Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Ogrom danych tekstowych to zmora niejednej organizacji. Setki komentarzy, opinii i artykułów zalewają bazy danych firm i pomimo podejrzenia, że mogą z nich płynąć cenne informacje biznesowe, dane tekstowe są często pomijane w procesach decyzyjnych. Nierzadko okazuje się jednak, że wiedza ukryta w tym pozornie nieprzystępnym źródle danych jest bezcenna! W tym miejscu nasuwa się pytanie… czy jesteśmy w stanie wnioskować z tekstu w szybki i bezbolesny sposób?
W odróżnieniu od np. wskaźników finansowych, gdzie wartości liczbowe są bezpośrednio interpretowalne, nieustrukturyzowany format danych tekstowych nie pozwala na prostą i szybką analizę. Jeżeli jednak razem z takimi danymi zbieramy przydatne metryki, jak np. ilość gwiazdek przy recenzji produktu, to możemy próbować automatyzować proces wyszukiwania pozytywnych i negatywnych cech naszego produktu. Moglibyśmy to osiągnąć poprzez analizę sentymentu wobec wykrytych w tekście jednostek – takich jak ekran telefonu czy interfejs głośnika.
Najczęściej mamy jednak do czynienia z tekstem pozbawionym jakichkolwiek etykiet – przykładem takich danych są konwersacje z klientami. W takiej sytuacji możemy ręcznie je analizować lub stworzyć zestaw heurystycznych algorytmów opartych o wyrażenia regularne wykrywające określone, arbitralnie, kategorie. Jest to niestety związane ze znacznym wydłużeniem czasu analizy i ciężką, ręczną pracą analityka. Na szczęście mamy dostępny zestaw metod znacznie ułatwiający ten proces!
Spis treści
Reprezentacja tekstu w przestrzeni wielowymiarowej
W celu umożliwienia zaawansowanej automatyzacji analizy tekstu, musimy przekształcić go w format obsługiwany przez algorytmy uczenia maszynowego – w numeryczną wersję tekstu. Takim formatem mogą być wektory określające znaczenie słów w przestrzeni.
Jednym z aktualnie najlepszych rozwiązań do tworzenia takich wektorów jest wykorzystanie wstępnie wytrenowanych algorytmów opartych o architekturę Transformer. Pozwalają one na stworzenie, opartej o kontekst, reprezentacji słów (a także całych zdań) w przestrzeni wielowymiarowej. W najprostszych słowach podobne teksty są dzięki takim modelom reprezentowane w przestrzeni blisko siebie.
Wykorzystując model wyspecjalizowany w tworzeniu reprezentacji całych zdań możemy przekształcić poniższe cytaty (z pewnego znanego serialu mockumentalnego) w wektory, a następnie obliczyć podobieństwo cosinusowe pomiędzy nimi, aby zweryfikować czy reprezentacje podobnych tekstów faktycznie są bliskie siebie.
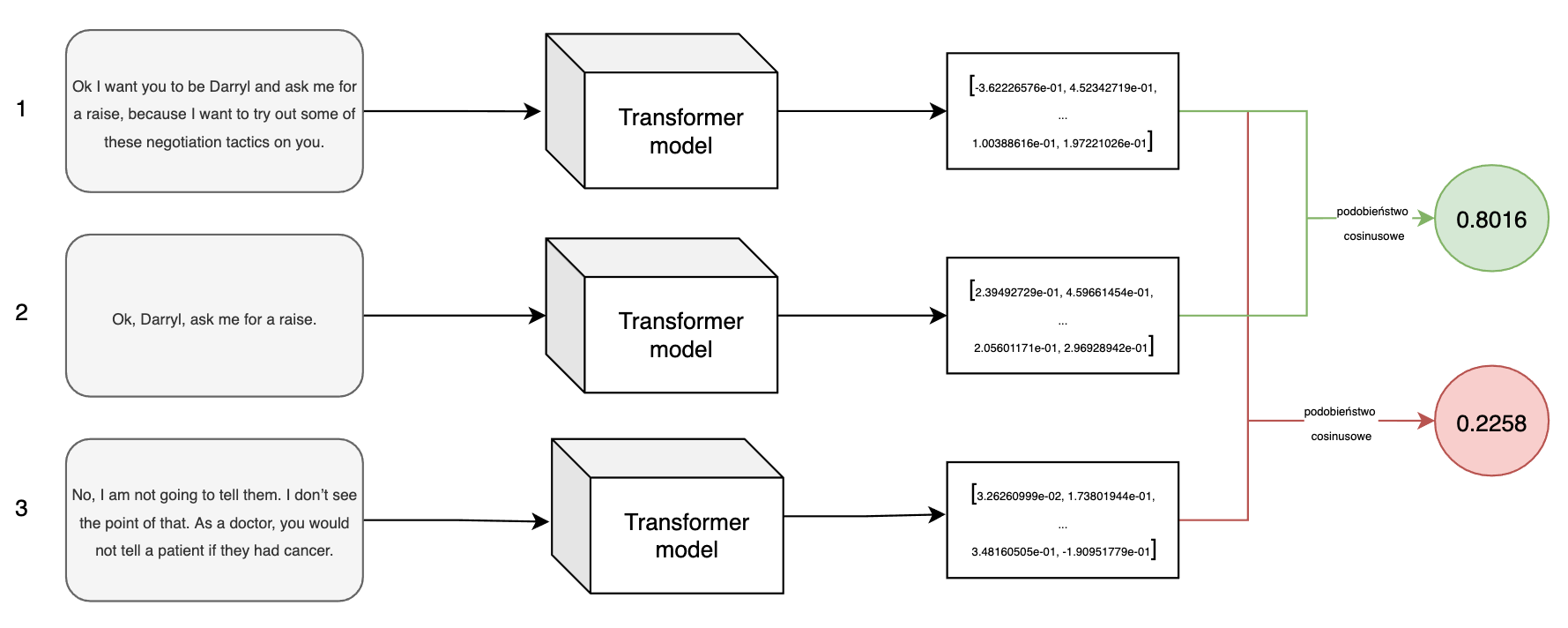
Pierwsze dwie wiadomości mają dosyć podobną treść, a trzecia dotyczy czegoś zupełnie innego. Przeliczenie podobieństwa cosinusowego dla danych reprezentacji (w parach 1-2 i 1-3) ukazuje spodziewany rezultat – miara podobieństwa pierwszej pary jest znacznie wyższa niż drugiej pary.
Algorytmy oparte o architekturę Transformer wyróżniają się ogólnodostępnością w formie dostosowanej na podstawie ogromnych zbiorów danych tekstowych. Nasza rola, w ich użytkowaniu, może sprowadzić się do prostego ściągnięcia danego modelu i przeliczenia go na naszych danych. Oczywiście, moglibyśmy go dostosować na naszych danych, ale w tym rozwiązaniu chodzi nam o prostotę i szybkość.
Uczenie nienadzorowane
Mając dane tekstowe w numerycznej formie, możemy przystąpić do analizy wykorzystując modele uczenia maszynowego. Brak etykiet powoduje, że musimy sięgnąć po alternatywne metody takie jak uczenie nienadzorowane. Oznacza to, że w trakcie treningu (dostosowywania modelu do danych) nie wskazujemy bezpośrednio klas obserwacji i chcemy, aby nasz algorytm sam wyodrębnił grupy obserwacji na podstawie ich cech. W przypadku danych tekstowych te cechy to tak naprawdę kierunek wektora będącego reprezentacją słowa (tekstu) w przestrzeni wielowymiarowej. Naszym celem jest więc identyfikacja skupisk tekstów o podobnym znaczeniu – podobnym kierunku.
Identyfikacja skupisk w tekście
Przetworzone dane tekstowe możemy wrzucić do modelu nienadzorowanego, który zidentyfikuje klastry. Niewielkim kosztem możemy go dostosować do danych przez tuning hiperparametrów.
Jednym z takich modeli, który niezwykle dobrze radzi sobie z danymi tekstowymi, chociażby ze względu na eliminację szumu jest DBSCAN (z ang. Density-based spatial clustering of applications with noise).
Ten algorytm, w dużym uproszczeniu, identyfikuje grupy obserwacji w gęstych regionach i pomija pozostałe. Dzięki temu obserwacje odstające czy szum, nie zostaną przyporządkowane do klastrów “na siłę”, jak to ma miejsce w przypadku np. algorytmu k-średnich, gdzie każda obserwacja musi zostać przyporządkowana do wcześniej zdefiniowanej liczby skupisk.
Tak jak jest to zaprezentowane na poniższej ilustracji – w przypadku algorytmu k-średnich każdy punkt należy do jakiegoś klastra, a w przypadku DBSCANu zidentyfikowane są rejony o największej gęstości pozostawiając szum (szare kropki) nietknięty.
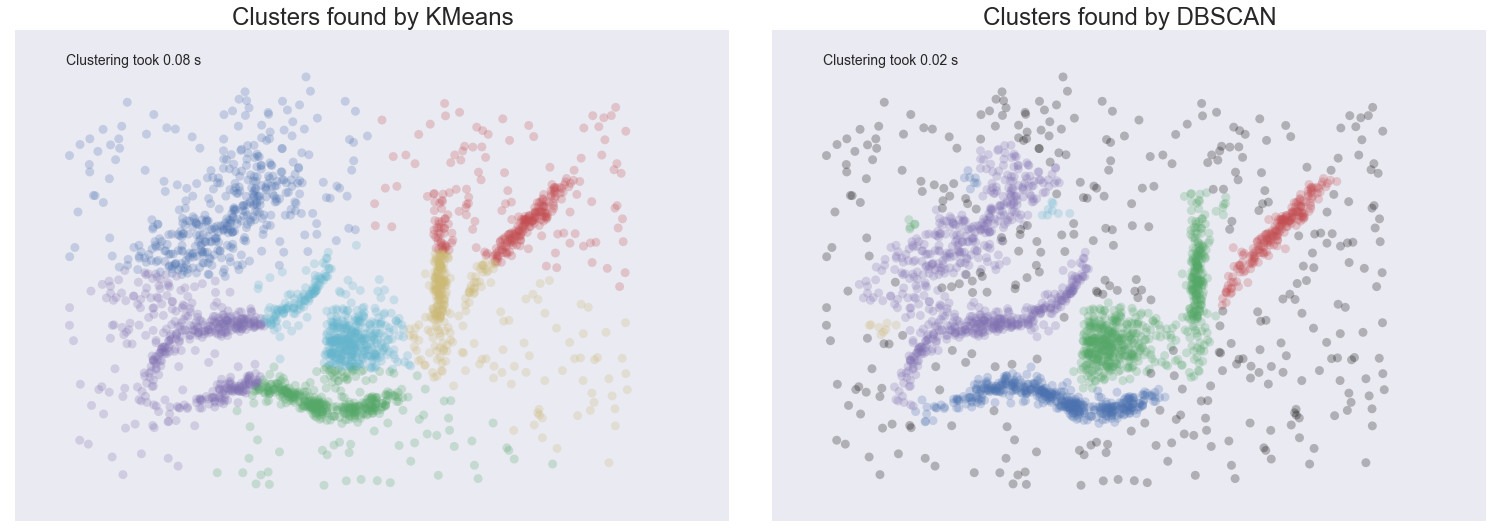
Źródło: hdbscan.readthedocs.io
Wykorzystując DBSCAN otrzymamy skupiska o dużej gęstości – zawierające teksty o bardzo zbliżonym znaczeniu. Szum, znacznie utrudniający analizę zostanie pominięty – mogą być nim np. wiadomości spam lub zupełnie niezwiązane z produktem opinie. Możliwe, że takie wiadomości lub opinie są warte dodatkowej analizy, lecz jeśli chcemy skupić się na głównych grupach/kategoriach, to pominięcie szumu zdecydowanie pozytywnie wpłynie na przebieg analizy.
Otrzymane skupiska możemy przeglądać ręcznie i sami identyfikować kategorię tekstu np. opinii dotyczących wad telefonu lub podobnych pytań. Możemy także wizualizować klastry po zredukowaniu wymiarów reprezentacji wektorowej tekstu, wykorzystując techniki jak PCA czy UMAP. Klastry na zbiorze wszystkich dialogów z pewnego znanego serialu mockumentalnego, takie jak:

… możemy zwizualizować w trzech wymiarach po redukcji wymiarów reprezentacji wektorowych wykorzystując technikę PCA z trzema komponentami (jak na poniższej ilustracji, gdzie każdy kolor oznacza inny klaster i widocznych jest 8 klastrów). Podobne do siebie linijki transkryptu są do siebie wyraźnie zbliżone.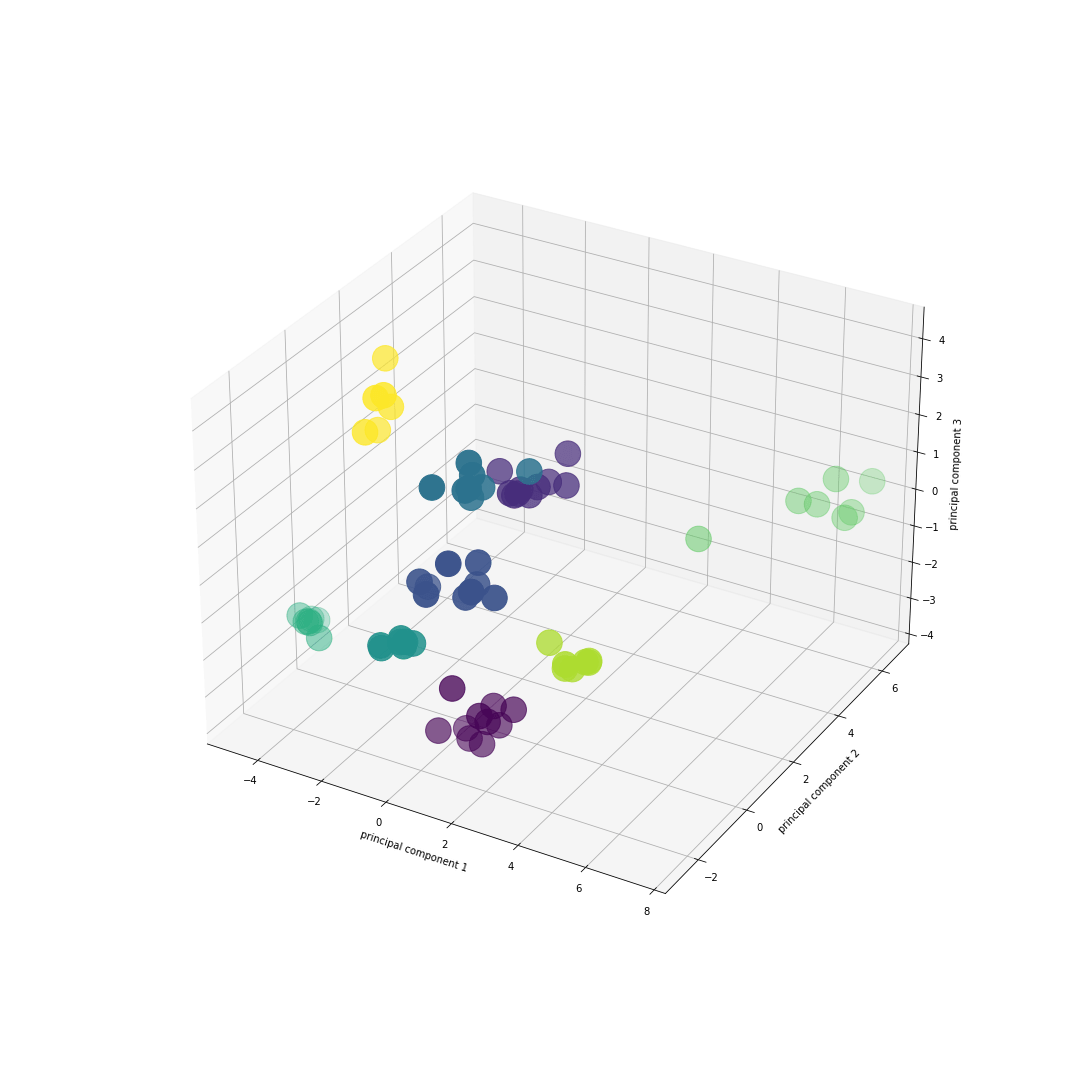
Bardziej zaawansowanym podejściem jest jednak próba zautomatyzowanej identyfikacji tematów w poszczególnych klastrach. Standardowym podejściem jest ekstrakcja najistotniejszych słów poprzez macierz TF-IDF. Jednak prosta modyfikacja tego podejścia polegająca na tworzeniu macierzy TF-IDF wewnątrz klastra (class-based TF-IDF,) a nie na całym korpusie tekstu znacząco ułatwią interpretacje skupisk.
W ten sposób możemy wyodrębnić skupiska podobnych tematów, a także niewielkim kosztem automatycznie nazywać te skupiska poprzez najistotniejsze terminy znajdujące się w tekście. Jedno z takich skupisk, zawierające zdania podobne do tych z przykładu obliczania podobieństwa miarą cosinusową, zostało określone słowami: raise, ask, salary, schedule, compensation, Michael – bez problemu możemy zinterpretować temat poruszany w tym klastrze. Otrzymane tematy możemy następnie ujednolicić do kilku kategorii lub wykorzystywać je w niezmienionej formie.
Z livechata Tidio na co dzień korzystają tysiące użytkowników stron internetowych, przeprowadzając miliony konwersacji z działami obsługi klienta. Zbiór danych, które gromadzimy dzięki naszemu widgetowi stale się powiększa, aktualnie przewyższając już 2TB. Wykorzystując opisane wyżej techniki znacząco przyspieszyliśmy proces analizy konwersacji i pozyskiwania wartości biznesowych z tekstu, który wyjściowo nie był oznaczony. Praca na zbiorze danych tekstowych wymaga poświęcenia i pasji do strukturyzacji danych. Wartość biznesowa jaka płynie z analizy tekstu dla całej firmy i rozwoju produktu zdecydowanie jednak przewyższa konieczne do zainwestowania nakłady pracy.
Chcesz dowiedzieć się więcej? Pasjonujesz się analizą tekstu i chciałbyś dołączyć do zespołu Tidio? Zaaplikuj na nasze stanowiska.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Wykrywanie defektów w produkcji z uczeniem nienadzorowanym

Generator zdjęć AI stworzył selfies końca świata. Są przerażające

Największe firmy ufają danym. Ulrika Jägare o przyszłości sztucznej inteligencji
