Jak rozpoznać obiekty ze zdjęcia? Wystarczy te 10 linii kodu w Pythonie
Technologia rozpoznawania obrazów, choć popularność zdobyła dobre kilka lat temu, do dziś jest używana w wielu różnych dziedzinach. Od klasycznego wykorzystania, czyli rozpoznawania obiektów na kamerach przemysłowych, po autonomiczne pojazdy, które cały czas kontrolują i reagują na wszystko, co pojawia się na drodze. Jak widać, technologia ta nadal budzi zainteresowanie, dlatego przygotowaliśmy ten poradnik, w którym wyjaśniamy, jak rozpoznawać obiekty za pomocą 10 linii kodu w Pythonie.
Rozpoznawanie obrazów coraz bardziej przybliża sztuczną inteligencję do umiejętności, którymi na co dzień posługują się ludzie. Dzięki niej, program może rozpoznać, co widać na obrazku, ale też określić, czy jest to przedmiot, człowiek, czy zwierzę. Co dziś możemy rozpoznać za pomocą tej technologii?
Policja wykorzystuje ją do poszukiwania przestępców — analizuje filmy i zdjęcia, by przetworzyć pojawiające się na nich twarze. Najpierw rozpoznaje wyróżniające wartości, a później porównuje je z listą poszukiwanych osób. Jeśli któraś z twarzy ma podobne choć część elementów, może zostać uznana za podejrzaną.

Dzisiaj nie skupimy się jednak na specjalistycznym wykorzystaniu technologii rozpoznawania obrazu, ale na tej najprostszej formie, czyli rozpoznaniu, co jest na obrazie. Nie zaskoczy Was pewnie fakt, że wykorzystamy przygotowaną wcześniej bibliotekę, która zawiera więcej niż 10 linii kodu, ale sama implementacja nie powinna zająć więcej niż 10 linii.
Przełom w rozwoju technologii rozpoznawania obrazu nastąpił w 2012 roku, kiedy powstały takie algorytmy jak R-CNN, Fast-RCNN, Faster-RCNN, RetinaNet i takie dokładne algorytmy jak SSD i YOLO. Wykorzystanie tych metod i algorytmów, które zostały oparte o deep learning, wymaga zrozumienia, jak działają matematyczne i deep learningowe frameworki.
Moses i John Olafenwa także stanęli przed tym problemem i postanowili stworzyć pythonową bibliotekę ImageAI, która pozwala developerom na prostą implementację jej w programach i aplikacjach, wykorzystując do tego tylko kilka linii kodu.
Do implementacji ImageAI potrzebujemy:
1. Zainstalowania Pythona
2. Zainstalowania ImageAI
3. Pobrania przykładowego folderu o nazwie “Object Detection”
Zaczynamy zabawę w rozpoznawaniu obiektów!
1. Pobierz Pythona 3 z oficjalnej strony Pythona.
2. Zainstaluj za pośrednictwem pip:
– Tensorflow
pip install tensorflow
– Numpy
pip install numpy
– SciPy
pip install scipy
– OpenCV
pip install opencv-python
– Pillow
pip install pillow
– Matplotlib
pip install matplotlib
– H5py
pip install h5py
– Keras
pip install keras
– ImageAI
pip3 install
https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
3. Pobierz modelowy plik RetinaNet, który wykorzystamy do rozpoznawania obrazów, za pośrednictwem tego linku.
Jeśli wykonałeś powyższe kroki poprawnie, czas na pierwsze testy technologii rozpoznawania obrazu. Utwórz plik w Pythonie, nazwij go, np. FirstDetection.py, a następnie wklej do niego poniższy kod. Skopiuj plik modelu RetinaNet, a następnie obrazek, który chcesz poddać analizie.
FirstDetection.py
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
for eachObject in detections:
print(eachObject["name"] , " : " , eachObject["percentage_probability"] )
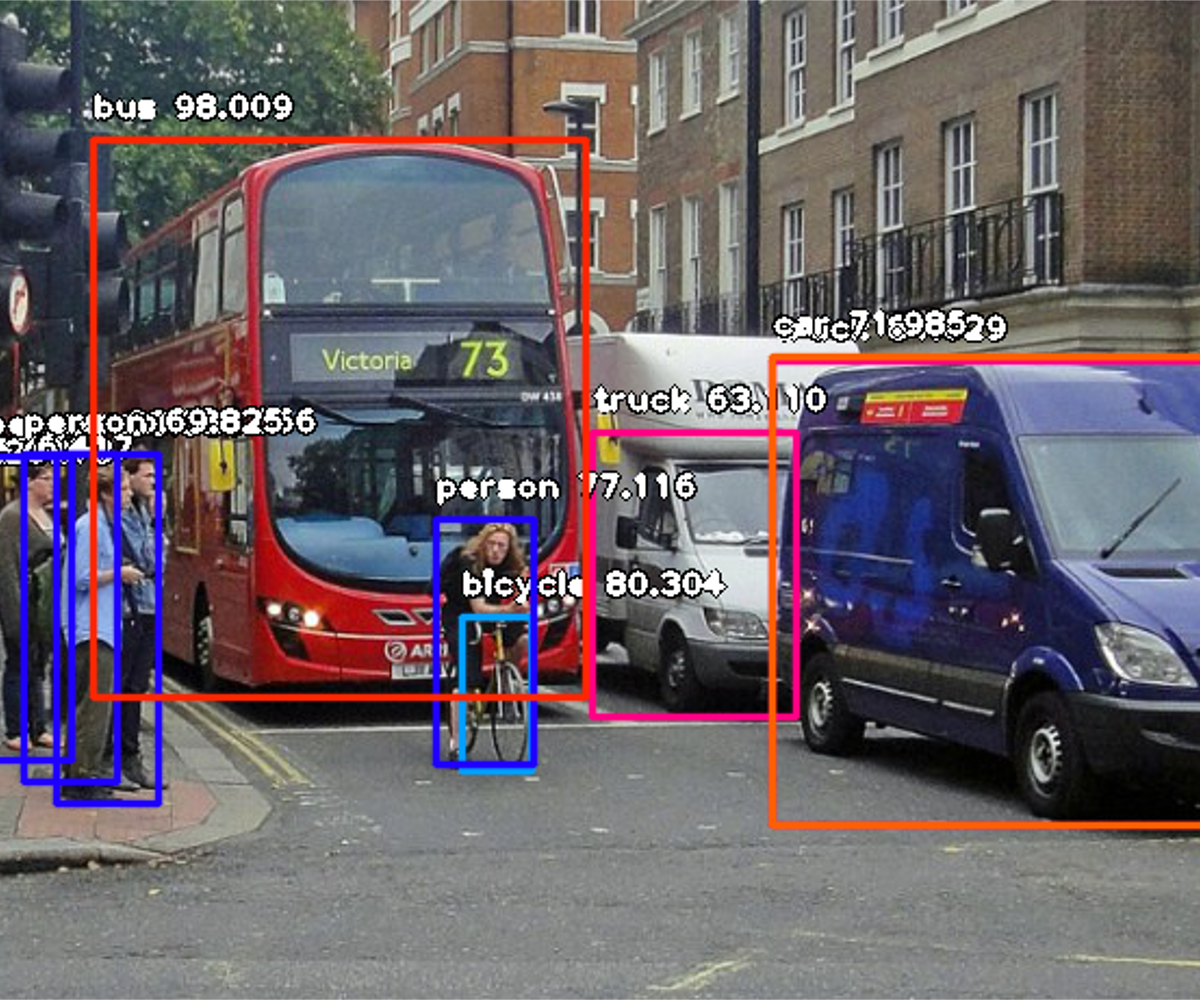
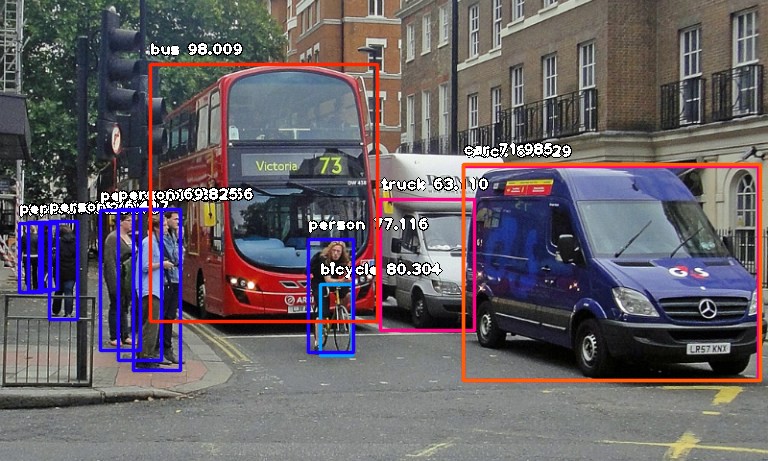
Następny krok to uruchomienie skryptu i czekanie na wyniki, które pojawią się w konsoli. Kiedy to się stanie, otwórz folder, w którym zobaczysz zdjęcie z zaznaczonymi obiektami, który wykrył program. Dla przykładu podajemy zdjęcia przed przefiltrowaniem i po.

Zdjęcia przed analizą obrazu (źródło)
Zdjęcie po analizie obrazu
Konsola pokaże co jest na obrazku oraz procentową wartość prawidłowej oceny tego, co wykryło:
person : 55.8402955532074
person : 53.21805477142334
person : 69.25139427185059
person : 76.41745209693909
bicycle : 80.30363917350769
person : 83.58567953109741
person : 89.06581997871399
truck : 63.10953497886658
person : 69.82483863830566
person : 77.11606621742249
bus : 98.00949096679688
truck : 84.02870297431946
car : 71.98476791381836

Zdjęcie przed analizą obrazu (źródło)

Zdjęcie po analizie obrazu
Dla powyższego obrazu, na konsoli zobaczysz:
person : 71.10445499420166
person : 59.28672552108765
person : 59.61582064628601
person : 75.86382627487183
motorcycle : 60.1050078868866
bus : 99.39600229263306
car : 74.05484318733215
person : 67.31776595115662
person : 63.53200078010559
person : 78.2265305519104
person : 62.880998849868774
person : 72.93365597724915
person : 60.01397967338562
person : 81.05944991111755
motorcycle : 50.591760873794556
motorcycle : 58.719027042388916
person : 71.69321775436401
bicycle : 91.86570048332214
motorcycle : 85.38855314254761
Teraz wyjaśnijmy jak działają te 10 linii kodu, o którym mowa w tytule.
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd()
Na powyższych 3 liniach widzicie: zaimportowaną bibliotekę ImageAI, zaimportowaną klasę os oraz zdefiniowaną zmienną, której celem jest umieszczenie obrazu po analizie w tym samym folderze, w którym zamieściliśmy oryginalne zdjęcie.
detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
Na powyższych liniach kodu, w pierwszej linii zdefiniowaliśmy klasę obiektu, w drugiej linii ustawiliśmy model type dla RetineNet, w trzeciej linii ustawiliśmy model path, w czwartej wczytaliśmy model do klasy rozpoznawania obiektu, a później wywołaliśmy funkcję rozpoznawania obiektu, którą wykorzystamy do wykrywania i analizy ścieżki obrazu wejściowego i ścieżkę obrazu wyjściowego.
for eachObject in detections:
print(eachObject["name"] , " : " , eachObject["percentage_probability"] )
W powyższych dwóch liniach kodu: w pierwszej sprawdzamy wszystkie wyniki zwrócone przez funkcję detector.detectObjectsFromImage, a następnie uzyskujemy nazwę i procentowe prawdopodobieństwo modelu dla każdego obiektu wykrytego na obrazie w drugim wierszu.
ImageAI ma wiele potężnych zastosowań procesu wykrywania obiektów. Jednym z nich jest możliwość wyodrębnienia obrazu każdego obiektu wykrytego na obrazie. Po prostu analizując dodatkowy parametr extract_detected_objects = True w funkcji detectObjectsFromImage, jak widać poniżej, klasa wykrywania obiektów utworzy folder dla obiektów obrazu, wyodrębni każdy obraz, zapisze go w nowym folderze i zwróci dodatkową tablicę zawierającą ścieżkę do każdego z obrazów.
detections, extracted_images = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"), extract_detected_objects=True)
Poniżej pokazujemy kilka wyodrębnionych obiektów ze zdjęć, które przytoczyliśmy na początku artykułu.

ImageAI możemy też dostosować do swoich potrzeb. Co można zmienić? Np.:
- dostosować minimalne prawdopodobieństwo: domyślnie, obiekty wykryte z procentem prawdopodobieństwa mniejszym niż 50, nie są pokazywane. Możesz zwiększyć tę wartość dla przypadków o wysokiej pewności lub zmniejszyć wartość dla przypadków, w których potrzebujesz wykryć wszystkie możliwe obiekty.
- wykrywać niestandardowe obiekty: za pomocą dostarczonej klasy CustomObject można określić, że klasa wykrywania ma zgłaszać wykrycia na jednej lub kilku unikalnych obiektach.
- ustawić prędkości wykrywania: możesz skrócić czas potrzebny na wykrycie obrazu, ustawiając prędkość wykrywania na „fast”, „faster” i „fastest”.
- ustawić typy wyjściowe: możesz określić, że funkcja detectObjectsFromImage powinna zwracać obraz w postaci pliku lub tablicy Numpy.
Wszystkie szczegóły i dokumentacje, jak korzystać z powyższych funkcji, a także inne funkcje wizji komputerowej, znajdziecie w repozytorium na GitHubie.
Artykuł został pierwotnie opublikowany na blogu towardsdatascience.com — przetłumaczyliśmy go za zgodą autora.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
