Testy w Pythonie. Trzy główne problemy zestawów testów

Pisanie testów kodu już jakiś czas temu weszło do programistycznego mainstreamu. Pythonowa społeczność również poddała się temu trendowi. Najłatwiej stwierdzić to po dostępnych narzędziach –nawet w bibliotece standardowej znalazło się miejsce dla modułu unittest, który zawziętym w zupełności wystarczyłby do pracy. Oczywiście poza nim Pythonowcy mają do dyspozycji wiele innych doskonałych narzędzi, jak pytest.
Co więcej, popularne frameworki i biblioteki (np. Django, Twisted) dostarczają rozmaitych helperów, które w znaczący sposób ułatwiają testowanie aplikacji w nich napisanych. Pisanie testów weszło nam w krew. Nikogo nie dziwią rozbudowane zestawy testów liczące tysiące linii kodu czy wysokie pokrycie (ang. coverage), oscylujące w okolicy 80% i więcej.

Sebastian Buczyński. Expert Python Developer w STX Next. Programista “na sterydach”, ze smykałką do poszukiwania potencjalnych punktów zapalnych tak w oprogramowaniu, jak i całych procesach. Doświadczenie zbierał pracując parę ostatnich lat nad rozbudowaną platformą teleinformatyczną (ostatnio jako lider techniczny), a także zahaczając po drodze kilka startupów tak tajnych, że strach o nich mówić.
Spis treści
Czy ilość pluginów do pytesta przekłada się na dobre testy?
Niestety, tak samo nie dziwią nas zestawy testów, które wykonują się kilkanaście (a czasem kilkadziesiąt) minut. Z racji dynamicznej natury Pythona, szybko rośnie też czas uruchomienia pojedynczego testu, tym samym utrudniając TDD. Nikt nie zaprzeczy, że z czasem projekty IT stają się bardziej skomplikowane, a ich utrzymanie kosztuje. Zdajemy się jednak odsuwać na dalszy plan fakt, że to samo dzieje się z naszymi zestawami testów. To w końcu nasza siatka bezpieczeństwa — nie powinniśmy jej zaniedbywać do momentu, w którym staje się nieznośnym ciężarem.
Pomimo tego, że mamy wiele wspaniałych narzędzi, które pomagają ZACZĄĆ testowanie, nie przekłada się to na UTRZYMANIE kondycji zestawów testów w dłuższej perspektywie. Tego problemu nie rozwiążemy paczką z PyPI — tu trzeba trochę inżynierii oprogramowania. Ten artykuł jest dla każdego, kto szuka sposobów na poprawienie stanu swoich testów, szuka recept na uwolnienie się od patchowania/mockowania połowy świata i chce by pisanie testów pomagało w pracy, a nie stawało się przykrym obowiązkiem.
Skutki zaniedbania zestawu testów
Wśród widocznych objawów charakterystycznych dla zaniedbanego zestawu testów wybijają się szczególnie trzy:
Testy są wolne
Jeżeli developer czeka kilkanaście minut na wykonanie się wszystkich testów (a przynajmniej tych, które uruchamia u siebie na komputerze) to już mamy problem. Nikt przez tyle czasu nie utrzyma uwagi na zadaniu. Równie kłopotliwy jest kilkunastosekundowy czas oczekiwania na uruchomienie jednego/kilku testów podczas TDD. Dodatkowo, te uciążliwości zniechęcają programistów do pisania testów, co może się odbijać na malejącej jakości przypadków testowych.
Testy są nieczytelne
W każdym nietrywialnym projekcie znajdzie się jakiś skomplikowany scenariusz do przetestowania. Kod testu do tego scenariusza przestaje wtedy przypominać trzylinijkowy test z tutoriala, a zrozumienie go wymaga maksymalnej koncentracji. Rekordowo trudne do czytania testy widziane przez autora artykułu liczyły sobie po kilkaset linii.
Testy są niestabilne
Im więcej rozmaitych rzeczy wykorzystuje nasz projekt (a zatem pośrednio test), tym większe ryzyko jest wystąpienia tak zwanego false-negative, czyli zawalenie testu mimo tego, że nie ma żadnego błędu. Co gorsza, ponowne uruchomienie zestawu albo samego testu już nie pokazuje błędu. Szczególnym przypadkiem jest próba uruchamiania testów współbieżnie — jeżeli od początku nie dbaliśmy o należytą izolację testów, czeka nas wiele emocjonujących chwil.
Jak żyć?
Jak wspomniałem we wstępie, problemu nie rozwiążemy instalując paczkę za pomocą pip albo przestawiając opcję w konfiguracjiDJANGO_SLOW_TEST = False.Potrzebujemy krytycznego spojrzenia na to, co robiliśmy do tej pory, świadomego podejścia, wzięcia odpowiedzialności i szczypty inżynierii oprogramowania. Dalsza część artykułu przedstawia możliwe rozwiązania trzech głównych problemów zestawów testów. Wprawdzie artykuł nie jest o narzędziach, ale wielokrotnie odwołuje się dopytesta iDjango po to, aby zilustrować pewne zagadnienia.
Szybkość wykonania zestawu testów w Pythonie
Grzech główny
Głównym spowalniaczem jest robienie zbyt wiele podczas testu. Innymi słowy, poza paroma linijkami kodu, które chcemy sprawdzić, często tracimy czas na wykonanie kodu frameworka, którego wcale testować nie musimy i nie chcemy.
Weźmy na warsztat Django i zobaczmy, jak wygląda stereotypowy test:
@pytest.mark.usefixtures('transactional_db')
def test_should_win_auction_when_no_one_else_is_bidding(
authenticated_client: Client, auction_without_bids: Auction # 1
) -> None:
expected_current_price = auction_without_bids.current_price * 10
url = reverse('make_a_bid', args=[auction_without_bids.pk]) # 2
data = json.dumps({
'amount': str(expected_current_price)
})
response = authenticated_client.post(url, data, content_type='application/json')
assert_wins_with_current_price(response, expected_current_price) # 3
1. Krok Arrange / Given: Zaczynamy od przygotowania systemu do stanu, w którym zamierzamy testować. Dzięki fiksturze auction_without_bids w bazie znajduje się oczekiwany model aukcji bez ofert.
2. Krok Act / When — wywołujemy odpowiedni widok korzystając z routingu Django, przekazując parametry.
3. Krok Assert / Then — sprawdzamy, czy odpowiedź spełnia nasze oczekiwania oraz opcjonalnie czy w bazie znajduje się to, czego się spodziewamy.
Trudno zarzucić coś strukturze tego testu, jak na dłoni widać książkowy schemat z kroków Arrange – Act – Assert / Given – When – Then. Jeżeli jednak zależy nam na szybkości zestawu testów, to nie mamy powodów do zadowolenia. W stosunku do sprawdzanej logiki, wykonujemy absurdalnie długą drogę przez wszystkie warstwy Django + Django Rest Frameworka:
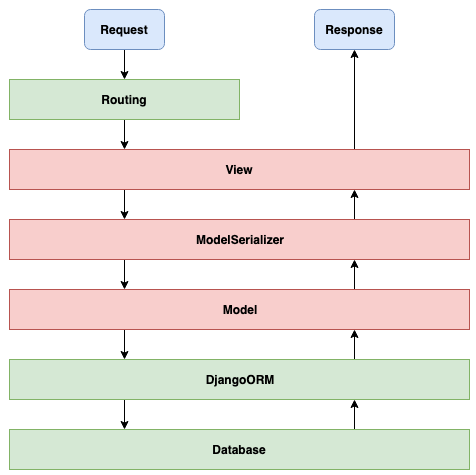
Warstwy w Django + DRF
To, co sprawdzamy powyższym teście zapewne znajduje się gdzieś na tej drodze. Nasza logika stanowi ułamek zarówno całego kodu wykonywanego podczas testu, jak i czasu trwania testu. Marnotrawstwo jest widoczne gołym okiem, szczególnie gdy takich testów mamy kilkanaście do jednego widoku.
Sposoby
Rozwiązaniem będzie wydzielić osobne miejsce dla naszej logiki. Koncepcyjnie, dorzucamy kolejną warstwę w powyższym diagramie, gdzie będziemy pisać kod, który implementuje wszystkie wymagania biznesowe.
Istnieje kilka podejść do tego, jak sobie takie wydzielone miejsce zorganizować. Jednym z najprostszych sposobów jest stworzenie modułu services.py i umieszczenie tam funkcji odpowiedzialnych za naszą logikę biznesową.
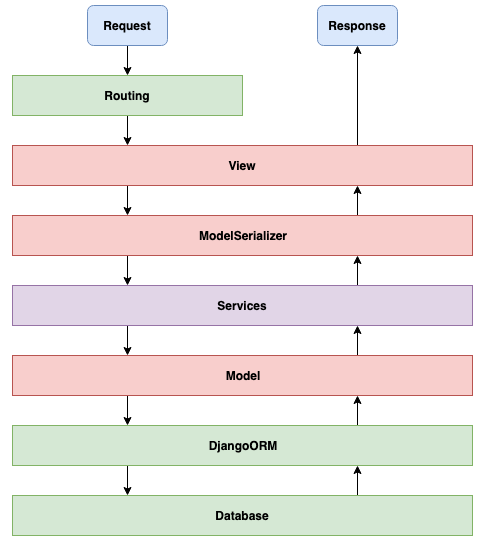
Wydzielona warstwa Services na logikę biznesową
Więcej szczegółów na temat tego podejścia możecie znaleźć w tej prezentacji. Jest to sposób prosty, acz może okazać się w pełni wystarczający dla pewnych przypadków.
Jeżeli szukacie bardziej rozbudowanej techniki, polecam Czystą Architekturę, o której możecie poczytać w tym artykule na justgeek.it.
Naturalnie budowanie osobnej warstwy na logikę biznesową to spora inwestycja. Nie w każdym projekcie warto to robić, szczególnie jeżeli tej logiki biznesowej za dużo nie ma. Natomiast w sytuacji gdy jest i to sporo, to czy opłaca się to robić? Z punktu widzenia szybkości i czystości testów — tak, i to z całą pewnością.
Testy jednostkowe na wydzielonej warstwie testują logikę biznesową ponad 50 razy szybciej, niż gdybyśmy mieli to samo robić przez widoki. Szczegóły wraz z konkretnymi liczbami w tym artykule.
Pozostaje pytanie, czy testowanie wyłącznie wydzielonej warstwy z logiką daje pewność, że będzie ona działać razem z naszym frameworkiem? Nie. W takim przypadku potrzebujemy jeszcze mieć test, który przejdzie przez możliwie dużo warstw. Możemy salwować się napisaniem JEDNEGO testu dla tak zwanego happy-path dla każdego widoku z użyciemDjango test clienta, albo zostawić to testom na wyższym poziomie (wykonywanym przez UI z Selenium). Wszystko zależy od projektu. Druga, jeszcze ważniejsza rzecz — zostawiamy nasze widoki/serializery maksymalnie głupie — nie umieszczamy tam żadnych instrukcji warunkowych. Ich jedyną rolą ma być przerzucenie danych do warstwy niżej.
Nie zagrzebuj logiki biznesowej gdzieś w czeluściach frameworka, chowając po widokach albo serializerach. Wyciągnij to osobno.

Pomniejsze grzechy
Innym często spotykanym przez autora antywzorcem jeśli chodzi o szybkość testów z Django jest używanie test clienta do sprawdzania, czy dany widok aby na pewno wymaga autoryzacji. Kolejny przykład to sprawdzanie w ten sam sposób obsługiwanych metod HTTP. Przykładowy scenariusz — mamy widok, który powinien obsługiwać tylko metody GET i POST. Piszemy test który sprawdza wszystkie pozostałe metody (PUT, PATCH, DELETE, …) i sprawdza asercją, czy na pewno dostajemy 406 Not Acceptable. Nie próbuję tutaj kwestionować zasadności pisania takich testów, ale sposób ich implementacji – już jak najbardziej. Oba te scenariusze można przetestować jednostkowo na samym widoku w izolacji, bez uruchamiania całej maszyny Django.
Tymczasem jeżeli rzucimy okiem na źródła klasy View w Django to zobaczymy, że cały mechanizm sprawdzania obsługiwanych metod sprowadza się do:
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
Oznacza to, że możemy równie skutecznie sprawdzić nasz widok jednostkowo poprzez asercje czy ma metody post, get, patch itd.
Szybkie sposoby
Istnieje kilka tak zwanych quick-wins, jeśli chodzi o szybkość testów:
- uruchamianie współbieżne testów z użyciem pytest-xdist,
- pomocne szczególnie z testami używającej bazy danych i innych zewnętrznych zależności, w przypadku testów jednostkowych różnica jest nieznaczna,
- wyłączenie hashowania hasła użytkowników w testach,
- przy testach UI/API — zamiast przechodzenie przez endpoint logowania, można spreparować odpowiednie cookies/JWT i oszczędzić parę sekund na teście,
- sprawdzenie czy nie używamy w testach zbędnych fikstur i wyeliminowanie ich,
- profilowanie testów z cProfile by namierzyć największe spowalniacze.
Czytelność testów
Grzech główny
“Goły” Python jest wystarczająco ekspresywny, jeśli chodzi o testy jednostkowe. Jeżeli jednak spróbujemy przetestować jakiś bardziej skomplikowany scenariusz biznesowy składający się z wielu kroków, to nasz zestaw testów zaroi się od długich, brzydkich potworków. Z pewnością takie testy będą działać i spełniać swoje zadanie, ale nie musimy wcale żyć z ich kiepską czytelnością. Potrzebna jest inna notacja. Witaj w świecie Domain Specific Languages (w skrócie DSL).
Sposoby
Testy API
Jeżeli testujemy API i w kodzie budujemy zapytania oraz sprawdzamy odpowiedzi, szybko złapiemy się na produkowaniu masy mało ekspresywnego kodu. Wtyczką do pytesta, która zwalnia nas z potrzeby pisania w imperatywny sposób jest tavern. W tym narzędziu używamy YAMLa do pisania scenariuszy w sposób deklaratywny określając jakie żądanie wysyłamy oraz jakiej odpowiedzi się spodziewamy:
test_name: Get some data
stages:
- name: Make sure we have the right ID
request:
url: https://jsonplaceholder.typicode.com/posts/1
method: GET
response:
status_code: 200
body:
id: 1
Swoją drogą, to tavern jest kompatybilny z pytest-xdist. Testy API świetnie nadają się do uruchamiania współbieżnie.
Testy scenariuszy biznesowych — BDD
Jeżeli szukamy notacji wygodnej do opisywania scenariuszy biznesowych, to warto zainteresować się Behaviour Driven Development (w skrócie BDD). Jedną z najpopularniejszych w Pythonie bibliotek do pracy z BDD jest behave. Testy w tej notacji powstają dwuetapowo. Najpierw zapisujemy nasz scenariusz w specjalnym języku Gherkin:
Feature: Bidding on an auction
Scenario: New bid on auction without prior bids
Given an auction has no bids
When bid is placed with price higher than the auction's current price
Then new bid will be winning one on the auction
Następnie każdy z kroków musimy zaimplementować już w Pythonie:
@given(u'an auction has no bids')
def step_impl(context):
...
@when(u'bid is placed with price higher than the auction's current price')
def step_impl(context):
...
@then(u'new bid will be winning one on the auction')
def step_impl(context):
...
Tematyce Behaviour Driven Development poświęcono niejedną książkę i niezliczoną ilość blog postów. Ten artykuł nie może z oczywistych względów opisać wyczerpująco tej techniki.
W kompetencjach autora pozostaje odpowiedzieć na pytanie, na jakiej warstwy aplikacji właściwie zastosować BDD? Jest kilka możliwości. Można implementować testy na poziomie UI, na przykład z Selenium. Można też próbować robić to przez API. Jeżeli zaś mamy wydzieloną warstwę na logikę biznesową, to możemy też tam testować behawioralnie. Niezmienne pozostaje, że im niższa warstwa tym nasze testy będą szybsze i bardziej stabilne. Najtrudniej więc będzie nam utrzymać testy na poziomie UI, a dużo łatwiej jeżeli testujemy warstwę logiki biznesowej. Oczywiście zbudowanie ostatniej to też spora inwestycja o czym była mowa wcześniej.
Własny DSL
Istnieje jeszcze jedno rozwiązanie, które okaże się pomocne gdy żadna z powyższych receptur nas nie urządza. Tworzymy własny język, w którym będziemy definiować testy odpowiednio definiując stan początkowy (Arrange / Given), potem komendę dla systemu (Act / When) i na oczekiwany stan końcowy (Assert / Then). Co ważniejsze, nie musimy stosować własnego DSLa na poziomie API/UI. Można także użyć go w niżej poziomowych testach.
Za ilustrację niech posłuży DSL do opisywania jednego z prostych algorytmów działania giełd, jak w tym poście na stackoverflow. Najpierw określamy stan początkowy systemu (Arrange / Given). W domenie giełdy mówimy o tak zwanym order booku:

W powyższym przykładzie definiujemy order book z 3 oczekującymi zleceniami sprzedaży, ułożone w kolejności rosnąco według ceny i czasu. Jest to kolejność wykonania dla nowych zleceń kupna — zgodnie z algorytmem opisanym na SO.
Następnie wskazujemy w teście jakie nowe zlecenie kupna/sprzedaży zostaje złożone (Act / When):
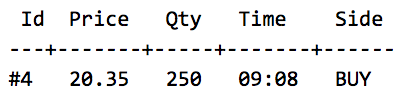
I na koniec definiujemy jak ma wyglądać order book po wykonaniu nowego zlecenia (Assert / Then):
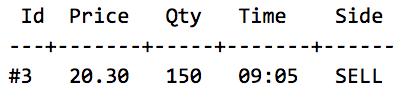
Jak widać, oczekujemy, że zlecenie sprzedaży zostanie wypełnione w całości i to samo spotka dwa z pierwszych zleceń kupna. Ostatnie z nich zostaje wypełnione częściowo (Qty zmieniło się z 200 na 150).
Dysponując taką notacją pisania testów łatwo sobie wyobrazić, jak szybko i łatwo możemy opisać wiele innych przypadków testowych w domenie giełd.
Kosztem własnego DSLa jest oczywiście potrzeba napisania i utrzymania kodu, który będzie tłumaczył nasze kroki zapisane w ciągach znaków na konkretne obiekty.
Stabilność testów
Grzechy główne
W przypadku stabilności testów najczęściej spotykanymi antywzorcami są:
- nieutrzymywanie dostatecznej izolacji testów między sobą
- poleganie na zawodnych zewnętrznych zależnościach (przykładowo system plików)
Sposoby
Naruszenie izolacji między testami polega najczęściej na, kolokwialnie rzecz ujmując, pozostawianiu po sobie bałaganu. Pierwsza rzecz, która przychodzi na myśl to bazy danych, ale tutaj pytest-django daje nam dobry przykład. Używając fikstury transactional_db transactional_db lub klasy TransactionalTestCase zapewniamy sobie, że przed każdym testem zostanie rozpoczęta transakcja, a na koniec zostanie wycofana, pozostawiając nas z czystym stanem. To tyle jeśli chodzi o gotowce, natomiast gdy używamy innych baz danych/brokerów/usług sami musimy zadbać o odpowiednie posprzątanie. Przykłady dla kilku popularnych rozwiązań:
System plików
Sam odczyt z pliku, na przykład konfiguracji, nie powinien powodować żadnych problemów. Dużo gorzej sprawa ma się z zapisem, który może zmieniać plik współdzielony przez wiele testów i w ten sposób wpływać na ich wynik. Zapewnienie izolacji polega na upewnieniu się, że różne testy korzystają z unikalnych plików. Zaczynamy od utworzenia katalogu tymczasowego i przestawienia odczytu/zapisu na lokalizację w nim. Na koniec testu usuwamy katalog tymczasowy. pytest zawiera parę przydatnych fikstur, które zapewniają automatyczne tworzenie i czyszczenie tymczasowych folderów. Raczej unikamy korzystania z plików, których używa aplikacja podczas normalnego działania.
ElasticSearch
Na ElasticSearchu dane są zorganizowane w indeksy, które z kolei składają się z dokumentów. O ile nasze testy nie zmieniają żadnych danych, to wystarczy raz na początku testów zaindeksować dokumenty i na końcu je usunąć. Pomocne może okazać się stworzenie tymczasowego indeksu tylko w tym celu, by na koniec w łatwy sposób można było po sobie posprzątać. Jeżeli testy zmieniają dane w ElasticSearchu, to izolację osiągamy poprzez ponowne tworzenie indeksu na początku każdego testu i usuwaniu go na końcu.
RabbitMQ
Na popularnym brokerze wiadomości trzymane są w kolejkach. Wszystko zależy od naszej konfiguracji — to, czy używamy stałych kolejek, czy może dynamicznie tworzymy nowe w razie potrzeb. W drugim przypadku raczej nie musimy robić nic, w pierwszym kolejki można usuwać i tworzyć ponownie lub korzystać z operacji purge — czyszczenia zawartości.
Redis
Ta baza danych ma wprawdzie szczątkową obsługę transakcji (a raczej warunkowego wykonania komend), ale zamiast jej używać o wiele łatwiej jest po prostu na końcu każdego testu skorzystać z FLUSHDB, aby opróżnić obecną bazę albo FLUSHALL — aby wyczyścić całą instancję.
Powyższe sposoby są wystarczające, ale tylko jeżeli uruchamiamy zawsze testy jeden po drugim. Nie zadziałają, gdy używamypytest-xdist, ale tutaj ponownie przychodzi nam pytest-django jako wzorowe rozwiązanie.
pytest-xdistdefiniuję fiksturę worker_id, która będzie zwracać inny ciąg znaków dla każdego procesu wykonującego testy. Przykładowe wartości, gdy uruchomimy testy z parametrem (-n 4) na 4 procesach to:pgw_0, gw_1, gw_2 i gw_3. pytest-django korzysta z tego i dla każdego z procesów tworzy OSOBNĄ bazę danych, dodając worker_id do jej nazwy, by była unikalna. Rozwiązanie dla innych zależności nasuwa się samo — musimy brać pod uwagę worker_id zarządzając naszymi zasobami.
System plików
W teorii nic nie musimy robić, gdyż fikstury z tymczasowymi katalogami od razu powinny być unikalne per test.
ElasticSearch
W tym przypadku rozwijamy używanie indeksów, doklejając do ich nazwy worker_id by mieć pełną separację pomiędzy poszczególnymi procesami wykonywującymi testy.
RabbitMQ
Na Rabbicie najwygodniej ograć sobie różne procesy dzięki wykorzystaniu vhostów — wirtualnych przestrzeni, które są od siebie kompletnie odseparowane. Kolejki, wiadomości i inne elementy utworzone w jednym vhost nie są widoczne w innych. Koniec końców, sprowadza się do parametryzacji połączenia do Rabbita za pomocą worker_id, by połączyć się do pożądanego vhosta po jego utworzeniu. Na końcu wykonania zestawu testów naturalnie usuwamy vhosty.
Redis
Redis ma mechanizm analogiczny do RabbitMQ — pozwala na tworzenie przestrzeni w których dane są niewidoczne w innych i nazywa je… bazami. Domyślnie mamy ich 8, numerowane o 0-7. O ile nie korzystamy w aplikacji z różnych baz, to możemy wykorzystać je do odseparowania procesów wykonujących testy. Powstrzymujemy się wtedy od używania FLUSHALL. Ostatnia ważna rzecz — bazy nie separują mechanizmu PUBLISH/SUBSCRIBE na Redisie, więc musimy mieć to na uwadze.
Strategia testów
Do przepisu na udane testowanie aplikacji brakuje jeszcze jednego — świadomej podejścia do tego, jakie testy piszemy i co nimi pokrywamy. Nie chodzi tu na przykład o całkowite pokrycie (ang. coverage) w ramach całego projektu, ale bardziej o to, że zgadzamy się na pokrycie na warstwie logiki rzędu 95% (co jest możliwe w Czystej Architekturze). Dodatkowo wspomagamy się testami behawioralnymi z behave + Selenium. Dla uzupełnienia napiszemy testy integracyjne.
Taka strategia dałaby nam idealną piramidę testów. Jednakże, nie w każdym projekcie (lub nie w każdym module/mikroserwisie) da się uzyskać taki kształt piramidy. Nie oznacza to, że coś robimy źle. Jeżeli nasza aplikacja jest mało wyrafinowana i służy za przeglądarkę do relacyjnej bazy danych, to choćbyśmy nie wiem jak się pocili, testy jednostkowe będą stanowić mniejszość. Podobnie będzie wyglądać sytuacja, gdy grom naszego kodu odpowiada za komunikację z zewnętrznymi usługami.
Antywzorcem jest testowanie wszystkiego w jeden sposób, “bo jest najpewniejszy”. Strategia testowania powinna też kłaść nacisk na minimalizowanie czasu wykonania zestawu testów i łatwość jego utrzymania. Dlatego antywzorcem byłoby testowanie absolutnie wszystkiego tylko przez UI z Selenium, bo te takie testy są wolne i najmniej stabilne i trudne w utrzymaniu (ze względu na to, że polegają na wielu rzeczach).
Podsumowanie
Chociaż pisanie testów jest dziś powszechne, to zdecydowanie zbyt mało mówi się o utrzymaniu zestawu w dobrej kondycji przez dłuższy czas. Podobnie jak kod produkcyjny wymagający ciągłej refaktoryzacji i ulepszania, tak nasze zestawy testów należy pielęgnować z nie mniejszą uwagą. Naszą nagrodą będzie większa swoboda we wprowadzaniu zmian dzięki większej jakości naszej siatki bezpieczeństwa.
Jeżeli wkładasz dużo wysiłku w testy i rezultat wciąż nie jest zadowalający, to znaczy, że ten wysiłek powinien zostać włożony w testowany kod. Trochę refaktoryzacji, aby poprawić testowalność i wydzielić logikę biznesową osobno zdecydowanie się opłaca.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
