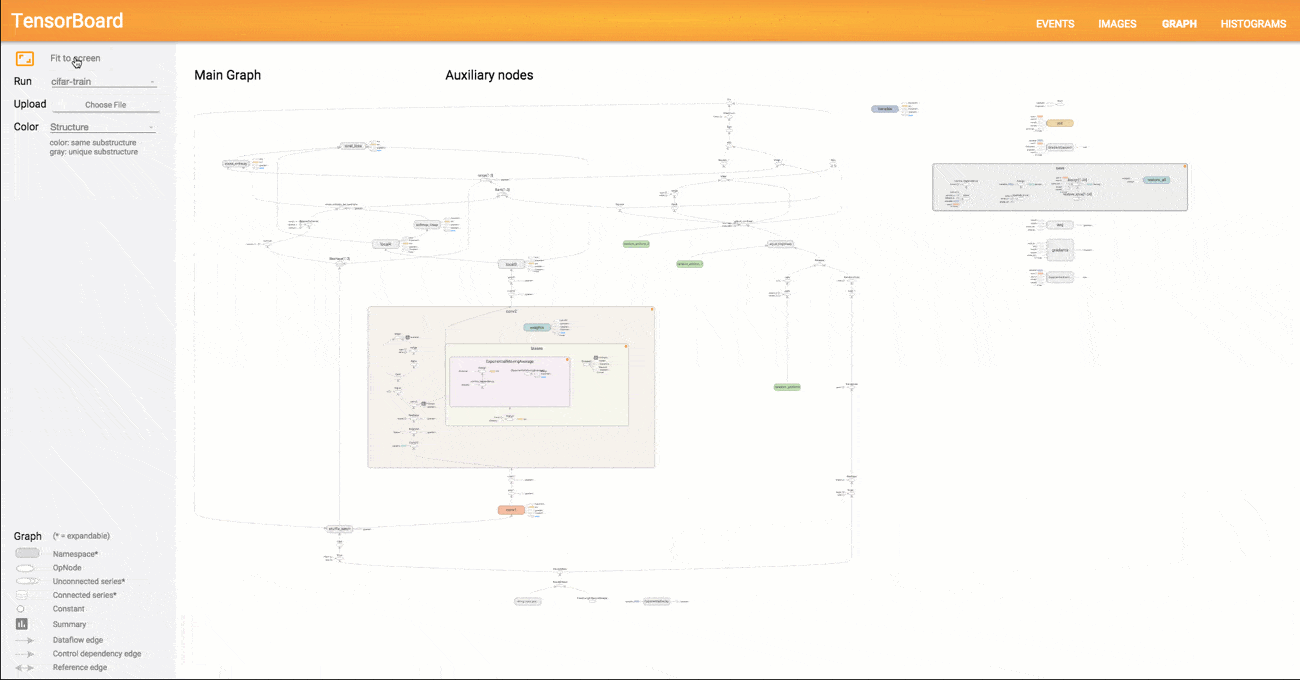
(Wizualizacja wykresu w TensorBoard)
W ten sposób możecie łatwo zwizualizować dane w TensorBoard:
# define from which variables generate summary from
loss_summary = tf.summary.scalar('loss_1', loss1)
image_summary = tf.summary.image('generated_image', result)
# merge whole summary into one instruction
summary = tf.summary.merge([loss_summary, image_summary])
# define summary writer
summary_writer = tf.summary.FileWriter('path/to/summary/',
graph=tf.Session().graph)
# run summary along computation
result, summary_values = tf.Session().run([network_output, summary],
feed_dict={input: input_data})
#write summary to disk and view it in TensorBoard
summary_writer.add_summary(summary_values)
2. Łatwe dzielenie się wytrenowanymi modelami
Za pomocą TensorFlow można łatwo dzielić się wytrenowanymi modelami. Wydaje się, że powinna to być podstawowa funkcjonalność, jednak wciąż nie jest ona standardem dla różnych frameworków.
Wiele frameworków wymusza podanie pełnego kodu modelu w celu załadowania jego parametrów. Natomiast TensorFlow wymaga jedynie pliku zawierającego wagi oraz nazw warstw potrzebnych do inferencji (warstwa wejściowa jest najważniejsza, ponieważ bez niej nie możemy uruchomić grafu obliczeniowego).
Dzięki temu wytrenowany model może zostać użyty (bez przepisywania lub ponownego kompilowania) w różnych projektach bez względu na użyty język programowania. Wciąż nie jest to jednolinijkowiec, ale przynajmniej nie trzeba definiować modelu od nowa:
# imported graph to be used as default later
imported_graph = tf.Graph()
with imported_graph.as_default():
# read graph definition from file
graph_def = tf.GraphDef()
with tf.gfile.GFile('path/to/model', 'rb') as model:
# parse it
graph_def.ParseFromString(model.read())
# and import to TensorFlow
tf.import_graph_def(graph_def, name="imported_model")
with imported_graph.as_default():
output = tf.Session().run("output:0", feed_dict={"input:0": our_input})
3. Obsługa wielu języków
TensorFlow został zaprojektowany do obsługi wielu języków programowania. Oficjalnie wspierane są: Python, C ++, JavaScript, Go, Java i Swift, ale tylko Python, jako najczęściej używany, posiada wsparcie dla wszystkich dostępnych funkcjonalności.
Ze względu na dużą popularność, społeczność TensorFlow utworzyła wiązania (ang. bindings), aby korzystać z framework’a w innych językach, takich jak C # (którego używałem i muszę przyznać, że jest to całkiem niezłe rozwiązanie) czy Ruby.
Pozwala to deweloperom używać modeli uczenia maszynowego do rozwiązań stacjonarnych, mobilnych, a nawet aplikacji internetowych.
Wady
1. Nieuporządkowany kod
Społeczność rozwijająca TensorFlow już nad tym pracuje i zapowiedziała, że w wydaniu 2.0 problem będzie rozwiązany. Niestety, obecny framework jest niespójny.
Której metody użyć?
- tf.nn.conv2d
- tf.nn.convolution
- tf.layers.conv2d
- tf.layers.Conv2d
- tf.contrib.layers.conv2d
- tf.contrib.layers.convolution2d
Nawet wpisanie „tf conv2d” w Google prowadzi do wyświetlenia 3 z tych opcji, co jest naprawdę frustrujące, kiedy chcemy się tylko dowiedzieć, którą funkcję wykorzystać.
2. Konieczny jest dodatkowy kod
Jak widać w powyższych przykładach, ilość kodu potrzebnego do dodania funkcjonalności nie jest zbyt duża. Niemniej jednak, konwencja nazewnictwa może być niespójna, a złożoność modułów przytłaczająca.
Każde obliczenie musi być wywołane z poziomu obsługi sesji. Stwarza to sytuację, w której korzystanie z TensorFlow jest jak używanie języka wewnątrz innego języka. Można zapomnieć o pisaniu czystego kodu pythonowego. Nawet coś tak prostego jak pętla for, wymaga nazwania przy użyciu odpowiednika TensorFlow.
Czasem dokumentacja nawet “zapomina” poinformować, że trzeba zawrzeć dodatkowe instrukcje w swoim kodzie, aby pewne rzeczy działały. Stało się tak, gdy próbowałem napisać swój własny moduł ładujący dane za pomocą pipeline’u TensorFlow i użyć wielu wątków roboczych (ang. workers), by zapewnić zrównoleglenie obliczeń przygotowujących dane.
Jednakże, co nie zostało zawarte w dokumentacji, potrzebne jest ręczne uruchomienie tych wątków. Bez tej części cały skrypt jest po prostu wstrzymany (nie wyświetla się żaden błąd czy ostrzeżenie) i czeka aż wątki robocze, które nigdy nie zostały uruchomione, dostarczą dane.
To jest przykład pokazujący, że te moduły nie zawsze są ze sobą idealnie połączone, co prowadzi do braku komunikacji między nimi i finalnie do sytuacji jak opisana powyżej.

3. Częste wydania nowej wersji
Dla niektórych to może brzmieć jak zaleta. Jednak w rzeczywistości w środowisku produkcyjnym lepiej unikać nowych wersji wydawanych co 1-2 miesiące, zwłaszcza jeśli mogą wpłynąć na kompatybilność wsteczną.
Jest to wyjątkowo szkodliwe podczas stosowania powiązań z innymi językami, jak TensorSharp w języku C#. Mój zespół napotkał kiedyś następujący problem: po wprowadzeniu nowych argumentów w jednej z powszechnie używanych funkcji, straciła ona kompatybilność z TensorSharp. Najłatwiejszym rozwiązaniem okazało się użycie starszej wersji TensorFlow i ponowny export całego modelu.
To zrozumiałe, że pewne zmiany w tak szybko rozwijającym się frameworku są nieuniknione, ale być może społeczność skorzystałaby bardziej, gdyby nowe wersje były rzadsze, a więcej uwagi poświęcono na spójność framework’a.
Kilka wskazówek ułatwiających pracę z TensorFlow
Wskazówka #1
Dla uzyskania lepszej wydajności, należy unikać uruchamiania sesji do wykonania pojedynczych operacji. Przetwarzanie wielu operacji jedna po drugiej zajmie więcej czasu niż uruchomienie jednej sesji do wykonania wszystkich na raz. Jest to możliwe dzięki zdolności TensorFlow do równoległych obliczeń, jednocześnie pozwala uniknąć narzutu związanego z wielokrotnym inicjowaniem sesji obliczeniowej.
Wskazówka #2
Unikajcie bałaganu w kodzie! To jest raczej ogólna rada, ale kluczowa podczas pracy z TensorFlow. Dobrym pomysłem jest przeniesienie definicji sieci do innego pliku. W ten sposób można później łatwo wprowadzać zmiany, bez konieczności przeszukiwania dużych plików.
Podsumowanie
Pomimo wad, TensorFlow jest jednym z najczęściej stosowanych frameworków do projektów związanych z uczeniem maszynowym, używanym przez gigantów takich jak IBM, Twitter, 9GAG, Ocado… i (niespodzianka) Google. Jest również jednym z moich ulubionych framework’ów, chociaż bardzo bym sobie życzył, żeby wyżej opisane wady zostały pewnego dnia naprawione (a im wcześniej, tym lepiej).
Jednocześnie uważam, że TensorFlow może być trochę przytłaczający dla początkujących użytkowników, ponieważ często zapewnia wiele implementacji tych samych funkcjonalności. Może to być mylące dla osób bez doświadczenia lub podstawowej wiedzy na temat różnic między sugerowanymi implementacjami. Jeśli to kogoś przeraża, lepiej wybrać prostsze alternatywy.
Artykuł został pierwotnie opublikowany na neurosys.com.
Podobne artykuły
Podejście do zmniejszania kosztów przetwarzania danych na przykładzie Azure Databricks

Data management, data governance i data modernization - jak okiełznać proces zarządzania danymi w organizacji

Big Data - klęska urodzaju czy złoty Graal? Praktyczne metody wykorzystania potencjału danych
Dane 1,3 mln użytkowników Clubhouse do pobrania? To nie wyciek, to data scraping

Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Migracja do chmury? Wypełnij ankietę i sprawdź, jak wygląda ten proces u innych!

Analiza infrastruktury i danych IoT. Wybór bazy
