Tworzenie prywatnego klastra Kubernetes na GKE. Takiego, który działa

Kubernetes powoli zaczyna pojawiać się wszędzie. Jak mówi stary dowcip: “strach otworzyć lodówkę”, żeby go tam nie znaleźć. Gdy kilka kontenerów na pojedynczym serwerze przestaje wystarczać, Kubernetes wydaje się naturalnym wyborem. Dzięki temu, że tworzy warstwę abstrakcji pomiędzy infrastrukturą, a aplikacjami jest niesamowicie wygodny. I niestety — niesamowicie skomplikowany.

Grzegorz Kocur. Senior DevOps Engineer w firmie Softwaremill. Wierzy, że nie ma jednego właściwego rozwiązania a kluczem do sukcesu jest dobór właściwego narzędzia do konkretnych potrzeb. Na co dzień zajmuje się systemami CI/CD, automatyzacją i orkiestracją. Prywatnie — mąż, ojciec, wielbiciel gór i wspinaczki.
Aby utworzyć własny klaster Kubernetes trzeba opanować sporo nowych rzeczy: etcd, certyfikaty, wiele możliwości utworzenia warstwy sieciowej… może od tego rozboleć głowa. Zwłaszcza, że później trzeba to jeszcze utrzymać i rozwijać. Na szczęście z pomocą przychodzi coraz szersza oferta utrzymywania klastrów Kubernetes po stronie dostawcy (ang. hosted).
Spis treści
Google Kubernetes Engine
Któż ma więcej doświadczenia w utrzymywaniu dużych klastrów Kubernetes niż Google? GKE to świetny wybór na początek — umożliwia utworzenie nowego klastra w ciągu kilku minut i całkowicie eliminuje konieczność utrzymania zarówno serwerów tworzących klaster, jak i samego klastra.
Spróbujmy utworzyć pierwszy klaster Kubernetes. Zakładam, że posiadasz konto w usłudze Google Cloud oraz zainstalowane narzędzie gcloud umożliwiające operacje na Google Cloud z poziomu linii poleceń.

Konsola graficzna
Dobrą praktyką jest tworzenie infrastruktury przy użyciu któregoś z narzędzi służącego do jej opisu w postaci kodu (Infastructure as a Code). Świetnym przykładem jest np. terraform. Możliwe jest również utworzenie klastra przy pomocy gcloud, całkowicie z poziomu linii poleceń. Na początku warto jednak pobawić się graficzną konsolą udostępnioną przez GCP jako strona www, chociażby po to, aby dowiedzieć się jakie mamy opcje.
Aby rozpocząć należy wybrać z menu Kubernetes Engine > Klustry > Utwórz klaster.
Na samej górze należy określić nazwę klastra, podać opcjonalny opis oraz wybrać lokalizację. Możliwy wybór to strefa (węzły klastra będą umieszczone w pojedynczej strefie dostępności) lub region (węzły będą umieszczone w wielu strefach w obrębie regionu). W zależności od dokonanego wyboru należy wybrać strefę lub region.
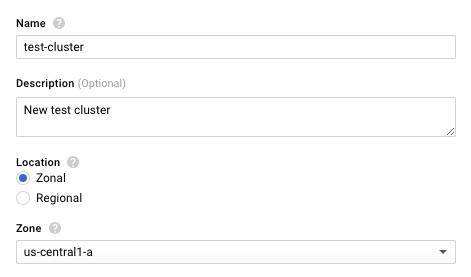
Następnie należy wybrać wersję Kubernetes, wielkość węzłów, obraz bazowy, z którego stworzone zostaną węzły oraz liczbę węzłów. Należy zwrócić uwagę, że jeśli powyżej został wybrany region, minimalna liczba węzłów to 3 (po 1 w 3 strefach dostępu). Poniżej widoczne jest wygodne podsumowanie dotyczące użytych zasobów. W tym przypadku zmieniono ustawienia domyślne i wybrano nowszą wersję Kubernetes.
Na dole strony widoczny jest intrygujący przycisk:
![]()
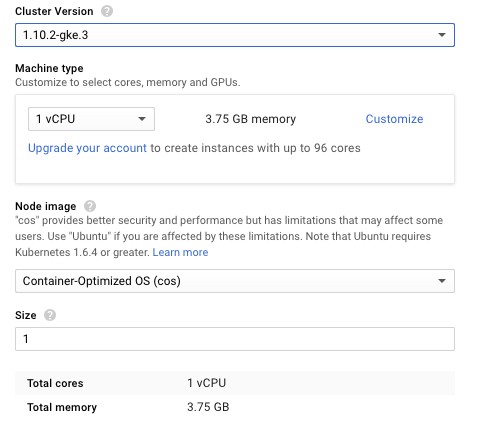
Sprawdźmy więc, co się pod nim kryje. Rozwijając go otrzymujemy dostęp do imponującej liczby zaawansowanych opcji konfiguracyjnych. Pozwalają one przypisać węzłom etykiety, uruchomić węzły w dodatkowych strefach, a nawet włączyć cechy klastra będące jeszcze w fazie alpha. Dostępne jest również autoskalowanie — w razie potrzeby GKE uruchomi automatycznie dodatkowe węzły (lub wyłączy nadmiarowe).
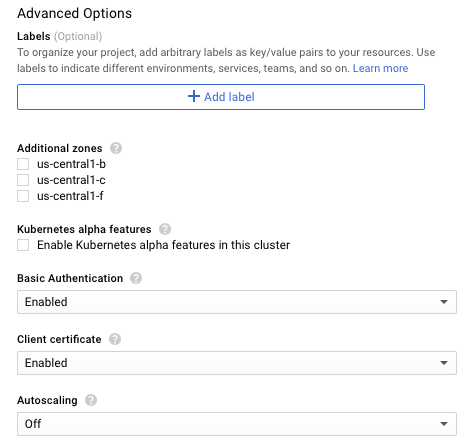
Możliwe jest też użycie instancji z opcją wywłaszczania. To zdecydowanie dobry pomysł w przypadku klastra testowego. Działanie w trybie 24/7 nie jest konieczne, a koszty będą zdecydowanie niższe (przypomnijmy — węzły z możliwością wywłaszczania będą “żyły” maksymalnie 24 godziny. Po tym czasie zostaną usunięte, a w ich miejsce powstaną nowe).
Kolejna propozycja wydaje się szczególnie interesująca. “Klaster prywatny” już na pierwszy rzut oka wygląda na bardziej bezpieczny, a publiczne adresy IP węzłów nie są zwykle potrzebne.

Po włączeniu powyższej opcji konieczne jest podanie puli adresów (prywatnych!) serwerów “master” tworzonego klastra. Możemy również wybrać własną pulę adresów dla kontenerów i usług.
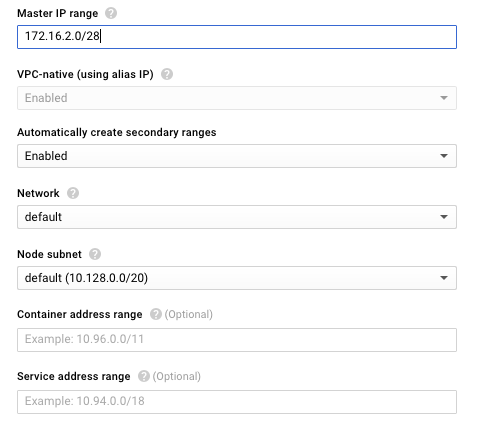
Dostępna jest też opcja ograniczenia dostępu do serwerów “master” (a co za tym idzie do klastra jako takiego) tylko dla konkretnych podsieci. Włączenie tej opcji zdecydowanie podniesie bezpieczeństwo, więc jeżeli dysponujemy stałym adresem IP zalecam skorzystanie z tej możliwości.
Na koniec mamy jeszcze sposobność instalacji dodatków, takich jak graficzny interfejs (kubernetes dashboard) czy kontrolera Ingress (który umożliwi dostęp z zewnątrz do usług używających protokołu HTTP(s)).

Po zatwierdzeniu nowy klaster jest tworzony, co zajmuje zwykle kilka minut. Zanim będziemy mogli się z nim połączyć przy pomocy kubectl, konieczne jest pobranie danych dostępowych przy pomocy narzędzia gcloud:
gcloud container clusters get-credentials test-cluster --zone us-central1-a --project new-project
Teraz możemy sprawdzić, czy nowo utworzony klaster działa poprawnie:
kubectl run hello-world --image=gcr.io/google-samples/node-hello:1.0 --port=8080 deployment.apps "hello-world" created
Wygląda na to, że wszystko działa jak trzeba. Sprawdźmy to:
kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE hello-world 1 1 1 1 54s kubectl get pods NAME READY STATUS RESTARTS AGE hello-world-78c5c876d4-ltdr5 1/1 Running 0 1m
Spróbujmy udostępnić naszą usługę światu:
kubectl expose deployment hello-world --port=8080 --type=LoadBalancer service "hello-world" exposed kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-world LoadBalancer 10.0.13.194 35.225.14.164 8080:30321/TCP 44s kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 19m
Sprawdźmy, czy się udało, używając przeglądarki:

Świetnie, wszystko wygląda dokładnie tak, jak powinno. Czas na coś bardziej skomplikowanego:
kubectl run mariadb --image mariadb --env="MYSQL_ROOT_PASSWORD=password" deployment.apps "mariadb" created kubectl get pods NAME READY STATUS RESTARTS AGE mariadb-785d6974b7-5q8kk 0/1 ImagePullBackOff 0 1m
Wygląda to dziwnie: dlaczego nasz klaster nie potrafi pobrać oficjalnego, publicznego obrazu?
Zastanówmy się: zdecydowaliśmy się na klaster prywatny. Chyba powoli czas sięgnąć do dokumentacji (oczywiście powinniśmy to zrobić na początku, ale przecież nikt tak nie robi).
In a private cluster, the Docker runtime can pull container images from Google’s Container Registry. It cannot pull images from any other registry on the internet. This is because the nodes in a private cluster do not have external IP addresses, so they cannot communicate with sites outside of Google.
Ach więc to tak. “Prywatny” oznacza “naprawdę prywatny”, czyli bez dostępu do internetu. Na pewno jest to bardzo bezpieczne, ale chyba nie do końca o to chodziło. A gdyby spróbować obejść problem “puszczając” ruch sieciowy przez inną instancję oraz używając translacji adresów IP?
Niestety w chmurze GCP nie mamy do dyspozycji gotowego, zarządzanego przez dostawcę urządzenia podobnego do “NAT Gateway” w AWS, więc musimy taką instancję utworzyć samodzielnie:
gcloud compute instances create nat-gateway --network default --can-ip-forward --zone us-central1-a --image-family=centos-7 --image-project=centos-cloud --boot-disk-size 10G --machine-type f1-micro
Koniecznie należy zastosować opcję –can-ip-forward — jest ona kluczowa, a można ją podać wyłącznie podczas tworzenia instancji.
Po utworzeniu nowej instancji i zalogowaniu się na nią przy pomocy ssh możemy skonfigurować ją jako bardzo prosty “router”:
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf sysctl -f iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE firewall-cmd --runtime-to-permanent
Ostatnią rzeczą, której potrzebujemy, jest odpowiedni wpis w tablicy routingu w VPC. Domyślne wpisy mają priorytet 1000, musimy więc użyć niższego numeru (im niższy numer tym większy priorytet):
gcloud compute routes create nat-internet-route --network default --destination-range 0.0.0.0/0 --next-hop-instance nat-gateway --next-hop-instance-zone us-central1-a --tags no-ip --priority 900
Zwróćmy uwagę na opcję –tag no-ip. Oznacza ona, że dodana trasa będzie wykorzystywana przez wszystkie instancje, które są oznaczone tagiem “no-ip” (chodzi o “network tag”, nie należy mylić tego z etykietą instancji, czyli “label”).
Dodajmy więc odpowiedni tag:
gcloud compute instances add-tags gke-test-cluster-default-pool-11723ed6-7lh1 --tags no-ip --zone us-central1-a
Po chwili:
kubectl get pods NAME READY STATUS RESTARTS AGE mariadb-67667f4b8c-lcss5 1/1 Running 0 7s
Oczywiście powyższe rozwiązanie jest tymczasowe — będzie działać, dopóki oznaczona w ten sposób instancja nie zostanie usunięta. Nowa instancja utworzona na jej miejscu nie będzie miała odpowiedniego taga. Aby rozwiązanie to stało się permanentne koniecznie jest utworzenie nowej puli instacji dla klastra (ustawiając odpowiedni tag) i usunięcie puli domyślnej. Zostawiam to jako samodzielne ćwiczenie dla czytelnika.
Podsumowanie
Klaster prywatny używający instancji bez bezpośredniego dostępu do internetu to bardzo dobry pomysł. Na pewno będzie bezpieczniejszy od standardowego i jednocześnie odporniejszy na ludzkie pomyłki dotyczące na przykład konfiguracji zasad zapory sieciowej. Klaster taki wymaga jednak dodatkowej konfiguracji. Będzie ona niezbędna, jeśli chcemy używać obrazów dockerowych przechowywanych poza wewnętrzną siecią Google (np. na Docker Hub). Należy zwrócić uwagę, że opisana konfiguracja tworzy pojedynczy punkt awarii (SPOF). Z drugiej jednak strony instancja NAT jest potrzebna wyłącznie podczas uruchamiania nowych zasobów i jej chwilowa niedostępność nie wpływa na funkcjonalność klastra.
Można również rozważyć używanie GCR jako jedynego miejsca przechowywania obrazów — takie rozwiązanie będzie działało bez konieczności tworzenia i utrzymywania dodatkowej instancji.
Artykuł został przetłumaczony z blog.softwaremill.com. Zdjęcie główne artykułu pochodzi ze stocksnap.io.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
