Tworzenie cross-platformowej logiki w języku C++ dla natywnych aplikacji (cz.1)

Niejednokrotnie spotykamy się z sytuacją, kiedy tworzymy aplikację w języku natywnym — z różnych powodów, czy to pod presją czasu, czy z chęci skorzystania z dobroci danej platformy. Co zrobić, jeśli aplikacja rozwinęła się na tyle, że zaczyna na siebie zarabiać, a my musimy podjąć decyzję o rozbudowie o kolejne platformy? Co jeśli stajemy przed problemem zrównania funkcjonalności pod względem logiki biznesowej? W tym artykule postaram się opisać moje doświadczenia związane z produkcją kodu cross-platformowego dla natywnych aplikacji.

Marcin Małysz. Na co dzień pracuje jako architekt oprogramowania w firmie Explain Everything budując i rozwijając silnik animacyjny zasilający nasz produkt. W wolnych chwilach tworzy gry i jest zapalonym graczem Counter Strike. Niektóre z jego prac można znaleźć na https://warsztat.gd/user/noxy/projects. Jako człowiek wychowany na 4chanie jedyna formę komunikacji jaką uznaje za słuszną to memy i gify.
Od zawsze interesowało mnie tworzenie gier, a w późniejszym czasie rozrosło się to w prawdziwą pasję. Dlatego też całość zagadnienia opiszę w postaci projektu gry wieloplatformowej, stworzonej na potrzeby zrozumienia problemu projektowania i pisania kodu, który kompiluje się i działa na wielu platformach. Podjąłem się go w charakterze hobby, dlatego też nie skupiam się na jego jakości czy użytych wzorcach. Głównym celem jest odpalenie rdzenia gry w aplikacjach, które są napisane w języku najczęściej używanym na danej platformie — bądź z przyczyn technicznych jedynym możliwym do użycia. Stąd brak użycia tak popularnego języka Swift w projekcie iOS (ale o tym w dalszej części artykułu).

Spis treści
Opis problemu
Rok temu stanąłem przed wyzwaniem polegającym na przeniesieniu silnika naszej aplikacji explaineverything.com z iOS i macOS na bardziej przenośny i skalowalny silnik, który pozwoliłby na integrację np. z Linuxem. Pomogłoby to obniżyć koszty utrzymania i rozbudowy oraz przede wszystkim umożliwić wyrównanie developmentu.
Aby lepiej zrozumieć problem, postanowiłem napisać grę, która będzie zawierać główną część związaną z renderowaniem, AI, komunikacją sieciową oraz zapisem i odczytem w języku, który znam, ale porzuciłem wiele lat temu: C++.
Dlaczego wybrałem C++? Wiele osób uważa go poniekąd za relikt i język niezwykle trudny do opanowania. Nie mam tu na myśli składni, ale standardu, który opisuje jak zachowa się kod. Problem komplikuje sytuacja tak zwanego “undefined behaviour”, gdzie wykonanie kodu zależy od implementacji danego kompilatora/architektury. Pomimo tej wady, C++ jest językiem niezwykle przenośnym i szybkim, co czyni go idealnym kandydatem do tego zadania.
Biblioteki, technologia i narzędzia
Aby problem nakreślić bardziej realnie, postanowiłem dodatkowo użyć paru bibliotek i kodu, który będzie również cross-platformowy oraz pozwoli rozwiązać ewentualne problemy z linkowaniem i przenoszeniem kodu. Wybrałem dwie biblioteki FMOD oraz FreeType2. Dodatkowo znalazłem bibliotekę clsocket, którą po drobnych modyfikacjach przygotowałem do obsługi logiki multiplayer. Wersją języka C++, która posłuży do implementacji będzie wersją 14, z powodu wspierania przez większość dostępnych dziś kompilatorów (dokładna lista kompatybilności jest dostępna pod tym adresem).
Do renderowania użyłem najbardziej popularnego API graficznego jakim jest OpenGL. Należy tu zaznaczyć, że będę operować na wersji 3.2 Core orac ES2.0. Obie zawierają wspólny subset funkcji, które przydadzą się do wyświetlenia obrazu i zapewnią pełną przenośność. Dodatkowo wybrałem zestaw paru bibliotek, które pomogą ułatwić budowę projektu i przyspieszą ew. implementację na niektórych platformach.
Podsumowując:
Język: C++14
Biblioteki cross-platformowe: FMOD, freetype2, stb_image, OpenGL
Dodatkowe biblioteki pomocnicze: GLFW, GLEW, clsocket oraz nuclear.
Ostatnia z opisanych bibliotek jest przenośną biblioteką pozwalającą na budowanie tak zwanego GUI, czyli interfejsu użytkownika na platformach, które nie wystawiają takiego API out of the box.
Tworzenie kodu
Odgórnym założeniem projektu jest tworzenie kodu, który będzie dołączany jako biblioteka statyczna albo jako część projektu kompilowana do wynikowej aplikacji. Pierwszym krokiem powinno być określenie platform, na których odpalimy naszą aplikację — w tym wypadku grę.
Wybrałem te najbardziej popularne oraz takie, które zaciekawiły mnie jako ew. potencjalne przyszłe zamienniki innych platform. Wybrane platformy to iOS, macOS, Linux, Windows, Android, HTML5 i Raspberry Pi. Na początku artykułu napisałem, że nasza “logika biznesowa” będzie dołączana do istniejących już aplikacji.
Robimy to z kilku powodów: zakładamy, że kod produkcyjnie już istnieje, działa i być może jest już napisany na paru (dwóch, trzech jednak nie wszystkich) platformach. Chcemy zachować natywną implementację jaką serwuje nam platforma — w moim wypadku były to gotowe aplikacje mobilne na iOS i Android oraz serwer przystosowany do pracy z systemem macOS. Platformy, które dopiero będą implementowane mogą pokusić się o użycie bibliotek technologii najbardziej popularnych w danym środowisku, bądź postawić na pełną cross-platformową implementację, która może dzięki temu przyspieszyć ew. wsparcie dla nowo pojawiających się platform, bądź zastąpienie aktualnych w całości, jeżeli oprogramowanie nie korzysta ze specyficznych dla platformy API czy funkcjonalności sprzętu.
Na tym etapie przedstawię projekt, który posłuży jako materiał na ten artykuł. Gra, którą stworzyłem, to przenośna strategia turowa, posiadająca tryb rozgrywki z komputerem, bądź innymi graczami w sieci. Przy jej tworzeniu pomogła mi firma infullmobile.com, która dostarczyła tekstury do projektu. Jej pełny kod źródłowy jest dostępny pod adresem: github.com/inFullMobile/pixfight. Jeżeli czujesz się na siłach, zachęcam do przejrzenia kodu, aby zrozumieć ogólna ideę projektu.
Całość podzieliłem na cztery główne katalogi:
1. Core — zawierający główny kod logiki C++ współdzielony między platformami.
2. Mapeditor — kod edytora map, który korzysta z Core i jest kompilowany do desktopowych platform Windows, Linux i macOS.
3. Platform — zawierający implementacje poszczególnych platform, na których odpala się gra korzystając z Core.
4. Server — kod dedykowanego serwera gry, potrzebnego do uruchomienia trybu dla wielu graczy oraz części klienta, z której korzysta Core.
Chciałbym tutaj zaznaczyć, że będę skupiać się w dużej mierze na problemach jakie napotkałem przy integracji części CORE z platformami, a nie na samym setupie środowiska i ew. wymaganiach, co do IDE. Są one często wyborem programisty — ja użyłem tych najbardziej popularnych.
Pierwszy problem jaki napotkamy, to odpowiednie ustawienie nagłówków w projekcie. O ile biblioteki załączone przez nas możemy bezproblemowo ustawić w naszym IDE, tak te dostarczone przez system, jak na przykład OpenGL, będą zaszyte w różnych lokalizacjach. W ich odnalezieniu można posłużyć się dokumentacją IDE, bądź użyć poleceń systemowych terminala / konsoli systemu.
Przykładowy nagłówek pliku, który posłuży nam do poprawnego dołączania nagłówków OpenGL do naszej aplikacji może wyglądać tak:
#pragma once
#ifdef __EMSCRIPTEN__
#define GL_GLEXT_PROTOTYPES
#include <GLES/gl.h>
#include <GLES2/gl2.h>
#include <GLES2/gl2ext.h>
#define GLFW_INCLUDE_ES2
#include <GLFW/glfw3.h>
#else
#ifdef _WIN32
#define NOMINMAX
#include <GL/glew.h>
#include <GL/gl.h>
#include <GLFW/glfw3.h>
#define GL_RED_EXT GL_RED
#endif
#ifdef __APPLE__
#if TARGET_OS_IPHONE
#include <OpenGLES/ES1/gl.h>
#include <OpenGLES/ES1/glext.h>
#include <OpenGLES/ES2/gl.h>
#include <OpenGLES/ES2/glext.h>
#else
#include <OpenGL/gl3.h>
#include <OpenGL/gl3ext.h>
#endif
#endif
#ifdef __ANDROID__
#include <GLES/gl.h>
#include <GLES2/gl2.h>
#include <GLES2/gl2ext.h>
#include <EGL/egl.h>
#include <string.h>
#elif defined(__linux__)
#ifdef _RPI_
#include <GLES2/gl2.h>
#include <GLES2/gl2ext.h>
#include <EGL/egl.h>
#else
#include <GL/glew.h>
#include <GL/gl.h>
#endif
#include <GLFW/glfw3.h>
#ifndef _RPI_
#define GL_RED_EXT GL_RED
#endif
#endif
Niestety nie jest to koniec naszych zmagań, bo o ile zidentyfikujemy odpowiednie platformy po odgórnie określonych definicjach jak __APPLE__ , __linux__ etc. — musimy wziąć pod uwagę fakt, że niektóre platformy definiują wiele makr. Przykładem może być Android, który jest zarazem Linuxem. Dlatego należy pamiętać, żeby odpowiednio zabezpieczyć się przed złą kolejnością.
Następnie musimy określić, których wersji OpenGL użyjemy. Wersje embedded system będą użyte do platform, które bezpośrednio wspierają to API jak np. telefony komórkowe, przeglądarki i komputery oparte na procesorach ARM. Celowo używam tu określenia procesor ARM ponieważ Raspberry Pi, pomimo że jest mikrokomputerem, tak naprawdę opiera się na podzespołach typowych dla smartfonów. Żeby go wydzielić nie użyłem makrodefinicji __arm__, a przygotowałem własną _RPI_ ustawianą w IDE podczas kompilacji pod ten konkretny sprzęt, aby uniknąć kolejnej dwuznaczności.
Zapis i odczyt plików
Następnym wyzwaniem z jakim przyjdzie nam się zmagać jest dostęp do zasobów naszej aplikacji — chodzi głównie o możliwość zapisu i odczytu plików. Warto więc skonstruować nasz kod tak, aby przy starcie otrzymywał ścieżkę roboczą do katalogu, w którym znajdują się nasze dane jak np. tekstury, pliku audio czy konfiguracje kończąc na plikach stanu gry. Mówię o tym ponieważ nie każdy system operacyjny pozwoli aplikacji na dostęp do dowolnego katalogu. Niektóre systemy jak np. Android czy iOS odpalają aplikacje w tak zwanym “sandboxie” izolując je od samego systemu, uniemożliwiając tym samym jej komunikację na zewnątrz. Dla przykładu dla systemu iOS będzie to std::string path = [[NSBundle mainBundle] resourcePath].UTF8String + "/data/"; gdzie np. dla systemu Linux użyjemy ścieżki do naszego pliku wykonywalnego pobranego za pomocą tego kodu.
std::string getExecutablePath() {
char result[ PATH_MAX ];
ssize_t count = readlink( "/proc/self/exe", result, PATH_MAX );
std::string path = std::string( result, (count > 0) ? count : 0 );
return path.substr(0, path.find_last_of("\/")) + "/data/";
}
Analogicznie będziemy zapisywać nasze dane, używając względnej ścieżki do naszego pliku wykonywalnego, bądź prosząc system o podanie ścieżki bezwzględnej, która będzie mieć nadane odpowiednie prawa do zapisu. Jeszcze innym sposobem może być wykorzystanie pamięci masowej ogólnego przeznaczenia. Takie rozwiązanie jest często stosowane w systemach Android, gdzie aplikacje przygotowują sobie specjalny katalog na karcie SD, bądź pamięci wewnętrznej telefonu, aby mieć bezpośredni dostęp do plików.
Mówiąc o zasobach, należałoby wspomnieć o tym, jak niektóre platformy przechowują dane aplikacji. W naszym wypadku to silnik C++ odpowiada za załadowanie plików (np. tekstur) z dysku, ich przetwarzanie i wyświetlanie. Dlatego potrzebujemy dostępu do plików w ich oryginalnej postaci. Dla przykładu xCode IDE firmy Apple podczas budowania aplikacji optymalizuje wszystkie pliki graficzne do formy zoptymalizowanej dla karty graficznej “psując” ich wygląd (proces ten nazywany jest potocznie PNGCrush). Dlatego musimy zadbać o to, aby takie pliki zostały wyłączone z procesu optymalizacji — inaczej będą wyświetlać się niepoprawnie. To samo dotyczy Androida, jednak tutaj problem wynika z budowy paczek APK, które są trzymane jako skompresowane, przez co dostęp do plików bezpośrednio nie jest możliwy i musimy je “wypakować” do zewnętrznego katalogu, aby móc z nich korzystać.

Programowanie kodu wieloplatformowego przy użyciu C++ niesie za sobą ryzyko związane z tak zwanym Undefinied Behaviour. Czym jest Undefinied Behaviour zapytacie? W uproszczeniu można powiedzieć, że wykonany kod zachowa się w sposób nie zdefiniowany, innymi słowy coś może zadziałać tak jak chcemy albo nie. Jest to zachowanie zgodne ze standardem C++. Ponieważ to na programiście leży odpowiedzialność zadbania o to, by taki kod wykonywał się poprawnie i był napisany w sposób przewidywalny. Sprawę komplikuje fakt, że proces tworzenia kodu często wymaga użycia wielu kompilatorów i wielu różnych procesorów, w których każdy może zachować się inaczej ponieważ użyty na konkretnej platformie kompilator nie ma obowiązku wygenerować kodu jakiego oczekujemy. Genialny przykładem może być dzielenie przez 7 🙂 Kod asemblera wygenerowany dla takiego działania może generować instrukcje, które w żaden sposób nie będą nas naprowadzać na to, że w danym miejscu wystąpiło dzielenie.
Przykładowy kod ASM dla kodu skompilowanego z -O0, czyli brak optymalizacji:
mov eax, dword ptr [rbp - 4] cdq mov edi, 7 idiv edi pop rbp ret
Oraz przykład tego samego kodu przy wysokiej optymalizacji -O2:
movsxd rax, edi imul rcx, rax, -1840700269 shr rcx, 32 add eax, ecx mov ecx, eax shr ecx, 31 sar eax, 2 add eax, ecx ret
W wersji zoptymalizowanej widać mnożenie przez jakąś dziwną wartość oraz przesunięcia bitowe zamiast normalnego dzielenia, jak w przypadku wersji nie zoptymalizowanej.
Wracając do problemu UB, pisząc kod, w którym z jakiegoś powodu wystąpiło UB może dojść do sytuacji, gdzie nasz kod działa przez wiele tygodni i wydaje się być stabilnym aż do momentu dodania nowej platformy, bądź wywołania tego kodu wielowątkowo. Nagle okazuje się, że nasz program przestaje działać. Szczęściem w nieszczęściu można nazwać sytuację, w której nasz kod zawiesi się, bądź zamknie aplikacje z wyjątkiem, gorzej gdy problem jest losowy i dojście do niego wymaga wielu godzin debugowania. (Miałem autentycznie taką sytuację, gdzie przez 3 dni szukaliśmy problemu, którego naprawienie wymagało zmiany dosłownie 1 linijki kodu). Dla przykładu UB można podać metodę .back() klasy vector ze standardowej biblioteki. Wywołanie tej metody na pustym wektorze generuje właśnie UB. Gdzie np. dla kompilatora LLVM wygenerowany kod poprawnie obsłuży tę sytuację i zignoruje to wywołanie wyrzucając ew. losową wartość referencji. Gorzej będzie z kompilatorem clang pod Linuxem, którego wygenerowany kod UB popada w nieskończoną pętlę blokując wątek na zawsze. (coś w rodzaju deadlock’a).
Zanim przejdę do kolejnej części, chciałbym poruszyć jeszcze problem rozwiązywania implementacji specyficznych dla danej platformy. Wiadomo nie od dziś, że można napisać wszystko od zera samemu. Ale często zdarza się, że chcemy skorzystać z pewnej bardzo specyficznej funkcjonalności, którą np. oferuje nam dany system operacyjny. Dla przykładu posłużę się tu mierzeniem czasu w bardzo wysokiej precyzji, które może nam się przydać do obliczenia fizyki, bądź generowania statystyk użycia. Do rozwiązania takiego problemu doskonale nadaje się mechanizm języka C++ nazywany potocznie polimorfizmem. Nie będę tu dokładnie opisywać na czym ten mechanizm polega — jeżeli kogoś interesuje dokładne wytłumaczenie zasady działania odsyłam do książek poświęconych językowi C++. (Polimorfizm oraz tak zwane VTable, które odpowiada za ten mechanizm). W uproszczeniu można powiedzieć, że nasz kod pomimo wielu implementacji wie jaką wersję ma wykonać.
Gra, którą tu prezentuję oblicza poruszanie, animację oraz ew. logikę poprzez użycie mechanizmu fizyki stało krokowej. Fizyka stałokrokowa jest to jeden z rodzajów implementacji obliczania delty czasu pozwalający uniknąć problemów związanych z brakiem stałej ramki czasowej oraz ew spadków FPS. Dzięki czemu jest ona zawsze dokładna i odporna na ewentualne błędy obliczeniowe.
constexpr static const float MAX_FRAME_TIME = 0.01;
_timer->update();
_sec = _timer->getElapsedSeconds();
_sec = max(0.0, _sec);
_accumulator += max(_sec, MAX_FRAME_TIME);
_accumulator = clamp(_accumulator, 1.0, 0.0);
while (_accumulator >= MAX_FRAME_TIME) {
think(MAX_FRAME_TIME);
_accumulator -= MAX_FRAME_TIME;
}
W podanym przykładzie interesuje nas głównie metoda: timer->update(), która wylicza czas jaki nastąpił pomiędzy ostatnią wyrysowaną klatką na ekranie, a aktualnym czasem wykorzystując do tego celu funkcje systemu operacyjnego, na którym została skompilowana. W tym wypadku stworzyłem implementacje oparte o następujące systemy operacyjne: Windows, Linux oraz Darwin (macOS , iOS). Pozwoliło to na dokładne liczenie czasu na wszystkich platformach, które posłużyły do uruchomienia gry.
Implementacja pod rodzinę systemów Windows:
void WindowsTimer::update() {
this->m_lastTime = milliseconds_now();
if (_use_qpc) {
m_elapsed = (m_lastTime - m_startTime) / _frequency.QuadPart;
}
else {
m_elapsed = m_lastTime - m_startTime;
}
this->m_startTime = this->m_lastTime;
}
long long WindowsTimer::milliseconds_now() {
if (_use_qpc) {
LARGE_INTEGER now;
QueryPerformanceCounter(&now);
return now.QuadPart;
}
else {
return GetTickCount();
}
}
Implementacja pod rodzinę systemów opartych o Darwin:
#include <mach/mach_time.h>
void DarwinTimer::update() {
this->m_lastTime = mach_absolute_time();
uint64_t difference = m_lastTime - m_startTime;
static double conversion = 0.0;
if ( conversion == 0.0 )
{
mach_timebase_info_data_t info;
kern_return_t err = mach_timebase_info( &info );
if( err == 0 )
conversion = 1e-9 * (double) info.numer / (double) info.denom;
}
m_elapsed = conversion * (double) difference;
this->m_startTime = this->m_lastTime;
}
Implementacja pod rodzinę systemów opartych o Linux:
#include <time.h>
void AndroidTimer::update() {
timespec lTimeVal;
#if defined(__EMSCRIPTEN__) || defined (__ANDROID__)
clock_gettime(CLOCK_MONOTONIC, &lTimeVal);
#else
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &lTimeVal);
#endif
this->m_startTime = lTimeVal.tv_sec + (lTimeVal.tv_nsec * 1.0e-9);
m_elapsed = (m_startTime - m_lastTime);
m_lastTime = m_startTime;
}
Jak widać znajomość wielu API systemowych jest kolejną umiejętnością przydatną przy tworzeniu kodu wieloplatformowego.
Aplikacje natywne
Jedną z pierwszych barier z jaką przyjdzie nam spotkać się podczas pisania, a raczej integracji kodu z natywnymi aplikacjami jest zarządzanie pamięcią na danej platformie. Jest to również doskonały moment, aby nauczyć się zasad pisania na danej platformie w myśl zasady “Know everything about something and something about everything”. Będzie to również doskonały moment na integrację z innymi zespołami deweloperskimi jeżeli takowe istnieją w biurze.
Większość popularnych języków programowania operuje na tak zwanym Reference Counting, czyli zliczaniu referencji użyć danego obiektu, bądź jego połączeniu z innymi obiektami. Dzięki temu kod wie, kiedy zwolnić pamięć (obiekt np. przestał być używany, bądź wszystkie jego relacje zostały rozwiązane). Na szczęście nowe wersje języka C++ dodają wsparcie do automatycznego zarządzania pamięcią poprzez tak zwane smart pointers. Jeżeli byliśmy przyzwyczajeni do zarządzania pamięcią za nas, dość łatwo przyjdzie nam zrozumienie zasady działania mechanizmów zawartych w C++. W tabeli poniżej znajduje się rozpisanie mechanizmy zarządzania pamięcią w zależności od użytego języka programowania:
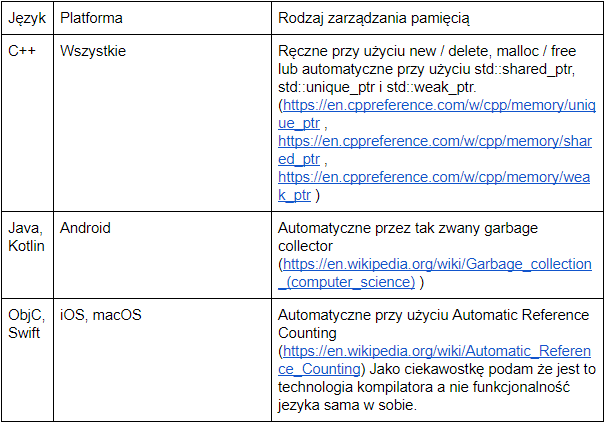
W tym momencie niektórzy z was pewnie zapytają dlaczego nie wspominam tutaj o niezwykle szybko adaptowanym języku Swift bądź Kotlin. O ile integracja z językiem Kotlin na platformie Android nie różni się praktycznie niczym w porównaniu z językiem Java, tak Swift jest wciąż bardzo problematyczny. Swift pomimo swojej wysokiej adaptacji przez programistów wciąż nie wspiera łączenia z językiem C++, przez co pozostaje pisanie w przestarzałym objC. Dlatego w platformach firmy Apple niezbędna jest znajomość obu języków, aby móc napisać wrapper w objC, który będzie się komunikować z naszą aplikacja napisaną w języku Swift.
To koniec części pierwszej artykułu. Z następnej, którą znajdziesz pod tym adresem, dowiecie się więcej na temat narzędzi oraz bibliotek, które wykorzystałem do stworzenia gry.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
