Wykrywanie defektów w produkcji z uczeniem nienadzorowanym

Jak donosi American Society of Quality (Amerykańskie Towarzystwo Jakości), wiele organizacji ponosi koszty związane z jakością wynoszące nawet do 40 proc. swoich całkowitych przychodów z produkcji. Duża część tych kosztów wynika z nieefektywności ręcznej kontroli, która jest najczęstszym sposobem zapewnienia kontroli jakości w produkcji.
Zastosowanie sztucznej inteligencji do automatyzacji kontroli jakości prezentuje bardziej produktywny oraz precyzyjny sposób przeprowadzania kontroli wzrokowej na liniach produkcyjnych. Jednak tradycyjne metody uczenia maszynowego posiadają kilka ograniczeń dotyczących tego, w jaki sposób możemy szkolić i wykorzystywać modele w wykrywaniu wad. Z tego względu w niniejszym artykule omówimy zalety uczenia nienadzorowanego w celu wykrywania defektów i omówimy podejścia stosowane przez MobiDev w naszym doświadczeniu praktycznym.
Spis treści
Co to jest wykrywanie defektów za pomocą sztucznej inteligencji (AI) i gdzie jest stosowane?
Wykrywanie defektów za pomocą sztucznej inteligencji opiera się na widzeniu komputerowym, które zapewnia możliwości automatyzacji całego procesu kontroli jakości za pomocą AI przy użyciu algorytmów uczenia maszynowego. Modele wykrywania defektów są szkolone w celu wizualnego sprawdzania elementów, które przechodzą przez linię produkcyjną i rozpoznawania anomalii na ich powierzchni oraz dostrzegania niespójności w wymiarach, kształcie lub kolorze. Wyjście zależy od tego, do czego model jest szkolony, ale w przypadku wykrywania wad proces zwykle wygląda następująco:
Jak działa wykrywanie defektów za pomocą sztucznej inteligencji w skrócie
Stosowane do procesów kontroli jakości wykrywanie defektów za pomocą sztucznej inteligencji jest skuteczne w kontroli dużych linii produkcyjnych i wykrywaniu usterek nawet na najmniejszych elementach produktu końcowego. Odnosi się to do szerokiego spektrum wytwarzanych produktów, które mogą zawierać wady powierzchniowe o różnym charakterze.
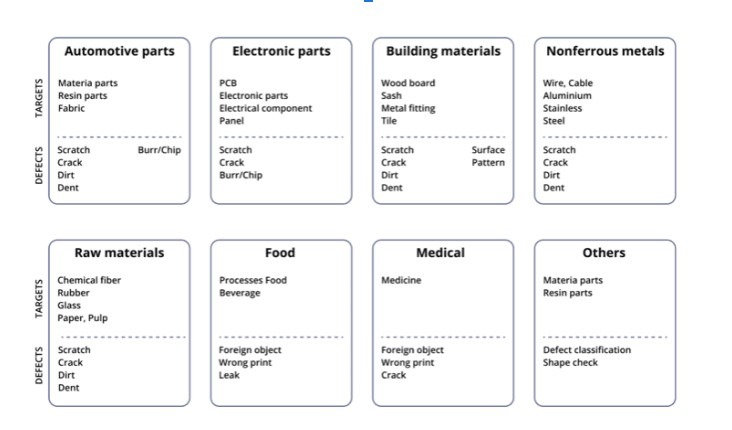
Wykrywanie defektów w różnych sektorach produkcji. Źródło: necam.com.
Intel opisuje przypadek wdrożenia wizji komputerowej w celu automatyzacji kontroli jakości opon. Jak stwierdzono w raporcie, precyzja kontroli jakości wzrosła z 90 do 99 proc., podczas gdy linia produkcyjna obniżyła koszty pracy o około 49 tysięcy dolarów. Ale takie systemy nie są związane wyłącznie ze stacjonarnym sprzętem w fabryce. Przykładowo, drony z kamerami mogą być wykorzystywane do kontroli wad nawierzchni lub innych powierzchni zewnętrznych, co znacznie skraca czas niezbędny do skontrolowania dużych obszarów miasta.
Branża farmaceutyczna odnosi również korzyści z kontroli linii produkcyjnych różnych produktów. Na przykład Orobix stosuje wykrywanie defektów w produkcji leków za pomocą określonego typu kamery, która może być używana przez nieprzeszkolonego operatora. Ta sama zasada ma zastosowanie do kontroli wad szkła farmaceutycznego, takich jak pęknięcia i pęcherze powietrza zatrzymane w szkle.
Takich przykładów można się doszukać w przemyśle spożywczym, tekstylnym, elektronicznym, ciężkiej produkcji i innych gałęziach przemysłu. Ale podejście do algorytmów wykrywania defektów z tradycyjnym uczeniem maszynowym napotyka pewne specyficzne problemy. Ponieważ producenci codziennie kontrolują tysiące produktów, gromadzenie danych dotyczących próbek do celów szkoleniowych, a także ich oznaczanie, staje się trudne. W tym miejscu w grę wchodzi uczenie się bez nadzoru.
Czym jest uczenie się bez nadzoru?
Większość aplikacji uczenia maszynowego opiera się na nadzorowanych metodach uczenia maszynowego. W nadzorowanym uczeniu chodzi o dostarczanie modelowi podstawowe informacje poprzez ręczne oznaczanie zebranych danych. W przypadku linii produkcyjnej zbieranie i oznaczanie danych może okazać się niemożliwe, ponieważ nie jesteśmy w stanie zebrać wszystkich wariantów pęknięć lub wgnieceń na produkcie, aby zapewnić precyzyjne wykrycie przez model. W tym miejscu napotykamy cztery problemy:
- trudności z uzyskaniem dużej ilości danych anormalnych,
- możliwość bardzo małej różnicy między próbką normalną a anormalną,
- znaczna różnica między dwiema anormalnymi próbkami,
- niezdolność do wcześniejszego stwierdzenia rodzaju i liczby anomalii.
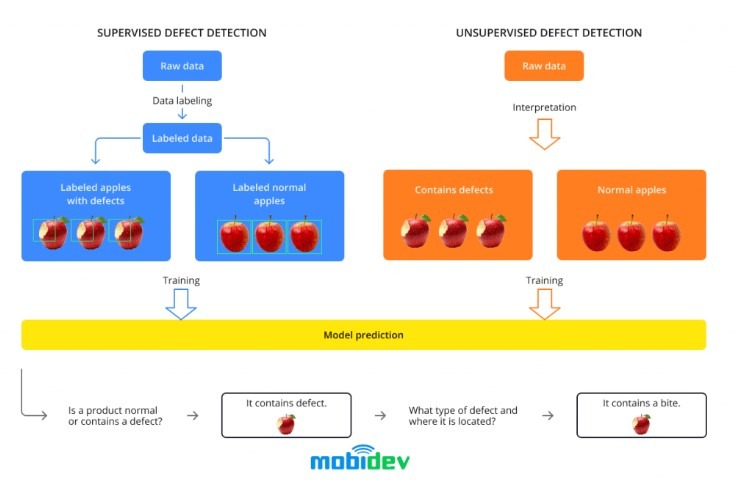
Nadzorowane a nienadzorowane wykrywanie defektów
Algorytmy uczenia maszynowego bez nadzoru pozwalają znaleźć wzorce w zbiorze danych bez wstępnie oznaczonych wyników i odkryć podstawową strukturę danych, w przypadku gdy niemożliwe jest wyszkolenie algorytmu w normalny sposób. W przeciwieństwie do uczenia nadzorowanego, ten proces uczenia wymaga mniejszych nakładów pracy, ponieważ oczekuje się, że model odkryje wzorce w danych z większym progiem dla odchyleń.
Detekcja anomalii przedstawia wcześniej niewidziane, rzadkie obiekty lub zdarzenia bez jakiejkolwiek wcześniejszej wiedzy na ich temat. Jedyną dostępną informacją jest to, że odsetek anomalii w zestawie danych jest niewielki. Jeśli chodzi o wykrywanie wad, pomaga to rozwiązać problem z oznaczaniem danych i pobieraniem ogromnych ilości próbek. Zobaczmy więc, jak można wykorzystać nienadzorowane metody uczenia do szkolenia modeli wykrywania defektów.
Jakie zastosowanie ma uczenie nienadzorowane w wykrywaniu defektów?
Wykrywanie defektów wiąże się z problemem wykrywania anomalii w uczeniu maszynowym. Chociaż nie polegamy tutaj na oznaczaniu, istnieją inne podejścia w uczeniu nienadzorowanym, które mają na celu grupowanie danych i dostarczanie modelowi wskazówek.
- Klastrowanie (ang. clustering) to grupowanie nieoznakowanych przykładów według podobieństwa. Klastrowanie jest szeroko stosowane w silnikach rekomendacji, segmentacji rynku lub klientów, analizie sieci społecznościowych lub w klastrowaniu wyników wyszukiwania.
- Eksploracja asocjacyjna ma na celu obserwację często występujących wzorców, korelacji lub skojarzeń ze zbiorów danych.
- Modele zmiennych ukrytych służą do modelowania prawdopodobieństwa rozkładu za pomocą zmiennych ukrytych. Jest ona używana głównie do wstępnego przetwarzania danych, redukcji obiektów w zestawie danych lub dekompozycji zestawu danych na wiele komponentów opartych na cechach.
Odkryte wzorce wraz z uczeniem nienadzorowanym mogą być wykorzystywane do wdrażania tradycyjnych modeli uczenia maszynowego. Przykładowo, możemy zastosować klastrowanie na dostępnych danych, a następnie użyć tych klastrów jako zestawu danych szkoleniowych dla nadzorowanych modeli uczenia.

Wykrywanie pęknięć betonu za pomocą nienadzorowanego uczenia maszynowego
Wykorzystując nasze ogromne doświadczenie w zakresie uczenia maszynowego, przeprowadziliśmy eksperyment z zastosowaniem zestawu danych pęknięć betonu. Celem było stworzenie modelu zdolnego do rozpoznawania obrazów z defektami oraz normalnych za pomocą uczenia nienadzorowanego. Dodatkowo w badaniu sprawdzono, w jaki sposób liczba obrazów defektów wpływa na stosowane w tym projekcie określone algorytmy.
Przykłady zestawów danych pęknięć betonu
W wybranym przez nas przypadku użycia zakładamy, że oznaczenia obrazów nie mogą być znane przed szkoleniem. Oznaczany jest tylko zestaw danych testowych w celu weryfikacji jakości prognozowania modelu, ponieważ szkolenie odbywa się w ramach podejścia nienadzorowanego. Celem uzyskania wyników klasyfikacji z nienadzorowanego modelu uczenia zastosowaliśmy w tym przypadku pięć różnych podejść.
 Klastrowanie
Klastrowanie
Ponieważ nie mamy do dyspozycji żadnych oznaczonych danych podstawowych, grupowanie nieoznaczonych przykładów odbywa się za pomocą klastrowania. W naszym przypadku ze zbioru danych musimy wyodrębnić dwa klastry obrazów. Przeprowadzono to przy użyciu wstępnie wyszkolonej splotowej sieci neuronowej VGG16 do ekstrakcji cech i K-średnich w celu klastrowania. Klastrowanie poskutkowało tutaj pogrupowaniem obrazów z pęknięciami i bez nich na podstawie ich podobieństw wizualnych. W skrócie, grupowanie wygląda mniej więcej tak:
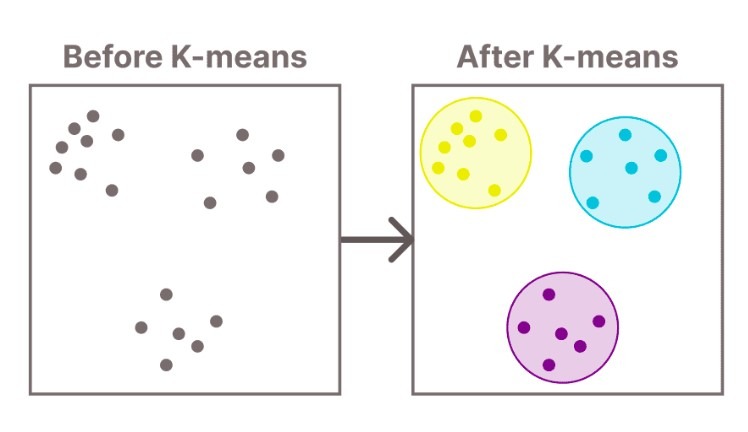 Klastrowanie K-średnich
Klastrowanie K-średnich
Metody klastrowania są łatwe do wdrożenia i zazwyczaj są traktowane jako podstawowe podejście do dalszego modelowania uczenia głębokiego.
Klastrowanie Birch
Przy takim podejściu klastry obrazów oparto na wizualnym podobieństwie z wstępnie wyszkoloną siecią neuronową ResNet50 do ekstrakcji cech oraz metodą Birch w celu klastrowania. Algorytm ten konstruuje strukturę danych w formie drzewka, z centroidami klastra odczytywanymi z liści. Jest to efektywny pod względem pamięci, internetowy algorytm uczenia. Wyniki klastrowania zostały zwizualizowane za pomocą analizy składowych głównych (PCA):
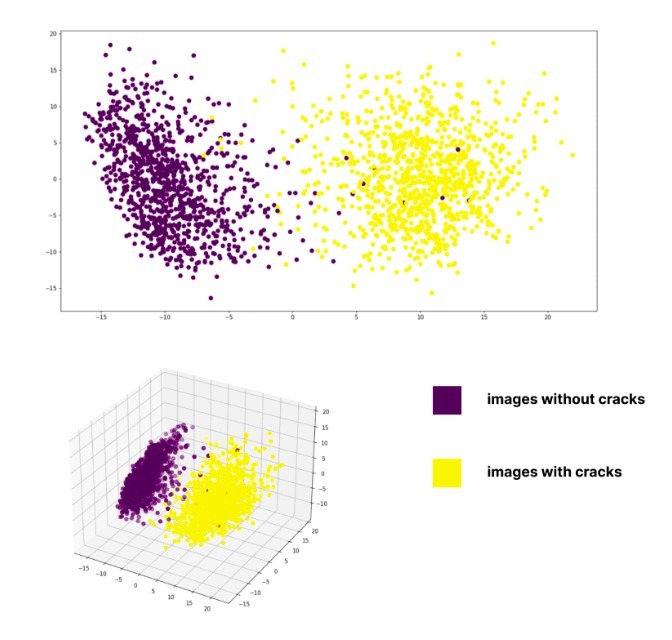 Wyniki klastrowania metodą Birch
Wyniki klastrowania metodą Birch
Jak widać, klastrowanie Birch pokazuje całkiem dobry rozkład klas, nawet w punktach, w których próbka znajduje się dość daleko od swojego centroidu.
Niestandardowy autokoder splotowy
Niestandardowy autokoder splotowy składa się z dwóch bloków: kodera i dekodera. Pozwala mu to uzyskiwać cechy w części kodera i zrekonstruowywać na ich podstawie obrazy w części dekodera.
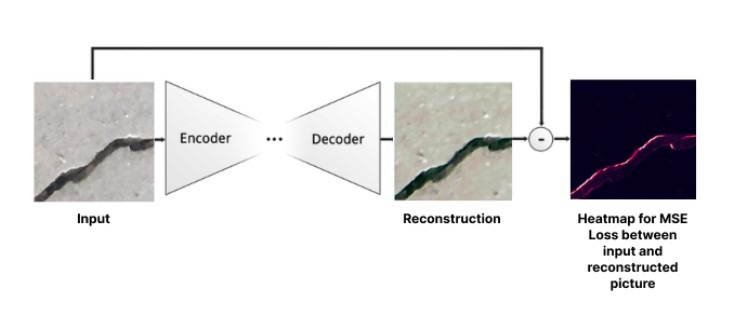 Wizualizacja kodera-dekodera
Wizualizacja kodera-dekodera
Ponieważ nie mamy oznaczeń dla szkolenia sieci, musimy wybrać inne podejście do uzyskiwania klas – na przykład, za pomocą progu dobieranego adaptacyjnie. Celem progu dobieranego adaptacyjnie jest jak najdokładniejsze rozdzielenie dwóch rozkładów (obrazów bez pęknięć i obrazów z pęknięciami):
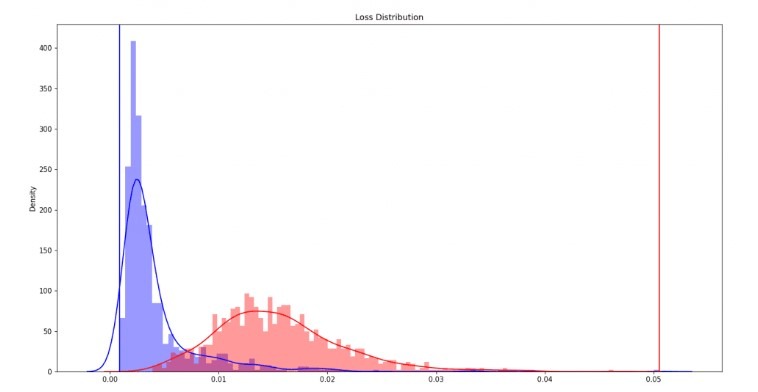 Wyniki rozkładu z autokodera
Wyniki rozkładu z autokodera
DCGAN
DCGAN generuje obrazy z przestrzeni z za pomocą straty przeciwnej (BCALoss). Wreszcie mamy trzy straty – stratę generatora, stratę dyskryminatora i stratę MSE (aby móc porównać wygenerowane obrazy i podstawowe informacje). Naszą klasyfikację możemy zbudować na tym samym podejściu, co w niestandardowym autokoderze – poprzez porównanie strat na obrazach z pęknięciami i bez przy pomocy progu dobieranego adaptacyjnie. W odniesieniu do progu właściwe będzie zastosowanie strat spowodowanych dyskryminacją lub strat MSE, w zależności od ich rozkładów.
GANomaly
GANomaly wykorzystuje warunkowe podejście GAN do trenowania generatora w celu tworzenia obrazów normalnych danych. Podczas wnioskowania, gdy przekazywany jest nieprawidłowy obraz, nie jest on w stanie przechwycić danych w poprawny sposób. Prowadzi to do złej rekonstrukcji wadliwych obrazów i dobrej rekonstrukcji prawidłowych, w rezultacie dając wynik anomalii.
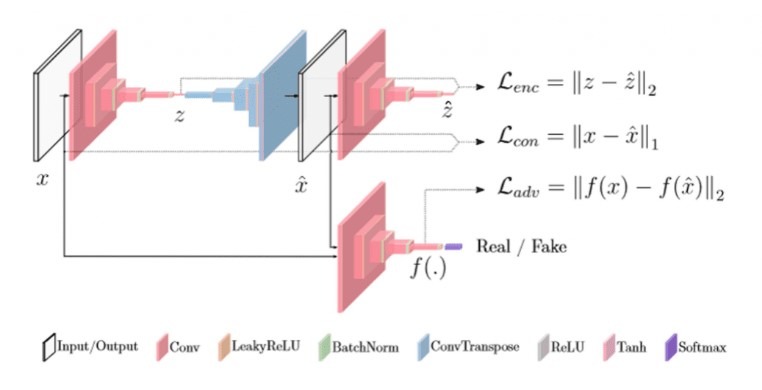
Architektura GANomaly. Źródło: arxiv.org.
Podejście do nienadzorowanego wykrywania anomalii
Być może najbardziej korzystną stroną technik uczenia nienadzorowanego jest to, że możemy uniknąć gromadzenia ogromnych ilości danych z próbek i oznaczania ich w celu szkolenia modelu. Stosując techniki uczenia nienadzorowanego w celu uzyskania wzorców danych, nie jesteśmy ograniczeni co do tego, który model można wykorzystać do rzeczywistej klasyfikacji i wykrywania defektów.
Jednak modele uczenia nienadzorowanego lepiej sprawdzają się w segmentacji istniejących danych na klasy, ponieważ dość trudno jest sprawdzić dokładność predykcji modelu, zwłaszcza bez zestawu danych oznaczonych. Tak więc konsultacja z ekspertami MobiDev w dziedzinie uczenia maszynowego, posiadających ogromne doświadczenie w zakresie uczenia nienadzorowanego, jest prawdopodobnie najlepszym sposobem podejścia do wykrywania defektów.
Porozmawiajmy o Twoim projekcie uczenia maszynowego!

 Artykuł został pierwotnie opublikowany tutaj. Zdjęcie główne pochodzi z unsplash.com.
Artykuł został pierwotnie opublikowany tutaj. Zdjęcie główne pochodzi z unsplash.com.
Podobne artykuły

Wykorzystujesz w projekcie AI? Wyznacz dedykowany zespół do kontroli jej jakości

Czy da się rozmawiać o AI bez magii i fantastyki? Podsumowanie debaty Tech Talk

Golang w rozwoju aplikacji AI. Najlepsze praktyki i studia przypadków

Dlaczego nie powinniśmy powstrzymywać rozwoju AI? Opinie ekspertów z Capgemini

Na rynku wciąż widać stabilną pozycję języka Java. Jaka będzie przyszłość Javy?

Czy programistów zastąpi sztuczna inteligencja? Ponad ⅓ badanych twierdzi, że tak

Portret lidera AI. Fragment książki pt. "Sztuczna inteligencja w biznesie"
