Scope Management w architekturze Javy

Scope jest jednym z podstawowych elementów programowania. Mamy z nim do czynienia na co dzień. Z mojego doświadczenia w roli zarówno developera, jak i architekta wynika, że to decyzje podjęte w jego zakresie wpływają zazwyczaj w dużej mierze na techniczną jakość projektu – na podatności na zmiany wymagań oraz szybkość refaktoringu. Na możliwość zarządzania długiem technicznym oraz na koszty związane z utrzymaniem oprogramowania. Chciałbym podzielić się swoimi spostrzeżeniami oraz dobrymi praktykami i pokazać, w jaki sposób zarządzanie zasięgiem może nam pomóc w wypracowaniu elastycznej i wygodnej w pracy architektury.

Sławomir Dymitrow. Systems Architect / Lead Developer w Brown Brothers Harriman. Ponad dziesięć lat doświadczenia w projektowaniu i pisaniu aplikacji w ekosystemie Javy nauczyło go, że architekt który nie koduje jest jak bibliotekarz, który nie czyta książek. Pomimo coraz szerszego zakresu obowiązków pozostaje wierny swojemu prawdziwemu powołaniu i, starając się dochować wierności zasadom „leadership by example” (szczególnie w zakresie dostarczania kodu), wymaga od siebie więcej niż od deweloperów, z którymi współpracuje. Aktywnie działa w kręgach Open Source i stawia na pragmatyczne rozwiązania. Prywatnie jest miłośnikiem dobrej muzyki i gamingu.
Spis treści
Ziemia niczyja
Czym jest scope? Termin ten ma w programowaniu wiele znaczeń i jeszcze więcej odcieni. Skupmy się jednak na zrozumieniu tego terminu w kontekście języków obiektowych. W takim wypadku jest on jednym z podstawowych mechanizmów gwarantujących enkapsulację. Korzystamy z niego za każdym razem, gdy tworzymy nową klasę, metodę, czy pole.
Czy z zarządzaniem zasięgiem wiążą się jakieś trudności? Bardzo dobrze radzimy sobie z tym w mikroskali – wiemy kiedy element ma być private, kiedy public, a kiedy protected. W przypadku pól, metod i klas wewnętrznych (nested class) wynika to najczęściej z naszych bieżących potrzeb. Public to publiczne API. Protected, (ewentualnie package-private – choć to rzadziej) przydaje się gdy chcemy użyć polimorfii i/lub dostać się do implementacji klasy bazowej z klas pochodnych. Private zaś oznacza, że nie chcemy się z nikim dzielić wewnętrzną logiką danej funkcjonalności. W przypadku tradycyjnych klas zazwyczaj pozostajemy przy tym, co generuje nasze IDE, czyli public.
W makroskali również nie sprawia nam większego kłopotu. W przypadku aplikacji monolitycznych wrzucamy wszystko do jednego „słoja” i staramy się nie dać zwariować poprzez konwencje nazewnicze i żonglerkę pakietami. W przypadku mikro-serwisów możemy posłużyć się tak sprawdzonymi metodykami, jak choćby zdefiniowane Bounded Contextów (DDD) i podział w stylu 1 serwis = 1 BC.
Niektórzy stosują również dosyć ekstremalne (według mnie) podejście, gdzie każdy niemal feature otrzymuje swój własny serwis. Nie zmienia to faktu, że istnieją w środowisku praktyki i podejścia, które możemy naśladować i dostosowywać do swoich potrzeb. Ich zasady są dość jasno określone, a granice widoczne. Wszelkie ich przekroczenie jesteśmy w stanie w miarę łatwo wyłapać choćby podczas Code Review.
Czy jest jeszcze jakaś inna skala? Coś pośredniego pomiędzy mikro i makro? Jest. Co więcej, to właśnie z nią mamy zazwyczaj największy problem. Jest to prawdziwa „ziemia niczyja”. Nie ma tu praktycznie żadnego sformalizowanego zestawu dobrych praktyk. Każdy jest tu sobie szeryfem i każdy stara się wypracować swój własny zestaw dobrych praktyk.
Czy w tej skali również da się wprowadzić jakieś ogólne, uniwersalne zasady? Takie, które znalazłyby zastosowanie w zdecydowanej większości przypadków, upraszczając przy tym życie deweloperów i architektów, i chroniąc ich przed kosztownymi błędami projektowymi, których naprawa po pewnym czasie staje się nieopłacalna ze względu na rozmiar koniecznej refaktoryzacji? W swojej dotychczasowej karierze programisty oraz architekta przechodziłem przez wiele etapów fascynacji różnymi metodykami, wzorcami oraz frameworkami.
Wielokrotnie próbowałem stworzyć czy to zestaw zasad, czy też framework, który okaże się odpowiedzią na powyższe pytania. Próbowałem stosować dobrze opisane praktyki, o których napisano całe książki i które posiadają złożone zestawy zasad oraz rozbudowaną nomenklaturę, takie jak DDD, CQRS czy Event Sourcing.
Czy doszedłem do jakichś wniosków? Tak, do dwóch:
- Najprostsze rozwiązania są najlepsze.
- Java posiada wbudowane rozwiązania, które odpowiednio zastosowane może pomóc nam w rozwiązywaniu wyżej nakreślonych problemów.
Odrobina prywatności
Gdy tworzymy nową klasę Javy, jaki jest jej domyślny zasięg? Jeżeli (tak jak zdecydowana większość deweloperów) korzystamy z pomocy IDE, klasa zapewne będzie publiczna. Jesteśmy przyzwyczajeni do konwencji 1 plik *.java = 1 publiczna klasa. Każdy tak robi. Jaki jest jednak rzeczywisty domyślny zasięg klas w Javie? Oczywiście jest to zasięg pakietowy (package scope – bez modyfikatora zasięgu). Czyżby twórcy Javy chcieli nam w ten sposób coś przekazać? Oracle w oficjalnej dokumentacji radzi: „Use the most restrictive access level that makes sense for a particular member. Use private unless you have a good reason not to.” Każdy deweloper wie, że należy używać możliwie jak najbardziej restrykcyjnych ograniczeń dostępu – dotyczy to również dostępu pakietowego w kontekście naszych klas.
No dobrze, ale w jaki praktyczny sposób mogę wykorzystać dostęp pakietowy w moim kodzie? Przecież to oznaczałoby, że wszystkie klasy muszę trzymać w jednym pakiecie, a ja lubię mieć rozbudowaną hierarchię pakietów. Sam przez bardzo długi czas nie potrafiłem przejść do porządku nad w/w problemem. Niemal każda klasa w moim kodzie lądowała w osobnym, odpowiednio nazwanym pakiecie. Miałem wtedy poczucie wprowadzania porządku i z góry określonej konwencji. W pewnym momencie zadałem sobie jednak pytanie – co jest ważniejsze? Czy raczej powinienem dostosować widoczność komponentów do mojej filozofii pakietów, czy może odwrotnie – powinienem dostosować hierarchię klas i pakietów do tego, aby zachować jak najbardziej restrykcyjny dostęp.
Okazało się, że da się pogodzić te dwie sprawy i uzyskać spójną, uniwersalną i czytelną metodykę. Zanim jednak przejdziemy do przykładów, chciałbym poruszyć problem który stanowi niejako drugi filar podpierający proponowane przeze mnie rozwiązania.
Frontem do klienta
Czym jest API? Jest to oczywiście zestaw operacji publicznie dostępny dla klientów danego elementu. Niniejszy artykuł traktuje o skali pośredniej, więc zarówno API pojedynczych klas, jak i całych serwisów odłóżmy na inną okazję i skupmy się na API modułów. Pojęcie „modułu” doskonale wpasowuje się w omawiany temat, gdyż jest to najmniej sformalizowana jednostka porządkowa w architekturze.
Wprawdzie Java z numerem 9 wprowadziła w nasz świat moduły za sprawą projektu Jigsaw, lecz nie rozwiązują one problemów nakreślonych przeze mnie. Jigsaw służy przede wszystkim do zmodularyzowania samego JDK, a jego zastosowania docenić mogą przede wszystkim twórcy bibliotek oraz kodu reużywalnego, z dużą ilością klientów. Klasyczne aplikacje biznesowe niespecjalnie są w stanie wykorzystać moc modułów w celu poprawy jakości architektury.
Czym w takim razie mógłby być nasz moduł? W moim świecie moduł jest grupą operacji, które wykonuję na danym zestawie obiektów lub danych (modelu domenowym). Klasycznym przykładem może tu być zarządzanie użytkownikami w systemie: użytkownika możemy stworzyć, edytować, usunąć, pobrać listę użytkowników, pobrać szczegóły danego użytkownika, przypisać użytkownikowi rolę w systemie bądź mu ją odebrać. Stwórzmy więc sobie na początek puste API, które będzie nam służyło do zarządzania użytkownikami:
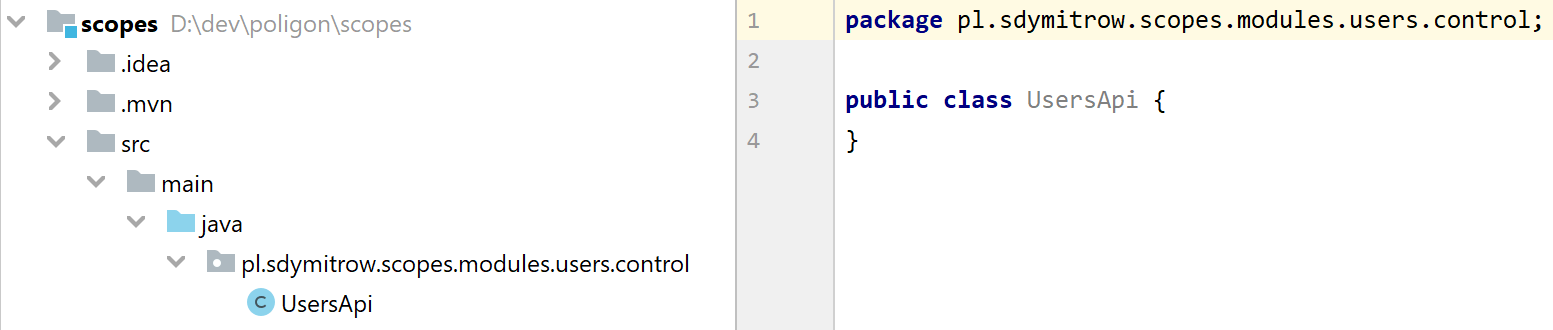
Stwórzmy również zalążek naszych testów, które udowodnią, że nasz kod działa zgodnie z wymaganiami:
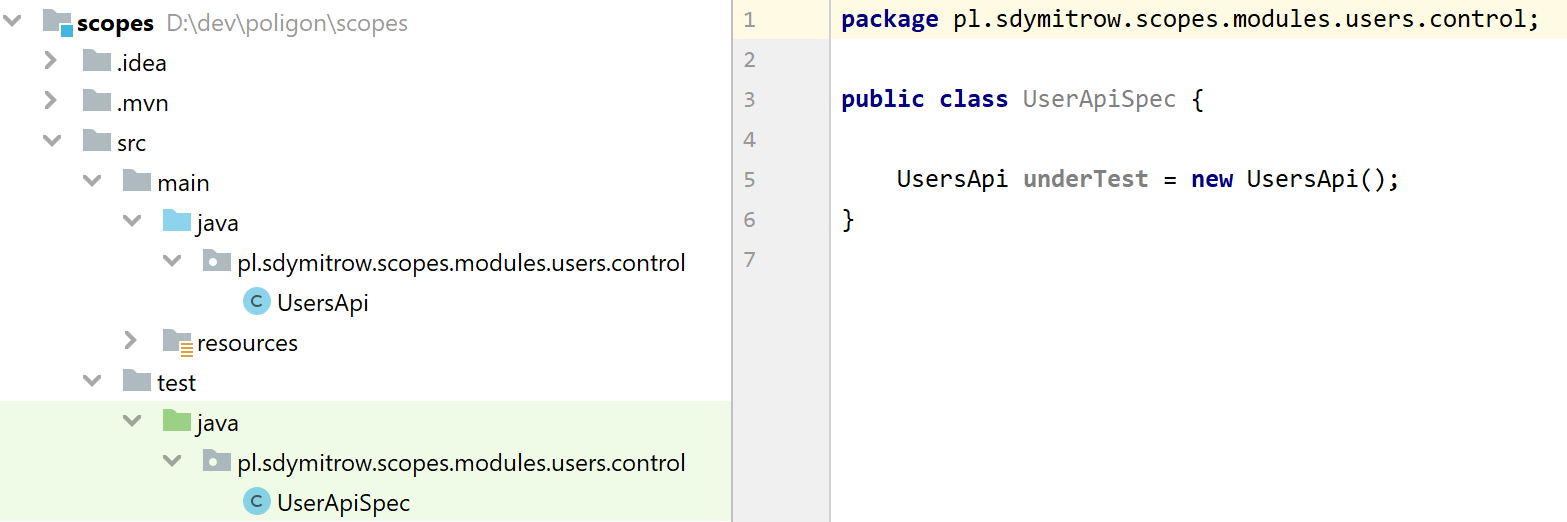
Pierwszą funkcjonalnością, jaką chcielibyśmy zapewne posiadać w naszym API jest możliwość stworzenia nowego użytkownika:

Oczywiście nasz test w chwili obecnej zakończy się niepowodzeniem, gdyż nie mamy jeszcze implementacji:

Przystąpmy zatem do jej wykonania. Nasza klasa API posłuży nam w tym momencie jako Fasada. Jest to jeden z najstarszych i nieco już zapomnianych wzorców projektowych. Pomimo swojego wieku świetnie się jednak nadaje do naszych celów. Będzie delegował właściwą pracę do klas zawierających implementację:

Zobaczmy więc jak wygląda nasz UserCreator:

Zauważyliście, że zarówno klasa UserCreator, jak i metoda create() są w zasięgu pakietowym? Jest to implementacja naszego modułu i jako taka nie powinna być widoczna nigdzie poza samym modułem. Logika ta, pomimo umieszczenia w osobnej klasie (i pliku), usadowiona została w tym samym pakiecie co API. Dzięki temu nasz moduł ma tylko jedną drogę wejściową. Wszelkie operacje jakie chcemy wykonać na użytkownikach siłą rzeczy muszą przejść przez nasze publiczne UsersApi. Z czasem ilość klas zapewniających implementację będzie rosnąć. Nie ma w tym absolutnie nic złego.
Każda odpowiednio nazwana klasa implementacyjna będzie spełniała jedną funkcję (SRP) i będzie dostarczała naszemu API implementacji. Na jeden moduł (będący jak już wspomnieliśmy logiczną jednostką łączącą związane ze sobą operacje) powinna przypadać jedna publiczna klasa z publicznym API, będąca jedynym punktem wejściowym do zawartej w module logiki biznesowej. W bardziej złożonych przypadkach może to wyglądać tak:
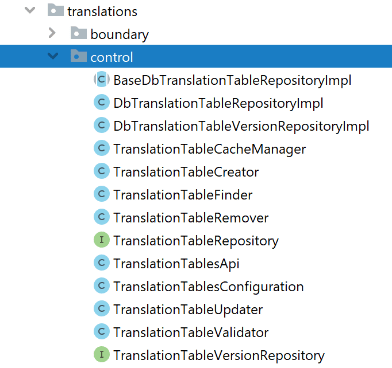
Ale tu są pomieszane klasy o różnym przeznaczeniu – repozytoria, walidatory itp. To prawda. Czy naprawdę jest w tym coś złego (oprócz pogwałcenia naszych przyzwyczajeń)? Cała logika biznesowa danego modułu jest w jednym miejscu, a konwencje nazewnicze klas pozwalają na bezproblemową nawigację po takim kodzie.
A co jeśli tej logiki jest naprawdę dużo? W takim wypadku jeden moduł można zawsze podzielić na kilka mniejszych, lub wydzielić pod-moduły (komunikujące się ze sobą poprzez swoje publiczne klasy API):
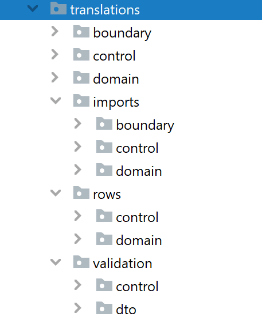
Ogromną wartością dodaną takiego rozwiązania jest porządek w publicznej przestrzeni nazw. Chcąc odwołać się do jakiegoś modułu wszelkiej maści IDE konsekwentnie ignorować będą klasy z dostępem pakietowym, pokazując jako dostępne tylko publiczne API.
Oczywiście rzeczywista implementacja będzie bardziej skomplikowana. Nic nie stoi na przeszkodzie, aby na przykład implementację zapisywania użytkowników przenieść do dedykowanego Repozytorium:


A następnie przygotować dwie implementacje – produkcyjną (testowaną integracyjnie, znajdującą się w kodzie produkcyjnym) oraz testową (testowaną jednostkowo, znajdującą się w kodzie testowym):

Instancjonując klasę UsersApi produkcyjnie użyjemy produkcyjnej implementacji:

Instancjonując ją do testów użyjemy testowej implementacji:

Przykład podany powyżej jest uproszczony na potrzeby artykułu. Przedstawia on jednak bardzo uniwersalny i praktyczny wzorzec, który daje się zastosować w o wiele bardziej skomplikowanych – i niekoniecznie CRUDowych – aplikacjach. Sam korzystam z niego namiętnie jako z podstawowego budulca moich aplikacji i rezultaty są bardzo zadowalające.
Jednym z wyznaczników dobrej architektury jest według mnie jej powtarzalność. W idealnym przypadku patrząc na dużą aplikację tworzoną przez cały zespół programistów obserwator powinien odnieść wrażenie, że aplikacja została napisana przez jedną osobę. Nauczenie się nawigowania po jednym module powinno pozwolić na nawigację po całej aplikacji, bez względu na jej rozmiar.
Zauważyliście zapewne, że w powyższym przykładzie nie testujemy klasy UserCreator bezpośrednio. Testy jednostkowe to następny element układanki, który bardzo dobrze wpasowuje się w całokształt zarządzania zasięgiem w architekturze.
Wszyscy jesteśmy jednostkami
Zastanówmy się nad definicją „jednostki” w wyrażeniu „testy jednostkowe”. Istnieją różne typy testów automatycznych – mamy testy jednostkowe, integracyjne, funkcjonalne, akceptacyjne i wiele innych. Jedną z podstawowych różnic między nimi jest właśnie zasięg testowanego kodu. Większość deweloperów utożsamia testy jednostkowe z testami najniższego poziomu, sprawdzającymi pojedyncze klasy. W takim przypadku jednostką jest klasa. Czy jest to jednak podejście dobre?
Aby odpowiedzieć na to pytanie, zastanówmy się czemu właściwie mają służyć testy automatyczne w naszym kodzie. Wg mnie ich dwa podstawowe cele to:
1. Udowodnienie, że aplikacja została zaimplementowana zgodnie z wymaganiami biznesowymi.
Aplikacja nigdy nie jest pisana w próżni. Zawsze jest jakiś biznesowy kontekst i jest (a przynajmniej powinna być) osoba definiująca wymagania. Testy potwierdzają nam, że wymagania zostały spełnione i aplikacja zachowuje się poprawnie w różnych scenariuszach, włączając zwłaszcza te brzegowe.
2. Ochrona aplikacji przed regresjami związanymi z ciągłym rozwojem lub naprawą błędów.
Testy dają nam poczucie bezpieczeństwa i odwagę w dokonywaniu zmian w kodzie. Mamy pewność, że jeżeli spowodujemy jakieś przypadkowe, niezamierzone zmiany, nasze testy to wychwycą i nie pozwolą na wprowadzenie do produkcji wadliwego produktu.
Czy samo posiadanie w kodzie testów automatycznych oraz wysoki poziom pokrycia gwarantują nam, że możemy czuć się bezpiecznie? W żadnym wypadku! Powiem więcej – jeżeli zdecydowana większość naszych testów to testy jednostkowe na poziomie klas, to najprawdopodobniej nie zabezpieczają one w wystarczającym stopniu przed regresją. Dlaczego?
Jak już powiedzieliśmy, nasz kod powinien być odzwierciedleniem wymagań biznesowych. Czy w jakimkolwiek biznesie znajdziemy więc pojęcie ‘klasy’ w rozumieniu czysto programistycznym? Raczej nie. Klasa jest dla biznesu czymś obcym. Jest to nasza wewnętrzna jednostka organizacyjna umożliwiająca podzielenie problemu na mniejsze części. Daje nam enkapsulację, abstrakcję oraz wpływa na reużywalność kodu. Nie ma ona jednak nic wspólnego z wymaganiami biznesowymi. Jest szczegółem implementacji. A implementacja, jak wiemy, może ulegać zmianom.
Wymagania biznesowe mają więc naturalnie zasięg większy niż pojedyncze klasy. Ponadto pomiędzy implementacją, a wymaganiami biznesowymi zachodzi następująca prawidłowość:
Zmiana wymagań biznesowych pociąga za sobą zmianę implementacji.
ALE
Zmiana implementacji niekoniecznie musi być spowodowana zmianą wymagań biznesowych.
Może ona być wynikiem refaktoringu, zmiany podejścia, naprawiania błędów, poprawiania wydajności, aktualizacji dependencji (np. zewnętrznych bibliotek). Jeżeli więc nasze testy automatyczne będą tkwiły na poziomie klas, to jakiekolwiek zmiany implementacji pociągną za sobą konieczność przeprowadzania zmian w testach. Testy, które są niejako „przyklejone” do konkretnych klas siłą rzeczy nie skupiają się na testowaniu wymagań, tylko na ich implementacji.
Może więc dość do kuriozalnej sytuacji, że pomimo braku zmiany wymagań, chęć prze-implementowania fragmentu kodu pociągnie za sobą konieczność prze-implementowania setek bądź nawet tysięcy testów. W takiej sytuacji ochrona przed regresją nie istnieje. Kod jest „zabetonowany” testami i jedyne co testy weryfikują to aktualną implementację. Aby przeciwdziałać takim sytuacjom oraz aby w rzeczywisty sposób chronić przed regresją, testy (a w szczególności asserty – miejsca, gdzie weryfikujemy poprawność testów) powinny być zmieniane w przypadku zmian w wymaganiach biznesowych. Żeby jednak to osiągnąć, testy takie (nawet jednostkowe!) powinny mieć odpowiedni zasięg. Zasięg większy niż klasa. Wg mnie odpowiednim zasięgiem dla testów jednostkowych jest moduł.
Ale zaraz! Przecież istnieją jeszcze testy integracyjne! Czy to nie one powinny odpowiadać za integrację pomiędzy klasami? W teorii tak. Testy integracyjne obarczone są jednak jedną bardzo istotną wadą: są wolne. Typowy test integracyjny wymaga postawienia kontekstu Springa, bazy danych w pamięci i często innych rzeczy, takich jak kolejki JMS. W idealnym świecie, gdybyśmy nie byli ograniczeni powolnością testów integracyjnych, nasz kod testowy powinien składać się tylko z nich. Niestety pójście tą drogą, pomimo że na początku może wydawać się kuszące, wraz z rozrostem aplikacji będzie coraz bardziej uciążliwe. W ekstremalnych przypadkach może dojść do sytuacji, gdzie build aplikacji będzie trwał 40 minut (lub więcej) i pełny test suite będzie uruchamiany tylko na serwerze CI.
Testy jednostkowe na poziomie modułu są najlepszym możliwym kompromisem. Zachowują się prawie tak jak testy integracyjne, a działają z nieporównanie większą szybkością. Dlaczego prawie? Kompromisem w tym przypadku jest konieczność rezygnacji z użycia I/O gdzie tylko się da. Rzeczywista (nawet in-memory) baza danych musi być w takim wypadku zastąpiona kolekcjami. Spójrzcie jeszcze raz na nasz przykładowy kod. W taki właśnie sposób można zastąpić prawdziwą bazę danych na potrzeby testów. W naszym przykładzie test, który napisaliśmy jest właśnie na poziomie API. Możemy dowolnie zmieniać implementację pod spodem i test będzie przechodził tak długo, jak nasze wymagania biznesowe są spełnione.
Takie podejście ma jeszcze jedną wartość dodaną – upewnia nas, że nasza logika nie polega na bazie w kwestii zapewnienia integralności danych. Wszelkiego rodzaju constrainty to rzecz mile widziana i pożyteczna, nie mniej jednak nasza aplikacja nie powinna polegać na założeniu, że w razie czego wyleci SQLException. Wszelkie walidacje powinny być wykonywane w naszym kodzie:
Czy wobec tego powinniśmy całkowicie odejść od klasycznych testów integracyjnych? Ależ nie. Klasyczne testy integracyjne jak najbardziej powinny być obecne w naszym kodzie – tyle że w rozsądnych ilościach, pozwalających na w miarę szybkie wykonanie kompletu testów. Z moich doświadczeń wynika, że odpowiednimi scenariuszami do pełnego testowania integracyjnego są:
- tzw. „happy path” – czyli pozytywny scenariusz pokazujący że wszystkie komponenty we wszystkich warstwach się „widzą” i działają ze sobą prawidłowo,
- miejsca, w których logika biznesowa w znacznym stopniu jest wyniesiona poza kod Javy – na przykład skomplikowane zapytania SQL, których mockowanie mija się z celem.
Czy w takim razie według Ciebie nie wolno nigdy testować na poziomie klasy? „Nigdy” i „zawsze” to pojęcia słabo pasujące do kodowania. Testy pojedynczych klas jak najbardziej mają swoje miejsce. Można z nich korzystać przy pisaniu tzw. utility. Często wypychamy różnego rodzaju logikę do klas *Util, które same w sobie nie są powiązane bezpośrednio z logiką biznesową i enkapsulują nam jakiś techniczny problem. Tego typu klasy jak najbardziej powinno testować się osobno, gdyż zwykle posiadają bardzo wiele przypadków użycia. Sprawdzenie ich wszystkich przy pomocy testów „modułowych” byłoby wysoce niepraktyczne.
Wiosna, ach to ty!
No dobrze, ale w jaki sposób połączyć to wszystko ze Springiem? Przecież nikt dzisiaj nie pisze kodu w samej, czystej Javie. Po to mamy kontenery Dependency Injection, żeby z nich korzystać. Pełna zgoda. Spring daje nam wiele fantastycznych możliwości i sam korzystam z niego, gdzie się da. Jego możliwości jednakowoż mogą stanowić źródło kolejnych problemów, jeżeli zbyt entuzjastycznie zaczniemy z nich korzystać.
Od czasu upopularnienia się kontenerów IoC przeważająca większość deweloperów z upodobaniem wrzuca wszystkie komponenty i serwisy do tego „wora” tak, aby można było się bez wszystko połączyć magicznym klejem (@Autowired) wiążącym aplikację w całość. Zwyczaj ten spopularyzowany został do tego stopnia, że posługiwanie się słowem kluczowym „new” w kontekście innym niż instancjonowanie DTOsów lub Encji stało się dla nas czymś rażącym, nieprzyjemnym i niesmacznym. Czy jednak słusznie? Czy wszystkie klasy, serwisy, repozytoria, fabryki, providery i inne cuda zasługują na to, by rejestrować je w kontenerze IoC?
Jak wiele innych, ta praktyka z początku wydaje się być synonimem wygody i elastyczności. Niestety na dłuższą metę zastawiamy sidła sami na siebie. Sidła cyklicznych zależności. „Ale jak to? Przecież Spring chroni nas przed cyklami! Nie jesteśmy w stanie stworzyć takich komponentów”:

Owszem, na poziomie kodu Spring chroni nas przed takimi rzeczami (chociaż jeżeli używamy jedynie słusznego wstrzykiwania przez konstruktor, to przed taką sytuacją chroni nas sama Java, gdyż nie będziemy w stanie zainstancjonować takich klas). Mnie jednak chodzi o cykle daleko bardziej niebezpiecznie, bo na pierwszy rzut oka niewidoczne i niegroźne. Mam na myśli cykle logiczne.
Czym jest cykl logiczny? Każdy z nas w jakiś sposób dzieli swoją aplikację na mniejsze części. W kontekście tego artykułu jednostką takiego podziału jest jak już wiemy moduł. Jeżeli w obrębie jednego modułu rejestrujemy w kontenerze IoC kilka publicznie dostępnych komponentów, to mając dwa takie moduły jesteśmy w stanie doprowadzić do następującej sytuacji:
Czy Spring zaprotestuje przeciwko stworzeniu takich relacji? Nie. Z czysto technicznego punktu widzenia wszystko jest ok. Czy jednak oznacza to, że nie mamy do czynienia z cyklem? Ależ mamy. Jest to cykliczna zależność pomiędzy naszymi własnymi jednostkami organizacyjnymi. Pamiętajmy, że nasza aplikacja będzie się stale rozwijać. Po jakimś czasie diagram zależności naszych komponentów będzie wyglądać podobnie do tego:
Czy takie cykliczne zależności są problematyczne? Są i to bardzo. Są piekłem dla każdego, kto próbuje zrefaktoryzować jakikolwiek większy kawałek kodu. W chwili, gdy będziemy chcieli usunąć, zmienić lub dodać nowy moduł może się okazać, że będziemy musieli przepisać sporą część naszej aplikacji.
Sytuacja przedstawiona powyżej obnaża jeszcze jeden, dość poważny problem: W miarę rozrastania się naszej aplikacji przestajemy kontrolować, co z czym jest powiązane i jak na dobrą sprawę powinno się konstruować instancje naszych serwisów. Owszem, jesteśmy w stanie ogarnąć fragmenty systemu. Jesteśmy również w stanie prześledzić konstrukcje pojedynczych komponentów. Całościowe ogarnięcie systemu umysłem przestaje być jednak możliwe. Jest to wg mnie bardzo niebezpieczna sytuacja i dość spora cena za „wygodne” korzystanie z adnotacji @Autowired.
No dobrze, czy jest na to jakiś sposób? Jest. Jedynym komponentem, jaki powinien być rejestrowany przez dany moduł w kontenerze DI jest jego publiczne API:

Wystarczy, że każdy moduł będzie wystawiał swoją klasę @Configuration, która będzie odpowiedzialna za dostarczenie do Springowego kontenera instancji danego API. Dzięki takiemu rozwiązaniu zyskamy dwie bezcenne rzeczy:
- Otwierając klasę
@Configurationdostaniemy jak na dłoni całą logikę niezbędną do stworzenia naszego API. Dopóki logiki nie ma zbyt dużo, może się to wydawać zbędne. Wraz z przybywaniem nowych funkcjonalności jednak okaże się to kluczowe dla długoterminowego utrzymania jakości kodu. Bardziej skomplikowane implementacje mogą wyglądać np. tak:

Na pierwszy rzut oka wygląda dość nieciekawie, prawda? Ma jednak ogromną przewagę nad stosowaniem @Autowired – pokazuje jak na dłoni w jaki sposób skonstruowany jest cały moduł. Pomyślmy też, że tak właśnie wygląda pod spodem instancjonowanie naszych serwisów – tylko jest to ukryte przez „magię” kontekstu Springa. Filozofia „co z oczu, to z serca” nie jest wg mnie najlepszym podejściem w takim przypadku.
- Trwale zabezpieczamy się przed wystąpieniem cyklicznych zależności pomiędzy naszymi logicznymi jednostkami organizacyjnymi. Jako, że jedynym komponentem wystawianym przez moduł jest jego API, wracamy do punktu w którym 2 API nie mogą zależeć od siebie nawzajem. Nasza architektura stanie się znacznie bardziej uporządkowana i podatna na refaktoring:

Jeżeli w przypadku powyżej chcielibyśmy nagle dodać zależność pomiędzy M1 i M3, Spring odmówi posłuszeństwa wykrywając cykliczną zależność.
Taka architektura może przynieść sporo wyzwań, gdyż takie ograniczenie może wymusić (i na 99% wymusi) głęboką analizę powiązań pomiędzy naszymi modułami. Oznacza do dodatkowy narzut na fazę planowania i wyklucza pisanie kodu „na ślepo”. Bardzo możliwe, że potrzeba będzie utworzenia modułów współdzielonych, które zawierać będą wspólne elementy logiki. Nie mniej warto zapłacić taką cenę na początku. To inwestycja zwracająca się z potężnym procentem w postaci porządku, czytelności i utrzymalności kodu, a także podatności na przyszły refaktoring.
A co z zewnętrznymi serwisami i dependencjami? – Zewnętrzne serwisy najlepiej trzymać poza modułami, w osobnej strukturze. Są to de facto jedyne klasy, w których powinniśmy używać adnotacji @Service:



To już jest koniec
Zdaję sobie sprawę, że przedstawione powyżej przemyślenia mogą być odebrane przez część z Was jako ekstremalne i to może odrzucić Was od próby wykorzystania ich w swoim kodzie. Czy twierdzę, że zaproponowana przeze mnie architektura jest jedyną słuszną drogą i nie istnieje żadna inna poprawna? Byłoby to bardzo aroganckie stwierdzenie. Nie znam wszystkich możliwych architektur i zdaję sobie sprawę z różnorodności naszych preferencji.
Jedyne co mogę stwierdzić to to, że dla mnie osobiście jest to najwygodniejsza i najprzyjemniejsza architektura z jaką do tej pory przyszło mi pracować. Jest ona owocem zarówno lat doświadczenia, głębokich przemyśleń, jak i słuchania ludzi dużo bardziej doświadczonych ode mnie. Jedną z takich osób, zasługujących na imienne wyróżnienie jest Jakub Nabrdalik. Jego wykłady i prelekcje wywarły ogromny wpływ na moje zrozumienie podstaw dobrej architektury w Javie. Wiele rozwiązań proponowanych w niniejszym artykule zainspirowanych jest właśnie w oparciu o jego idee. Jest swego rodzaju kompilacją dobrych praktyk, które poznałem podczas swojej pracy, a także podczas rozmów z kolegami po fachu i szkoleń, jakie mogłem odbyć.
Programiści cenią sobie wolność twórczą oraz swobodę w podejmowaniu decyzji projektowych. Z tego też powodu intencjonalnie starałem się w swoich przemyśleniach nie narzucać praktyk oraz nie tworzyć reguł tam, gdzie nie było to koniecznie. Żadne zasady i podręczniki nie zastąpią wyczucia i doświadczenia. Decyzje odnośnie nazewnictwa klas i pakietów, rozmiarów poszczególnych modułów czy wybór pomiędzy monolitem, a mikro-serwisami etc. – to wszystko powinno zostać w gestii osób zajmujących się konkretnymi przypadkami. Uważam, że rozwiązania zaproponowane w niniejszym artykule są w miarę uniwersalne i można dopasować je do niemal każdego scenariusza. Każdy na ich podstawie może zbudować swoją własną wersję „idealnej” architektury.
Lubię o sobie myśleć jako o osobie pragmatycznej. Nie wykorzystuję wzorców i praktyk dla idei i dlatego, że tak mów jakieś „święte prawo” kodowania w danym języku. Wykorzystuję rzeczy które są dla mnie wygodne i które dają mi poczucie bezpieczeństwa. Jeżeli więc przemówiły do Was przedstawione wyżej argumenty, zachęcam do sprawdzenia mojej architektury w praktyce. Jej motywem przewodnim jest łatwość w dokonywaniu zmian. Każdy doświadczony programista/architekt wie, że nie wszystkie decyzje projektowe są trafione, a kluczem jest niezamykanie sobie drogi do szybkiego i bezpiecznego refaktoringu.
Zasady, pomimo dość długiego artykułu, można streścić w kilku zwięzłych punktach:
1. Dzielimy logikę na logiczne moduły:
- Każdy moduł wystawia 1 publiczne API, które deleguje prace do swoich wewnętrznych komponentów, które nie są widoczne dla reszty aplikacji.
- W razie potrzeby dzielimy większe moduły na kilka mniejszych lub wydzielamy pod-moduły.
2. Moduły testujemy tylko z poziomu publicznego API:
- Testujemy wymagania biznesowe, nie implementację.
- Chcemy, aby nasza logika nie polegała na integralności bazy danych i innych zewnętrznych zależności.
3. Do każdego API tworzymy konfigurację rejestrującą to API w wybranym przez nas kontenerze IoC:
- W obrębie klasy konfiguracji komponenty API tworzymy za pomocą operatora „new”.
- Wszelkie zewnętrzne zależności API wstrzykujemy za pomocą naszego kontenera IoC.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Brown Brothers Harriman Sp z o.o. nie jest kapitałowo, ani w żaden inny sposób, powiązane z justjoin.it. Brown Brothers Harriman Sp z o.o. nie monitoruje treści zamieszczanych na stronie, ani też nie wpływa na zawartość strony, z wyjątkiem artykułów osobno oznaczonych jako pochodzące od pracowników.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
