Trzy drogi DevOps i co z nich wynika

Książka “Projekt Feniks. Powieść o IT, modelu DevOps i o tym, jak pomóc firmie w odniesieniu sukcesu” stanowi idealny łagodny wstęp do tej metodyki. Jestem przekonany, że po jej przeczytaniu czytelnik nie raz i nie dwa krzyknie “ależ ja spotkałem podobnego człowieka/sytuację!”. Definiuje ona i pokazuje w działaniu trzy główne zbiory zasad DevOps (nazywane też drogami DevOps). Dzisiaj właśnie o tych zasadach.
Pierwsza droga: Zasady przepływu, nazywane też myśleniem systemowym (ang. Systems Thinking).
Druga droga: Wzmacnianie sprzężeń zwrotnych (ang. Amplify Feedback Loops).
Trzecia droga: Kultura ciągłego uczenia się i eksperymentowania (ang. Culture of Continual Experimentation and Learning).
Zrozumienie konsekwencji tych trzech zasad oraz uświadomienie, jakie powszechnie występujące w IT problemy one rozwiązują pozwala zrozumieć przyczyny wielkiego sukcesu metodyki DevOps a w konsekwencji błyskawicznego jej rozpowszechnienia. Zanim przejdziemy do szczegółowego omówienia dróg DevOps, warto przedstawić poniższy diagram obrazujący związki pomiędzy nimi:
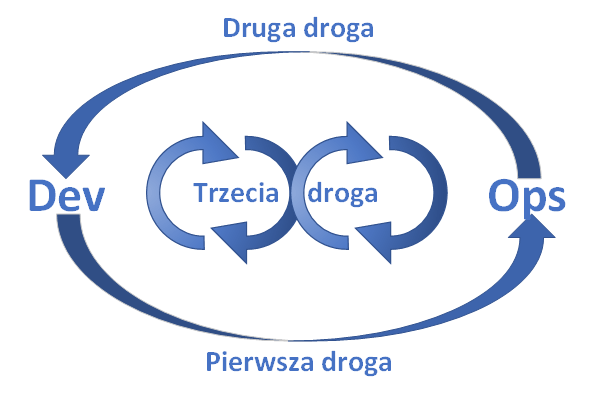
Powyższy diagram można podsumować następująco:
Pierwsza droga zaleca dbanie o sprawność przepływu efektów pracy z obszaru wytwarzania do obszaru operacji (a tym samym do klienta). Druga zaleca dbanie o efektywny przepływ informacji z obszaru operacji do obszaru wytwarzania. Trzecia droga zaleca dbanie o dwa wcześniejsze przepływy i ustawiczne wzmacnianie/poprawianie ich.
Opiszemy tu hasłowo tematy związane z trzema drogami DevOps, po więcej szczegółów odsyłając zainteresowanego czytelnika do odpowiedniej literatury, na przykład do Gene Kim, Patrick Debois, John Willis, Jez Humble, John Allspaw “DevOps. Światowej klasy zwinność, niezawodność i bezpieczeństwo w Twojej organizacji” wyd. polskie Helion 2017, tłumaczenie Radosław Meryk.
(Poprzednia część artykułu znajduje się tutaj)
Trzy drogi DevOps
Droga pierwsza, czyli przepływ
Zasady przepływu sprowadzają się do prostej rekomendacji: zalecają podjęcie działań mających na celu maksymalne skrócenie czasu od złożenia zamówienia przez klienta do wdrożenia realizującej zamówienie funkcjonalności na środowisku produkcyjnym.
I to właśnie zmiany całości procesu produkcji oprogramowania jakie należy wprowadzić w celu realizacji powyższej zasady mają bardzo daleko idące konsekwencje. Najważniejsze z tych rekomendowanych do wprowadzenia zmian to:
- Zmniejszenie rozmiarów partii realizowanych zmian.
Ta rekomendacja wynika z ducha zwinnych procesów produkcji i nie jest charakterystyczna wyłącznie dla DevOps. Jej wdrożenie jest uwarunkowane zarówno technicznie, jak i organizacyjnie, ale umożliwia znaczne uproszczenie samego procesu wytwórczego poprzez min. odejście od wielkich zespołów realizujących pojedyncze zmiany. Małe zespoły (których rozmiar określa się często jako “zespół na dwie pizze”) są zwykle sprawniejsze i wymagają mniej dodatkowej pracy związanej z koordynacją i zarządzaniem.
Dodatkową, niebanalną korzyścią z możliwości dzielenia większych zmian i realizowania ich mniejszymi partiami jest zwykle możliwość szybszego dostarczania klientowi funkcjonujących części całości zamówionej zmiany.
- Zmniejszenie interwałów pracy.
Jest to również standardowa rekomendacja metodyk zwinnych. Przyspieszenie cyklu realizacyjnego przy jednoczesnym zmniejszeniu rozmiarów realizowanej pracy, wśród wielu innych korzyści daje min. większą elastyczność w projekcie, czyli umożliwia szybsze reagowanie na nieoczekiwane sytuacje.
- Zmniejszenie ilości pracy w toku.
Dwie powyższe rekomendacje mają tę konsekwencję, że przyczyniają się do zmniejszenia ilości prac rozpoczętych, ale jeszcze nie skończonych. To również daje oszczędności związane choćby z nie generowaniem dodatkowych kosztów (a jest nimi np. praca zespołu “zamrożona” w takich nie udostępnionych klientowi zmianach).
- Spowodowanie żeby praca była widoczna.
Jest to pierwsza nieoczywista zmiana rekomendowana przez DevOps. Aby zrozumieć jej sens należy wrócić do analogii z metodyką Lean i zastanowić się, co powoduje, że widać iż na jakimś stanowisku zgromadziło się zbyt wiele pracy do wykonania. W przypadku fabryki jest to bardzo proste i wystarczy rzut oka na halę produkcyjną: przy niektórych stanowiskach zgromadzone jest po prostu dużo materiałów które służą do wykonywania pracy.
Tak rozumiana praca nie jest widoczna w przypadku technologii informatycznych. Nie da się “na pierwszy rzut oka” określić, gdzie dokładnie spiętrzają się zadania do zrobienia. Do tego potrzebny jest mechanizm monitorowania wykonywania pracy, czyli właśnie spowodowanie, że stanie się ona widoczna, czyli będzie można zawsze określić, gdzie i od kiedy aktualnie jest wykonywana.
Rekomendacja ta jest ważna jeszcze z jednego powodu. W przypadku fabryki przemieszczanie pracy między różnymi etapami jest bardzo widoczne – szczególnie gdy odbywa się to wstecz normalnego procesu produkcji. Dzieje się tak dlatego, że trzeba fizycznie przemieścić materiały między miejscami pracy. W przypadku technologii informatycznych nie ma takiego “problemu”. Przemieszczanie pracy odbywa się często za pomocą jednego “kliknięcia” – np. przepisania zadania w systemie.
Dzieje się to równie łatwo w przód, jak i wstecz procesu biegu strumienia wartości technologii. Powyższa cecha przyczynia się do powstawania znanego wszystkim informatykom zjawiska “ping-pong”, czyli cyklicznego przekazywania pracy między dwoma lub więcej wykonującymi ją jednostkami. Zjawisko to jest szczególnie powszechne a więc i uciążliwe, gdy “ping-pong” występuje między dwoma zespołami.
Najczęstszą realizacją tej rekomendacji jest wdrożenie tablic kanban. Jakie korzyści przynosi?
- Eliminowanie przestojów i opóźnień w procesie.
Rekomendacja ta jest blisko związana z poprzednią, wiąże się jednak z analizą i ewentualną modyfikacją wszystkich tych cech organizacji, które mają wpływ na powstawanie przestojów. Z najważniejszych można wymienić kilka przykładowych:
- Kwestia zlokalizowania zespołu operacji w stosunku do zespołu wytwórczego. Funkcjonowanie tych zespołów jako oddzielne działy, łączenie, lub w rozwiązaniu mieszanym ma bardzo daleko idące konsekwencje dla efektywności procesu. Temat ten jest opisany bardziej szczegółowo w jednym z kolejnych rozdziałów.
- Zmniejszenie liczby koniecznych tzw. “przełączeń kontekstu” – tak na poziomie indywidualnym, jak i organizacyjnym. [Pojęcie “zmiana kontekstu”, znane każdemu programiście oznacza konieczność zmiany tematu nad którym dana osoba/zespół pracuje. Jest to zwykle operacja bardzo kosztowna czasowo (trzeba poświęcić czas na np. zapoznanie się lub przypomnienie sobie tematu nad którym rozpoczyna się pracę) – zmniejsza się tym samym efektywność pracy.]
- Znajomość rzeczywistych czasów realizacji zadań dla poszczególnych osób/zespołów. Pozwala wykrywać te miejsca w procesie, gdzie kolejkowane są zadania, które to sytuacje mogą generować bardzo duże opóźnienia w realizacji całości prac.
Przykładowo, jeśli jakaś osoba ma zrealizować zadanie trwające zwykle 1h, a ma w kolejce już 4 takie zadania, to średni czas realizacji tego zadania wyniesie 5h, z czego zadanie spędzi 80% czasu oczekując na realizację. Praktyka priorytetyzowania zadań powoduje dodatkowo, że zadania o niskim priorytecie (zwykle to one generują dług technologiczny) mają jeszcze dłuższe czasy oczekiwania. - Dbanie o nieprzekraczanie określonego poziomu zajętości elementów procesu.
Warunek bardzo blisko związany ze wskazanym wyżej, nie dotyczy jednak wyłącznie osób i zespołów, ale również zasobów technicznych wykorzystywanych w procesie produkcji. W książce “Projekt Feniks” umieszczony został bardzo sugestywny wykres pokazujący konsekwencje stopnia zajętości zasobu (w procentach) dla czasu oczekiwania na ten zasób.
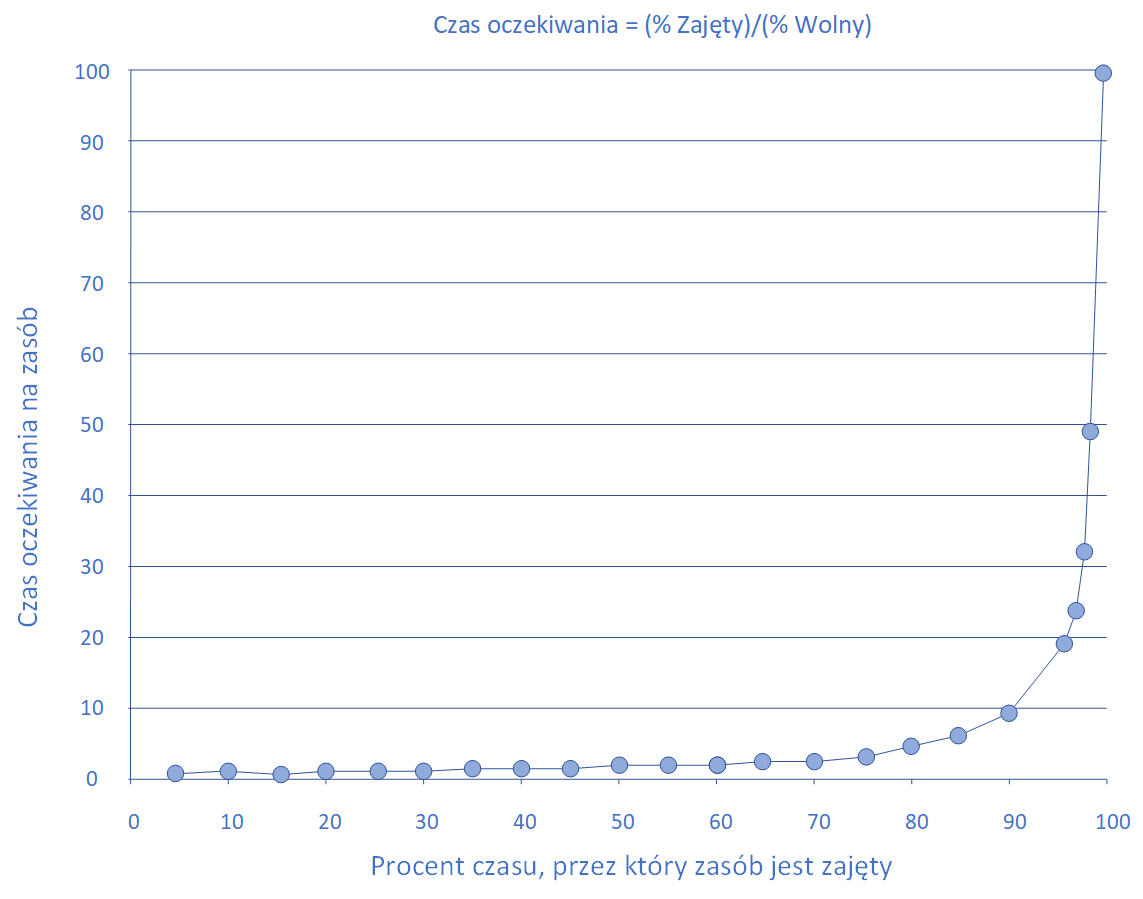
Długość kolejki lub czas oczekiwania na zasób w zależności od jego zajętości – za: Gene Kim, Kevin Behr, George Spafford „Projekt Feniks. (…)”
Wbrew intuicji, zależność ta nie jest liniowa, a wykładnicza – po szczegóły odsyłamy czytelnika do w/w książki.
- Zwracanie uwagi na sprawność procesu jako całości.
Wydawałoby się, że stwierdzenie to jest oczywiste w świetle powszechnej świadomości faktu, że organizacja realizująca zamówienie klienta jest tylko tak sprawna jak jej najmniej sprawny element. Ta rekomendacja pojawiła się między innymi dlatego, że często z pozamerytorycznych powodów proces doskonalenia organizacyjnego jest ograniczany do wybranych fragmentów całości, co nie gwarantuje pożądanych efektów.
- Zabezpieczenie funkcjonującego procesu przed nieuprawnionymi działaniami.
DevOps rekomenduje, aby przestrzeganie procedur bezpieczeństwa był wymuszane w większym stopniu poprzez odpowiednio funkcjonujące narzędzia, a w mniejszym przez ręczne procedury. Te drugie są dużo bardziej podatne na błędy ludzkie i bycie świadomie omijanymi.
Te, oraz inne nie wymienione tu, rekomendowane zmiany przekładają się na konkretne tematy techniczne, takie jak:
- Wybór architektury wspierającej odpowiednią granulację procesu realizacji zmian i ich wysoki stopień niezależności. Realizacja w metodyce DevOps projektu wytwarzania dużej monolitycznej aplikacji jest siłą rzeczy utrudniona. Najbardziej “naturalne” w opisywanej tu sytuacji są architektury rozproszone, np. oparte o mikrousługi.
- Procesy produkcji oparte na ciągłym budowaniu, ciągłej integracji, testach automatycznych.
- Procesy wydawania nowych wersji oparte na ciągłym dostarczaniu (ang. continuous delivery) lub najlepiej ciągłym wdrażaniu (ang. continuous deployment) wsparte przez automatyzację nie tylko samego procesu instalacji, ale i przygotowania infrastruktury i jej konfiguracji (tzw. “infrastruktura jako kod” i “konfiguracja jako kod” – opisane dalej).
- Mechanizmy związane ze śledzeniem realizacji poszczególnych zadań w strumieniu wartości technologii z użyciem tablic (jap. kanban).
Aspekt techniczny DevOps został omówiony szerzej w kolejnym rozdziale.
Droga druga, czyli sprzężenia zwrotne
Zasady sprzężenia zwrotnego zalecają umożliwienie stałego, szybkiego i niezakłóconego przepływu informacji wstecz kierunku strumienia wartości technologii na wszystkich jego etapach. Zasady sprzężenia zwrotnego są drugim niezbędnym składnikiem metodyki DevOps ze względu na fakt, że proces produkcji oprogramowania jest zjawiskiem niezwykle złożonym, składającym się z niezliczonej ilości indywidualnych, ale i współzależnych kroków podejmowanych przez różne osoby i zespoły.
Poza przypadkami najmniejszych projektów, zwykle też nie ma jednej osoby, która zna całość wszystkich czynności realizowanych w ramach projektu. W związku z tym błędy związane z koordynacją pracy i nieprzewidywalne konsekwencje nieuświadomionych współzależności między czynnościami są w zasadzie nie do uniknięcia. To co jest kluczowe w takiej sytuacji i to co rekomenduje DevOps, to aby wprowadzić mechanizmy umożliwiające rozwiązywanie problemów zaraz po ich wystąpieniu i gromadzić wiedzę zapobiegającą ich powtórzeniu. A do tego, aby takie działania były możliwe, potrzebna jest przede wszystkim informacja o wystąpieniu problemów – informacji tej powinny dostarczać odpowiednie narzędzia – najlepiej w pełni automatycznie. A więc zasady drugiej drogi są w dużej części realizowane przez dość powszechnie znane rozwiązania informatyczne z obszaru telemetrii.
Z konkretnych rekomendacji, na jakie przekłada się powyższe zalecenie można wymienić następujące:
- Wykorzystywanie ciągłej integracji.
Jest to pierwszy, najbardziej podstawowy mechanizm dający programistom wprowadzającym zmiany w kodzie informację zwrotną o spełnianiu przez nie najprostszych kryteriów poprawności, czyli tego, że aplikacja jako całość da się zbudować po zmianie i da się poprawnie zainstalować na środowisku integracyjnym.
Oczywiście mechanizmy ciągłej integracji powinny być w pełni automatyczne począwszy od reakcji na zmiany kodu aż po wysłanie do zainteresowanych osób raportu z zainstalowanego środowiska.
- Wykorzystywanie testowania automatycznego.
Testowanie automatyczne jest kolejnym stopniem zapewniającym wykrywanie błędów w oprogramowaniu na możliwie najwcześniejszym etapie. Jest to znany temat, więc nie będziemy się tu koncentrować się na jego opisie. Należy jednak podkreślić, że DevOps rekomenduje pełną automatyzację zarówno testów jednostkowych, jak i funkcjonalnych – najlepiej wykonywanych każdorazowo podczas procesów CI/CD (zobacz dalej).
- Stałe udostępnianie danych z monitorowania systemów.
Funkcję jaką pełni testowanie automatyczne na początku strumienia wartości technologii pełnią systemy monitoringu w jego końcowej części. Warto powtórzyć tu kilka standardowych cech takich systemów, które czynią je bardzo przydatnymi w realizacji celów stawianych przez drugą drogę:
- Udostępnianie na bieżąco danych o funkcjonowaniu systemu w rzeczywistym (nie-testowym) środowisku, czyli w produkcji. Często dodatkowo monitorowaniu podlegają wybrane środowiska testowe, takie jak środowisko do testów akceptacyjnych czy testów wydajnościowych – pozwala to zdobyć niektóre informacje zanim system znajdzie się w produkcji.
- Monitorowaniu mogą podlegać nie tylko (a nawet nie przede wszystkim) techniczne aspekty działania systemu, ale również te aspekty które mają bezpośredni przełożenie na odczucia użytkowników z jego wykorzystywania. Przykładowo, czasy odpowiedzi poszczególnych funkcjonalności.
- System może posiadać mechanizmy automatycznego wykrywania anomalii i powiadamiania o nich. Uwalnia to operatorów od ciągłego nadzorowania go i pozwala szybko powiadamiać nie tylko ich, ale i inne zainteresowane osoby. Niektóre z systemów w przypadku wykrycia anomalii automatycznie gromadzą zbiór dodatkowych (standardowo nie zbieranych) informacji o systemie w celu późniejszego ułatwienia analizy przyczyn wystąpienia anomalii, czyli tzw. migawkę systemu (ang. snapshot).
- Maksymalnie szybkie udostępnianie twórcom (programistom) informacji o efektach ich pracy w środowisku produkcyjnym.
Ostatnim z ważnych strumieni informacji pozwalających realizować założenia drugiej drogi są informacje zwrotne od użytkowników systemu. Tak jak w przypadku innych strumieni informacji zwrotnych, tak i dla zgłoszeń o błędach na produkcji DevOps rekomenduje udrażnianie i przyspieszanie ich przepływu. Oczywiście, nie oznacza to, że bezrefleksyjnie popiera bezpośrednie i niczym nieograniczone zgłaszanie błędów przez użytkowników bezpośrednio programistom. Jak zawsze, w takiej sytuacji konieczne jest odnalezienie “złotego środka”, z jednej strony zapewniające sprawność przekazywania informacji zwrotnej, a z drugiej przeciwdziałającego marnowaniu czasu wysoko wykwalifikowanych specjalistów na czynności, które mogą być wykonywane przez inny personel – i tutaj z pomocą przychodzi na przykład ITIL (zobacz).
Drugim aspektem rekomendacji DevOps w tym obszarze jest podejście do tematu rozwiązywania krytycznych problemów. Otóż DevOps rekomenduje tutaj coś, co na pierwszy rzut oka wydaje się sprzeczne z ustalonymi zwykle praktykami, czyli grupowe rozwiązywanie problemów (tzw. swarming – od angielskiego słowa oznaczającego “rój”). Zwykle uważa się, że odciąganie większej ilości osób do rozwiązania problemu nie jest dobre, bo zakłóca inne prace (np. poprzez “przełączanie kontekstu”), ale w przypadku krytycznych sytuacji DevOps uważa, że korzyści polegające z jednej strony na opanowaniu problemu zanim stanie się jeszcze bardziej krytyczny (np. dojdzie do najwyższego kierownictwa klienta), a z drugiej strony rozpowszechnianie wiedzy i gromadzenie doświadczenia jest warte poniesionych kosztów organizacyjnych. Oczywiście, przy założeniu, że takie sytuacje stanowią wyjątki od normalnego funkcjonowania systemu, a nie normę.
Wdrożenie praktyk rekomendowanych przez drugą drogę realizuje kilka celów. Ich głównym celem jest stworzenie efektywnego i odpornego na błędy (korygującego je w miarę możliwości samoczynnie i w miejscu wystąpienia) środowiska, w którym realizowany jest projekt. Zapewnia ono też budowanie wiedzy i doświadczenia w zespole wytwórczym. Dzięki szybkości otrzymywania informacji budowana jest też świadomość odpowiedzialności za efekty swojej pracy. Świadomość autora, że zmiana, którą przygotowuje znajdzie się na produkcji w ciągu kilkudziesięciu minut po tym jak podejmie decyzję, że ta zmiana jest gotowa i że w przypadku problemów ze zmianą dostanie jeszcze w tym samym dniu “wezwanie na dywanik” (określenie w przenośni – DevOps w trzeciej drodze przestrzega przed wprowadzaniem tego typu atmosfery pracy) bardzo szybko uświadamia konsekwencje własnych błędnych decyzji i motywuje do uczenia się.
Książka “Projekt Feniks. Powieść o IT, modelu DevOps i o tym, jak pomóc firmie w odniesieniu sukcesu” stanowi idealny łagodny wstęp do tej metodyki. Jestem przekonany, że po jej przeczytaniu czytelnik nie raz i nie dwa krzyknie “ależ ja spotkałem podobnego człowieka/sytuację!”. Definiuje ona i pokazuje w działaniu trzy główne zbiory zasad DevOps (nazywane też drogami DevOps). Dzisiaj właśnie o tych zasadach.
Droga trzecia, czyli uczenie się
Zasady zawarte w trzeciej drodze rekomendują stworzenie w organizacji (rozwoju i operacji) takiej kultury organizacyjnej i atmosfery która wspiera doskonalenie dwóch wcześniejszych procesów – w tym otwarte wskazywanie istniejących w nich błędów/ograniczeń. Rekomendacje zawarte w tej drodze mają najmniej techniczny charakter, a są najbardziej związane z praktyką zarządzania zespołami pracowników.
Wywodzą się one z obserwacji, że w sztywnych, zbiurokratyzowanych, czy zarządzanych “autorytarnymi” metodami strukturach zanika inwencja twórcza, pracownicy stają się obojętni na funkcjonowanie systemu jako całości i koncentrują się na pilnowaniu “własnego ogródka”. W skrajnych przypadkach takie sytuacje prowadzą do rozpowszechnienia się przekonania, że “nic ode mnie nie zależy” oraz praktyki tworzenia przy wykonywaniu każdej czynności niezbyt ładnie nazywanych tzw. “d…chronów”.
Taki stan rzeczy bardzo utrudnia skuteczne wdrożenie i funkcjonowanie DevOps w organizacji. W związku DevOps sugeruje tu wiele różnych mechanizmów mających przeciwdziałanie powyższym zjawiskom. Warto tu wymienić kilka podstawowych tematów, na które kładzie nacisk DevOps:
- Popieranie przekształcania lokalnych odkryć w globalne usprawnienia.
Organizacja powinna wspierać pracowników, którzy udoskonalili coś w swoich własnych obszarach, umożliwiając im jednocześnie rozpowszechnianie tej wiedzy i wdrażanie udoskonaleń w innych miejscach strumienia wartości technologii. Oczywiście, takie stanowisko jest popierane werbalnie przez wszystkich i zawsze, ale praktyka i sprzeczne interesy różnych grup w procesie często stoją na przeszkodzie rozpowszechnianiu się dobrych rozwiązań. Kluczowym staje się stworzenie systemu i klimatu który przeciwdziała takim blokadom bez jednoczesnego tworzenia dodatkowych konfliktów.
- Tworzenie kultury organizacyjnej która popiera uczenie się.
Poprzez uczenie się rozumiane są tutaj nie wszelkiego rodzaju szkolenia, ale uczenie się na podstawie efektów swojej codziennej pracy i swoich pomysłów – co ważne, zarówno na podstawie sukcesów, jak i porażek. Jeśli pracownicy boją się konsekwencji organizacyjnych i społecznych każdego, nawet najmniejszego niepowodzenia, zamiera jakakolwiek własna inwencja.
- Tworzenie kultury bezpieczeństwa (ang. just culture – kultura sprawiedliwego traktowania).
Rekomendacja ta sprowadza się zasadniczo do odpowiedniego typu reakcji na porażki (np. awarie systemu). Zaleca ona koncentrowanie się na poszukiwaniu metod szybkiego naprawienia problemu i zapobieganiu jego powtórzeniu zamiast poszukiwania winnych jego wystąpienia (co łatwo przeradza się w “polowanie na czarownice”).
- Wdrażanie technik badania reakcji organizacji na awarie produkcyjne.
DevOps rekomenduje tu wręcz organizowanie ćwiczeń w reakcji na symulowane awarie (tzw. technika “chaos monkey” wykorzystywana min. w Netflix).
- Zarezerwowanie czasu na prace rozwojowe i przekazywanie wiedzy. Aby realizować wszystkie wyżej wymienione działania, pracownicy potrzebują czasu. W pełni zajęci “bieżączką” pracownicy nie będą wykazywać większej inwencji, nawet jeśli stworzy im się do tego idealne warunki we wszystkich innych obszarach.
Jak widać, tematy opisywane przez trzecią drogę należą do repertuaru zarządczych technik miękkich. Wymieniono tu tylko kilka z nich, zapewne jeszcze kolejne jest w stanie wskazać każda osoba mająca doświadczenie w zarządzaniu zespołami ludzkimi.
Szczegóły, czyli na czym to technicznie polega
Czytelnik, który przebrnął przez poprzednie rozdziały mógł odnieść wrażenie, że Devops ma niewiele wspólnego z jakimikolwiek współczesnymi narzędziami wsparcia procesu produkcji. Jest to oczywiście nieprawda, natomiast prawdą jest że wdrożenie wyłącznie narzędzi, bez zmienienia sposobu działania organizacji i co najważniejsze, panującej w niej mentalności, nie przyniesie wielkiej poprawy. Naturalnie, zmiany na plus się pojawią, bo zawsze lepiej jest mieć automatyczny proces ciągłej integracji niż go nie mieć. Ale bez zidentyfikowania, gdzie leżą główne czynniki opóźniające bieg strumienia wartości technologii, znaczna część pracy i inwestycji w rozwiązania techniczne mające umożliwić wdrożenie DevOps w organizacji zapewne się zmarnuje. Samo wdrożenie DevOps w organizacji jest ogromnym tematem i nie będzie tu poruszane.
Niniejszy rozdział jest poświęcony narzędziom, które zwykle wspierają DevOps na różnych etapach procesu produkcji i funkcjonowania oprogramowania (jak to zostało powiedziane wcześniej – strumienia wartości technologii).
Niniejszy przegląd ma charakter siłą rzeczy nieco subiektywny i nie pretenduje w żadnym razie do jakiejkolwiek kompletności, choćby z powodu bardzo szybkiej ewolucji narzędzi w większości z omawianych obszarów.
Kolejne części tego rozdziału skupią się na dość hasłowo potraktowanych procesach (czytelnik może znaleźć ich opisy w większości książek z obszaru inżynierii oprogramowania) pogrupowanych zupełnie umownie w zależności od ich orientacyjnego położenia w pojedynczym przebiegu strumienia wartości technologii i o wspierających te procesy narzędziach. Należy tu jednak podkreślić, że proces DevOps jest ze swojej zasady cykliczny i najczęściej przedstawiany jest jak niżej:
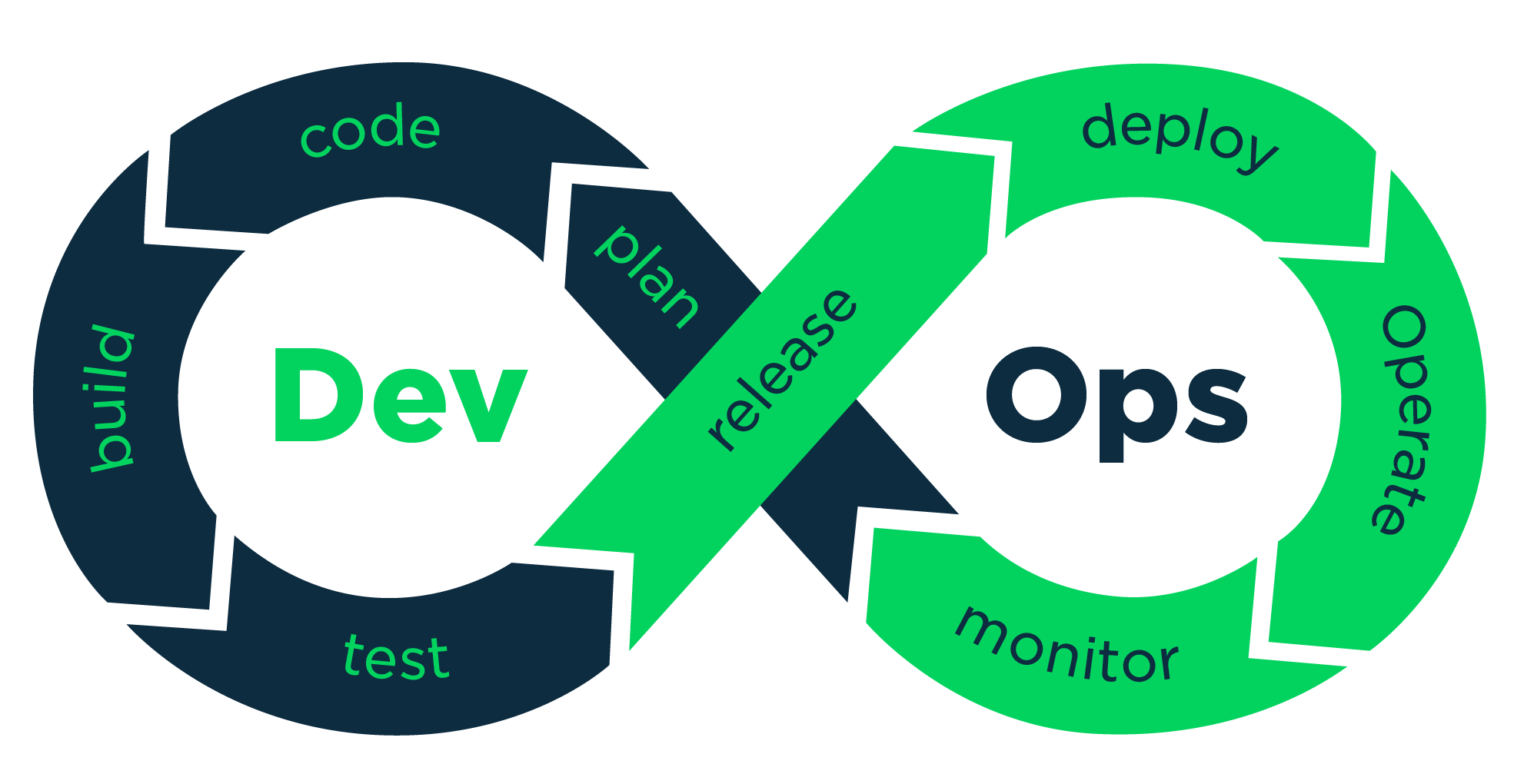
Za DevOps, źródło: Pease, Jeremy. 2017. „DevOps Part 1: It’s More Than Teams.” Contegix. June 9 (obecnie niedostępne)
Takie podejście jest w oczywisty sposób implementacją tzw. cyklu Deminga (zobacz) znanego z teorii zarządzania.
Planowanie i zarządzanie pracą
Narzędzia, które wspierają całość zarządzania pracami projektowymi (czyli planowanie, przydzielanie i monitorowanie realizacji zadań – zgodnie z zasadą: niech praca będzie widoczna! ), są w dużej części współdzielone z innymi metodykami zwinnymi. Jako takie nie są więc charakterystyczne dla DevOps.
Zdaniem autora należy tu wymienić dwa najważniejsze:
- JIRA to narzędzie wyprodukowane wiele lat temu przez firmę Atlassian służące do śledzenia zadań (z angielska: issue tracker). Choć na początku jego rozwój wydawał się nieco chaotyczny, z czasem osiągnęło ono naprawdę wielkie możliwości połączone ze znakomitą elastyczności i możliwościami zarówno integracji i innymi narzędziami, jak i rozszerzania przez mechanizm wtyczek (ang. plugins).
- ….oraz tablica korkowa z karteczkami reprezentującymi zadania. Prosta, zawsze widoczna i dostępna oraz odporna na awarie infrastruktury. W dobie telefonów komórkowych łatwa do dokumentowania – tym samym śledzenia zmian, choć słabo poddająca się automatyzacji.
Metodyka DevOps zwraca uwagę na jeden aspekt używania tablic kanban – niezależnie od tego, w jakim narzędziu są one zaimplementowane. Do listy faz na tablicy kanban należy włączyć również te powszechnie łączone z operacjami – takie jak np. wdrażanie czy konfigurowanie środowiska (oczywiście, jeśli jest to uzasadnione cechami projektu).
Początek strumienia wartości technologii
Zanim przejdziemy do bardziej szczegółowego omówienia narzędzi do wsparcia kodowania, budowania i testowania, warto zwrócić uwagę na to czego nie ma w tej części. A nie ma narzędzi wspierających jakiekolwiek prace mające miejsce przed rozpoczęciem kodowania – na przykład zbieranie wymagań klienta (przykładowo w postaci “user stories”), czy prace projektowe nad architekturą rozwiązania. Wynika to oczywiście ze specyfiki metodyki DevOps i tego na jakie elementy kładzie ona nacisk.
Kodowanie
Omawiając tematu kodowania w aspekcie metodyki DevOps warto się skoncentrować na jednym konkretnym aspekcie tej pracy. Jest nim korzystanie programisty z repozytorium kodu źródłowego (tzw. “systemu kontroli wersji” – ang. version control system, VCS). To, jakie możliwości daje narzędzie, w którym realizowane jest zarządzanie kodem źródłowym, w dużym stopniu rzutuje na to, jak sprawna i elastyczna będzie praca zespołu wykonawczego. A w szczególności, ile czasu członkowie tego zespołu będą zużywać na czynności czysto administracyjne związane z utrzymaniem spójności kodu wytwarzanego przez wiele osób.
Niekwestionowanym standardem w tym obszarze jest obecnie Git. Narzędzie to, będące rozproszonym systemem kontroli wersji (ang. distributed version control system) uzyskało w ciągu ostatniej dekady na tyle dominującą pozycję, że można zaryzykować tezę, iż w ciągu najbliższych paru lat spodziewać się należy pojawienia się pokolenia programistów znających z praktyki wyłącznie to rozwiązanie.
Zalety Git’a
Warto wymienić w tym miejscu te cechy Git’a, które wspierają postulowaną przez DevOps dbałość o sprawny przepływ strumienia wartości technologii, czyli zwyczajnie sprawne przekazywanie kodu ze stacji roboczej programisty do dalszych etapów produkcji.
Najważniejsze z tych cech to:
- Lokalny charakter Git’a – większość operacji Git wykonywane jest na stacji roboczej posiadającej własne lokalne repozytorium (stąd “rozproszoność” systemu). Dopiero gdy programista jest przekonany, że wyprodukowany kod nadaje się do upublicznienia poprzez przekazanie go do centralnego repozytorium kodu. Takie podejście w wielkim stopniu porządkuje pracę ułatwiając używanie “atomów zmian”, czyli takich ich fragmentów, które tworzą pewną całość. Jednocześnie, pracując wyłącznie na repozytorium lokalnym, programista nie traci nic z zalet mechanizmów kontroli wersji.
- Istnienie standardu struktury repozytorium – tzw. Git flow (zobacz). Ułatwia kontrolę zawartości wydawanych wersji. Zmniejsza “koszty wejścia” w projekt. Promuje standardowość rozwiązań, a więc reużywalność gotowych narzędzi.
- Tanie korzystanie z gałęzi (ang. branches). Rozwijanie zmian w gałęziach promuje “atomowość” zmian, możliwość ich równoległego wytwarzania przez wiele osób i zespołów, a w końcu kontrolę tego co ma zawierać wydawana wersja aplikacji.
- Zmniejszenie ilości problemów pojawiających się przy łączeniu kodu (ang. merging). Pozwala zaoszczędzić naprawdę wiele czasu i frustracji.
- Git umożliwia budowanie sieci repozytoriów. Struktura gwiaździsta, czyli repozytorium centralne – repozytoria lokalne nie jest jedyną możliwą! Jest to rzadko wykorzystywana możliwość dająca możliwość sprawnego zarządzania naprawdę złożonymi rozwiązaniami realizowanymi przez wiele zespołów.
Git stał się na tyle ważnym narzędziem, że powstało wiele systemów, które traktują go jako bazę do budowania rozwiązań integrujących albo wręcz obejmujących również inne elementy infrastruktury wspierającej proces wytwórczy (ang. software development toolchain). Z najpopularniejszych można tu wymienić trzy:
- GitHub – rozwiązanie chmurowe pozwalające tworzyć i zarządzać zarówno darmowymi repozytoriami jak i rozwiązaniami komercyjnymi.
- BitBucket – rozwiązanie chmurowe (możliwe również do zainstalowania w chmurach prywatnych) firmy Atlassian pozwalające nie tylko zarządzać wieloma repozytoriami Git, ale również integrować te repozytoria z wieloma zewnętrznymi narzędziami (takimi jak choćby JIRA).
- GitLab – pełna platforma wspierająca metodykę DevOps.
Oczywiście, nie ma rozwiązania bez wad i Git również je posiada. Choć oczywiście ich lista zależy w pewnym stopniu od indywidualnych preferencji. Przykładowo, Git nie ułatwia procesu przesuwania znaczników (ang. tag), a wręcz utrudnia synchronizację efektów tego procesu pomiędzy repozytoriami. Pewne osoby uważają to za wadę (można do nich zaliczyć autora), inne twierdzą że jest to uzasadnione ograniczenie.
Budowanie
Procesy budowy wchodzący w skład ciągłej integracji (ang. continuous integration – w skrócie “CI” ) rozpoczyna sekwencję działań mających miejsce już poza stacją roboczą programisty i kluczowych z punktu widzenia przemieszczanie się strumienia wartości wartości technologii do dalszych do dalszych etapów produkcji. Drugi z kluczowych składników procesu ciągłej integracji, czyli testowanie, jest opisany w kolejnym rozdziale.
Cechy, które powinien posiadać dobry proces CI:
- Powinien być w pełni automatyczny i bezobsługowy. W szczególności, musi automatycznie uruchamiać się w reakcji na zmiany w części gałęzi repozytorium przeznaczonej do integracji (zobacz. np. opis gałęzi “develop” w Git flow).
- Powinien zawierać kroki związane zarówno z budową aplikacji, jak i jej testami automatycznymi (zwykle są to testy jednostkowe).
- Powinien obejmować automatyczne instalowanie stworzonej dystrybucji aplikacji na przeznaczonym do tego środowisku. Jest to pierwszy krok potrzebny do przekształcenia ciągłej integracji w opisane dalej ciągłe dostarczanie.
- Powinien automatycznie uruchamiać generowanie wymaganych raportów (min. o jakości kodu) i przekazywanie ich do systemów dedykowanych do ich przechowywania.
- Na koniec działania powinien wybranym kanałem (zwykle email) informować zespół o sukcesie, bądź niepowodzeniu procesu – wraz z podaniem szczegółów w taki sposób który umożliwia sprawcom problemów szybkie ich naprawienie.
Dobrze funkcjonujący proces ciągłej integracji daje wiele korzyści. Z punktu widzenia metodyki DevOps najważniejszymi z nich są umożliwienie wykrywania błędów na bardzo wczesnym etapie wytwarzania, co zmniejsza koszty ich obsługi i eliminuje daleko idące konsekwencje późnego ich wykrycia.
Narzędzia, w których implementuje się proces ciągłej integracji służą też zwykle do koordynacji obsługi innych procesów związanych z budową/instalacją/konfiguracją aplikacji i środowisk. Wszystkie wymienione powyżej wymagania powodują, że narzędziom go wspierającym stawiane są bardzo duże wymagania, jeśli chodzi o możliwości integrowania systemów i ogólną elastyczność. Tego typu system, gdy jest odpowiednio skonfigurowany, służy zwykle jako swego rodzaju “punkt wejścia” dla wykonywania różnych inicjowanych automatycznie bądź ręcznie operacji wykonywanych w trakcie normalnej pracy projektowej.
Istnieje wiele komercyjnych, jak i darmowych rozwiązań tego typu: często nazywa się je “platformami CI”. Można tu wymienić choćby Bamboo (rozwiązanie firmy Atlassian) czy TeamCity (rozwiązanie firmy JetBrains). Jednak najbardziej rozpowszechnionym rozwiązaniem jest obecnie Jenkins będący oprogramowaniem open source.
Jak znaczna część platform CI, tak i Jenkins implementuje paradygmat build jako kod (ang. build as a code), który oznacza, że całość procesu ciągłej integracji (i innych procesów zaimplementowanych w narzędziu) definiuje się przygotowując odpowiedni program w jakimś języku specjalizowanym. Kategoria takich języków często oznaczana jest zbiorczo jako DSL (ang. domain specific language), w celu wyróżnienia ich od języków ogólnego przeznaczenia. Język DSL, którego używa Jenkins jest oparty o Groovy, który z kolei można określić jako “język skryptowy oparty o Java”.
Jednym z najważniejszych kryteriów użyteczności platform CI są ich możliwości integrowania różnych narzędzi – zarówno zewnętrznych w stosunku do samej platformy, jak i wykorzystywanych wewnątrz niej do pracy z określonymi językami programowania, bibliotekami czy całymi narzędziami. Zwykle tego typu rozszerzenia udostępniane są na platformie w postaci wtyczek (ang. plugin). Jenkins posiada obecnie (stan na maj 2021 roku) centralne repozytorium zawierające ponad 1800 wtyczek (zobacz Search Results | Jenkins plugin), w znacznej części tworzonych i udostępnianych liczną społeczność. W zasadzie można tam znaleźć wszystko, co jest potrzebne w standardowym projekcie realizowanym we jakiejkolwiek z rozpowszechnionych technologii.
Drugą z pożądanych cech platform są możliwości ich skalowania poziomego [skalowanie poziome to zwiększanie wydajności rozwiązania poprzez dodawanie nowych węzłów do wykorzystywanej infrastruktury. W przeciwieństwie do skalowania pionowego – czyli podnoszeniu wydajności węzłów (np. poprzez przydzielanie im dodatkowych zasobów).].
Sytuacja, gdy należy podnieść ogólną wydajność rozwiązania procesów CI i podobnych jest bardzo częsta. Kiedy? Na przykład gdy rozwiązanie rośnie. Wraz z rozrastaniem się projektu wzrastają również wymagania dot. ilości równoległych procesów budowy, czy ilości obsługiwanych środowisk. Dodatkowo, często istnieje konieczność wykorzystywania np. różnych systemów operacyjnych w różnych procesach zaimplementowanych na platformie CI.
Wszystkie rozpowszechnione platformy (w tym Jenkins) posiadają możliwość skalowania poziomego poprzez dodawanie centralnie zarządzanych węzłów. W Jenkinsie węzły mogą zostać stworzone na w zasadzie każdym rodzaju systemu operacyjnego, na którym możliwe jest uruchomienie maszyny wirtualnej Java. Oczywiście mogą być również tworzone jako kontenery. Zarówno w przypadkach kontenerów, jak i maszyn (zwykle wirtualnych) węzły Jenkins mogą funkcjonować jako rozwiązania chmurowe.
Ze względu na swój krótki cykl rozwojowy (cotygodniowe wydawanie nowych wersji), Jenkins jest rozwiązaniem podlegającym relatywnie szybkim zmianom. Ma to zarówno zalety, jak i określone konsekwencje. Najważniejszą z konsekwencji jest konieczność korzystania z kanału wersji stabilnych (aktualizowanych co około 12 tygodni i posiadających tzw. LTS – ang. long term support), jeśli wykorzystywane środowisko ma charakteryzować się wysoką niezawodnością i być wolne od błędów.
Testowanie
Szybkie i niezawodne testowanie automatyczne jest drugim z filarów procesu ciągłej integracji. DevOps kładzie szczególny nacisk na automatyzację tego procesu, bo rozwiązuje ona następujące problemy pojawiające się w przypadku manualnej realizacji testów przez przeznaczony do tego dział zapewnienia jakości (ang. quality assurance):
- Koszt wykonywania testów manualnych (liczony czasem, a zatem i pieniędzmi na nie przeznaczonymi) rośnie wraz z wielkością aplikacji. Zwykle ten wzrost nie jest liniowy, bo złożoność aplikacji mierzona ilością związków między ich elementami rośnie zwykle w sposób bardziej zbliżony do wykładniczego i często tak też rośnie rozmiar i złożoność testów.
- Z samej swojej natury testy manualne prawie nigdy nie mogą być wykonywane na tyle często, aby dostarczać informacji o jakości każdej zmiany wprowadzonej do kodu aplikacji i każdej zbudowanej przez platformę CI wersji. Zaburza to związek pomiędzy zmianami w aplikacji, a wykrytymi w niej błędami. W skrajnych przypadkach, gdy dla bardzo dużej aplikacji testy trwają wiele dni, zależność ta jest prawie zupełnie tracona. Powoduje to konieczność każdorazowego przeprowadzania “śledztwa” dotyczącego konkretnej przyczyny błędu. W przypadkach gdy trudno jednoznacznie wskazać zmiany, które są przyczyną błędu, może dochodzić np. do opisanego już wcześniej zjawiska “ping-ponga”. W sytuacji rzadko wykonywanych testów manualnych nie bez znaczenia jest również fakt, że poprzez swoją długotrwałość opóźniają przekazywanie programistom informacji zwrotnej o jakości ich kodu, tym samym spowalniając proces uczenia się na błędach.
- Oczywistą wadą testów manualnych jest również ich mniejsza wiarygodność niż testów automatycznych. Mimo zastosowania wielu narzędzi wspomagających (choćby sformalizowanych scenariuszy testowych), z samej swojej natury czynności manualne są bardziej podatne na pomyłki niż czynności wykonywane przez automat.
Istnieje wiele kryteriów podziału testów, natomiast z punktu widzenia rekomendacji dawanych przez metodykę DevOps należy rozważyć ich dwie charakterystyczne grupy: testy jednostkowe i testy funkcjonalne.
- Testy jednostkowe – tworzone przez programistów w celu testowania pojedynczych metod, funkcji, czy całych klas. W większości sytuacji są bezstanowe – celem jest sprawdzanie, że testowany przez nie fagment kodu działa poprawnie. Jednym z celów realizacji procesu ciągłej integracji jest to, żeby wykonywanie testów jednostkowych i raportowanie ich wyników było procesem automatycznym i związanym z konkretnymi zmianami.
Bardzo ważną wskaźnikiem pokazującym jakość tworzonego kodu jest miara stopnia pokrycia kodu testami jednostkowymi. Zwykle wyliczana dla metod, klas czy nawet rozgałęzień w kodzie i później jako obliczona wg. określonego algorytmu wartość podawana później w procentach. Często stosowaną metodą zapewnienia jakości jest stosowanie określonego minimalnego stopnia pokrycia nowo tworzonego kodu testami jednostkowymi. Nierzadką praktyką jest nawet uniemożliwienie programistom włączania (ang. merging) zmian do gałęzi integracyjnej kodu w sytuacji, gdy wskaźnik pokrycia nowego kodu testami nie przekracza pewnej minimalnej wartości.
- Testy funkcjonalne – sprawdzanie aplikacji na poziomie udostępnianego przez nią interfejsu. Oczywiście mogą być zarówno manualne (nazywane powszechnie “klikaniem w aplikację”) albo automatycznie z użyciem specjalizowanych narzędzi. Idealnym rozwiązaniem przybliżającym projekt do rekomendowanych przez DevOps praktyk jest wykonywanie automatycznych testów funkcjonalnych każdorazowo w ramach działania procesu ciągłego dostarczania (po zainstalowaniu aplikacji na dedykowanym środowisku). Taki cel jest jednak często trudny do osiągnięcia ze względu na dwa czynniki:
- Wysoki koszt związany z utrzymywaniem aktualności testów funkcjonalnych w stosunku do wytwarzanej aplikacji.
- Czas wykonania takich testów – mierzony nawet w godzinach.
W praktyce w przypadku automatycznych testów funkcjonalnych często stosuje się dwa pośrednie rozwiązania: pierwsze to okresowe, niezależne od ciągłej integracji uruchamianie tych testów (np. w nocy). Drugie to manualne uruchomienie testów na wybranym środowisku z zainstalowanymi konkretną wersją aplikacji w celu np. przeprowadzania jej testów regresyjnych.
Funkcjonują również inne kryteria podziału testów – np. na cel ich przeprowadzania. Pojawiają się wtedy takie typy testów jak: testy regresyjne, testy wydajnościowe, czy testy wymagań niefunkcjonalnych. Omówienie tych tematów w kontekście DevOps dalece wykracza poza zakres tego artykułu.
Istnieje mnóstwo różnych narzędzi wspierających wykonywanie testów i gromadzenie oraz udostępnianie ich rezultatów. Wybór narzędzia zależy głównie od tego jaki typ aplikacji podlega testom i jaki rodzaj testów jest wykonywany. Z narzędzi dla testów funkcjonalnych aplikacji pracujących w oparciu o przeglądarki warto tutaj wymienić bardzo popularne Selenium – darmowe rozwiązanie pozwalające zarówno rejestrować ręcznie wykonywane czynności w celu późniejszego automatycznego ich odtwarzania, jak i tworzyć scenariusze testów w postaci kodu. Innym wartym wspomnienia narzędziem jest SonarQube – przedstawiciel narzędzi do wyliczania, gromadzenia i prezentowania danych o jakości kodu.
Dane o wszelkiego rodzaju testach (np. ich wyniki i związki z tworzonym kodem) są dla takich narzędzi jednym z ważnych typów danych na podstawie których określana jest ta jakość.
Środek strumienia wartości technologii
Umowny środek strumienia wartości technologii wiąże się z przygotowaniem dwóch kluczowych produktów projektu jakimi są zwykle wersja produkowanej aplikacji oraz środowisko w jaki ma ona działać.
Pakowanie i wydawanie nowych wersji
Dwa wymienione w tytule procesy są często łączone ze względu na ich bliski związek – drugi nie istnieje bez pierwszego, ale w praktyce zdarza się również, że pierwszy zawsze pociąga za sobą drugi. Przez “pakowanie” rozumiemy tutaj przygotowanie nowej dystrybucji aplikacji i umieszczenie jej w miejscu wybranym do jej przechowywania – tzw. repozytorium artefaktów (ang. artifact repository). Taka operacja nie zawsze wiąże się z procesem przygotowania nowej wersji (ang. release process), bo zdarza się że np. proces ciągłej integracji nie generuje nowych wersji aplikacji a jedynie umieszcza zbudowany artefakt w repozytorium – np. w strumieniu zmian pod znacznikiem ‘LATEST’ albo ‘SNAPSHOT’.
Równie często praktykowane jest, że proces ciągłej integracji wcale nie produkuje jakiejkolwiek dystrybucji aplikacji przeznaczonej do przechowywania – w takich sytuacjach procesy pakowania i wydawania nowych wersji stanowią jedną całość.
Systemy repozytoriów artefaktów wspierające proces pakowania i udostępniania dystrybucji binarnych aplikacji (lub kontenerów je zawierających) są o tyle ważne dla całości działań w ramach DevOps, że dane w nich zawarte stanowią nie tylko źródło różnych wersji aplikacji w postaciach gotowych do użycia (lub wręcz archiwum wersji użytych, gdy dla danego artefaktu nastąpił również proces wydania nowej wersji) ale również źródło informacji o sposobie powstania tych wersji i miejscach ich wykorzystania. Dzieje się tak dzięki metadanym przechowywanych łącznie każdym artefaktem. Dzięki temu repozytoria artefaktów są cennym elementem wspierającym działania w ramach drugiej drogi DevOps.
Repozytoria artefaktów mogą funkcjonować zarówno jako samodzielne oprogramowanie takie jak np. JFrog Artifactory, ale są również częściami rozwiązań kontenerowych i orkiestacyjnych takich jak Docker i Kubernetes, czy wręcz PaaS – jak OpenShift.
Wydawanie nowych wersji jest natomiast częścią większego procesu – jest nim zarządzanie zmianą. Z punktu widzenia technicznego, jego podstawą jest zwykle albo wykorzystanie binarnej dystrybucji aplikacji już istniejącej w repozytorium artefaktów, albo przygotowanie nowego przeprowadzając na potrzeby tego wydania wszystkie wcześniejsze procesy począwszy od budowy.
Z drugiej strony, sam proces wydania nowej wersji nie jest ostatnim etapem procesu zarządzania zmianą (nawet w wąskim, “technicznym” znaczeniu tego terminu). W przypadku spełnienia zdefiniowanych kryteriów jakościowych i po podjęciu takiej decyzji, wersja podlega zwykle procesowi instalacji na środowisku wykonawczym – który to proces jest opisany dalej.
W związku z rozległością tematu i jego silną zależnością od technologii i specyfiki organizacji, omówione zostaną tylko ogólne zasady podejścia do tematu rekomendowane przez DevOps.
Książka “Projekt Feniks. Powieść o IT, modelu DevOps i o tym, jak pomóc firmie w odniesieniu sukcesu” stanowi idealny łagodny wstęp do tej metodyki. Jestem przekonany, że po jej przeczytaniu czytelnik nie raz i nie dwa krzyknie “ależ ja spotkałem podobnego człowieka/sytuację!”. Definiuje ona i pokazuje w działaniu trzy główne zbiory zasad DevOps (nazywane też drogami DevOps). Dzisiaj właśnie o tych zasadach.
Charakterystyczną cechą procesu wydawania nowych wersji aplikacji jest nie tylko relatywnie duży odsetek zawartych w nim ręcznych działań, ale również trudność w całkowitym ich wyeliminowaniu. Operacje manualne często trudno wyeliminować całkowicie, gdyż nawet w dalece zautomatyzowanych procesach wydawania nowych wersji potrzebny jest krok decyzyjny. Zwykle ostateczną decyzję o tym, czy uruchomić wydawanie nowej wersji pozostawia się człowiekowi – często jest to osoba dedykowana zarządzaniu procesem zmian (ang. Change Manager) lub wręcz zarządzająca procesem wydawania nowych wersji (ang. Release Manager).
Szczególnie w dużych projektach zdarza się, że osoby pełniące w/w role nie są specjalistami technicznymi, a raczej koordynatorami pewnych obszarów np. pełnią jednocześnie rolę właścicieli produktu (ang. product owner) wg. metodyki Agile. W takich sytuacjach ważne jest aby maksymalnie usprawnić podejmowanie takiej decyzji, np. poprzez zgromadzenie w jednym miejscu wszystkich niezbędnych informacji i zautomatyzowanie wszystkich czynności wykonywanych po podjęciu takiej decyzji. Idealną sytuacją jest udostępnienie np. w ramach Jenkins albo JIRA jednego przycisku o nazwie “utwórz nową wersję” którego kliknięcie przez uprawnioną osobę uruchamia całość procesu i automatycznie realizuje wszystkie potrzebne czynności.
Specjaliści DevOps zwracają jednak uwagę, że istnieją tzw. “wydania niskiego ryzyka”. Zwykle są to bardzo proste zmiany, które realizacja powinna skutkować w pełni zautomatyzowanym powstawaniem i wdrożeniem nowych wersji aplikacji. Przykładowo, zgłoszone błędy produkcyjne muszą przejść przez sekwencję testów (najlepiej automatycznych, choć jest to bardzo utrudnione ze względu na różnorodność zgłoszeń błędów) i po ich pozytywnym przejściu najczęściej nie jest potrzebna indywidualna decyzja o powstaniu nowej wersji aplikacji. Taka operacja może więc zostać w pełni zautomatyzowana łącznie z podjęciem decyzji o wydaniu nowej wersji – za podjęcie takiej decyzji uznaje się w takiej sytuacji np. umieszczenie przez programistę kodu w odpowiednim repozytorium i zaznaczenie w odpowiednim systemie informacji o rozwiązaniu zgłoszonego błędu.
W sytuacji potwierdzenia jakości dostarczonego rozwiązania przez następujące po po tych operacjach testy (których przygotowanie może być np. obowiązkowo realizowaną częścią rozwiązania błędu), pozostałe czynności mogą wykonać już procesy automatyczne. Takie podejście wydatnie wspierają współcześnie stosowane technologie takie jak konteneryzacja i architektura oparta na mikrousługi. Jest ono także pierwszym krokiem do pełnego uruchomienia opisanego dalej procesu ciągłego wdrażania.
Spis treści
Konfigurowanie środowisk
Każdy specjalista operacji IT wie, że czasami środowisko łatwiej zbudować od zera, niż je naprawić. Zwykle jest też tak, że im bardziej skomplikowane jest środowisko, tym są większe szanse (albo ryzyko) wystąpienia takiej sytuacji. Dodatkowo, w czasach rozpowszechnienia wirtualizacji i konteneryzacji, punkty wyjścia do budowy środowiska są zwykle bardzo dobrze zdefiniowane i możliwe do szybkiego odtworzenia. Dlaczego więc nie zautomatyzować w pełni procesu przygotowania środowiska i nie zaakceptować, że w przypadku potrzeby wykonania w środowisku JAKIEJKOLWIEK zmiany jest ono budowane od zera?
Tak hasłowo można przedstawić rozumowanie stojące za koncepcją “infrastruktura jako kod” (ang. infrastructure as a code – IaC). Drugą blisko związaną koncepcją opierającą się na analogicznych założeniach jest też “konfiguracja jako kod” (ang. configuration as a code – CaC), która jest omawiana w jednym z dalszych rozdziałów. Granica między tymi dwoma koncepcjami jest w dużym stopniu umowna i można ją różnie przeprowadzić.
Po pierwsze, można to zrobić w taki sposób, że za konfigurację uznaje się wszystkie zmiany w środowisku wymagane wyłącznie przez produkowaną aplikację do jej poprawnego działania. Natomiast infrastruktura to wszystkie wcześniejsze, zwykle dość standardowe operacje instalacyjno-konfiguracyjne. Podział na takie dwa obszary ma najczęściej sens, ponieważ cechują się one różną zmiennością. Infrastruktura jest dużo bardziej stabilna i niezależna od środowiska aplikacyjnego, więc opłacalne jest wydzielanie jej i osobne kontrolowanie jej zmian. Dzieje się tak również dlatego, że w niektórych sytuacjach zmiany w infrastrukturze pociągają za sobą np. konsekwencje formalne związane z np. licencjami za używane oprogramowanie.
Drugim sposobem przeprowadzania tego rozgraniczenia jest np. podział na kod, który tworzy infrastrukturę (np. w chmurze) i kod, który wyłącznie zmienia jej konfigurację (np. poprzez zmianę parametrów środowiska).
W dalszej części tego artykułu używane jest to pierwsze rozróżnienie IaC i CaC.
Spośród zalet koncepcji IaC warto wymienić trzy, które szczególnie wspierają optymalizowanie przepływu strumienia wartości technologii, a tym samym wpisują się w metodykę DevOps:
- Szybkość – wykonanie operacji w pełni automatycznie jest zawsze szybsze niż wykonanie tej samej operacji ręcznie. Zatem dostarczenie środowiska trwa krócej, co samo w sobie jest już wartością z punktu widzenia DevOps.
- Ryzyko – operacje automatyczne w przeciwieństwie do manualnych nie są podatne na zwykłe pomyłki. W obu przypadkach mogą wystąpić błędy, ale ze względu na kolejną cechę (powtarzalność) – dużo łatwiej eliminować je z kodu.
Utrzymywanie kodu w narzędziu IaC zmniejsza też ryzyka związane z aktualnością dokumentacji, czy transferem i ewentualną utratą wiedzy przez organizację.
Kod ten stanowi także niebagatelne źródło informacji zwrotnych o środowiskach dostępne dla programistów, pełniąc tym samym ważną funkcję w realizacji celów drugiej drogi DevOps.
- Powtarzalność – pozwala eliminować błędy z kodu stosując podejście iteracyjne. Zwykle też operacje definiowane przez narzędzia IaC są też idempotentne, co dodatkowo ułatwia rozwiązywanie problemów nawet w częściowo zbudowanym środowisku (powtórzenie już wykonanej operacji nie wprowadza błędów).
Spora część narzędzi stosuje deklaratywne podejście do definiowania infrastruktury, tym samym prawie całkowicie zwalniając użytkownika z myślenia o konkretnych operacjach jakie dla danego środowiska trzeba wykonać – jest to określane przez samo narzędzie na podstawie zdefiniowanego pożądanego stanu docelowego.
Oczywiście, powyższe zalety przekładają się na zmniejszenie kosztów operacji IT, co ma niebagatelny koszty procesu produkcji jako całości.
Ze względu na ważność koncepcji IaC dla funkcjonowania DevOps jako całości, narzędzia te są jednymi z kluczowych elementów łańcucha narzędzi wykorzystywanych przez DevOps (ang. DevOps toolchain). Prawdopodobnie dlatego istnieje na rynku tak wiele narzędzi opartych o tę koncepcję. Najczęściej też trudno rozdzielić ich funkcjonalności wspierające IaC od tych wspierających CaC (ang. configuration as a code). Z najpopularniejszych warto wymienić tutaj:
- Ansible – rozwiązanie będące własnością firmy RedHat posiadające również wersję Community. Rozwiązanie bezagentowe, oparte o podejście deklaratywne i wykorzystujące pliki YAML do definicji infrastruktury. Rozszerzenia funkcjonalności realizowane przez moduły mogą być tworzone w wielu różnych językach programowania. Posiada centralne repozytorium gotowych rozwiązań (modułów, ról) – tzw. Ansible Galaxy.
- Chef – kompleksowe, składające się ze specjalizowanych modułów rozwiązanie firmy Progress do automatyzacji i zarządzania konfiguracją. Posiada warianty oparte o licencję Apache 2.0. Rozwiązanie typu klient/serwer bądź bezagentowe, oparte o podejście deklaratywne i Ruby.
- Puppet – rozwiązanie stworzone przez firmę o tej samej dostępne w wersji open source jak i komercyjnie. Rozwiązanie oparte o podejście deklaratywne. Centralnym narzędziem używanym do definiowania infrastruktury są tu moduły – będące typowym przykładem dedykowanego DSL.
- Terraform – rozwiązanie firmy HashiCorp koncentrujące się na współpracy z usługami chmurowymi. Posiada zarówno wersję open source jak i płatną Enterprise. Umożliwia korzystanie z API dostawców chmurowych z pomocą deklaratywnego DSL. Rozszerzalne za pomocą modułów będących mieszaniną DSL i plików JSON. Posiada centralne repozytorium gotowych modułów nazywane “Terraform registry”.
Wszystkie w/w narzędzia współpracują z najpowszechniejszymi systemami operacyjnymi, systemami konteneryzacji i orkiestratorami kontenerów, narzędziami do wirtualizacji – zarówno wewnątrz infrastruktury korporacyjnej jak i w chmurach publicznych.
Powyższe pozycje w żaden sposób nie wyczerpują listy dostępnych rozwiązań – wybór konkretnego z nich jest oczywiście ważny i ma najczęściej daleko idące konsekwencje, tym niemniej największą zmianą jakościową w operacjach IT jest samo zastosowanie koncepcji IaC w praktyce.
Końcowa część strumienia wartości technologii
Umownym końcem przebiegu strumienia wartości technologii dla konkretnej partii pracy jest udostępnienie klientowi wywożonej wersji aplikacji oraz gromadzenie danych o jej funkcjonowaniu. Umowność zaklasyfikowania tych operacji do części końcowej polega min. na tym że zgodnie z rekomendacjami DevOps te same czynności związane z instalacją, konfigurowaniem i monitorowaniem aplikacji są wykonywane nie tylko na środowiskach produkcyjnych, ale również na testowych. Poza tym strumień wartości technologii jest procesem ciągłym – różne partie pracy znajdują się jednocześnie na jego różnych etapach.
Instalowanie i konfigurowanie aplikacji
Wzajemny związek między instalowaniem i konfigurowaniem aplikacji a pozostałymi elementami procesu dostarczania infrastruktury (ang. infrastructure provisioning) opisanego w jednym z poprzednich rozdziałów jest bardzo zależny od używanych technologii. W przeszłości te dwie aktywności były dość ściśle rozgraniczone – po zainstalowaniu i skonfigurowaniu infrastruktury systemowej pozostawała ona w dużym stopniu niezmienna (zwykle z dokładnością do aktualizacji oprogramowania standardowego), często też dostęp do niej był kontrolowany przez działy funkcjonujące poza strukturą projektową – typową administrację IT. Obecnie, głównie ze względu na konteneryzację rozwiązań, rozróżnienie między tym co jest dostarczaniem a co konfigurowaniem infrastruktury dla aplikacji straciło swój jednoznaczny charakter.
Jednak wciąż istnieje kilka koncepcji charakterystycznych dla prac instalacyjno-konfiguracyjnych opisywanych w tym rozdziale, szczególnie w kontekście metodyki DevOps. Wymagają one opisania i są nimi:
- Pojęcie ciągłego dostarczania (ang. continuous delivery) zwykle definiuje się jako utrzymywanie w określonej gałęzi repozytorium kodu cały czas gotowego do wdrożenia. Dzieje się to poprzez automatyczne instalowanie i testowanie rozwiązania na przeznaczonym do tego środowisku i natychmiastowe dostarczanie autorowi zmiany informacji zwrotnej pozwalającej skorygować ewentualne błędy. Pojęcie jest rozszerzeniem procesu ciągłej integracji w kierunku większego stopnia automatyzacji
- Pojęcie ciągłego wdrażania (ang. continuous deployment) oprócz czynności opisanych w punkcie wyżej obejmuje również automatyzację procesu wdrażania na produkcję (opis procesów – zobacz).
Procesy ciągłej dostarczania i wdrażania oznacza się zbiorczo skrótem “CD” – od pierwszych znaków ich nazw.
- Narzędzia dedykowane dla procesów CD. Jak w wielu opisanych już tu przypadkach, do realizacji procesów CD mogą służyć różnorakie narzędzia. Można je podzielić na kilka klas takich jak:
- Narzędzia dedykowane do zarządzania konfiguracją i stosujące podejście “konfiguracja jako kod”. Wiele z narzędzi opisanych w rozdziale o instalowaniu środowisk ma moduły dedykowane do wykonywania operacji wdrażania. Przykładem jest Chef który posiada moduł “Chef App Delivery”.
- Narzędzia takie jak Jenkins posiadają odpowiednie wtyczki zarówno do wdrażania jak i konfigurowania aplikacji.
- Dedykowane narzędzia do wdrażania takie jak Octopus Deploy czy Digital.ai Deploy.
- Wdrażanie i konfigurowanie aplikacji może być zaimplementowane z użyciem jednego ze standardowych DSL (takiego jak choćby PowerShell). Wszystko oczywiście zależy od uwarunkowań technicznych i organizacyjnych.
- W związku z tym, że parametry konfiguracyjne wytwarzanej aplikacji definiują zwykle programiści, a narzędziami do IaC lub CaC dysponują najczęściej osoby zajmujące się operacjami, często opłacalne jest używanie scentralizowanego systemu dostarczającego konfigurację na potrzeby samej aplikacji. Taki system pozwala na:
- Pobieranie przez aplikację aktualnej konfiguracji aplikacji w czasie rzeczywistym. Dzięki temu nie ma potrzeby wydawania nowej wersji tylko po to aby zmienić globalnie lub lokalnie wartości wybranych parametrów konfiguracyjnych.
- Przechowywanie danych konfiguracji w standardowych narzędziach i standardowej formie, np. plików JSON w repozytorium kodu, czyli w Git. Takie podejście automatycznie zapewnia śledzenie zmian w konfiguracji aplikacji.
- Umożliwienie łatwego modyfikowania konfiguracji przez zespoły deweloperskie. W tym również na produkcji – pod warunkiem posiadania odpowiednich uprawnień w systemie kontroli wersji.
Narzędzia dostarczające takiej funkcjonalności są bliskie koncepcji “konfiguracja jako kod” – mowa tu o dedykowanej konfiguracji i danych o charakterze dość bliskim deklaratywnym DSL. Siłą rzeczy, takie narzędzia są ściśle związane technologią, w jakiej wykonana jest aplikacja. Przykładowo, dla aplikacji stworzonych w Spring istnieje Spring Cloud Config.
Czynności związane z instalowaniem aplikacji oraz zmianami konfiguracji są znaczącą częścią prac operacyjnych, zatem dobry wybór narzędzi wspierającym może dać duże korzyści dla sprawnego przepływu strumienia wartości technologii – tak jak definiuje to DevOps.
Monitorowanie
Kolejną znaczącą częścią prac operacyjnych jest monitorowanie działania systemów. Mowa to nie tylko o monitorowaniu działania systemu produkcyjnego, ale również środowisk testowych oraz wszystkich innych elementów infrastruktury które są oceniane jako krytyczne dla sprawnego funkcjonowania procesu produkcji (a więc np. systemów do ciągłej integracji).
Monitorowanie systemów dostarcza danych telemetrii, które są jednym z najważniejszych elementów poprawnego funkcjonowania zasad drugiej drogi DevOps – dzięki nim programiści posiadają aktualną informację o zachowaniu produkowanej przez siebie aplikacji albo w warunkach “laboratoryjnych” (jakimi są środowiska testowe) albo w warunkach rzeczywistych.
Użyteczne systemy dostarczające zespołowi wytwórczemu informacji zwrotnej o działaniu produktu posiadają zwykle co najmniej następujące cechy, po części omówione już w poprzednich rozdziałach:
- Scentralizowanie dostępu do danych z monitorowania/analizy.
- Gromadzenie danych o technicznym, ale i funkcjonalnym działaniu aplikacji.
- Agregowanie i kontekstowe łączenie danych z różnych elementów monitorowanego systemu. Możliwość korzystania z danych z systemów zewnętrznych.
- Możliwość eksportu danych do systemów zewnętrznych (np. kontroli wersji czy obsługi zdarzeń).
- Wyliczanie syntetycznych statystyk.
- Powiadamianie rutynowe oraz o anomaliach.
- Narzędzia analityczne.
Istnieje duża ilość narzędzi do monitorowania systemów – zarówno w formie samodzielnych rozwiązań, ale również jako części pakietów o szerszym zastosowaniu. Warto tu zwrócić uwagę na dwie nieco różne grupy produktów wspierających dostarczanie informacji zwrotnej postulowane przez drugą drogę DevOps.
- Klasyczne systemy monitorowania oparte o zasady zdefiniowane w APM (ang. application performance management – zobacz). Systemy koncentrują się na gromadzeniu różnego rodzaju metryk w postaci numerycznej. Analiza logów (o ile jest dostępna) pełni rolę drugorzędną. Warto tu wymienić dwa o zdecydowanie różnym charakterze:
- AppDynamics – kompleksowe komercyjne rozwiązanie oferujące możliwość monitorowania wszystkich warstw systemów (łącznie z monitorowaniem wydajności aplikacji na stacji użytkownika końcowego czy rozwiązań dla systemów mobilnych) będące własnością firmy Cisco. Realizuje wszystkie postulaty zdefiniowane w APM. Ważną możliwością dawaną przez narzędzie jest możliwość definiowania transakcji w monitorowanych aplikacjach i analizowania wpływu działania wszystkich warstw systemu na wydajność tak zdefiniowanych transakcji.
- Zabbix – otwartoźródłowe rozwiązania dostarczane przez firmę o tej samej nazwie. Umożliwia realizację wszystkich postulatów zdefiniowanych przez APM poprzez odpowiedni dobór wtyczek. Wspiera monitorowanie stacji końcowych użytkowników a także monitorowanie z użyciem i bez użycia agentów. Narzędzie cechują szerokie możliwości współpracy z systemami zewnętrznymi.
- Systemy monitorowania połączone z mechanizmami archiwizowania i analizy logów. Nie są systemami monitorowania wydajności w klasycznym tego słowa znaczeniu, ponieważ dużą rolę pełni w nich element przetwarzania surowych danych. Dzięki szerokim możliwościom analizy i agregacji danych o różnych typach (nie tylko numerycznych) pełnią ważną rolę w dostarczaniu informacji zwrotnej. Pozwalają programistom analizować dane z logów nad których wytworzeniem mają oni bezpośrednią kontrolę poprzez umieszczenie odpowiednich rozkazów w kodzie aplikacji. W połączeniu z możliwością przełączania poziomu szczegółowości logowania zdarzeń podczas działania systemu (dawaną np. przez wspomniane wcześniej narzędzia do dostarczania konfiguracji w trybie runtime), narzędzia te są bardzo efektywnym wsparciem przy rozwiązywaniu problemów. Dwa popularne to:
- Elastic stack – zestaw narzędzi w skład którego wchodzą przede wszystkim Elasticsearch – specjalizowany system do gromadzenia, wyszukiwania i analizowania danych oraz Kibana – konfigurowalny interfejs graficzny przeznaczony do wizualizacji danych. Najczęściej używany do analizy logów łącznie z komponentem Logstash przeznaczonym do pobierania i konwersji danych. Rozwiązanie Elastic stack może służyć nie tylko do gromadzenia i analizy logów, ale również danych z innych źródeł – poprzez system wtyczek.
- Splunk – narzędzie do analizy logów występujące w trzech wersjach: Enterprise, Cloud oraz darmowej Light (o mniejszych możliwościach). Wyposażone w pełny graficzny interfejs użytkownika z szerokimi możliwościami raportowania, tworzenia wykresów, alertów itp. Umożliwia włączenie mechanizmów sztucznej inteligencji do procesu analizy logów.
Monitorowanie systemów może też być częścią proaktywnego podejścia do usprawnienia procesu rozwiązywania problemów, które to podejście rekomenduje DevOps (np. wspomniana już technika chaos monkey). Proaktywność opiera się na symulowaniu awarii i przeprowadzaniu ćwiczeń w ich rozwiązywaniu. Dzięki takiemu podejściu zespoły doskonalą swoje umiejętności analityczne ale także weryfikowana jest przydatność danych zawartych w systemach monitorowania oraz zaimplementowane w nich mechanizmy.
Książka “Projekt Feniks. Powieść o IT, modelu DevOps i o tym, jak pomóc firmie w odniesieniu sukcesu” stanowi idealny łagodny wstęp do tej metodyki. Jestem przekonany, że po jej przeczytaniu czytelnik nie raz i nie dwa krzyknie “ależ ja spotkałem podobnego człowieka/sytuację!”. Definiuje ona i pokazuje w działaniu trzy główne zbiory zasad DevOps (nazywane też drogami DevOps). Dzisiaj właśnie o tych zasadach.
Różnice perspektyw, czyli jak patrzy się na to samo z różnych stron
DevOps jest metodyką (czasami zamiast tego słowa używane jest określenie “zbiór praktyk” lub nawet “zbiór najlepszych praktyk”) możliwą do zastosowania w projektach o bardzo różnej skali. Od najmniejszych, kilkuosobowych do projektów dużej skali (również tych realizowanych z wykorzystaniem podwykonawców). Najczęściej, niezależnie od skali projektu DevOps wykorzystuje się łącznie z jedną z metodyk zwinnych – te narzędzia do zarządzania pracami projektowymi mają dużo wspólnych elementów, a w obszarach rozłącznych dobrze się wzajemnie uzupełniają. Niniejszy rozdział przedstawia w bardzo dużym skrócie właśnie tematy związane z funkcjonowaniem DevOps w organizacjach o różnej skali oraz różnych strukturach.
Podobne artykuły

Na czym polega praca z DevOps? Wywiad z Aleksandrem Czarnołęskim i Michałem Piotrowiczem

Za duży popyt, za mała podaż, czyli dlaczego na rynku brakuje DevOpsów?

Kim jest DevOps Engineer i jak nim zostać?
