Jak uruchomić mainnetowy node Ethereum na AWS
Ostatnio AWS opublikował szablony CloudFormation, pozwalające uruchomić prywatną sieć testową Ethereum. Ich rozwiązanie zawiera aplikację do przeglądania bloków, minera, itp. Podejście AWS jest dobre dla uruchomienia prywatnej sieci testowej, natomiast jest trudne do przystosowania, żeby działać w sieci mainnet.

Marek Kowalski. Współzałożyciel i CTO w Rumble Fish Blockchain Development. Marek jest przodującym programistą w zakresie technologii Blockchain. Podczas swojej ponad dziesięcioletniej kariery w IT pracował między innymi w software housach we Włoszech, Hiszpanii i Stanach Zjednoczonych. Doświadczenie, zainteresowanie innowacyjnymi rozwiązaniami oraz wnikliwość sprawiły, że jest teraz jednym z wiodących programistów Blockchain w Europie. Pod jego kierownictwem zespół Rumble Fish prowadzi pomyślną współpracę z klientami, wprowadzając nowe produkty oraz osiągając doskonałe wyniki.
Po pierwsze, spróbujmy odpowiedzieć, dlaczego ktoś może potrzebować prywatnie hostowanego node’a Ethereum na mainnet, zamiast polegać na Infurze. W Rumble Fish mamy kilka projektów, w których jakiś komponent backendowy wchodzi w interakcje z Ethereum blockchain. W niektórych przypadkach reaguje on na powiadomienia o eventach, w innych jest odpowiedzialny za zamknięcie transakcji finansowej i musi działać błyskawicznie.
Nigdy nie jest dobrym pomysłem, aby proces o kluczowym znaczeniu dla firmy polegał na usłudze zewnętrznej. Jeśli cokolwiek stałoby się z Infurą, usunięcie problemu będzie poza naszym zasięgiem. Jeśli padnie, możemy tylko czekać aż zewnętrzny team usunie awarię. Dla wielu aplikacji to może nie stanowić problemu, ale w naszym przypadku musieliśmy wyeliminować takie ryzyko.
Spis treści
Wyzwania związane z uruchamianiem node’a na mainnecie
Trwałość danych Blockchain
Największym wyzwaniem związanym z uruchomienie mainnetowego node’a jest jego synchronizacja. Synchronizacja nowo podłączonego node’a od zera zajmuje 2-3 godziny, aby dostać się do bieżących bloków. Następnie potrzebne jest jeszcze 2-3 dni, aby zakończyć proces weryfikacji kryptograficznej wszystkich bloków. Proces weryfikacji korzysta ze wszystkich dostępnych IOPSów, co sprawia, że node jest mało responsywny. W tym czasie node może ulec opóźnieniu nawet o 30 bloków, przez co robi się mało przydatny. Dopiero po zakończeniu procesu weryfikacji node robi się stabilny i można na nim polegać. Stacki oferowane przez AWS nie rozwiązują tego problemu — każdy node zaczyna synchronizacje od zera. To jest ok, o ile nie masz dużej ilości danych do zsynchronizowania z innych node’ów, więc nie nadaje się dla mainnetu.
Ponieważ uzyskanie nowego node’a „kosztuje” 3 dni, konieczne jest utrzymanie ściągniętych danych między uruchomieniami node’a. Istnieje więcej niż jeden sposób, aby to osiągnąć. Rozwiązanie, które proponujemy to umieszczenie danych blockchainu na EBS i wykonanie snapshotu, kiedy blockchain zostanie w pełni zsynchronizowany. Jeśli node zostanie zrestartowany, a nowy przejmie jego funkcje, musi on dociągnąć bloki od momentu snapshotu, a nie całe 3 lata historii blockchainu.
Oczywiście to nie jest idealne rozwiązanie i wolelibyśmy mieć trwałe dane bez konieczności ponownego zsynchronizowania wszystkich bloków.

Podejścia, które zlekceważyliśmy
Pojedynczy trwały EBS
Jedną z rzeczy, którą próbowaliśmy, było utworzenie trwałego EBS volume poza kontekstem maszyny EC2 i podłączenie go do node’a podczas uruchamiania. Takie podejście ma swoje zalety. Kiedy tworzy się nowa maszyna, podejmuje synchronizacje w miejscu, gdzie poprzednia maszyna przerwała. To podejście minimalizuje czas regeneracji maszyny.
Z drugiej strony takie podejście nie działa dobrze z rosnącą liczbą instancji w górę i w dół. W scenariuszu, w którym chcielibyśmy mieć więcej node’ów do przełączenia awaryjnego lub zrównoważenia obciążenia, trzeba dodać dodatkową warstwę, aby zdecydować, który dysk EBS mamy użyć lub w miarę możliwości stworzyć nowy. Odrzuciliśmy to podejście jako zbyt skomplikowane.
Elastic File System (EFS)
Kolejną interesującą próbą rozwiązania problemu było użycie EFS. W przeciwieństwie do EBS ten system może być połączony z wieloma instancjami, które współdzielą go za pomocą protokołu podobnego do NFS. Niestety widzieliśmy, że node’y z blockchainowymi danymi na EFS bardzo długo się synchronizują. Parity używa dużo IOPS i wydajność oferowana przez EFS jest daleko niewystarczająca.
Dostęp do publicznej sieci dla warstwy synchronizacji
Aby się zsynchronizować, node musi być w stanie akceptować połączenia od innych node’ów. Wymagane jest, aby jedna strona połączenia mogła akceptować połączenia, więc teoretycznie moglibyśmy obyć się bez dostępu do publicznej sieci i polegać na możliwości połączenia do partnerów.
W takim scenariuszu nasz node mógłby pracować tylko z node’ami oferującymi dostęp publiczny, co eliminuje znaczną część populacji partnerów.
Aby zapewnić publiczny dostęp, skorzystaliśmy z następujących kroków.
1. Parity jest uruchomione w kontenerze dockera. Port 30303 jest otwarte przez następujący przepis:
Resources:
TaskDefinition:
Type: AWS::ECS::TaskDefinition
Properties:
...
ContainerDefinitions:
...
PortMappings:
- ContainerPort: 30303
HostPort: 30303
Protocol: tcp
2. Ponadto node musi znać swój publiczny adres IP, ponieważ jest używany jako identyfikator enode używany przez inne node’y do identyfikacji. Poniższe rozwiązanie polega na API wystawionym przez EC2, więc jest specyficzne dla AWS.
From docker/run_parity.sh:
PUBLIC_IP=`curl -s http://169.254.169.254/latest/meta-data/public-ipv4` /parity/parity --config config.toml --nat extip:$PUBLIC_IP
3. Aby port maszyny EC2 był dostępny, należy go również otworzyć w konfiguracji grupy zabezpieczeń. Jest za to odpowiedzialna poniższa część stacku.
Resources:
ECSSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
...
SecurityGroupIngress:
- FromPort: 30303
ToPort: 30303
CidrIp: 0.0.0.0/0
IpProtocol: tcp
Prywatny dostęp do json-rpc i interfejsów websocket
Parity ma jeszcze dwa interfejsy sieciowe do uzyskiwania dostępu do danych blockchain.
- port 8545 jest używany przez interfejs json-rpc: umieszczenie transakcji i uzyskiwanie wszelkiego rodzaju informacji,
- port 8546 umożliwia to samo ale poprzez protokół websocket.
Najpierw omówmy, dlaczego uważamy, że json-rpc nie powinien być dostępny publicznie. W zależności od konkretnego przypadku otworzenie json-rpc może nie sprawiać problemu. Jednak w Rumble Fish wierzymy, że cokolwiek co może być ukryte powinno pozostać ukryte.
Pozostawienie otwartego interfejsu json-rpc nie stanowi zagrożenia dla środków na koncie. Niemniej łatwo sobie wyobrazić, że osoba atakująca może po prostu uruchomić wiele zapytań na node’zie, aby go przeciążyć. Warto więc się postarać i zabezpieczyć tą część infrastruktury.
Nasze podejście do prywatnego dostępu składa się z następujących elementów.
1. Cloudformation stack tworzy i eksportuje specjalną SecurityGroup używaną do uzyskiwania dostępu do node’a. Można ją zaimportować w innym stacku używając:
!Fn::Import MainnetParity-AccessSecurityGroup
2. Ta grupa ma dostęp do instancji używając następującego ustawienia w grupie SecurityGroup Instancji EC2.
Resources:
ECSSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
...
SecurityGroupIngress:
- FromPort: 8545
ToPort: 8545
SourceSecurityGroupId: !GetAtt AccessSecurityGroup.GroupId
IpProtocol: tcp
- FromPort: 8546
ToPort: 8546
SourceSecurityGroupId: !GetAtt AccessSecurityGroup.GroupId
IpProtocol: tcp
Te porty są kierowane do docker kontenera, analogicznie do tego co wcześniej robiliśmy z portem 30303.
Resources:
TaskDefinition:
Type: AWS::ECS::TaskDefinition
Properties:
...
ContainerDefinitions:
...
PortMappings:
- ContainerPort: 8545
HostPort: 8545
Protocol: tcp
- ContainerPort: 8546
HostPort: 8546
Protocol: tcp
3. Klient łączący się z json-rpc / websocketem musi używać prywatnego adresu IP instancji. Osiągamy to, tworząc Route53 HostedZone i rejestrując IP instancji przy uruchomieniu maszyny.
Cloudformation stack eksportuje serwery DNS tej strefy jako
!Fn::Import MainnetParity-NameServer
Powinieneś umieścić tą wartość jako wpis NS w konfiguracji swojej domeny DNS.
Monitorowanie i logowanie
Stack jest skonfigurowany do zbierania interesujących plików z maszyny i przesyłania ich do CloudWatch log stream’u MainnetParity-logs.
Proces synchronizacji i weryfikacji
Tutaj interesują nas nazwy plików /parity/parity/... które są wyjściem z procesu Parity. Przy pierwszym uruchomieniu stack użyje warp sync, aby pobrać historię blockchainu przy użyciu protokołu pobierania zbiorczego Parity.
Na wyjściu wygląda to tak:
2018-05-11T09:27:56.202Z ++ curl -s http://169.254.169.254/latest/meta-data/public-ipv4 2018-05-11T09:27:56.253Z + PUBLIC_IP=18.196.95.41 2018-05-11T09:27:56.253Z + /parity/parity --config config.toml --nat extip:18.196.95.41 2018-05-11T09:27:56.297Z Loading config file from config.toml 2018-05-11T09:27:56.350Z 2018-05-11 09:27:56 UTC Starting Parity/v1.10.3-stable-b9ceda3-20180507/x86_64-linux-gnu/rustc1.25.0 2018-05-11T09:27:56.350Z 2018-05-11 09:27:56 UTC Keys path /root/.local/share/io.parity.ethereum/keys/Foundation 2018-05-11T09:27:56.350Z 2018-05-11 09:27:56 UTC DB path /root/.local/share/io.parity.ethereum/chains/ethereum/db/906a34e69aec8c0d 2018-05-11T09:27:56.350Z 2018-05-11 09:27:56 UTC Path to dapps /root/.local/share/io.parity.ethereum/dapps 2018-05-11T09:27:56.350Z 2018-05-11 09:27:56 UTC State DB configuration: fast 2018-05-11T09:27:56.350Z 2018-05-11 09:27:56 UTC Operating mode: active 2018-05-11T09:27:56.361Z 2018-05-11 09:27:56 UTC Configured for Foundation using Ethash engine 2018-05-11T09:27:56.730Z 2018-05-11 09:27:56 UTC Public node URL: enode://ec52f4ae94c624b1f8bf9c9b60fd63261beb42af6fea9d0fa4aeb6f52047fdf4afd92d9e3cd9c0f3387e892f378b3491ed8d85c38349ad50dce99539e952e38f@18.196.95.41:30303 2018-05-11T09:27:57.057Z 2018-05-11 09:27:57 UTC Updated conversion rate to Ξ1 = US$694.89 (6852745.5 wei/gas) 2018-05-11T09:28:06.806Z 2018-05-11 09:28:06 UTC Syncing #0 d4e5…8fa3 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #0 1/25 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T09:28:16.806Z 2018-05-11 09:28:16 UTC Syncing snapshot 9/1370 #0 2/25 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T09:28:21.807Z 2018-05-11 09:28:21 UTC Syncing snapshot 15/1370 #0 2/25 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T09:28:26.808Z 2018-05-11 09:28:26 UTC Syncing snapshot 21/1370 #0 2/25 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T09:28:31.809Z 2018-05-11 09:28:31 UTC Syncing snapshot 27/1370 #0 3/25 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T09:28:36.809Z 2018-05-11 09:28:36 UTC Syncing snapshot 29/1370 #0 3/25 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs
Proces synchronizacji snapshotów zajmuje około 3 godziny. Po zsynchronizowaniu snapshotów Parity pobierze wszystkie bloki utworzone od ostatniego snapshotu, aż do obecnie najnowszego bloku. Ta faza wygląda w logach tak:
2018-05-11T10:26:46.793Z 2018-05-11 10:26:46 UTC Syncing snapshot 1327/1370 #0 26/50 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T10:26:56.798Z 2018-05-11 10:26:56 UTC Syncing snapshot 1346/1370 #0 26/50 peers 8 KiB chain 3 MiB db 0 bytes queue 10 KiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T10:27:08.097Z 2018-05-11 10:27:08 UTC Syncing #5590000 b084…309c 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #5590000 24/25 peers 63 KiB chain 1 KiB db 0 bytes queue 6 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T10:27:16.794Z 2018-05-11 10:27:16 UTC Syncing #5590000 b084…309c 0 blk/s 0 tx/s 0 Mgas/s 1750+ 1 Qed #5591752 26/50 peers 174 KiB chain 39 KiB db 95 MiB queue 11 MiB sync RPC: 0 conn, 0 req/s, 0 µs
Wykonanie tego etapu zajmie jeszcze około godzinę.
Po zakończeniu tej fazy log zmieni się i będzie wyglądał następująco:
2018-05-11T15:24:30.011Z 2018-05-11 15:24:30 UTC Syncing #5595608 f2fe…d003 0 blk/s 0 tx/s 0 Mgas/s 0+ 7 Qed #5595619 11/25 peers 33 MiB chain 182 MiB db 1 MiB queue 8 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T15:24:41.386Z 2018-05-11 15:24:41 UTC Updated conversion rate to Ξ1 = US$679.41 (7008882.5 wei/gas) 2018-05-11T15:24:41.795Z 2018-05-11 15:24:41 UTC Imported #5595620 ef95…d8b2 (181 txs, 7.98 Mgas, 4237.27 ms, 27.63 KiB) + another 3 block(s) containing 330 tx(s) 2018-05-11T15:24:48.290Z 2018-05-11 15:24:48 UTC Imported #5595622 221b…509d (162 txs, 7.99 Mgas, 1194.76 ms, 25.13 KiB) 2018-05-11T15:24:51.186Z 2018-05-11 15:24:51 UTC Imported #5595623 b744…cf9c (183 txs, 7.98 Mgas, 1698.02 ms, 33.23 KiB) 2018-05-11T15:25:27.225Z 2018-05-11 15:25:27 UTC #40653 13/25 peers 37 MiB chain 182 MiB db 0 bytes queue 24 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T15:25:27.241Z 2018-05-11 15:25:27 UTC #40653 13/25 peers 37 MiB chain 182 MiB db 0 bytes queue 24 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T15:25:27.252Z 2018-05-11 15:25:27 UTC #40653 13/25 peers 37 MiB chain 182 MiB db 0 bytes queue 24 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T15:25:27.310Z 2018-05-11 15:25:27 UTC #40653 13/25 peers 37 MiB chain 182 MiB db 0 bytes queue 24 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T15:25:41.464Z 2018-05-11 15:25:41 UTC Imported #5595627 a4a9…9dc0 (136 txs, 7.98 Mgas, 529.92 ms, 19.68 KiB) 2018-05-11T15:26:02.263Z 2018-05-11 15:26:02 UTC #78637 23/25 peers 37 MiB chain 183 MiB db 241 KiB queue 22 MiB sync RPC: 0 conn, 0 req/s, 0 µs 2018-05-11T15:26:03.398Z 2018-05-11 15:26:03 UTC Reorg to #5595628 8fc3…7c58 (a4a9…9dc0 18c7…4d47 #5595625 f6c1…feae 3faf…012d af04…83a8)
Nowy typ linii logowania rozpoczynający się od numeru bloku (#40653 ...) pochodzi z procesu weryfikacji pobranych bloków. W tym procesie Parity weryfikuje każdy blok kryptograficznie i zapewnia, że nikt nie zmanipulował danych, które pobraliśmy od innych node’ów.
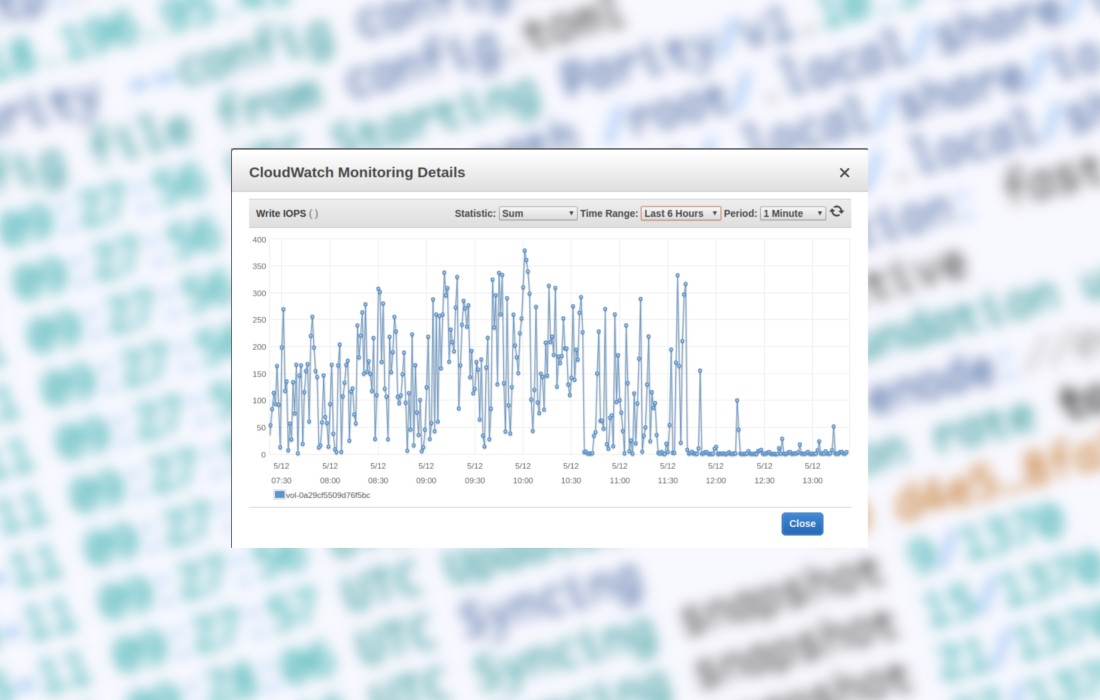
Ten proces trwa około 3 dni, gdy jest uruchamiany na maszynie t2.medium z dyskiem EBS gp2 z 300 IOPS. Podczas jego działania można obserwować w monitorowaniu EBS, że wszystkie dostępne IOPSy są używane. Zrzut ekranu poniżej przedstawia moment zakończenia procesu weryfikacji. Możesz zobaczyć różnicę we wzorcu użycia.
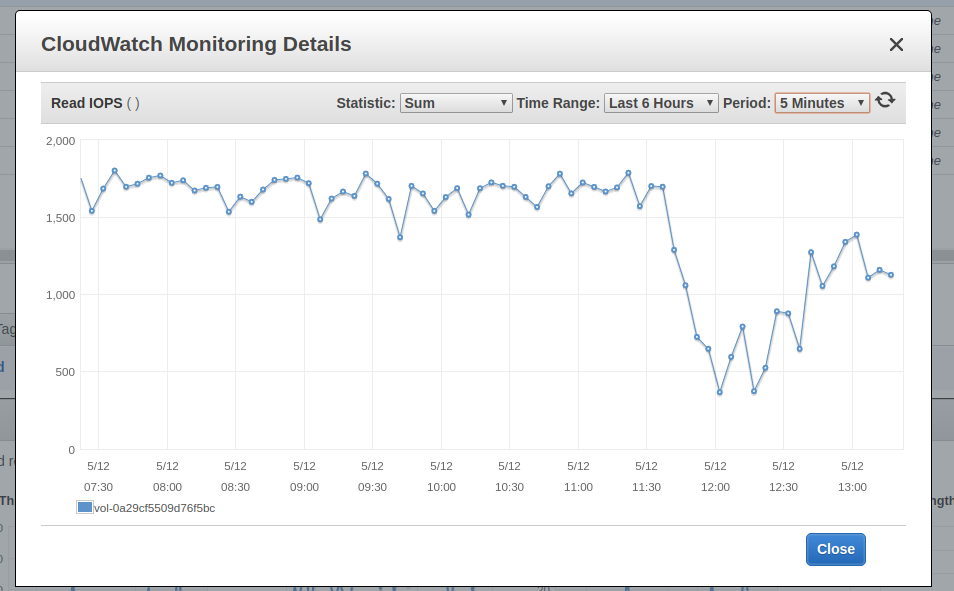
Read IOPS
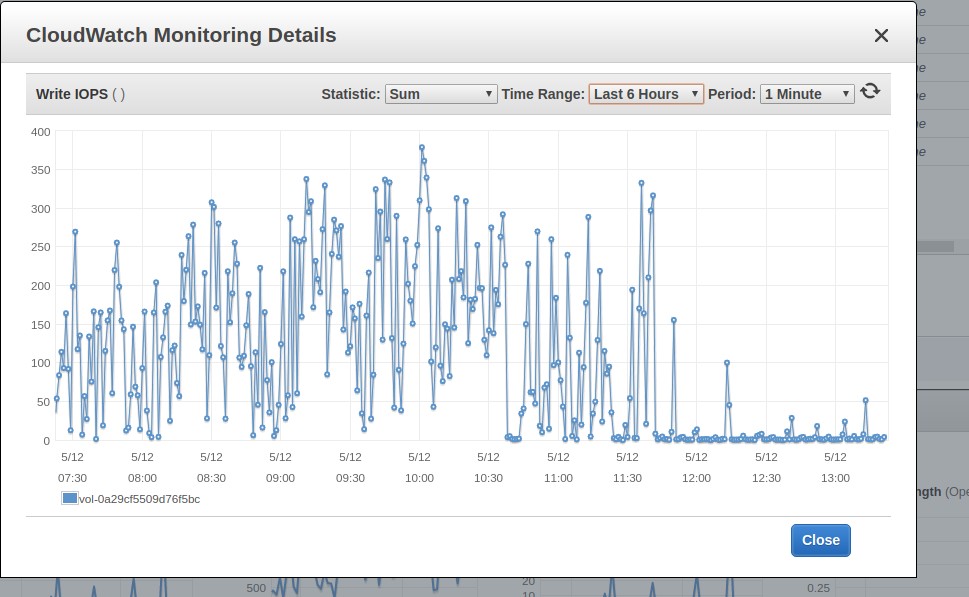
Write IOPS
Ponieważ proces weryfikacji jest ograniczony przez dostępne IOPSy, można go przyspieszyć dostarczając dodatkowe IOPSy. W naszym CloudFormation stack używamy gp2 VolumeType o rozmiarze 100 GB. AWS zapewnia 300 IOPSów dla takiego dysku. Jeśli chcesz przyspieszyć weryfikację, możesz zmodyfikować VolumeType na io1 i prowizjonować mu np. 1200 IOPS. Na tym poziomie obserwujemy w zakładce monitoringu, że proces weryfikacji nie jest już ograniczony przez dostępne IOPS, ale brakuje mu mocy CPU. Dlatego można go dalej przyspieszyć, zmieniając typ maszyny EC2 z t2.medium na c5.large. Działając na c5.large zauważyliśmy, że podczas weryfikacji Parity używa 2000 IOPS i może zakończyć cały proces w około 7 godzin, więc to jest dobry trick, jeśli bardziej niż na pieniądzach zależy nam na czasie.
Pamiętaj jednak, że dodatkowo prowizjonowane IOPSy nie są tanie — miesięczny koszt pozostawienia dysku o tym rozmiarze oraz IOPS, wyniesie w okolicach 100 USD, więc lepiej uważać.
Utrzymanie synchronizacji
Gdy node jest w pełni zsynchronizowany, zwykle pozostaje zsynchronizowany z najnowszym blockiem.
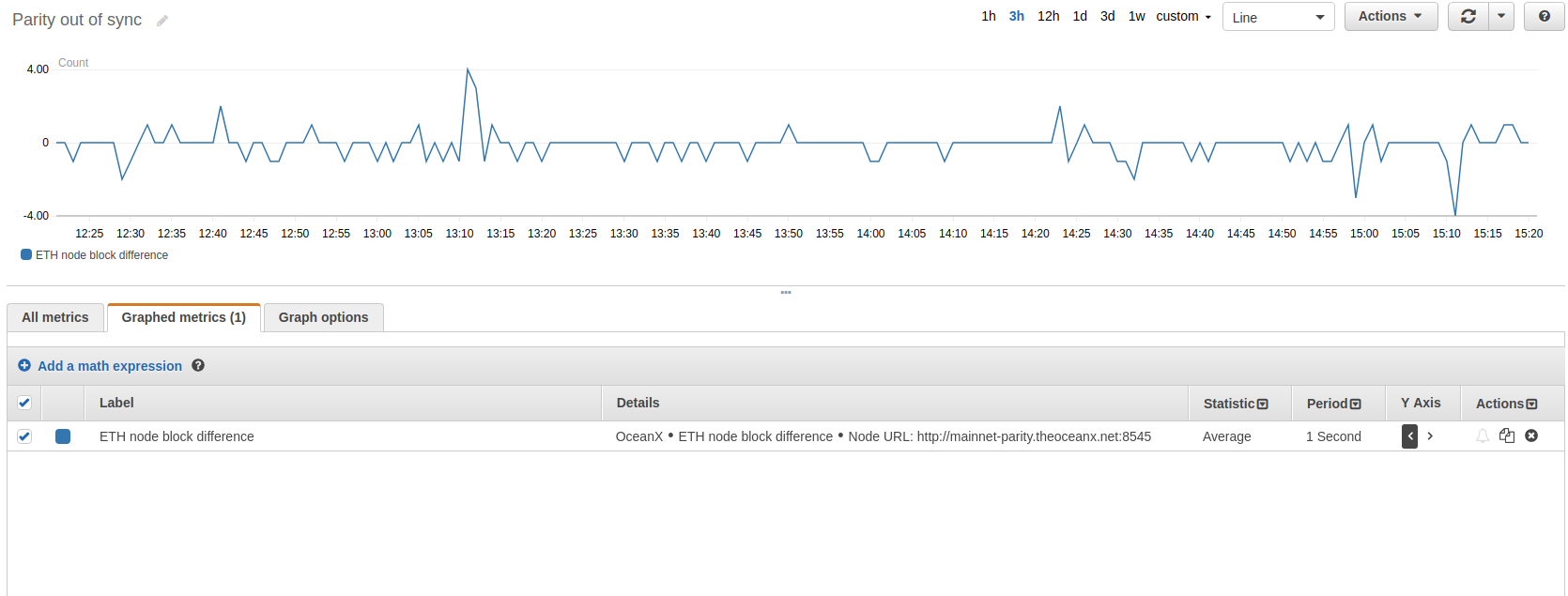
Powyższy obrazek przedstawia efekt wywołania eth_blockNumber na naszym node’ie i na Infurze. Przez większość czasu node’y są zsynchronizowane. Sporadycznie nasz node lub Infura spada o 1-4 bloki do tyłu. Pamiętaj, że obecnie to repozytorium nie zawiera Lambdy odpowiedzialnej za gromadzenie powyższych danych. Ta część infrastruktury znajduje się w narzędziu wyższego rzędu.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
