Tak wygląda nasz workflow od powstania ticketu po rozwiązanie problemu na produkcji

Początkiem każdego projektu powinno być jego zaplanowanie. W zależności od tego czy jest on prowadzony kaskadowo, czy zwinnie, może ono być mniej lub bardziej szczegółowe. Proces ten jest jednak nierozłącznym elementem wspomagającym określenie budżetu czy przewidywanych ram czasowych.
Projekt, na podstawie którego powstał ten artykuł, był realizowany przez Accenture z użyciem tradycyjnej metody kaskadowej (waterfall), ze wspomagającymi go elementami technik i metodyk zwinnych (agile/scrum) – można powiedzieć, że była to swego rodzaju hybryda.

Marek Kubica. Test Architect Specialist w Accenture – globalnej firmie świadczącej usługi w zakresie technologii cyfrowych, chmury obliczeniowej i bezpieczeństwa. Tematami testowania i zapewnienia jakości rozwiązaniom cyfrowym zajmuje się od 2014 roku. Absolwent Uniwersytetu Śląskiego na wydziale Informatyki i Nauki o Materiałach z tytułem doktora. W swojej pracy zawodowej dba o proces wytwarzania oprogramowania, zarządza międzynarodowym zespołem, a także czuwa nad zapewnieniem jakości i terminowości dostarczenia produktu.
Planowanie rozpoczęliśmy od:
- Określenia głównych celów projektu, które staraliśmy się definiować korzystając z metody SMART, czyli budowaliśmy je tak, by były konkretne, mierzalne, możliwe do zrealizowania w określonym czasie.
- Stworzenia harmonogramu projektu, a także zaplanowania dostarczania poszczególnych funkcjonalności, dzięki czemu możliwe było określenie zasobów i dostępności zespołu testowego.
- Stworzenie dokumentu RACI (macierz odpowiedzialności), w którym określono, kto będzie odpowiedzialny za poszczególne zadania projektowe – w tym przypadku chodziło o określenie odpowiedzialności Accenture-klient i wskazania tych obszarów.
- Opracowania podejścia i planu testowego (test approach and plan) – w dokumencie tym znalazły się wszystkie informacje dotyczące zakresu wykonywanych prac testowych (były to między innymi: testy jednostkowe, funkcjonalne, wydajnościowe, stochastyczne, UI i Operational Acceptance Test (OAT)), a także jasnego określenia elementów, które nie będą w tym projekcie wykonane przez Accenture (np. testy UAT, BVT czy PenTesty). Opisano podejście sprawdzania poszczególnych funkcjonalności, rodzaju i typów wykonywanych testów, a także czas ich realizacji. Na podstawie kontaktu z analitykami biznesowymi wyszczególniono, które funkcjonalności i w jakim stopniu powinny zostać pokryte testami manualnymi i automatycznymi, a także określono podejście przyrostowej regresji manualnej i automatycznej. W dokumencie opisano środowiska, na których będą wykonywane testy, a także zasady ich funkcjonowania i dostępności.
Określono kryteria rozpoczęcia i zakończenia testów (Exit and Entry Criteria). Zaproponowano jak powinien wyglądać szablon przypadku testowego, a także defektu z opisaniem poszczególnych pól. Wskazano narzędzia, które zostały wykorzystywane w projekcie – w przypadku narzędzia do zarządzania testami i defektami, a także monitorowania postępów prac testowych była to Jira. Określono również możliwe ryzyka, a także opracowano plan ich ograniczania ze wskazaniem osób odpowiedzialnych. - Na podstawie założonego harmonogramu i planu wyestymowaliśmy ilość zasobów potrzebnych do realizacji projektu określonych w MD (man days). Przy początkowej fazie dużego projektu praktycznie niemożliwym jest określenie wszystkich ryzyk, zależności i występujących między systemami czy infrastrukturą połączeń. Nie da się również ocenić, ile dokładnie tester manualny wykona przypadków testowych dziennie, ponieważ różnią się one między sobą skomplikowaniem czy występującymi zależnościami. Jednakże budując zespół trzeba określić, ile osób i o jakich kompetencjach będzie potrzebnych, dlatego określiliśmy średnie możliwości zespołu testowego dodając 15% jako bufor bezpieczeństwa.
Początkowym etapem pracy z Jirą było stworzenie odpowiednich zadań dla zespołu programistycznego. Zadania te zostały opracowane na podstawie stworzonej przez analityków biznesowych i zatwierdzonej przez klienta dokumentacji, opisującej działanie poszczególnych funkcjonalności składających się na aplikację. Dokumentacja (FD – specyfikacja funkcjonalna, HLD, LLD – wysoko i niskopoziomowa koncepcja rozwiązania) została rozbita przez zespół analityków na konkretne zadania (taski) które należy zaimplementować.
Kolejny etapem było pokrycie stworzonych dla programistów zadań odpowiednimi przypadkami testowymi (test cases). Każda z testowanych funkcjonalność otrzymała odpowiednie listy rozwijane w Jirze w celu ich późniejszego łatwiejszego odnalezienia, a także łatwego zobrazowania progresu podczas wykonywania testów i odnalezienia potencjalnie najbardziej narażonego na błędy i regresje obszaru.
W zależności od projektu i ustawień Jiry testy można podzielić na wiele różnych sposobów. My na przykład w stworzonym obiekcie przypadku testowego używając listy rozwijanej pojedynczego wyboru przyjęliśmy podział na testy:
- funkcjonalne – czyli te, które zostały zaprojektowane na podstawie dostarczonej dokumentacji działania wdrażanego systemu,
- niefunkcjonalne – czyli te, które nie są związane bezpośrednio z daną funkcjonalnością, ale określają jak działa. W naszym przypadku były to: testy jednostkowe, wydajnościowe, testy bezpieczeństwa.
Zastosowaliśmy również podział na przypadki testowe:
- pozytywne – sprawdzające tak zwaną poprawną ścieżkę (happy path) działania aplikacji, zakładającą, że użytkownik wykona kroki zgodnie z założeniami i działaniem systemu,
- negatywne – sprawdzające ścieżkę, w której użytkownik celowo lub przypadkowo próbuje użyć aplikacji w sposób do tego nie przeznaczony. Dzięki testom negatywnym możliwe było stworzenie systemu bardziej odpornego na nieprawidłowe działania użytkownika – nie tylko te zamierzone i zgodne z dokumentacją,
- UX/UI – testy sprawdzające użyteczność i funkcjonalność systemu, a także design nowo zaprojektowanej aplikacji.
Testy zostały również podzielone na:
- Manualne – testy, które wykonane zostały przez testerów w sposób tradycyjny, odwzorowujący pracę użytkownika i sprawdzające funkcjonalność aplikacji.
- Automatyczne – zostały wybrane na podstawie zaprojektowanych testów manualnych – naszym celem było skupienie się na przyrostowej automatyzacji krytycznych testów. Już w początkowej fazie projektu zostały określone przedziały ilościowe, które powinny zostać pokryte automatyzacją by mogły być użyte w testach regresji kolejnych cykli wdrażania aplikacji.
Ponieważ część testów należało wykonać na fizycznych urządzeniach, użyliśmy do ich oznaczenia funkcji etykiety (labelki), dzięki czemu łatwo je było namierzyć. Etykiety w Jirze to coś na kształt popularnych „tagów”, które można dodać do każdego obiektu. Opcja etykiet w Jirze jest bardzo przydatna ze względu na swą elastyczność i brak konieczności wcześniejszej konfiguracji (każdy może stworzyć nową i jej używać) i w zasadzie w mniejszych projektach można przy ich użyciu łatwo ‘poukładać’ cały projekt.
Jednakże to, co w niektórych przypadkach jest zaletą w dużych projektach może stać się wadą. Ponieważ etykiety nie są z góry określone i każdy użytkownik może dopisywać swoje (a system rozróżnia duże i małe litery) to możemy spotkać się z sytuacją, że niektóre pozycje mogą zostać nazwane przez użytkowników synonimami, co może wprowadzić chaos i być trudne do opanowania czy posprzątania. Nie ma również możliwości określenia etykiet jako pól wymaganych, co w przypadku gdy chcemy, aby dane informacje znalazły się w stworzonym obiekcie jest bardzo przydatne. Dlatego etykiety są funkcją wspomagającą, ale nie powinno się na nich nie opierać całego projektu.
Przypadkom testowym, które zaprojektowaliśmy zostały nadane odpowiednie priorytety od niskich (P4), przez średnie i wysokie, aż do krytycznych (P1). Dzięki takiemu oznaczeniu łatwiej było nam wskazać potrzebne do zautomatyzowania testy, a także w przypadku ryzyka związanego z małą ilością czasu łatwiej wybrać testy które można by ewentualnie pominąć lub przełożyć na później.
Priorytetyzacja testów:

Wszystkie pola, które wymieniono powyżej ustawiliśmy jako wymagane, a parametr dla priorytetu testu został wstępnie ustawiony na medium. Jako że w projekcie nie mieliśmy dostępnych wtyczek wspomagających wykonywanie testów, takich jak Zephyr czy TestFLO, zdecydowaliśmy się na konkretny szablon dla przypadków testowych, który wyglądał następująco:
W miejscu opisu umieściliśmy pola:
- Warunek wstępny (precondition) – zawiera wszystkie warunki, które muszą być spełnione przed wykonaniem przypadku testowego.
- Kroki testowe (test steps) – opisują, co jest przedmiotem testu i jakie akcje krok po kroku należy wykonać do jego poprawnego wykonania. Opis powinien być wykonany w taki sposób żeby każda osoba nawet bez wiedzy o systemie była w stanie go zrealizować. Jeśli to konieczne powinna znaleźć się informacja o wykorzystanych lub potrzebnych do realizacji danych.
- Oczekiwany rezultat (expected result) dla każdego kroku – mówi o tym jakie powinno być prawidłowe zachowanie aplikacji. Tester weryfikuje czy wykonany krok/test ma ostateczny status zaliczony (pass) lub niezaliczony (fail).
Wszystkie przypadki testowej po ich napisaniu przez zespół testowy były zatwierdzone wewnętrznie przez analityków biznesowych następnie komunikowane do klienta i przez niego zatwierdzane przed rozpoczęciem wykonywania testów.
Przypadki testowe opisane zostały przez następujący workflow:
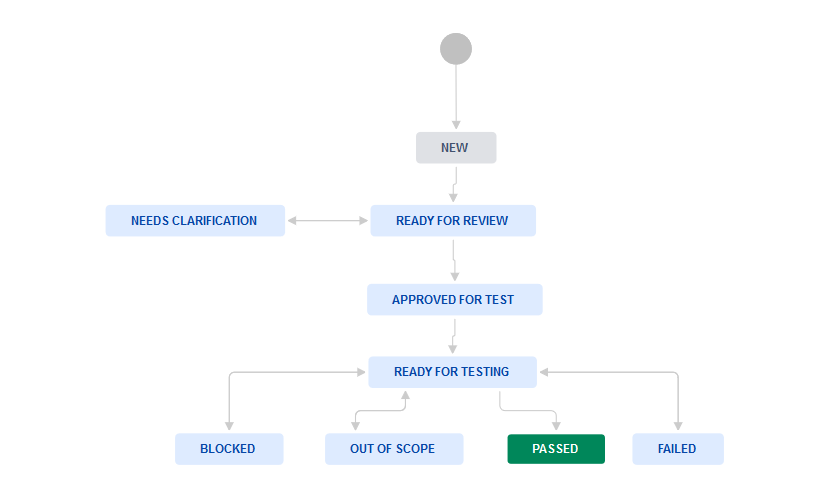
Jeśli test, który wykonujemy nie działa tak jak zakładano w dokumentacji i wynik testu został ustawiony na failed, należy do niego zgłosić i podpiąć defekt.
Wykonanie testów zaplanowano w trzech cyklach testowych:
Cykl 1:
- zaplanowanie i zatwierdzenie 100% przypadków testowych,
- wykonanie wszystkich testów zaplanowanych w tym cyklu zakończonych pass lub fail (na koniec cyklu nie wolno zostawić żadnego przypadku w statusie: in progress, tbd czy blocked). Celem było wykonanie 100% testów i znalezienie jak największej ilości defektów,
- wszystkie defekty z najwyższymi priorytetami 1 i 2 musiały zostać zakomunikowane zespołowi programistów, następnie naprawione i zamknięte (ponownie przetestowane) w tej fazie,
- status z efektów pracy na bieżąco monitorowany przy użyciu dashboardów w Jirze i raportów tygodniowych, a także raportu końcowego na koniec cyklu.
Cykl 2:
- ponowna egzekucja 70% testów wykonanych w cyklu 1 (w tym wszystkich testów, które zakończyły się niepowodzeniem w poprzednim cyklu plus dopełnienie pozostałymi testami celem uzupełnienia regresji z pierwszeństwem tych, które były powiązane ze stworzonymi defektami),
- poza testami powiązanymi z defektami pozostała część zakresu cyklu drugiego powinny być w pierwszeństwie testy z priorytetami 1 i 2 – wykonanie może odbywać się w sposób automatyczny,
- wykonanie wszystkich testów zaplanowanych w tym cyklu zakończonych pass lub fail,
- ponowne przetestowanie i zamknięcie błędów naprawionych przez programistów,
- status z efektów pracy na bieżąco monitorowany przy użyciu dashboardów w Jirze i raportów tygodniowych, a także raportu końcowego na koniec cyklu,
- zakomunikowane klientowi terminu wdrożenia na środowisko SIT i wybranie wersji, która zostanie dostarczona,
- Dostarczenie poprawionych defektów na środowisko testowe i SIT w kontrolowany sposób.
Cykl 3:
- ponowne wykonanie 100% zaprojektowanych testów jako kombinacja testów manualnych i zautomatyzowanych,
- wykonanie wszystkich testów zaplanowanych w tym cyklu zakończonych pass lub fail,
- ponowne przetestowanie i zamknięcie błędów naprawionych przez programistów,
- status z efektów pracy na bieżąco monitorowany przy użyciu dashboardów w JIrze i raportów tygodniowych, a także raportu końcowego na koniec cyklu,
- zakomunikowane klientowi terminu wdrożenia na środowisko SIT i wybranie wersji która zostanie dostarczona,
- dostarczenie poprawionych defektów na środowisko testowe i SIT w kontrolowany sposób,
- poinformowanie klienta o niezamkniętych defektów z priorytetem 3 i 4 (jeśli jakieś zostaną),
- stworzenie dokumentu podsumowującego wszystkie cykle przeprowadzonych testów, a także potwierdzenie spełnienia wszystkich kryteriów zamknięcia procesu testowego.
Celem zachowania historii wykonań wszystkie kolejne cykle były kopiami poprzednich. Każdy z zaprojektowanych przypadków testowych został przed rozpoczęciem cyklu przypisany do odpowiedzialnego za niego testera wraz z ustaleniem daty zakończenia jego wykonania. Jako dowód wykonania testu po jego wykonaniu należało dołączyć załącznik w postaci zrzutu ekranu końcowej weryfikacji w aplikacji.
Jako, że nieodłącznym efektem testowania są wykrywane przez zespół testowy defekty systemu, skonfigurowaliśmy odpowiednio Jirę pod kątem zarządzania zgłoszonymi błędami. Niezależnie od priorytetu, a także zapewnień programistów na temat łatwości poprawy defektu zasadą jest, że każdy jeden musi być odpowiednio zaraportowany w narzędziu do jego zarządzania.
Należy unikać zgłaszania problemów mailem, na komunikatorze czy bezpośrednio do programistów bez umieszczania ich w systemie, gdyż może to powodować zapomnienie o naprawieniu czy ponownym przetestowaniu danego błędu. Nie polecam również stosowania Excela jako narzędzia do zarządzania błędami, gdyż mimo, że nadaje się on praktycznie do wszystkiego to dedykowane narzędzia na pewno wspomoże skuteczniej i usprawni pracę.
Zgodnie z szablonem, który zaproponowaliśmy na potrzeby projektu zaraportowany defekt zawierał:
- numer wersji oprogramowania, w której został wykryty,
- funkcjonalność/aplikacja której błąd dotyczy,
- cykl, w którym był wykonany,
- osoba, do której defekt jest przypisany. Jako, że Jira nie oferuje możliwości przypisania defektu do kilku osób lub całego zespołu/grupy rozdzieliliśmy przypisania po liderach zespołów: programistów, analityków biznesowych, infrastruktury itd, a oni wybierali konkretną osobę która zajęła się rozwiązaniem problemu,
- priorytetu od 1-5 (opis poniżej),
- analizy przyczyny wystąpienia błędu (Root cause). Przykładowe: błędne zaprojektowanie aplikacji, błąd w kodzie, konfiguracja, dane, środowisko itp.,
- czasu, w którym deweloperzy zobowiązują się dostarczy naprawienia defektu i przekazania do ponownego testu,
- link – połączenie z powiązanym przypadkiem testowym,
- zrzut ekranu, jeśli potrzebny i możliwy,
- log z aplikacji, jeśli potrzebny i możliwy,
- środowisko na jakim wykryty został defekt,
- etykiety, w której np. można zaznaczyć, że błąd dotyczy danych historycznych itp.
- tytuł, który precyzyjnie opisuje problem, którego rozwinięcie znajdziemy w raportowanym defekcie. Tytuł powinien zawierać podsumowanie, streszczenie błędu na tyle na ile to możliwe. Powinien on być jak najbardziej czytelny i precyzyjny.
- opis defektu zawierający:
- kroki, które zostały wykonane lub należy wykonać by defekt odtworzyć (steps to recreate),
- rezultat, który oczekiwaliśmy po wykonaniu tych kroków (expected result),
- rezultat, który otrzymaliśmy w wyniku aktualnego działania aplikacji (actual result).
Priorytety defektów zostały nadane zgodnie z wytycznymi:

Wszystkie defekty funkcjonalne były przeglądane i zatwierdzane przez analityków biznesowych i przekazywane do zespołu programistów. Defekty, które zostały odrzucone podlegały ponownej analizie i zamykane jeśli uznano, że zostały błędnie zgłoszone.
Defekty, które zostały uznane za zmiany w oprogramowaniu (change request) były opisywane ze szczegółowymi wyjaśnieniami i otrzymywały odpowiednia etykietę, a także wymagały konsultacji i poinformowanie klienta.
Defekty zgłaszane przez klienta w fazie SIT/UAT po zatwierdzeniu przez analityków biznesowych również były konwertowane i raportowane w powyższym szablonie. Następnie po zaimplementowaniu ponowne sprawdzenia odbywały się po stronie zespołu testowego Accenture na środowisku testowym i po pozytywnym zatwierdzeniu zostały przekazywane na środowisko klienta.
Defekty rozwiązywane zostały przez następujący workflow:
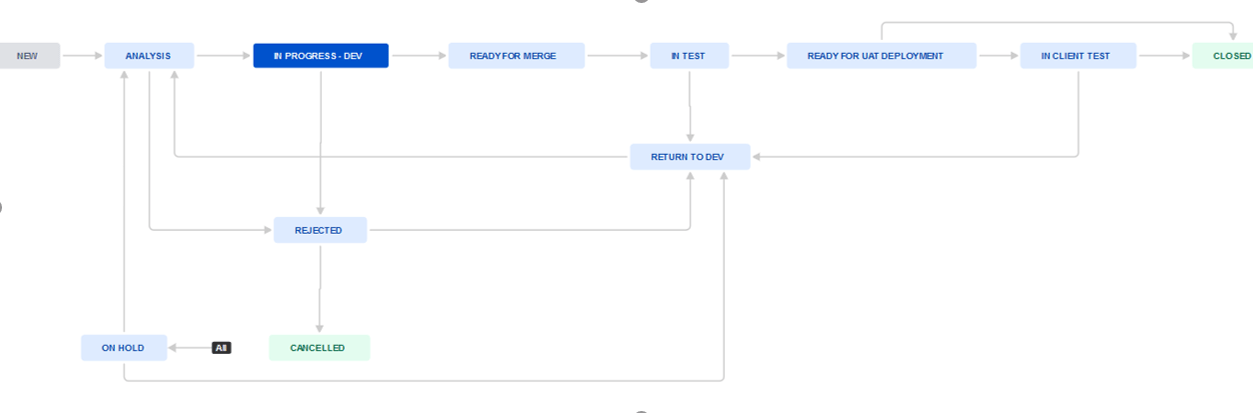
Konfigurowalne pulpity (dashboards) w Jirze, na których można umieszczać wykresy i statystyki zostały wykorzystane zarówno do prezentacji i pomiarów wykonania przypadków testowych, jak i przedstawienia i łatwiejszego odnalezienia zgłoszonych defektów aplikacji. Do monitorowania aktualnego wykonania testów w każdym cyklu użyto głównie wykresów kołowych, ograniczonych odpowiednio skonfigurowanymi filtrami. Na osobnych pulpitach pokazano status każdego kolejnego cyklu i bieżącego wykonania w zależności od funkcjonalność i statusów końcowych wykonanych przypadków testowych.
Zastosowano również wykresy dwuwymiarowe (Two Dimensional Filter) z określeniem osi X i Y dzięki czemu na jednym wykresie można było np. pokazać wykonanie testów dla danej funkcjonalności, a także status przypadków testowych. Dzięki wizualizacji przypisanych zadań dla poszczególnych testerów staraliśmy się odciążać osoby z największą ilością pozostałych do wykonania zadań.
Monitoring stanu zaraportowanych defektów również odbywał się głównie dzięki zastosowaniu wykresów kołowych i dwuwymiarowych pokazujących np. liczbę błędów o priorytecie krytycznym lub wysokim, które należało naprawić przed końcem danego cyklu. Wspomagaliśmy się również wykresem pokazującym ilość otwartych i zamkniętych defektów (Created vs. Resolved Chart) w danym przedziale czasowym.
Podsumowanie
Opisany powyżej przykład dotyczył jednego z projektów realizowanych przez Accenture z wykorzystaniem dostępnych środków i możliwości w danym czasie, a także wymagań klienta. Nie traktowałbym tego rozwiązania jako złotego środka możliwego do stosowanego dla wszystkich projektów, gdyż zgodnie z definicją PMI (Project Management Institute) każdy “projekt to jednorazowe przedsięwzięcie podejmowane w celu wytworzenia unikalnego produktu lub dostarczenia unikalnej usługi” – dlatego powinno być traktowane i rozwiązywane unikatowo.
W Accenture zwykło się mówić: ‘wszystko zależy od projektu’ – dlatego do każdego rozwiązania podchodzimy indywidualnie wykorzystując różne metodyki i narzędzia, aczkolwiek opisane rozwiązanie może być jednym z przykładów zastosowania Jiry i niektórych z jej możliwości jako narzędzia do zarządzania procesem testowym.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Jak budować efektywną strategię QA i usprawnić współpracę na linii Dev-QA

Czy QA to nadal drzwi do IT i co rynek „gotuje” testerom? Wywiad z Jakubem Klechem

Pair testing: jak developerzy i testerzy wspólnie dbają o jakość

Jako twórcy aplikacji mało wiemy o odbiorcach. O użyteczności i dostępności w IT

Klienci chcą rozwiązań problemów, a nie fajerwerków. O zjawisku overengineeringu

Zmienił się apetyt na ryzyko. Organizacje w końcu kładą nacisk na budowę kultury jakości

Automatyzuj przewidywalną część pracy. Zaoszczędzony czas poświęć na dogłębną analizę kodu
