Przetwarzanie mowy i tekstu. Sprawdzamy w praktyce produkty AWS

Chmurę publiczną powinniśmy traktować jak pudełko pełne gotowych klocków, z których możemy budować złożone aplikacje. Kiedyś zaawansowane funkcje jak rozpoznawanie obrazów, syntezator mowy, zamienianie audio na tekst, tłumaczenie itp. były dostępne tylko dla nielicznych firm. Dziś takie możliwości mają wszyscy wprost na wyciągnięcie ręki.

Jakub Warczarek. Cloud Architect w dziale Cloud Implementation Nordcloud. Zajmuje się projektowaniem i implementacją kompleksowych rozwiązań z wykorzystaniem chmury. W wolnych chwilach eksperymentuje, dzieli się swoją wiedzą na firmowym blogu. Polecamy zajrzeć do BrandStory firmy NORDCLOUD, by poznać ją bliżej.
Wystarczy zalogować się do konsoli AWS i już można zacząć z nich korzystać bez ponoszenia kosztów wstępnych. Standardem i pięknem chmury jest to, że płaci się tylko i wyłącznie za rzeczywiste wykorzystanie zasobów (model pay-as-you-go).
Spis treści
Co oferuje chmura w zakresie przetwarzania mowy i tekstu
Chmura oferuje szeroki wachlarz usług rozwiązujących konkretne problemy. W poprzednim wpisie kolega z firmy przybliżył usługę Amazon Rekognition umożliwiającą zaawansowaną analizę obrazów. W niniejszym artykule chciałbym skoncentrować się na tym, co AWS oferuje w zakresie przetwarzania mowy i tekstu.
Dla ludzi komunikacja w sposób werbalny jest czymś naturalnym, natomiast dla komputerów niestety nie. Przez lata przyzwyczailiśmy się do interakcji z nimi (wbrew naszej naturze) przy pomocy klawiatury i myszki, a obecnie coraz częściej ekranu dotykowego. Dopiero od niedawna mamy okazję korzystać z asystentów głosowych takich jak na przykład Alexa, Cortana, Siri, czy Asystent Google. Uważam, że w najbliższych latach forma ta będzie tylko zyskiwać na popularności.
Chmura AWS jest pełna gotowych rozwiązań. Chcesz zamienić tekst na mowę i umożliwić łatwe wyszukiwanie słów? Wykorzystaj Amazon Transcribe. Potrzebujesz syntezator mowy? Jest Amazon Polly. Chcesz automatycznie tłumaczyć teksty? Masz Amazon Translate. Potrzebujesz odczytać tekst ze zdjęć, dokumentów, formularzy itp.? Amazon Textract zrobi to w inteligentny sposób. Nawet analiza tekstów i wyciąganie z nich wartościowych danych staje się łatwe i zautomatyzowane, gdy wykorzystamy serwis Amazon Comprehend oferujący zaawansowane przetwarzanie języka naturalnego. Amazon Alexa nie ma jakiejś potrzebnej umiejętności? Możesz dodać ją sam. A nawet wykorzystując Amazon Lex zbudować w pełni funkcjonalny interfejs głosowy dla własnej aplikacji. Wyobraźnia jest jedynym ograniczeniem, bo technologia istnieje i jest w zasięgu ręki!
Pozbawiamy maszynistki pracy, czyli Amazon Transcribe w praktyce
Plik mp3 z wypowiedzią wykorzystaną w poniższym przykładzie został pobrany stąd. Aby Amazon Transcribe mógł go skonwertować na tekst, musi on być wcześniej umieszczony w S3 Bucket. Mój S3 Bucket nazwałem speech-xyz.
Po wybraniu usługi Amazon Transcribe klikamy przycisk Create job i wypełniamy następujący formularz (oczywiście to samo można osiągnąć korzystając z API czy SDK).

Podajemy w nim ścieżkę do pliku audio umieszczonego na S3 – s3://speech-xyz/1392882.mp3 oraz język w jakim jest wypowiedź (w tym przypadku angielski). Ciekawą opcją (niewykorzystaną w niniejszym przykładzie) jest identyfikacja rozmówców. Poszczególne osoby biorące udział w rozmowie zostaną automatycznie oznaczone etykietami. Inną możliwością jest grupowanie wypowiedzi na podstawie kanału, z którego pochodzą (możemy to wykorzystać gdy analizowany plik audio jest wielokanałowym nagraniem). Wynikiem działania jest plik JSON, który zostanie zapisany w S3 Bucket podanym w konfiguracji (opcja Choose output location). Zawiera on szereg przydatnych informacji, poniżej jego fragment.
{
"jobName": "speech-to-text",
"accountId": "703046952410",
"results": {
"transcripts": [
{
"transcript": "Once you formed a bad habit, you can't get rid of it easily."
}
],
"items": [
{
"start_time": "0.15",
"end_time": "0.54",
"alternatives": [
{
"confidence": "0.9321",
"content": "Once"
}
],
"type": "pronunciation"
},
{
"start_time": "0.54",
"end_time": "0.68",
"alternatives": [
{
"confidence": "0.6686",
"content": "you"
}
],
"type": "pronunciation"
},
...
Poza całym tekstem, mamy wypisane poszczególne słowa, wraz z znacznikami start_time i end_time (czas jego rozpoczęcia i zakończenia) oraz parametrem confidence informującym nas z jaką pewnością usługa rozpoznała dane słowo. Jak widać w rozważanym przypadku Amazon Transcribe wywiązał się bardzo dobrze ze swojego zadania. W celu wygodnego przeszukiwania i analizy takich plików można wykorzystać usługę Amazon Athena, która umożliwia wykonywania zapytań SQL do danych umieszczonych na S3.
Powyższa usługa doskonale nadaje się do katalogowania wypowiedzi pochodzących z materiałów audio i wideo (obsługiwane formaty: mp3, mp4, wav, flac) w celu dalszego ich przetwarzania. Mogłaby zastąpić ręczne spisywanie zeznań przez protokolantów na rzecz automatycznej analizy nagrania. Niestety język polski nie jest jeszcze wspierany (stan na maj 2019).
Pozbawiamy tłumaczy pracy, czyli Amazon Translate w praktyce
Amazon Translate wykorzystuje sieci neuronowe do tłumaczenia tekstów w czasie rzeczywistym. Daje to całkiem niezłe rezultaty. Obsługa tej usługi z wykorzystaniem API lub SDK jest niezwykle prosta. W żądaniu należy przesłać tekst do przetłumaczenia, podać język w jakim on jest (lub ustawić „auto„ wtedy zostanie automatycznie wykryty) oraz na jaki język chcemy go przetłumaczyć.
{
"Text": "Once you formed a bad habit, you can't get rid of it easily",
"SourceLanguageCode": "auto",
"TargetLanguageCode": "pl"
}
W odpowiedzi otrzymamy.
{
"TranslatedText": "Kiedy już masz zły nawyk, nie możesz się go łatwo pozbyć",
"SourceLanguageCode": "en",
"TargetLanguageCode": "pl"
}
Możemy również skorzystać z GUI.
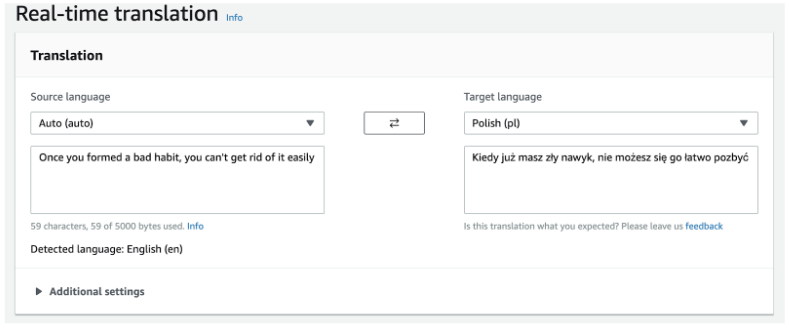
Jak widać tłumaczenie jest całkiem wysokiej jakości. Dla tłumaczonego tekstu jest ograniczenie 5000 znaków na jedno zapytanie, więc w przypadku dłuższego tekstu trzeba go podzielić. W celu poprawy jakości tłumaczeń można dostarczyć własną terminologię wtedy nazwy własne będą tłumaczone w określony przez nas sposób, niezależnie od kontekstu w jakim się znalazły.
Uważam, że Amazon Translate z powodzeniem można wykorzystać na przykład w sklepie internetowym do automatycznego tłumaczenia opinii o danym produkcie pochodzących od użytkowników z różnych krajów.
Pozbawiamy lektorów pracy, czyli Amazon Polly w praktyce
Amazon Polly to nic innego jak dobrze znany w Polsce syntezator Ivona, który został zakupiony przez AWS w 2013 roku i jest stale rozwijany w polskich biurach.
Ta usługa potrafi generować plik mp3 zawierający głos lektora (są dostępne zarówno głosy męskie, jak i żeńskie) odczytującego tekst i zapisywać go do S3. Korzystając z usługi musimy podać tekst, żądany głos oraz wybrać język w jakim ma zostać on odczytany. Wszystkie opcje są dostępne zarówno z poziomu interfejsu graficznego, jak również API oraz SDK.
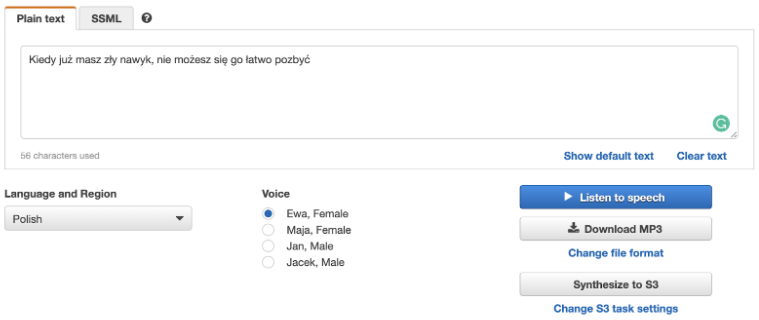
Amazon Polly oferuje również wsparcie dla SSML (Speech Synthesis Markup Language). Jest to specjalny format pozwalający na konfigurowanie w jaki sposób dany tekst ma zostać przeczytany przez syntezator. Na przykład szeptem, pojedyncze słowo w innym języku, między zdaniami ma być zrobiona sekundowa przerwa, jak mają być czytane liczby itd. (po więcej wraz z przykładami zajrzyj tu).
Dzięki tej usłudze w kilka chwil możemy wzbogacić chociażby naszego bloga o wersje wpisów w formie audio. Teraz będzie można również ich posłuchać. Wystarczy, że do każdego tekstu dołączymy link z nagraniem audio w formacie mp3 umieszczonym na S3 (a przedtem wygenerowanym przez Amazon Polly). Jak widać jest to dziecinnie proste.
Co dalej?
Wcześniej wymienione usługi w połączeniu z innymi dostępnymi na AWS pozwalają na szybkie rozwiązywanie złożonych problemów biznesowych, gdyż doskonale się ze sobą integrują. Posiadają udokumentowane API i SDK dla najpopularniejszych języków programowania. Stąd wystarczy napisać parę linijek kodu, żeby wszystko zaczęło ze sobą współpracować. Jedynym ograniczeniem jest tylko nasza wyobraźnia. Chociażby łącząc ze sobą trzy usługi szerzej przeze mnie opisane (Transcribe, Translate i Polly) z wykorzystaniem AWS Lambda (function a a service), można zbudować funkcjonalny serwis. Na przykład taka aplikacja mogłaby w automatyczny sposób tworzyć polskie napisy do obcojęzycznych filmów, a nawet nagranie lektora tak wszechobecnego w polskiej telewizji. Wtedy zamiast Tomasza Knapika dialogi w filmie czytałby nam któryś z głosów dostępnych w usłudze Amazon Polly. Mam nadzieję, że w tym krótkim tekście udało mi się zachęcić do eksperymentowania.
Możesz dołączyć do mojego zespołu AWS Architektów i wspólnie odkrywać podobne funkcjonalności AWS, Azure, GCP i pracować przy projektach związanych z chmurą publiczną w Nordcloud. Sprawdź kogo szukamy.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły
Podejście do zmniejszania kosztów przetwarzania danych na przykładzie Azure Databricks

Data management, data governance i data modernization - jak okiełznać proces zarządzania danymi w organizacji

Big Data - klęska urodzaju czy złoty Graal? Praktyczne metody wykorzystania potencjału danych
Dane 1,3 mln użytkowników Clubhouse do pobrania? To nie wyciek, to data scraping

Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Migracja do chmury? Wypełnij ankietę i sprawdź, jak wygląda ten proces u innych!

Analiza infrastruktury i danych IoT. Wybór bazy
