Zaczyna się od krawędziowania. O technologii rozpoznawania obrazu
– Świat jest bardzo złożony, składa się z wielu elementów. Nie jesteśmy w stanie za pomocą jednego algorytmu rozpoznać wszystkiego – człowieka, drzewa, budynku itp. – powiedział nam Jakub Romanowski, Head of Research & Development w Senfino. Rozmawialiśmy z nim o technologii rozpoznawania obrazu wykorzystywanej w medycynie oraz o tym, jak zacząć pracę w tej branży. Zobaczcie, czego dowiedzieliśmy się z tej rozmowy.

Jakub Romanowski. Head of Research & Development w Senfino. Absolwent Politechniki Częstochowskiej. Zarządza i pracuje z zespołem R&D. Główny nurt rozwoju oprogramowania i badań to systemy rekomendacji, ale i szereg wyzwań z dziedziny medycyny, nauki i przemysłu. Praca codzienna to szeroko pojęta sztuczna inteligencja z głównym naciskiem na systemy neuronowo rozmyte i sieci neuronowe. Dzięki ciągłej współpracy z uczelniami oraz czołowymi naukowcami z dziedziny sztucznej inteligencji ciągle podnosi kwalifikacje zespołu R&D Senfino.
Spis treści
Na początku chciałem zapytać o to, co software house Senfino ma wspólnego z technologią rozpoznawania obrazu?
Jakub Romanowski: Senfino wydzieliło swój kolejny dział, który nazywa się Senfino Technologies i zajmujemy się w nim głównie R&D. Rozpoznawanie obrazu jest tak naprawdę nieodłącznym elementem naszej działalności. Przewija się ono chyba w każdej płaszczyźnie R&D i możemy ją spotkać choćby w medycynie.
W jaki sposób wykorzystuje się technologię rozpoznawania obrazu w medycynie? Możesz podać jakiś przykład?
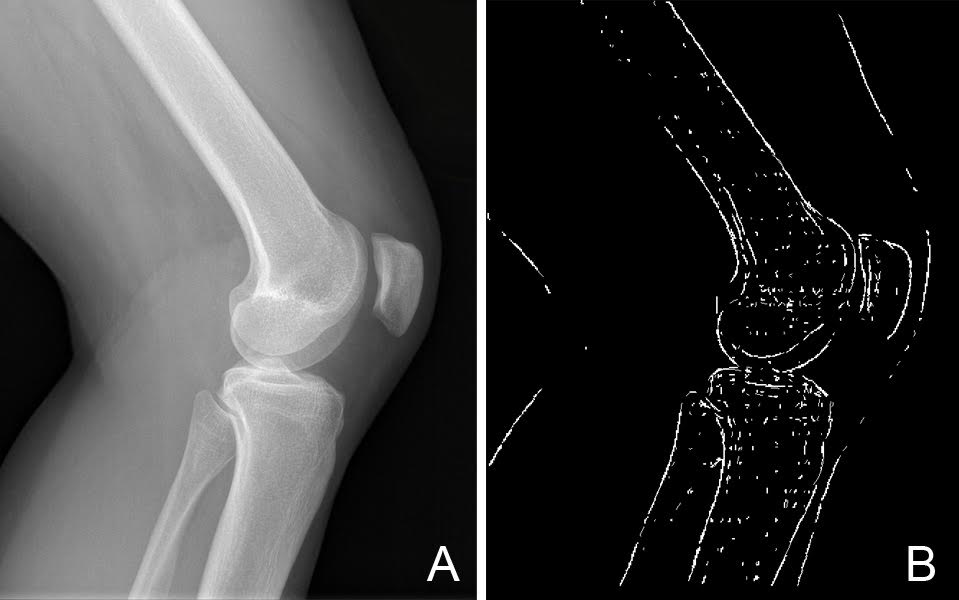
JR: Wykorzystuje się ją w odczytywaniu tego, co jest na zdjęciu rentgenowskim (RTG), a metoda rozpoznania zawartości zdjęcia składa się zwykle z kilku algorytmów. Podstawą dla wielu algorytmów przetwarzania obrazu jest krawędziowanie, którego celem jest np. wyznaczenie granic tkanki miękkiej, czyli mięśni lub tłuszczu, od twardej, czyli kości. Najważniejsze oczywiście jest zajęcie się właśnie kością, bo chodzi głównie o jej uszkodzenie czy złamanie. Często badana jest osteoporoza, czyli właściwości kości i to jest jeden z pierwszych etapów, w którym zagłębiamy się jeśli chodzi o jakość lub strukturę kości. Sporym problemem w odczytywaniu zdjęć jest to, że są one dostarczane w różnych rozdzielczościach i różnej jakości. Wynika to z tego, że są robione przez różnego rodzaju aparaturę…
… co pewnie rodzi wiele problemów. Jakich?
JR: Problemem jest to, że zdjęcia są różnej jasności. Można jednak ustawić średnią jasność piksela w otrzymywanym obrazie. Jest to jeden z najbardziej zautomatyzowanych sposobów, żeby nie zawsze ręcznie otrzymywać wartość progowania wymaganą do detekcji krawędzi. Można ustawić średnią wartość pikseli zdjęć i proporcjami je poprzeliczać. Czasami w zdjęciu pojawiają się szumy, które nazywamy „kaszą” osadzającą się na czarnych obszarach. Wtedy możemy dokonywać operacji wyostrzenia obrazu lub rozmycia – nie ma zależności, stosujemy kilka zabiegów. Część z tych mechanizmów można wykonać przed krawędziowaniem.
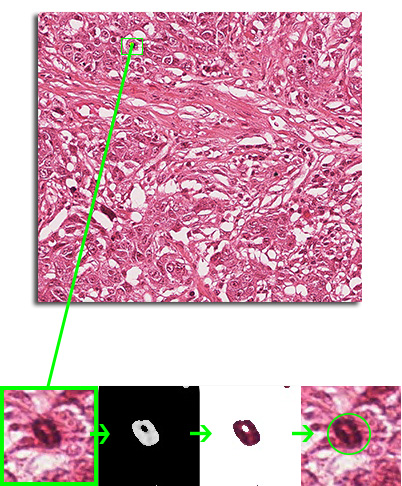
Czy przez to, że w Polsce badania RTG wykonuje się na słabym sprzęcie, do analizy zdjęć rentgenowskich zawsze potrzebny jest człowiek i tego zadania nie może samodzielnie wykonać algorytm?
JR: Myślę, że tak. Słaba jakość obrazu to jeden z największych problemów, na który natrafiłem podczas badań. Placówki zagraniczne mają dodatkowo rozwiniętą aparaturę RTG, to znaczy, że wykonują dwa zdjęcia o różnej sile natężenia promieniowania. Dobra jakość tych zdjęć w połączeniu z dwoma wartościami natężenia promieniowania pozwala odpowiednim algorytmom rozdzielić tkanki miękkie od tkanek twardych. Nie wszystkie też szpitale w Polsce w ogóle obsługują transmisję cyfrową obrazu, więc zdjęcia są tylko w formie fizycznej, a ich zeskanowanie jeszcze bardziej obniża jakość RTG.
Czy samo krawędziowanie coś daje?
JR: Daje i nie daje. Jest to podstawa do tego, by określić, gdzie znajduje się region zainteresowania na zdjęciu. My widzimy, gdzie znajduje się tkanka miękka i twarda – to tyle. Krawędziowanie nam w tym pomaga, dzięki niemu wiemy, na czym musimy się skupić i co nas interesuje.
Ile trwa pierwszy i drugi etap? Czasowo, ile wam to zajmuje?
JR: Na przeciętnej klasy laptopie są to sekundy. Po sekundzie, może półtorej mielibyśmy już wykonane obliczenie.
Wydawało mi się, że rozpoznanie/klasyfikacja obrazu mogłoby być potrzebne – nie wiem – w sytuacji, gdy komuś robimy zdjęcie i chcemy wiedzieć, kim dana osoba jest. Albo lecimy samolotem, robimy zdjęcie lasu z góry i dzięki fotografii dowiadujemy się, gdzie jesteśmy i co to za las.
JR: Przykłady, które wymieniłeś nie są aż tak proste do zrealizowania, choć nie niemożliwe. Świat jest bardzo złożony, składa się z wielu elementów. Nie jesteśmy w stanie za pomocą jednego algorytmu rozpoznać wszystkiego – człowieka, drzewa, budynku itp. Niektóre rzeczy lub organizmy tak, ale złożoność procesu rozpoznawania obiektów jest na tyle duża, że to wszystko musi być pojmowane oddzielnie. W 2008 roku powstał dosyć istotny algorytm o nazwie SURF. Wyszukuje punkty kluczowe obrazu obliczając ich charakterystyczne wartości. Zrobiłem, nie tylko zresztą ja, sporo badań na ten temat i potwierdzam, że jest to algorytm bardzo wydajny. Świetnie nadaje się do śledzenia osoby np. podczas wideo. Zrobienie jednak zdjęcia Giewontu przeze mnie w dzień, a przez ciebie w nocy, to już inny obraz. Ważne jest bowiem oświetlenie, które w rozpoznawaniu obrazu ma decydujące znaczenie.
Jak od środka działa algorytm, który powie, że masyw górski, który widzę przed sobą to Giewont?
JR: Algorytm rozpoznaje punkty kluczowe obiektów w danym obrazie. W rozpoznaniu tego pomaga również mechanizm związany z krawędziowaniem, o którym mówiliśmy przed chwilą. Gdy zaczniemy szukać punktów kluczowych między niebem a górą, to one tam wystąpią ze względu na gradient koloru. Schodząc z góry obrazem napotkamy na wierzchołek, szczelinę czy coś, co jest dla Giewontu charakterystyczne. Żeby w oparciu o punkty kluczowe bezbłędnie odczytać, że dana góra to Giewont, zdjęcie musiałoby być zrobione w możliwie identycznych warunkach. Istnieją też inne metody jak np. dopasowanie do zadanego kształtu-obrysu całej góry, lub jej najbardziej charakterystycznych elementów ale to temat na kolejne rozmowy.
Czy są algorytmy, które mają 100% skuteczności?
JR: Tak naprawdę nie. Mogą być, jednak przy odpowiednich warunkach badawczych, ale w praktyce zawsze przytrafiają się jakieś błędy. Łatwiej jest uniknąć błędu, gdy pracuje się na obiektach „martwych”. Wiadomo – organizm żywy się zmienia, trudniej jest go za każdym razem rozpoznać, pojawiają się wątpliwości podczas procesu rozpoznania obrazu. Osoby z dużym doświadczeniem w tej branży potrafią stworzyć taki algorytm, który ma bardzo dobrą skuteczność. Do tego się zresztą dąży – aby wyniki za każdym razem były blisko 100% skuteczności. W praktyce wygląda to jednak tak, że prawie zawsze są jakieś błędy – mniejsze lub większe i algorytm wymaga dostosowania do zadanego problemu.
Rozwiązaniem byłby jeden algorytm, który będzie rozpoznawał wszystko?
JR: Osoba, która go stworzy, będzie mogła rządzić światem (śmiech). Zdjęcia z Facebook’a mogą ci powiedzieć mnóstwo rzeczy na temat danej osoby. Gdy siedzi kilka osób przy stoliku w restauracji, to za pomocą zdjęcia możemy zobaczyć, co jest na stoliku – czy jest to cola czy butelka z innym napojem. Szczegółowe algorytmy pozwalają jednak to wszystko dokładnie rozpoznać i to nawet bez idealnego zdjęcia w super świetle.
Co jest wyzwaniem dla osoby zajmującej się technologią rozpoznawania obrazu? Wideo?
JR: Wideo można podzielić na tyle klatek, z ilu w ogóle powstało nagranie. Sama w sobie klatka jest nieco rozmyta, a dopiero gdy tworzą one obraz, to płynnie się je ogląda. Jednak głównym wyzwaniem jest temat poruszany wcześniej – rozpoznanie całej zawartości i kontekstu zdjęcia.
Jak wygląda ścieżka kariery dla osoby, która wchodzi do tej branży, do tego świata?
JR: To bardzo trudna sprawa. Moim zdaniem w tej branży najlepiej odnajdą się osoby, które są programistami i działały w branży produkcyjnej. Znają już w jakimś stopniu specyfikę tej pracy, dostały już kopa w tyłek, dużo się nauczyły i pewne mechanizmy mają już przećwiczone. Do tego konieczna jest smykałka do czegoś naukowego. Robi to pół na pół. Wszyscy ludzie, z którymi współpracuję, były albo są związane z uczelnią. Każda z nich zajmuje się programowaniem. To ich pasja, zawsze robią coś produkcyjnego, bo nie chcą, żeby dany algorytm leżał w szafie, chcą z tym wyjść do ludzi, muszą to pokazać.

Co jest miarą doświadczenia w waszej branży?
JR: A tu Cię pewnie zdziwię – rozmowa… ale na temat. Ostatnio miałem przyjemność poznać takiego chłopaka, z którym długo rozmawialiśmy na temat rozpoznawania obrazu. Mówił płynnie, fachowo, znał dużo pojęć, widać było, że jest doświadczony i ma naprawdę dużo do przekazania. Znał podstawowe algorytmy, ich rozszerzenia i modyfikacje, a przede wszystkim potrafił to dobrze oprogramować. Naprawdę był kimś więcej niż tylko osobą pracującą w tej branży – umiał dużo i z pewnością wiele osób fachowości mogło się od niego nauczyć.

To wszystko?
JR: Poza umiejętnościami stricte technicznymi, które każdy nabiera przez lata praktyki, ważna jest umiejętność pracy w zespole. Odnalezienia się w grupie. W branży IT nie może być chorej rywalizacji, bo bez współpracy nic nie powstanie. Ambicje często trzeba odstawić na bok i należy kierować się dobrem ogółu.
Jakie umiejętności musi już posiadać junior, by móc pracować wykorzystując technologię rozpoznawania obrazu?
JR: Każdy po skończeniu studiów ma inny poziom wiedzy. Spotkałem kiedyś chłopaka, który poszedł na studia informatyczne tak po prostu – nie wiązał z tym początkowo żadnych poważnych planów – a ja po rozmowie z nim poczułem jakbym gadał z gościem, który jest po kilkuletnich studiach doktoranckich. Kapitalny facet, mega mądry, doświadczony, sumienny, ma to coś. Pracował długo nad tym samemu, zgłębiał wiedzę, uczył się algorytmów, robił wszystko, by dojść samemu na możliwie najwyższy poziom. Co ważne – znakomicie mu to dziś wychodzi.
Ta branża wymaga tego, aby dużo czasu poświęcać samemu na pracę i dokształcanie się. Nie można polegać na tym, że studia lub kurs coś ci zapewnią. Długa, żmudna praca w samotności nad zrozumieniem detali i zależności operacji algorytmicznych pomaga robić stopniowy progres. Czemu w samotności? Powodem jest to, że jak dostaniesz wszystko na tacy, nie jest to wiedza wypracowana i moim zdaniem poziom zrozumienia zagadnienia nie jest wystarczająco na plus. To co wypracujesz i zrozumiesz samemu rozwija, a jeśli chcesz być specjalistą w danej gałęzi musisz to wypracować. Dopiero to potencjalnego juniora kwalifikuje do tego, by w tej branży zostać na dłużej.

Jak uważasz, kiedy technologia w rozpoznawaniu obrazu zastąpi ludzi?
JR: Trudno powiedzieć, bo to jest bardzo ogólne pytanie. Tak już się dzieje, to żadna tajemnica. Czymś, co powinno bardziej martwić ludzi, są metody sztucznej inteligencji, które przeżywają znów swoją świetność. Sieci neuronowe, logika rozmyta robią sporo zamieszania w świecie IT. Nowe możliwości algorytmiczne, jak i moce obliczeniowe maszyn powodują to, że granicą możliwości i nowych rozwiązań jesteśmy tylko my i to jak postrzegamy świat. To przekłada się na przetwarzanie obrazu. Sieci neuronowe i obrazy to para, która dała niesamowite postępy w dziedzinie przetwarzania i rozumienia obrazu.
Dzięki temu, że jesteśmy w stanie uczyć się i modelować człowieka, jego świadomość jak i podświadomość, smak i zachowania. Mamy niesamowite możliwości gdzie sztuczna inteligencja zmienia ludzkość. Jest jeszcze ta “druga strona mocy” jak w Star Wars… Możemy w wielu kwestiach zastąpić człowieka i wyeliminować go z niektórych czynności — maszyna może go zastąpić.
Najpiękniejsze i zarazem najgorsze jest to, że sztuczna inteligencja pozwala poznać człowieka czasami nawet głębiej niż on sam jest świadomy swoich cech. Dzięki temu można odpowiednio mu pomóc, pokierować w ścieżce kariery, czy zarekomendować odpowiednie tylko dla niego dobra materialne, ale… zawsze jest ale — można wykorzystać tą “moc” całkowicie odwrotnie.
Podobne artykuły

Rok w startupie, to jak trzy lata w tradycyjnej firmie. Wywiad z Mateuszem Gostańskim

Kultura pracy zdalnej. Czym jest, jak ją zbudować i czy w ogóle warto?

W jaki sposób za pomocą UX i UI zwiększyć efektywność i zredukować koszty rozwoju oprogramowania

Wymień Husky na Lefthook i wejdź na nowy poziom znajomości Git Hooków

Modelarz vs. programista. Która profesja jest kluczem do sukcesu w świecie AI?

Nie odpowiadaj za błędy własnym majątkiem, czyli krok po kroku do zabezpieczenia swojej pracy

Dowiedz się, jak polska firma wspiera naukowców w poszukiwaniu alternatywnych źródeł energii
