Wyzwania automatyzacji testów interfejsu użytkownika

Przez ostatnie kilka miesięcy pracowałem nad bardzo ekscytującym projektem, w którym wykorzystywaliśmy Domain Driven Design oraz testy pisane zgodnie z podejściem BDD (Behaviour Driven Development) oraz zasadą “testuj najpierw”. Największe pokrycie kodu było na poziomie testów integracyjnych, a testy jednostkowe wykorzystywane były głównie do weryfikacji skomplikowanej logiki biznesowej naszych bogatych modeli.

Artykuł przygotował dla nas Maksymilian Majer. CEO itCraftship. Maksymilian jest inżynierem i architektem oprogramowania z trzynastoletnim doświadczeniem. Jego pasją jest optymalizacja i automatyzacja procesów wokół jakości oprogramowania oraz pracy w zdalnych zespołach. Od ponad ośmiu lat jest związany z branżą startup’ów także od strony biznesowej, ale nigdy nie rozstaje się z kodem na zbyt długi czas. Obecnie pomaga firmom IT wdrażać kulturę pracy zdalnej i budować efektywne zespoły rozwoju produktu.
Żeby było zabawniej, DDD stosowaliśmy w projekcie pisanym w Python + Django, więc niestety trzeba było iść na pewne kompromisy (brak value objects, niemożliwa enkapsulacja, itp.), ale to materiał na zupełnie odrębny artykuł. Mimo to nasze podejście do testów sprawdzało się, mieliśmy dobrą informację zwrotną w przypadku wprowadzenia regresji, a po zastosowaniu sewera continuous integration (Semaphore CI w naszym przypadku) bardzo usprawnił się nasz przepływ pracy. Natomiast brakowało dodatkowej warstwy, która wykrywałaby regresje na poziomie interfejsu użytkownika.
W związku z tym, że na froncie nadal wykorzystywane jest leciwe jQuery i nie korzystamy niestety z nowoczesnych bibliotek typu React, Vue czy Angular, testowanie widoków było terenami, na które zespół niechętnie się zapuszczał.
Pierwsze podejście do wprowadzenia testowania interfejsu (tzw. end to end testing lub e2e) zrobiliśmy krótko po tym, kiedy zacząłem współpracę z zespołem. Na tamtym etapie rozważaliśmy wiele podejść, m.in. następujące:
- Puppeteer
- NightmareJS z xvfb
- Cypress
- Protractor + Selenium + Headless Chrome lub Chrome z xvfb
- Behave + Splinter + Selenium
- Behave + Selenium Python driver
Po dłuższej analizie (m.in. po tym świetnym artykule) zdecydowaliśmy się na podejście Behave + Splinter + Selenium. Najważniejszym powodem było to, że nie chcieliśmy wprowadzać dodatkowej komplikacji w postaci projektu w JavaScript i myśleliśmy, że dobrym pomysłem będzie ponowne użycie specyfikacji z naszych testów integracyjnych. Sugerowaliśmy się m.in. tym cytatem z dokumentacji projektu behave django:
„If you want to test/exercise also the “user interface”, it may be a good idea to reuse the feature files, that test the model layer, by just replacing the test automation layer (meaning mostly the step implementations). This approach ensures that your feature files are technology-agnostic, meaning they are independent how you interact with “system under test” (SUT) or “application under test” (AUT)”.
Od początku napotykaliśmy problemy. Chcieliśmy odpalać testy na przeglądarce Google Chrome, ponieważ większość użytkowników aplikacji właśnie z tej przeglądarki korzysta. W środowisku lokalnym miało to sens, ale odpalanie na serwerze CI wymagało wprowadzenia konteneryzacji. Biorąc pod uwagę nasze nieduże doświadczenie na tamten czas z Docker Compose i ogólnie konteneryzacją aplikacji, ciężko było nam zestawić usługi tak, żeby kontener z Selenium łączył się naszą aplikacją w innym kontenerze.
Kiedy wszystko udało się lokalnie, to na serwerze CI testy „wysypywały” się w nieprzewidywalny sposób. Zależało nam na wiarygodnej, przewidywalnej i zautomatyzowanej informacji na temat wprowadzonych regresji, a nie dochodzeniu, czy testy nie przechodzą ze względu na środowisko lub jeszcze inne powody. W końcu testy, których się nie odpala są równie słabe, jak brak testów.
Po tej nieudanej próbie tymczasowo porzuciliśmy nasze zapędy, żeby testować interfejs użytkownika i koncentrowaliśmy się nadal na naszych testach integracyjnych. Testowanie regresji w interfejsie użytkownika pozostało manualne i wykonywane na głównych scenariuszach użycia aplikacji za każdym razem, kiedy mieliśmy wprowadzać nowszą wersję aplikacji na produkcję. Jednym słowem: porażka.
Drugie podejście do testowania UI
Niedawno natknąłem się na interesujący projekt o nazwie CodeceptJS. Zaintrygowała mnie jego trywialna składnia, bliska naturalnemu językowi. Zdawało mi się, że nawet średnio-techniczna osoba jest w stanie zrozumieć testy pisane z użyciem CodceptJS. Ponadto CodeceptJS wprowadza dodatkową warstwę abstrakcji nad API udostępniane przez narzędzia do automatyzacji przeglądarek (Selenium, NightmareJS, Protractor, Puppeteer czy Appium) ujednolicając sposób w jaki wchodzimy z nimi w interakcję.
W międzyczasie zdobyliśmy więcej doświadczenia z dockerem i fakt, że projekt jest w JavaScript nie bolał już tak bardzo. Korzystając z docker-compose oraz prywatnego kontenera w rejestrze Docker Hub mogliśmy wydzielić testy do osobnego repozytorium, które tylko korzysta z obrazu naszej aplikacji w Pythonie. Tym samym nie bałaganimy dodatkowymi zależnościami ze świata JavaScriptu (i stricte testów e2e) w naszym głównym repozytorium aplikacji, która jest pisana w Pythonie.
Zachęciło nas to do podjęcia kolejnej próby do testów e2e, teraz bogatszych już o doświadczenia z poprzedniej porażki.
Poniżej przedstawiam przykłady testu logowania błędnymi danymi i jak wygląda to w popularnych narzędziach do automatyzacji. Dla porównania jest tam też test napisany z użyciem CodeceptJS, który będzie wyglądał tak samo niezależnie od tego, z którym narzędziem zostanie użyty.
// Protractor:
it('Should show invalid username or password', () => {
browser.get("/wp-login.php");
var inputField = element(by.xpath("//label[. = 'Username or Email
Address']/following-sibling::input"));
inputField.sendKeys("maks");
inputField = element(by.xpath("//label[. =
'Password']/following-sibling::input"));
inputField.sendKeys("some wrong psw");
element(by.buttonText('Log In')).click();
var errorMsg = element(by.id('messages'));
expect(errorMsg.getText()).toEqual('ERROR: Invalid username. Lost
your password?');
});
// NightmareJS
it('Should show invalid username or password', async () => {
await text = nightmare
.goto('/wp-login.php')
.type('#username', 'maks')
.type('#password', 'some wrong psw')
.click('form [type=button]')
.wait('#messages')
.evaluate(function () {
return document.querySelector('#messages').innerText;
});
await nightmare.end()
expect(text).toEqual('ERROR: Invalid username. Lost your password?');
});
// Puppeteer:
it('Should show invalid username or password', async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('/wp-login.php');
await page.click('#user_login');
await page.keyboard.type('maks');
await page.click('#user_pass');
await page.keyboard.type('some wrong psw');
await page.click('#wp-submit');
await page.waitFor(1000);
const text = await page.evaluate(() =>
document.querySelector('#login_error').textContent);
await browser.close();
expect(text).toEqual('ERROR: Invalid username. Lost your
password?');
});
// CodeceptJS:
Scenario('Invalid username or password', (I) => {
I.amOnPage('/wp-login.php');
I.fillField('Username or Email Address', 'maks');
I.fillField('Password', 'some wrong psw');
I.click('Log In');
I.see('ERROR: Invalid username. Lost your password?');
});
Gist: https://gist.github.com/maksymilian-majer/797fa346a8a94eee5633ad0b36e284f1
Zobacz rezultat naszego testu w CodeceptJS i jak zgrabnie wypisane są polecenia w stylu BDD, które pisane są niemal naturalnym językiem:
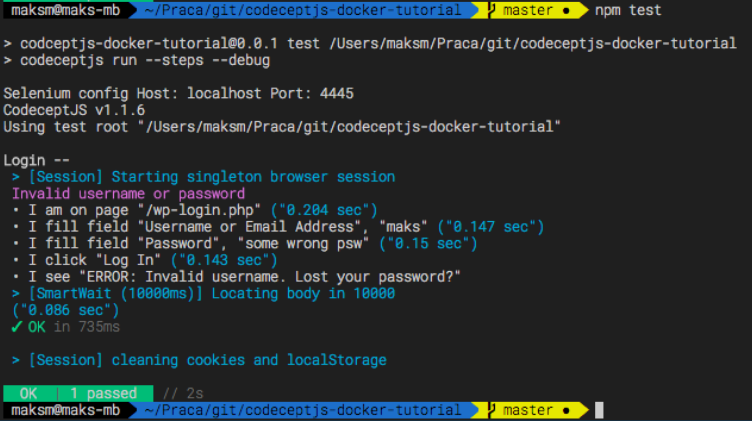
Dodatkowym atutem CodeceptJS jest to, że w standardzie robi zrzut z ekranu, kiedy test nie przeszedł – pomaga to dojść dlaczego tak się stało.
Po pierwszych próbach z tym narzędziem widzieliśmy już, że testowanie E2E będzie od teraz dużo bardziej przyjemne. Nasze testy są pisane z użyciem czytelnego, ekspresyjnego API a ich wyniki są czytelne nawet dla nietechnicznego personelu. Przede wszystkim tworzenie testów jest łatwiejsze a ich rezultaty bardziej przewidywalne, co sprawia, że oszczędzamy czas na dochodzeniu, czemu nie działają i śpimy spokojnie o wprowadzanie regresji w UI. Dodatkowym bonusem jest łatwiejszy on-boarding testerów, ponieważ praca z CodeceptJS nie wymaga dużego doświadczenia w testowaniu automatycznym.
W dalszej części artykułu zamierzam pokazać, na przykładzie popularnego projektu WordPress, jak udało nam się uzyskać przewidywalne rezultaty z testów i cieszyć większym spokojem przy wprowadzaniu nowych wersji naszej aplikacji.Do dalszej lektury przydatna będzie podstawowa znajomość Node i NPM, aby podążać za wszystkimi instrukcjami. Jeśli te zagadnienia są Ci obce, możesz pobrać kod źródłowy towarzyszący temu artykułowi, który znajduje się na GitHubie i zastosować się do instrukcji w README.
Konfiguracja Docker Compose
Zanim będziemy mogli testować naszego WordPressa musimy skonfigurować środowisko Docker Compose tak, żeby WordPress był widzialny zarówno w naszej lokalnej sieci, jak i w izolowanej sieci kontenerów. Przede wszystkim należy zainstalować Docker Compose. Instrukcje jak to zrobić znajdują się tutaj.
Po zainstalowaniu musimy utworzyć plik docker-compose.yml, który definiuje naszą usługę wraz ze wszystkimi zależnościami:
version: '3.3'
services:
chrome:
image: selenium/standalone-chrome
ports:
- '4445:4444'
- '5901:5900'
networks:
default:
aliases:
- selenium
db:
image: mysql:5.7
volumes:
- dbdata:/var/lib/mysql
- .:/code
restart: always
environment:
MYSQL_ROOT_PASSWORD: somepsw
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
depends_on:
- db
image: wordpress:latest
ports:
- "80:80"
restart: always
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
networks:
default:
aliases:
- wptests
volumes:
dbdata:
Gist: https://gist.github.com/maksymilian-majer/53f4a1c6ba5463542c87eebf8f22e6ab
Poniżej opiszę nasze serwisy oraz wyjaśnię kilka istotniejszych ustawień:
chrome
Ten serwis zawiera selenium wraz przeglądarką chrome, na której odtwarzane będą nasze testy. Dla naszej lokalnej sieci udostępniamy dwa porty (4445, 5901), które różnią się od domyślnych, aby uniknąć konfliktów z lokalną wersją selenium. Ponadto nadajemy kontenerowi wewnętrzną nazwę selenium – to będzie dopiero, kiedy będziemy chcieli podłączyć się do selenium z innego kontenera, co jest poza zakresem tego artykułu.
db
To jest nasza WordPressowa baza danych. Ważną zmianą w stosunku do domyślnej konfiguracji jest to, że do katalogu /code/ w kontenerze mapujemy nasz główny folder aplikacji:
volumes:
...
- .:/code
To będzie wykorzystane później podczas przywracania bazy przed uruchamianiem pierwszych testów.
wordpress
To jest kontener, na którym działa WordPress. W przypadku testowania własnej aplikacji tutaj zdefiniujesz kontener bazujący na Twoim obrazie z rejestru (np. Docker Hub) albo lokalnego Dockerfile. Dla potrzeb naszego przykładu wyeksportowaliśmy port 80, ponieważ chcemy, aby nasz wordpress miał taki sam URL, kiedy odwołujemy się do niego z naszej lokalnej sieci oraz z innych kontenerów w środowisku Docker Compose:
ports:
- "80:80"
Jeśli masz inną usługę słuchającą na porcie 80, to musisz ją wyłączyć. Nie doszukałem się w dokumentacji obrazu WordPress’a czy wewnętrzny port można zmienić, bo wtedy wystawiłbym pod innym portem. W Twojej aplikacji prawdopodobnie będziesz mieć na to wpływ i zalecam wykorzystanie innych portów, ale takich samych – np. „8080:8080”.
Najważniejsze jest jednak ustawienie nazwy hosta, pod którą WordPress będzie widziany przez inne kontenery – w szczególności interesuje nas selenium:
networks:
default:
aliases:
- wptests
Ponieważ chcemy mieć też możliwość odpalania testów lokalnie, a wordpress przechowuje główny URL w bazie danych, będziemy musieli mapować też nazwę hosta wptests w naszym pliku hosts. Na komputerze z macOs możesz zrobić to w następujący sposób:
sudo echo '127.0.0.1 wptests' | sudo tee -a /etc/hosts
Na innych systemach operacyjnych musisz poradzić sobie z tym samemu.
Przydałoby się jeszcze, żebyśmy nie musieli ręcznie przechodzić przez instalację WordPress’a, zatem przygotowałem plik backup.sql, który możesz znaleźć tutaj.
Musisz zapisać go w głównym folderze projektu.
Po utworzeniu pliku docker-compose.yml i wprowadzeniu zmiany w pliku hosts jesteśmy już gotowi, żeby sprawdzić czy nasze środowisko Docker Compose działa i jest gotowe na testy. Należy odpalić poniższą komendę:
docker-compose up -d
To polecenie uruchamia wszystkie nasze serwisy i ich zależności. Pozostało tylko odtworzyć bazę danych z pliku backup.sql. Dokonasz tego poleceniem:
docker-compose exec db /bin/bash -c "mysql -uroot -psomepsw wordpress < /code/backup.sql"
Po wykonaniu tych kroków otwórz swoją przeglądarkę i upewnij się, że wszystko działa poprawnie otwierając poniższy URL:
Powinien powitać Cię taki widok:

Jeśli będziesz odpalać testy w środowisku Continuous Integration, to przeważnie wykonasz dwa powyższe polecenia na samym początku i już możesz uruchomić odpalać testy E2E. Na końcu tego artykułu dowiesz się, jak tego dokonać na serwerze Semaphore CI.
W prawdziwym świecie
Jeśli testujesz prawdziwą instalację WP, nie wystarczy tylko odtworzenie bazy danych. Potrzebne będą jeszcze wszystkie pluginy, wgrane pliki (uploads), itp. Nie będę zagłębiał się w szczegóły, ponieważ jest ten dobry artykuł, który to wyjaśnia.
Praca z CodeceptJS
Uruchomienie w środowisku lokalnym i w kontenerze
Na tym etapie masz już działającą instalację WordPress’a gotową do testowania CodeceptJS. Pora zainstalować i skonfigurować CodeceptJS. Framework ma dosyć dobrą dokumentację, w szczególności QuickStart, ale ja chcę pokazać bardziej zaawansowane zaawansowane możliwości konfiguracyjne, które przydadzą się w większych projektach.
Żeby kontynuować wymagany będzie Node w wersji min. 8.9 a także NPM. Polecam stosowanie NVM (Node Version Manager) oraz możliwości automatycznego przełączania wersji Node’a w przypadku używania pliku .npmrc i Node w wersji >9.
Moim celem jest zawsze minimalizowanie globalnych zależności, żeby ułatwić rozpoczęcie pracy nad nowym projektem, dlatego CodeceptJS oraz Selenium instalowałem jako zależności lokalne:
npm i -D codeceptjs codeceptjs-webdriverio selenium-standalone
Po zainstalowaniu tych zależności można zainicjować projekt używając CLI dostarczonego z CodeceptJS, ale wtedy trzeba by było mieć zainstalowaną paczkę globalnie. W naszym wypadku możemy do skryptów NPM dodać następujący wpis, aby móc używać komend CLI:
"scripts": {
...
"cjs": "codeceptjs",
...
}
Ten zabieg pozwoli wywoływać komendy CLI z pomocą takiego polecenia:
npm run cjs [command_name]
Przykładowo dla inicjalizacji projektu będzie to:
npm run cjs init
Natomiast używanie CLI jest opcjonalne, a bardziej zaawansowane możliwości konfiguracyjne nie są obsługiwane, dlatego preferuję ręczne dodawanie testów i konfiguracji, żeby lepiej organizować złożone projekty.
Mój cały package.json wygląda następująco:
{
"name": "codceptjs-docker-tutorial",
"version": "0.0.1",
"description": "End to end tests for WordPress using CodeceptJS",
"main": "index.js",
"repository": {
"type" : "git",
"url" :
"https://github.com/maksymilian-majer/codeceptjs-docker-tutorial.git"
},
"scripts": {
"cjs": "codeceptjs",
"test": "codeceptjs run --steps --debug",
"test:current": "SELENIUM_PORT=4444 codeceptjs run --steps
--debug --grep @current",
"test:selenium-standalone": "SELENIUM_PORT=4444 codeceptjs run
--steps --debug",
"test:debug": "SELENIUM_PORT=4444 node --inspect-brk=51413
./node_modules/.bin/codeceptjs run",
"test:docker": "SELENIUM_HOST=selenium docker-compose run codeceptjs",
"selenium": "selenium-standalone",
"selenium:install": "selenium-standalone install",
"selenium:start": "selenium-standalone start"
},
"author": "Maksymilian Majer",
"license": "MIT",
"devDependencies": {
"codeceptjs": "^1.1.6",
"codeceptjs-webdriverio": "^1.1.0",
"selenium-standalone": "*"
},
"dependencies": {}
}
Gist: https://gist.github.com/maksymilian-majer/94a9cab5224a54bafbc2533cb8d81f21
Zdefiniowałem w nim kilka przydatnych skrytpów NPM, których działanie wyjaśnię szerzej w dalszej części artykułu.
W trakcie inicjalizacji projektu tworzony jest plik konfiguracyjny codecept.json, ale framework umożliwia bardziej elastyczną formę konfiguracji poprzez plik codecept.conf.js. Warto pamiętać, żeby mieć tylko jeden z tych plików.
W moim wypadku plik codecept.conf.js wygląda następująco:
let webDriverConfig = require('./webdriver.conf'); // reading selenium config from separate file
webDriverConfig.host = process.env.SELENIUM_HOST || 'localhost'; // choosing local vs. docker selenium
webDriverConfig.port = process.env.SELENIUM_PORT || 4445; // running local and docker on different ports to avoid conflics
console.log('Selenium config', 'Host:', webDriverConfig.host, 'Port:', webDriverConfig.port);
exports.config = {
"tests": "./tests/**/*_test.js",
"timeout": 10000,
"output": "./output",
helpers: {
WebDriverIO: webDriverConfig
},
include: {
"I": "./steps_file.js",
"Security": "./tests/01_security/steps.js" // allows adding
commonly used steps – like login
},
"bootstrap": false,
"mocha": {},
"name": "codceptjs-docker-tutorial"
};
Gist: https://gist.github.com/maksymilian-majer/ededa5eaf2bb1c8e5c79b1991de9c421
Ciekawą techniką, którą tutaj wykorzystałem jest rozdzielenie konfiguracji poszczególnych helperów. CodeceptJS umożliwia odpalanie testów jednocześnie przy pomocy kilku narzędzi do automatyzacji przeglądarek. Ja wykorzystuję tylko jedno, ale równie dobrze można odpalać testy równolegle w kilku. Dla czytelności w konfiguracji warto rozdzielić pliki i wczytywać w głównym pliku konfiguracyjnym, jak w powyższym przykładzie.
Ponadto warto zwrócić uwagę na te dwie dodatkowe linijki, które dodałem na potrzeby odpalania testów zarówno przy użyciu lokalnego selenium oraz selenium w kontenerze dockera:
webDriverConfig.host = process.env.SELENIUM_HOST || 'localhost'; webDriverConfig.port = process.env.SELENIUM_PORT || 4445;
Chcąc uniknąć konfliktów z lokalnym selenium, nasz kontener będzie wystawiał port 4445, więc w przypadku odpalania testów na lokalnym serwerze selenium i w lokalnej przeglądarce musimy zmienić port na 4444. Natomiast gdybyśmy chcieli skorzystać z kontenera dockera CodeceptJS, dodałem też opcję konfiguracji nazwy hosta, pod którym znajduje się selenium. Ja zrezygnowałem z odpalania CodeceptJS w kontenerze, ponieważ większość serwerów CI ma Node i NPM i spokojnie można zainstalować na nich CodeceptJS. Odpalanie testów w kontenerze wymagało dużo większych zasobów, testy przechodziły wolniej i często doświadczaliśmy przekroczonych czasów żądania (timeouts). Dla chętnych z przyjemnością udostępnię plik docker-compose.yml z dodatkową możliwością odpalania testów w kontenerze.
Jeszcze są dwa istotne ustawienia, o których napiszę więcej w dalszej części artykułu, ale wspomnę o nich już teraz:
include: {
"I": "./steps_file.js",
"Security": "./tests/01_security/steps.js" // allows adding commonly used steps – like login
}
Sekcja includes pozwala zdefiniować parametry, jakie będą wstrzykiwane (Dependency Injection) jako parametry naszych scenariuszy. Pierwsza zależność I jest domyślna i tworzony podczas inicjalizacji CodeceptJS, natomiast drugą dodałem, żeby zdefiniować powtarzalne czynności związane z bezpieczeństwem – w tym wypadku logowanie.
Mając za sobą podstawową konfigurację musimy jeszcze dodać ustawienia selenium w pliku webdriver.conf.js:
module.exports = {
url: "http://wptests",
smartWait: 5000,
browser: "chrome",
restart: false,
windowSize: "maximize",
waitForTimeout: 10000,
smartWait: 10000,
keepCookies: true,
keepBrowserState: true,
port: 4445,
timeouts: {
"script": 60000,
"page load": 60000
},
coloredLogs: true
};
Warto zauważyć jedno z istotnych ustawień:
url: "http://wptests"
W naszej konfiguracji sieci w Docker Compose nadamy kontenerowi z WordPressem nazwę wptests, żeby kontener z selenium mógł go widzieć.
Po dodaniu konfiguracji należy dodać plik z definicją I, czyli steps_file.js:
'use strict';
// in this file you can append custom step methods to 'I' object
module.exports = function() {
return actor({
// Define custom steps here, use 'this' to access default methods of I.
// It is recommended to place a general 'login' function here.
});
}
Obecnie Twój projekt powinien mieć następującą strukturę:
codeceptjs-docker-tutorial/ ├── backup.sql ├── codecept.conf.js ├── docker-compose.yml ├── package.json ├── package-lock.json └── webdriver.conf.js
Pora napisać pierwszy scenariusz testowy. Najpierw dodaj pusty moduł w pliku
tests/01_security/steps.js:
module.exports = {};
Później dodamy więcej kodu do tego pliku, ale na tą chwilę to wystarczy, żeby można było uruchomić pozostałe testy.
Pierwszy test
Następnie utwórz swój pierwszy scenariusz testowy w pliku
tests/01_security/01_login_test.js:
Feature('Login');
Scenario('Login page has Username and Password labels', (I) => {
I.amOnPage('/wp-login.php');
I.see('Username or Email Address');
I.see('Password');
});
Test zaczynamy od wejścia na stronę logowania i sprawdzenia czy widzimy na niej odpowiedni tekst. Jak widzisz API aktora CodeceptJS jest bardzo intuicyjne i nie sprawi problemów nawet mało technicznych osobom. Zdecydowanie polecam każdemu testerowi manualnemu, który chce zrobić pierwsze kroki w kierunku automatyzacji. Spróbujmy uruchomić testy.
Zaczniemy od uruchomienia w lokalnym selenium. Zakładam, że kontener z WP już działa po wykonaniu poprzednich instrukcji. Przyszła pora na zainstalowanie selenium lokalnie:
npm run selenium:install
Następnie uruchom selenium – najlepiej w osobnej karcie swojej aplikacji terminalowe. Ewentualnie możesz wywołać polecenie w trybie detached (przełącznik -d), tylko potem pamiętaj, żeby zabić proces:
npm run selenium:start
Kiedy selenium już działa możesz uruchomić testy:
npm run test:selenium-standalone
Jeśli otworzy się przeglądarka Chrome i później zobaczysz poniższy rezultat w konsoli to znaczy, że odnieśliśmy pierwszy sukces 🙂

Teraz pora na kolejną próbę – odpalenie na selenium działającym w kontenerze:
npm test
Rezultat powinien być podobny, za wyjątkiem tego, że nie zobaczysz przeglądarki, a port selenium będzie miał numer 4445. Jeśli wszystko poszło pomyślnie, to masz już konfigurację, w której możesz wygodnie rozwijać testy lokalnie, a później odpalać je w kontenerach, co przyda się w środowisku CI.
Mając podstawową konfigurację i działające środowisko do testów E2E możemy przejść do bardziej interesujących testów i zaawansowanych możliwości CodeceptJS. Zacznijmy od sprawdzenia, czy walidacja pól działa poprawnie. Dopiszemy scenariusze do naszych testów funkcjonalności logowania, które sprawdzają walidację oraz logowanie poprawnymi danymi. Twoje testy powinny wyglądać następująco:
Feature('Login');
Scenario('Login page has Username and Password labels', (I) => {
I.amOnPage('/wp-login.php');
I.see('Username or Email Address');
I.see('Password');
});
Scenario('Password field is required', (I) => {
I.amOnPage('/wp-login.php');
I.fillField('Username or Email Address', 'maks');
I.click('Log In');
I.see('ERROR: The password field is empty.');
});
Scenario('Invalid username or password', (I) => {
I.amOnPage('/wp-login.php');
I.fillField('Username or Email Address', 'maks');
I.fillField('Password', 'some wrong psw');
I.click('Log In');
I.see('ERROR: Invalid username. Lost your password?');
});
Scenario('Login with correct credentials', (I) => {
I.amOnPage('/wp-login.php');
I.fillField('Username or Email Address', 'admin');
I.fillField('Password', 'secureP@ssw0rd1');
I.click('Log In');
I.seeInCurrentUrl('/wp-admin/');
I.see('Welcome to WordPress!');
});
Powyższe scenariusze pokrywają nam główne cele funkcji logowania. Warto pamiętać, że testy E2E są kosztowne i warto pisać je tylko dla kluczowych przypadków użycia aplikacji. Dla potrzeb przykładów w tym artykule nie będę stosował się do tego zalecenia.
Don’t Repeat Yourself – powtarzalne kroki
Logowanie, które przetestowaliśmy powyżej jest czynnością, którą będziemy chcieli wykonać przed testowaniem każdej funkcjonalności w panelu administracyjnym WordPress’a. W związku z tym wypadałoby przenieść ją wspólnych definicji interakcji, które w CodeceptJS nazywają PageObjects.
Zaczniemy od tego, żeby przenieść wspólny kod do wcześniej utworzonego pliku
tests/01_security/steps.js:
module.exports = {
_init() {
I = actor();
},
loginUrl: '/wp-login.php',
// in a real world scenario you'll want to get those
// from environment variables:
adminCredentials: {
user: 'admin',
password: 'secureP@ssw0rd1'
},
// setting locators
fields: {
user: 'Username or Email Address',
password: 'Password'
},
loginButton: 'Log In',
// introducing methods
loginWith(username, password) {
I.amOnPage(this.loginUrl);
I.fillField(this.fields.user, username);
I.fillField(this.fields.password, password);
I.click(this.loginButton);
},
loginAsAdmin() {
this.loginWith(this.adminCredentials.user,
this.adminCredentials.password);
},
};
Jeśli dobrze pamiętasz, powyższy plik został już dodany w pliku codecept.conf.js. W związku z tym możemy go wstrzyknąć jako parametr do naszych scenariuszy w taki sposób:
Scenario('Invalid username or password', (I, Security) => {
// możemy tutaj używać Security.loginWith('user', 'pass');
});
Po refaktoryzacji z wykorzystaniem PageObjects nasze testy będą wyglądały następująco:
Feature('Login');
Scenario('Login page has Username and Password labels', (I) => {
I.amOnPage('/wp-login.php');
I.see('Username or Email Address');
I.see('Password'); });
Scenario('Password field is required', (I) => {
I.amOnPage('/wp-login.php');
I.fillField('Username or Email Address', 'maks');
I.click('Log In');
I.see('ERROR: The password field is empty.'); });
Scenario('Invalid username or password', (I, Security) => {
I.amOnPage('/wp-login.php');
Security.loginWith('maks', 'some wrong password');
I.see('ERROR: Invalid username. Lost your password?');
});
Scenario('Login with correct credentials', (I, Security) => {
I.amOnPage('/wp-login.php');
Security.loginAsAdmin();
I.seeInCurrentUrl('/wp-admin/');
I.see('Welcome to WordPress!');
});
Cały kod źródłowy projektu w obecnym stanie możesz znaleźć w tym commicie: https://github.com/maksymilian-majer/codeceptjs-docker-tutorial/tree/ab01c2d9e22c59664bf3c5502eda39fc872d0b69
Przygotowanie testu
Po przetestowaniu logowania chciałbym zająć się najważniejszą funkcjonalnością WP, czyli zarządzaniem postami. W tym celu utworzę kolejny plik tests/02_posts/01_posts_test.js. Zanim będę mógł utworzyć nowy post muszę być zalogowany. Chciałbym, żeby to odbyło się przed każdym scenariuszem w moim pliku.
Uwaga: W konfiguracji włączyłem opcję zachowania cookies i state przeglądarki, więc nie jest to potrzebne, ale dla celów demonstracji wykomentowałem te linie w pliku webdriver.conf.js:
// keepCookies: true, // keepBrowserState: true,
Teraz, aby zalogować się przed każdym scenariuszem użyję hook’a Before i nasze testy mogą wyglądać teraz następująco:
Feature('Posting);
Before((I, Security) => {
Security.loginAsAdmin(); });
Scenario('Creating a new post', (I) => {
I.amOnPage('/wp-admin/edit.php');
I.click('Add New');
I.fillField('#title', 'My new test post')
I.switchTo('#content_ifr'); // switching to TinyMCE iFrame I.click('#tinymce');
I.fillField('#tinymce', 'This is the content of my new test post.');
I.switchTo(); // back to parent I.click('Publish');
I.see('Post published. View post');
I.click('View post');
I.seeInCurrentUrl('my-new-test-post');
I.see('My new test post');
I.see('This is the content of my new test post.'); });
Scenario('Removing created post', (I) => {
I.amOnPage('/wp-admin/edit.php');
I.moveCursorTo('#the-list a[aria-label*="My new test post"]');
I.click('Trash');
I.see('1 post moved to the Trash. Undo');
I.dontSee('My new test post');
});
Uruchamianie tylko wybranych testów
Często będziecie chcieli pracować tylko nad testami w jednym pliku. Można to uzyskać przekazując parametr –grep przy uruchamianiu testów. Ja dla wygody skorzystałem z funkcji tagowania testów i utworzyłem pomocniczy skrypt NPM, żeby uruchamiać tylko konkretne testy.
W package.json:
"scripts": {
... "test:current": "SELENIUM_PORT=4444 codeceptjs run --steps --debug --grep @current",
...
},
Wewnątrz testu, który chcesz odpalić możesz dodać tag @current w taki sposób:
Feature('Posting @current');
Następnie wystarczy, że uruchomisz:
npm run test:current
Debugging
Jedną ze słabo udokumentowanych możliwości jest debugowanie z wykorzystaniem IDE – np. WebStorm czy VS Code. W moim package.json skonfigurowałem komendę, aby odpalić testy w trybie interaktywnego debuggera, aby umożliwić podłączenie się z poziomu IDE:
npm run test:debug
Ponadto dla VS Code dodałem konfigurację launch.json, która umożliwia ustawianie breakpoint’ów w kodzie. Po wywołaniu powyższego polecenia Node będzie czekał aż podłączymy się do niego debuggerem, aby kontynuować.
Natomiast interaktywne debugowanie jest według mnie dużo mniej przydatne, niż odpalanie CodeceptJS z przełącznikiem –debug, o czym możesz przeczytać w dokumentacji: https://codecept.io/advanced/#debug.
Usuwanie problemów
W tej sekcji będę dodawał problemy zgłaszane przez czytelników wraz z rozwiązaniami.
Nieprawidłowe dane logowania
Kiedy zalogujesz się jako admin w lokalnej przeglądarce możesz otrzymywać błędy w logowaniu przy próbie logowania poprawnymi danymi. Polecam wtedy wylogować się na lokalnej przeglądarce. W przypadku odpalania testów testów z poziomu serwera CI taki problem nie wystąpi, ponieważ zwykle są one uruchamiane w odizolowanych wirtualnych maszynach.
Następne kroki
Nie będę bardziej zagłębiał się w API CodeceptJS oraz jego możliwości, ponieważ są one dobrze udokumentowane. Chciałem pokazać bardziej życiową konfigurację i wykorzystanie na realnym projekcie, aby stworzyć szkieleton, który możesz wykorzystać dla swoich celów. Zapraszam do kontynuowania lektury na stronie CodeceptJS: https://codecept.io/basics/.
Konfiguracja projektu w Semaphore CI
Jednym z głównych celów, o którym wspominałem na początku, jest automatyzacja sprawdzania regresji. W związku z tym na koniec chcę pokazać, jak można skonfigurować projekt, który będzie uruchamiał nasze testy w Semaphore CI.
1. Zacznij od rejestracji konta w Semaphore i podłączenia Github’a.
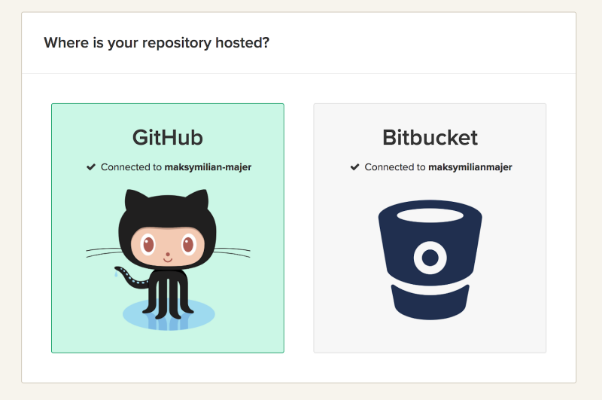
2. Następnie przejdź na stronę dodawania nowego projektu https://semaphoreci.com/new i wybierz Github:
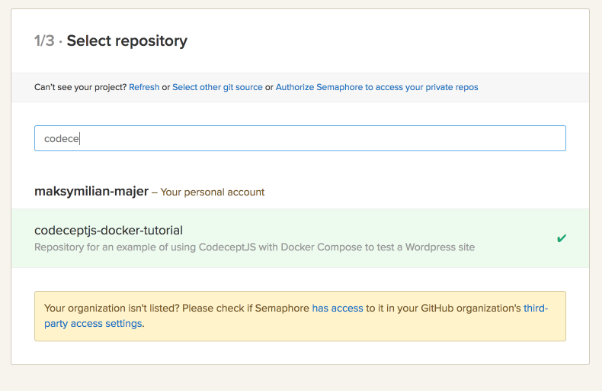
3. Odnajdź swoje repozytorium i kliknij w nie:
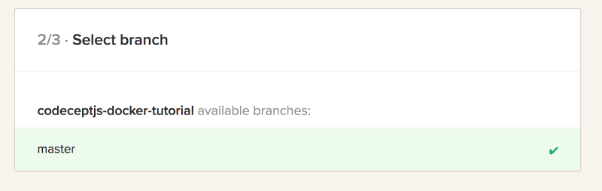
4. Wybierz swój branch:
5. Wybierz właściciela projektu:
6. I poczekaj aż Semaphore wykryje jego typ:

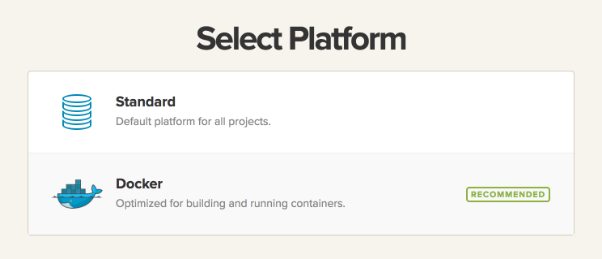
7. Powinna pokazać Ci się rekomendacja wyboru platformy opartej na Dockerze, więc wybierz ją:
8. Następny krok z wyborem Deployment platform możesz pominąć klikając link Skip this step na dole.
9. Ostatnim krokiem jest konfiguracja parametrów build’a:
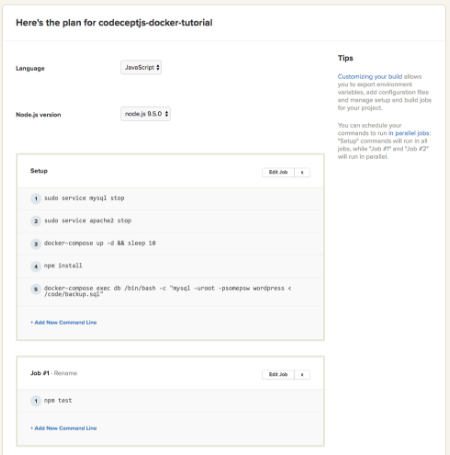
Z naszej perspektywy ważne jest, aby wyłączyć serwisy mysql oraz apache2, żeby nie było konfliktów z portami naszych serwisów z docker-compose.yml. Poniżej treść do przeklejenia:
Setup sudo service mysql stop sudo service apache2 stop docker-compose up -d && sleep 10 npm install docker-compose exec db /bin/bash -c "mysql -uroot -psomepsw wordpress < /code/backup.sql" Job #1 npm test
10. Ostatecznie kliknij przycisk Build with this settings
11. I Voilà – twój projekt zbuduje się na Semaphore w niecałe dwie minuty 🙂
Podobne artykuły

Lista najciekawszych projektów technologicznych. Nad czym pracują naukowcy?

Aitana — influencerka, którą pokochali nawet celebryci. Zarabia spore pieniądze i... nie istnieje

Sam Altman, współtwórca OpenAI zwolniony z posady dyrektora generalnego. Po kilku dniach go przywrócili [AKTUALIZACJA]

Ponad 1/3 polskich firm korzysta już ze wsparcia AI. Poznajcie wyniki raportu "AI i rynek pracy w Polsce"

25. urodziny Google. Jak zmieniał się przez lata?

W którym Big Techu zarabia się najwięcej? Blind publikuje dane

Scott Farquhar jest miliarderem i CEO dużej firmy tech. Do biura przychodzi raz na trzy miesiące
