Jak powstaje sztuczna inteligencja w grach komputerowych

Sztuczna inteligencja brzmi bardzo skomplikowanie i zawile, kiedy tak naprawdę prawie wszyscy realizują ją tymi samymi metodami. Aby zrozumieć, jak powstaje sztuczna inteligencja, warto poznać, czym są: maszyny stanów skończonych, drzewa decyzyjne, sieci neuronowe i kilka innych. Tego dowiecie się z poniższego artykułu.

Marek Winiarski. Z wykształcenia i zawodu programista webowy. Z zamiłowania gracz i bloger. Na studiach odkrył, że przekazywanie wiedzy go bawi i zaczął to robić w internecie na blogu mwin.pl, pisząc głównie o produkcji gier z lekkim pociągiem do ich strony psychologicznej i ekonomicznej. W życiu poza-komputerowym fan angielskiej piłki nożnej i orientalnej kuchni.
Spis treści
Techniki podejmowania decyzji
Najbardziej oczywistym zagadnieniem dotyczącym sztucznej inteligencji w grach komputerowych jest system podejmowania decyzji. To ten moment, kiedy agent (tak w żargonie sztucznej inteligencji nazywa się komputerowego przeciwnika) reaguje na zachowanie gracza. Docierają do niego pewne bodźce, które może przeanalizować i dzięki nim zachować się w adekwatny do sytuacji sposób. Przykładowo, bodźcem może być zobaczenie gracza, na co reakcją będzie otwarcie ognia. Przy czym to bardzo banalny przykład, bo często komputerowi rywale analizują dużo więcej danych, zanim podejmą decyzję. W przypadku strzelanki, zanim padnie decyzja o otwarciu ognia, agent musi sprawdzić, czy ma załadowany magazynek, czy ma dość życia żeby stanąć do walki oraz czy nie lepiej będzie najpierw przedostać się za osłonę itd.
Mimo że wydaje się iż w każdej grze schematy podejmowania decyzji mogą być kompletnie różne, to prawda jest taka, że większość gier korzysta z tych samych algorytmów, które różnią od siebie wyłącznie dane wejściowe i wyjściowe.
Maszyny Stanów Skończonych
Najpowszechniej i najszerzej stosowana metoda realizacji sztucznej inteligencji w grach komputerowych to Maszyny Stanów Skończony (ang. Finite-State Machine – FSM). W polskim tłumaczeniu pojawia się też nazwa: automat o skończonej liczbie stanów lub w skrócie automat skończony.
Zasada działania jest bardzo prosta. A dokładniej mamy 3 zasady:
- Automat musi mieć skończoną liczbę stanów, w których może się znajdować,
- Pomiędzy stanami istnieją przejścia, realizowane po spełnieniu pewnych warunków,
- Automat może znajdować się na raz tylko w jednym stanie.
Do naszego automatu dostarczamy dane wejściowe. Na ich podstawie obliczany jest stan wyjściowy, co może być nieco mylące, bo automat nie zwraca żadnej wartości, a jedynie przechodzi z jednego stanu do drugiego. Tym stanem wyjściowym jest właśnie stan, w którym znajduje się automat po przetworzeniu danych wejściowych. Brzmi skomplikowanie, więc przytoczę przykład objaśniający.
Programowanie najczęściej stara się odzwierciedlić rzeczywistość, dlatego rzeczy widoczne dookoła nas, będą miały bardzo dobre zastosowanie jako przykłady. Żarówka np. ma dwa stany: Włączona i Wyłączona. Albo woda i jej 3 stany skupienia: ciekły, gazowy i stały. Do przejść między stanami doprowadza zmiana temperatury. Kolejny przykład to drzwi. Jakie mogą mieć stany drzwi?
- Otwarte,
- Zamknięte,
- Zamknięte na klucz.
Do tego musimy mieć jakieś dane wyjściowe. Oczywiście zawsze możemy podać cokolwiek, ale w tym wypadku sensowne są dwa sygnały wejściowe:
- Użyj ręki (naciśnij klamkę),
- Użyj klucza (włóż i przekręć klucz w zamku).
Jeżeli wykorzystamy sygnał ręki na drzwiach otwartych, to stanem wyjściowym będą drzwi zamknięte. Jeśli znów wykorzystamy sygnał ręki na drzwiach zamkniętych, to stanem wyjściowym będą drzwi otwarte. Analogicznie będzie przy drzwiach zamkniętych i zamkniętych na klucz i sygnałem klucza. Jednak bardziej rozbudowana kombinacja pojawia się, gdy chcemy przejść z drzwi zamkniętych na klucz do drzwi otwartych. Nie mamy tutaj bezpośredniego połączenia. Więc najpierw trzeba użyć klucza, a następnie ręki.
Wszystko fajnie, ale jak to zastosować w grze? Najczęściej stany będą pewną akcją wykonywaną przez agenta. Patrolowanie, atakowanie, ucieczka, leczenie się itp. Przejścia między stanami dalej będą przejściami między stanami, jednak zaczną oczekiwać spełnienia warunków. Np. żeby agent przeładował broń, musi mieć zapasową amunicję i miejsce w magazynku (po co przeładowywać naładowany karabin?). Żeby zaatakować gracza musi mieć amunicję w magazynku i musi widzieć gracza.
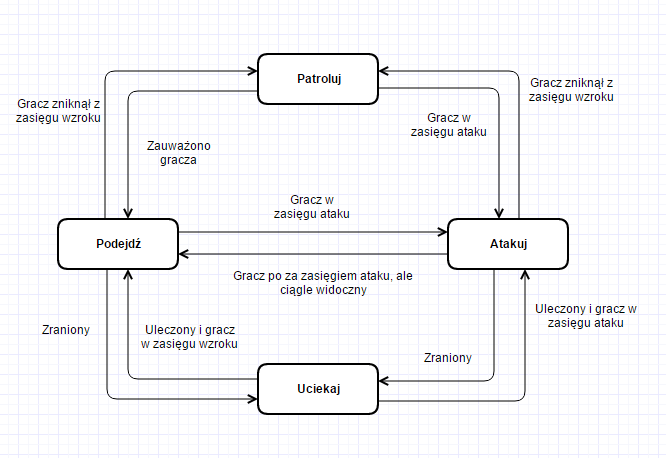
Przykładowa maszyna stanów skończonych
Na powyższym rysunku przedstawiłem przykładową maszynę stanów skończonych. Jest to chyba najbardziej podstawowy rodzaj jaki możemy sobie zrobić.
Tak naprawdę jedyne co teraz można robić to dokładać kolejne stany i budować bardziej skomplikowane warunki. Przykładowo między podejściem, a atakiem mamy warunek czy gracz jest w zasięgu ataku. Bodźcem jest tutaj zmiana odległości między graczem, a agentem. Ale poza zasięgiem możemy sobie jeszcze sprawdzić czy mamy amunicję. Im bardziej złożone będą warunki i im więcej będzie stanów, tym bardziej złożona i (być może) lepsza będzie nasza sztuczna inteligencja. Warto pamiętać o odpowiednim doborze połączeń i nie wstawiać za wszelką cenę jak najwięcej opcji, bo wtedy sami możemy się pogubić albo agent będzie lekko opóźniony, bo przejście całego drzewa zajmie mu kilkanaście sekund.
Jeśli chodzi o same warunki, mogą być one banalnie proste: jeśli dostaje bodziec w postaci zauważenia gracza, to atakuje. Może też zrobić to w oparciu o jakieś funkcje, które sprawdzą szereg warunków. Dodatkowa ważna informacja, to fakt, że jeden agent może być sterowany nawet kilkoma maszynami stanów — oczywiście jeśli będą dobrze zaprojektowane. Również dany stan może być opisany kolejną maszyną stanów. Np. w stanie “Patroluj”, moglibyśmy mieć dwa stany: idź do punktu patrolowego i znajdź kolejny punkt patrolowy. Jeden wykonywałby akcję przemieszczania, a drugi ustalał, gdzie szukać kolejnego punktu.
W zasadzie tak prezentują się maszyny stanów skończonych i jest to najprostsza metoda kreowania sztucznej inteligencji.
Drzewa Decyzyjne
Ten system stał się bardzo popularny u dużych developerów w ciągu ostatnich 20 lat. Sprzęt stał się na tyle mocny, że możliwe było wykorzystanie tej techniki. Przodownikami były tutaj ekipy pracujące nad grami Halo i Gears Of War.
Drzewa decyzyjne opierają się na zasadach tworzenia drzew w informatyce. Czyli dostajemy zorganizowaną, hierarchiczną strukturę danych, która zaczyna się od korzenia (root) i kończy na liściach (leaf).
W tym wypadku agent, żeby określić jak powinien się zachować wykonuje obliczenia na drzewie. Czyli sprawdza wszystkie kolejne gałęzie, aż dojdzie do liścia. Każdy z węzłów, może zwrócić: ture, false albo running – czyli określa, że jeszcze się nie policzył. Ostatni stan jest wbrew pozorom ważny. Mając na scenie kilku agentów ze skomplikowanymi drzewami, nie byłoby opcji policzyć całego drzewa w ciągu jednej klatki, więc decyzje byłyby głupie albo gra zawieszałaby się. Dlatego proces liczenia takiego drzewa, może trwać nawet kilka klatek gry.
W drzewie decyzyjnym rozróżniamy kilka szczególnych rodzajów węzłów:
- Węzły złożone – Mają pod sobą kilka dzieci i określają w jaki sposób realizować sprawdzanie:
– Sekwencja (Sequence) – Zwraca true, kiedy wszystkie węzły potomne zwróciły true (takie logiczne AND),
– Selektor (Selector) – Zwraca true, gdy trafi na pierwsze możliwe true. - Węzły dekoracyjne – W przeciwieństwie do złożonych, te mogą mieć tylko jednego potomka i wykonują pewną operację:
– Negacja (Inverter) – Jest to klasyczne, logiczne NOT. Jeśli jego potomek zwraca true, to on zwraca false,
– Powtarzacz (Repeater) – Oblicza swoją wartość określoną (bądź nieskończoną) liczbę razy, do póki nie osiągnie założonej wartości. Można go wykorzystać, np. do oczekiwania na odpowiednią ilość energii.
– Ogranicznik (Limiter ) – Ograniczę liczbę obliczeń danego węzła. Swojego rodzaju ogranicznik dla powtarzacza.
Same liście mogą zwracać nam wyniki działań funkcji, czy sprawdzanych atrybutów. Np. sprawdzać, czy odległość między graczem, a agentem jest mniejsza od 10.
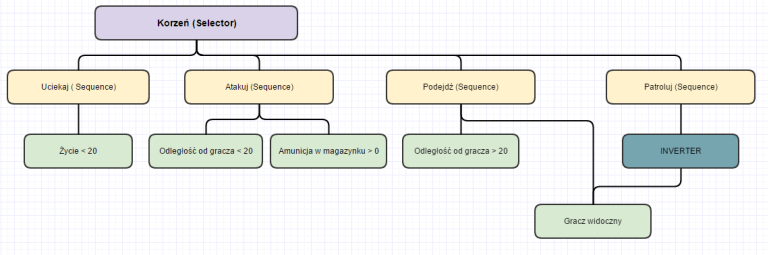
Przykładowe drzewo decyzyjne
Ważne jest również to, że obliczanie zaczyna się od lewej strony i idzie w prawo (patrz rysunek powyżej). Czyli, jeśli jako pierwszy child dla roota będzie “Atakować?”, to właśnie takie rozwiązanie wybierze agent jeśli tylko spełni warunki. Np. w drzewie powyżej, korzeń zacznie badanie od węzła “Uciekaj”, który sprawdza, czy życie jest mniejsze od 20. Powiedzmy, że zwróci false, przez co cały węzeł “Uciekaj” zwraca false. Przechodzimy wtedy do węzła “Atakuj”. Powiedzmy, że oba jego warunki zostały spełnione i zwraca true — a robi to ponieważ korzeń jest selektorem. Tym samym przeciwnik podjął decyzje i atakuje.
Pytanie, które tutaj się samo nasuwa: to jaka jest różnica między drzewami decyzyjnymi i maszyną stanów skończonych? Główna przewaga drzew to skalowalność, oraz fakt, że są lepszym rozwiązaniem modułowym. Co to oznacza? Łatwiej i przejrzyściej powiększyć nam tak zbudowane drzewo, niż diagram stanów, który czasami może się bardzo rozrosnąć – możemy mieć nawet setki stanów. Tutaj hierarchia zapewnia, że wszystko będzie dalej czytelne. Jeśli chodzi o moduły, to tak opakowana sztuczna inteligencja może być z powodzeniem wykorzystana wielokrotnie w różnych projektach. Kiedy maszyna stanów często jest dedykowana konkretnemu przypadkowi. Jak wspominał Damian Isla na konferencji GDC (Game Developers Conference) w 2005 roku, tak rozbudowane maszyny stanów są zbyt trudne do debugowania, dlatego jego ekipa, pracująca nad grą Halo 2, wykorzystała drzewa decyzyjne.
Już tylko nieco bardziej skomplikowana Maszyna Stanów Skończonych może nieco zamazać nam pogląd na sytuację. Źródło
W ogólnym rozrachunku, nic nie stoi na przeszkodzie, żeby wykorzystywać jednoczenie oba rozwiązania.
Skala Użyteczności (Utility AI)
Ten koncept jest raczej nowy i nieopisany zbyt dokładnie w różnych źródłach. Jednak pojawiają się firmy, które ten schemat chcą mocno promować, takie jak Apex Game Tools.
Idea powstała dlatego, że twórcy chcący budować coraz to bardziej skomplikowane i rozbudowane systemy sztucznej inteligencji, napotkali ponownie problem rozrostu w drzewach decyzyjnych. Drzewa rosły do takich rozmiarów, że mimo układu hierarchicznego i tak stawały się trudne do ogarnięcia i debugowania. Dodatkowo ogromne drzewo obliczało swój ruch bardzo długo. Próbowano rozwiązać problem tworząc pod-drzewa, które miały być w stanie obliczać swoją wartość, bez udziału reszty drzewa, jednak to potęgowało tylko problemy z debugowaniem.
Biorąc pod uwagę najnowsze trendy w grach, gdzie dominują otwarte, wypełnione zawartością światy, takie jak Far Cry, czy Wiedźmin, mamy tam ogromne zapotrzebowanie na wielu agentów na raz, którzy będą zachowywali się naturalnie. Przy skomplikowanym systemie, zmarnujemy na to wiele zasobów komputera, przez co może na tym ucierpieć płynność rozgrywki, albo obciążenie spowoduje to, że przeciwnicy będą bardzo głupi, bo nie zdążą podjąć dobrej decyzji.

Porównanie drzewa decyzyjnego i Utility AI
Pierwszym studiem, które wykorzystało Utility AI było Guerilla Games. System pojawił się w grze Killzone 2. Podobne systemy, ale nie do końca to, wykorzystano w F.E.A.R czy w Cywilizacji. Ale na czym w zasadzie polega Utility AI? Nasz agent może zawsze wykonać pewne akcje. Jednak, aby zdecydować, jaką akcję podjąć ocenia sytuację. Gdzie słowo „ocenia” jest słowem klucz. Każdej sytuacji dotyczą pewne okoliczności, które tutaj są danymi wejściowymi. Dla różnych działań, każda okoliczność ma jakąś wartość punktową. System zlicza punkty i wybiera akcję najlepiej punktowaną.
Korzyści z tego rozwiązania jest kilka. Po pierwsze, taki system jest prosty do zaprojektowania. Znika bariera słowna między projektantem, a programistą. Można powiedzieć: “Jeśli żołnierz jest pod ostrzałem, to najważniejsze dla niego, jest znaleźć osłonę”. Łatwo całość rozszerzyć. Jeśli będziemy chcieli dodać nową zasadę, np. dla żołnierza ma się teraz dodatkowo liczyć czy ma kompana czy nie, to taką zasadę możemy od ręki dopisać wszędzie. W przypadku drzewa, czy maszyny stanów, możemy sobie coś zepsuć. Po trzecie, mając do dyspozycji prosty w obsłudze system, generujemy mniej błędów, przez co mamy więcej czasu na tworzenie sztucznej inteligencji, zamiast marnować go na debugowanie.
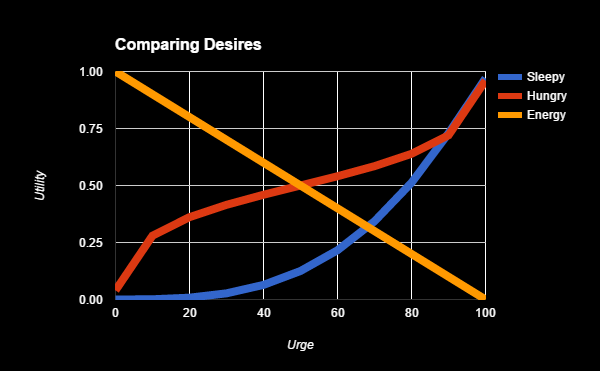
Ocena różnych wartości składowych, może odbywać się na bazie wykresu
Dodatkowym plusem jest to, że praktycznie automatycznie wprowadzamy sobie elementy logiki rozmytej.
Logika Rozmyta
Zdefiniowanie logiki rozmytej jest najprostsze, kiedy skonfrontujemy ją z logiką klasyczną. W naszej klasycznej logice mamy dwa stany: Prawda albo Fałsz. Logika rozmyta daje nam stany pośrednie i pozwala pracować z koncepcjami, które nie są rzeczowe – czyli wymagają określenia “w jakim stopniu” lub “ile”. Np. bardzo mały, dość duży, średni etc.
Różnica między logiką rozmytą i klasyczną
Taki stan rzeczy pozwala na budowanie bardziej skomplikowanych i rzeczywistych systemów sztucznej inteligencji. Pozwala np. wprowadzić emocje. Nasz przeciwnik już nie jest zły albo spokojny, tylko może być spokojny, poirytowany, wkurzony, bardzo zły, rozgniewany etc. Zyskujemy na tym dwie rzeczy. Po pierwsze możemy operować na tych stanach pośrednich, a po drugie w rozmowie programisty z projektantem, określenie “Przeciwnik ma atakować, kiedy będzie bardzo zły” nabiera sensu.
Ważne jest, że wartości logiki rozmytej zapisujemy w formie znormalizowanej. Tzn. przyjmujemy wartości od 0 do 1, gdzie można rozumieć to jak procenty: 0 = 0%, 0.23 = 23%, 0.76 = 76%, 1 = 100%.
Żeby wykorzystać logikę rozmytą, musimy sobie najpierw określić, co chcemy symulować za jej pomocą. Załóżmy, że chcemy sprawdzać, czy agent powinien rzucić zaklęcie leczenia. Będzie to zależało od dwóch czynników: jego stopnia bezpieczeństwa (dla uproszczenia przyjmiemy, że będzie to odległość od gracza), oraz od aktualnego stanu zdrowia.
Teraz musimy sobie wymodelować zasady, które możemy uważać za rozsądne. W moim odczuciu wygląda to tak:
- Jeżeli jestem bardzo ranny to rzucam zaklęcie dużego leczenia, jeżeli jest bezpiecznie,
- Jeżeli jestem trochę ranny to rzucam zaklęcie małego leczenia, gdy jest bezpiecznie lub niebezpiecznie,
- Jeżeli nie jestem ranny to się nie leczę,
- Nie leczę się, jeśli jest niebezpiecznie.
Teraz na tej podstawie musimy określić zbiory rozmyte, które będą definiować nasze rozmiary przedstawione w języku naturalnym. Czyli w jakiś sposób trzeba przedstawić, kiedy „bardzo ranny” zmienia się w „ranny”, a kiedy „bezpiecznie” zmienia się w „niebezpiecznie”. Najczęściej służą do tego wykresy:
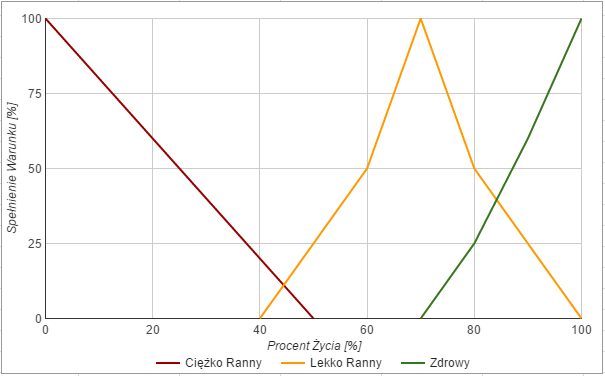
Wykres określający, w jakim stanie jest agent
Załóżmy, że agent ma 80% życia. Będzie to wtedy gdzieś w tym miejscu:

Obieramy wartość, na postawie aktualnego stanu życia postaci
Co z tego możemy odczytać? Że nasz bohater jest w 0.5 lekko ranny oraz w 0.25 zdrowy. Teraz podobne badanie robimy na naszej zmiennej odległości. Najpierw wykres:

Wykres wartości bezpieczeństwa
A następnie zaznaczamy aktualną wartość. Powiedzmy, że gracz jest 350 m od agenta:
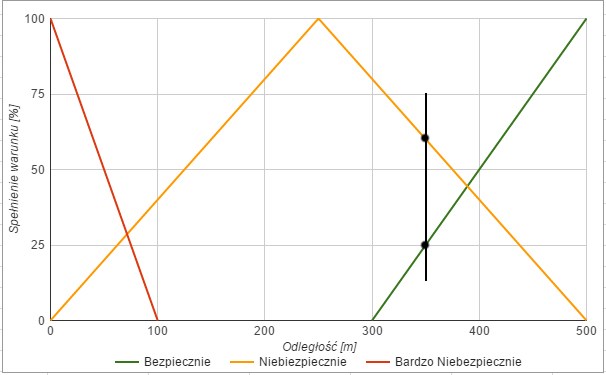
Aktualna wartość odległości agenta od gracza
Wynika z tego, że pozycja agenta jest w 25% bezpieczna i w ok. 65% niebezpieczna.
Teraz zobaczmy, jakie zasady mogą być spełnione? Nasz gracz jest trochę zdrowy i trochę lekko ranny, więc pojawiają się trzy pierwsze zasady, mogące mieć zastosowanie:
- Nie leczę się, gdy jestem zdrowy,
- Rzucam zaklęcie małego leczenia, kiedy jestem lekko ranny i jest niebezpiecznie,
- Rzucam zaklęcie małego leczenia, kiedy jestem lekko ranny i jest bezpiecznie.
W oparciu o bezpieczeństwo, możemy określić, że jest bezpiecznie i niebezpiecznie, co dokłada nam możliwość wystąpienia kolejnych 3 zasad:
- Rzucam zaklęcie małego leczenia, gdy jestem lekko ranny i jest niebezpiecznie (tutaj mamy duplikat),
- Rzucam zaklęcie małego leczenia, gdy jestem lekko rany i jest bezpiecznie (znów duplikat),
- Rzucam zaklęcie dużego leczenia, gdy jestem bardzo ranny i jest bezpiecznie.
Teraz należy wykonać oceny prawdziwości każdego ze scenariuszy. Prawdziwość, to najmniejszy możliwy procent ze wszystkich warunków. Przykładowo: rzucam zaklęcie małego leczenia, gdy jestem lekko ranny i jest bezpiecznie. Jestem lekko ranny w 50%, a jest bezpiecznie w 25%. Zatem, w najwyższym możliwym procencie, zdanie jest prawdziwe w 25%. Takiej ewaluacji dokonujemy dla każdego zdania, otrzymując:
- Nie leczę się, gdy jestem zdrowy – 25% (Jestem zdrowy w 25%, odległość tutaj nie miała znaczenia),
- Rzucam zaklęcie małego leczenia, kiedy jestem lekko ranny i jest bezpiecznie – 25% (To omawialiśmy w przykładzie),
- Rzucam zaklęcie małego leczenia, kiedy jestem lekko ranny i jest niebezpiecznie – 50% (50% jestem ranny i 65% jest niebezpiecznie),
- Rzucam zaklęcie dużego leczenia, gdy jestem bardzo ranny i jest bezpiecznie – 0% (w 0% jestem bardzo ranny).
I teraz wybieramy najwyżej ocenione zdanie, czyli tutaj rzucam zaklęcie małego leczenia, bo jestem lekko ranny i jest niebezpiecznie. W ten sposób decyzję możemy podejmować na każdy możliwy temat.
W przypadku Utility AI wspomniałem, że praktycznie z automatu dodaje nam logikę rozmytą. Teraz widać dlaczego. Jeśli każde zadanie, zależy od kilku czynników, które oceniamy w różnych skalach to tak naprawdę dodajemy elementy logiki rozmytej. Jeżeli np. przeładowanie broni zależy od odległości w jakiej jest przeciwnik i tego ile pocisków zostało nam w karabinie, to możemy przyznać np. 20 pkt za odległość i 100 pkt za ostatnie dwa pociski. Wtedy, jeśli żadna czynność nie dostanie więcej punktów, wygrywa przeładowanie.
Tyle, jeśli chodzi o dokonywanie decyzji.
Wyszukiwanie ścieżki (Pathfinding)
Przechodzimy teraz do algorytmów szukania ścieżki. Jest to jedna z ważniejszych rzeczy w grach. Co z tego, że przeciwnik podejmie decyzję, jeśli potem nie będzie potrafił nigdzie się dostać, czy przemieszczać się po planszy?
Kiedyś plansze gier były dużo prostsze, przykładowo w klasycznym Space Invaders przeciwnicy tylko opadali w dół i ruszali się na boki. W Pacmanie, a jedynym ograniczeniem rywali były ściany labiryntu. Dzisiaj, gdy to bardzo rozbudowane światy z krzywiznami terenu i masą różnych dekoracyjnych elementów, oraz dziesiątkami innych agentów. Dlatego poruszanie się agenta musi być przemyślane.
W wypadku wyszukiwania ścieżek, najczęściej do głosu dochodzą algorytmy wyszukiwania ścieżki w grafie. Nie zawsze są one rozwiązaniami najlepszymi, dlatego mówimy tu o algorytmach heurystycznych, czyli optymalizacyjnych.

Algorytm A* (A-Star)
Najpopularniejszym algorytmem wyszukującym ścieżkę pomiędzy punktami A i B jest algorytm A* (A-star). Mimo że istnieje wiele innych algorytmów robiących to samo, jak algorytm Dijkstry (nie mylić z grubasem z Wiedźmina), czy algorytm Monte-Carlo wykorzystany np. w AlphaGo od Google. Dzieje się tak, ponieważ ze wszystkich algorytmów A* jest prosty w implementacji i efektywny w działaniu.
A* zawsze znajduje ścieżkę między dwoma punktami, jeśli tylko ona istnieje, dodatkowo będzie to zawsze optymalna ścieżka. Kolejnym powodem opowiadającym się za tym algorytmem, jest fakt że dobrze wykorzystuje heurystykę, tzn. żaden inny algorytm (korzystający z tej samej heurystyki), nie znajdzie bardziej optymalnej drogi, przy testowaniu mniejszej liczby węzłów.
Już wiemy, czemu algorytm jest fajny, ale w zasadzie na czym polega? Musimy tutaj rozważyć naszą planszę jako graf z pewnymi wierzchołkami. Wierzchołki połączone są krawędziami, które mogą mieć pewien koszt. Algorytm zawsze wybiera najtańsze w danym momencie przejście, czyli przechodzi do wierzchołka, do którego koszt przejścia był najniższy. Wykonuje to, dopóki nie trafi na punkt docelowy. Bardzo ładnie obrazuje to gif z Wikipedii:

Działanie algorytmu A*
Jak widać, algorytm na początku ma do wyboru dwie krawędzie o wartościach: 1,5 oraz 2. Ale do całości dolicza heurystykę – h(a) dla każdego wierzchołka. Czyli faktyczny pierwszy wybór to: 5,5 i 6,5 – ruszamy więc do wierzchołka A. Kolejny wybór to: 1,5 + 2 + 2 (bo dwie krawędzie + heurystyka), oraz 2 + 4,5, czyli ogólnie: 5,5 vs 6,5. Wybieramy wierzchołek B. Kolejna para to znów wierzchołek D o ciągle tym samym koszcie 6,5, oraz wierzchołek C o koszcie: 6,5 (za krawędzie) + 4, czyli 11,5. Tym razem wygrywa wierzchołek D. No i kolejny test: Wierzchołek C z: 11,5 oraz wierzchołek E z: 7. Wybieramy E. Następny krok to wierzchołek docelowy, więc go bierzemy i jesteśmy u celu.
Wszystko fajnie. Tylko gdzie wierzchołki i krawędzie w grach? W turówkach to jeszcze, ale w strzelance?
Uproszczanie świata gry
Mimo że czasami tego nie widać, większość gier dzieli sobie świat na właśnie takie proste przestrzenie. Metod podziałów jest kilka i wybranie sobie odpowiedniego zależy głównie od stylu gry jaką wybierzemy. Przykładami mogą być kwadraty czy sześciany. Ale mamy też bardziej skomplikowane metody podziału, takie jak czworoboki wypukłe, czy punkty widoczności.

Przykładowe podziały świata gry
Tutaj mamy odpowiednio:
- A – Niepodzielony świat,
- B – Siatka prostokątna – najprostsza możliwa metoda. Środkami (czyli naszymi wierzchołkami grafu) mogą być tutaj środki czy wierzchołki kwadratów,
- C – Drzewa czwórkowe – Podobne do prostokątnej siatki, tyle, że dzielimy sobie kwadraty na coraz mniejsze, aż do momentu kiedy pełny kwadrat zmieści się w świecie gry nieprzysłonięty. Środki to znów centrum lub wierzchołek kwadratu. Na plus zasługuje tutaj fakt, że duże kwadraty przyspieszają wyszukiwanie drogi,
- D – Wielokąty wypukłe – Bardziej skomplikowana metoda, gdzie fragmenty wyznacza się w oparciu o wierzchołki przeszkód, z których ciągnie się linię przecięcia, aż do napotkają inne przecięcie, bądź przeszkodę. Można też tworzyć tutaj siatki nawigacyjne. Środkami mogą być środki wielokątów, lub ich obwody,
- E – Punkty widoczności – Ta metoda podziału skupia się głównie na omijaniu przeszkód. Wierzchołki określają gdzie znajduje się przeszkoda i każemy agentowi poruszać się w pewnej odległości od wierzchołków,
- F – Uogólnione cylindry – Przestrzeń między sąsiadującymi przeszkodami traktujemy jak dwuwymiarowy cylinder. Obliczamy sobie oś środkową w przestrzeni pomiędzy dwoma sąsiadującymi przeszkodami, wliczając w to granicę mapy. Tak wyznaczone punkty, określają nam, gdzie postać może się przemieszczać.
To pewnie nie wszystkie metody w jakie da się podzielić siatkę. Wszystko zależy od zapotrzebowania i stylu gry jaką tworzymy. Każda z tych metod ma swoje wady i zalety. Np. przy podziale siatki na wielokąty, musimy dodać algorytm, który rozwiąże problem poruszania się, wewnątrz wielokąta. W punktach widoczności nie uwzględnimy dynamicznych postaci. Siatka prostokątna, da nam opcję omijania przeszkód i postaci, ale za to wymaga najwięcej obliczeń. Wybór powinien zależeć od gry jaką tworzymy.
Algorytm A* ma jedną zasadniczą wadę. Potrafi obliczać się długo i czasami się zawiesić, jeśli szukana ścieżka nie istnieje. Dlatego, zanim przystąpimy do wyszukiwania ścieżki, warto wcześniej sprawdzić, czy droga do wybranego punktu w ogóle istnieje. Przy okazji możemy też sprawdzić, czy droga, którą szukamy nie jest linią prostą – wtedy nie potrzeba liczyć całej drogi i można w ten sposób zoptymalizować działanie algorytmu. Istnieją jeszcze inne techniki optymalizacji tego algorytmu, ale nie będziemy tego tutaj omawiać.
Są również inne algorytmy i sposoby obliczania ścieżki, jednak to ten stosowany jest szeroko i niemal we wszystkich grach od 1968 roku i nic nie zapowiada, żeby miało się to zmienić. Dlatego nie omawiam innych, bardziej niszowych algorytmów. Nawet w Unity NavMesh to bardzo zoptymalizowany i rozbudowany A*.
Algorytmy stadne
Kolejnym zagadnieniem, nad którym się pochylimy są algorytmy stadne. Zasadniczo są to algorytmy, które mają symulować zachowanie roju pszczół, gromady ptaków lub ławicy ryb. Algorytm został zaproponowany przez Craiga Raynoldsa w 1987 roku. Jego postulat zakładał, że są 3 proste zasady, które połączone razem dają nam realistyczne zachowanie. Te zasady to:
- Rozdzielność – Oznacza, że dany boid (bo tak nazywamy agentów w grupie), stara się utrzymać odległość od będących w jego pobliżu pozostałych boidów,
- Wyrównywanie – Oznacza, że dany boid porusza się w tym samym kierunku, w którym porusza się całe stado z tą samą prędkością,
- Spójność – Oznacza, że boid stara się utrzymać minimalny dystans od środka całej grupy.
Po pewnym czasie Raynolds dołożył kolejną zasadę:
- Omijanie – Oznacza, że boidy mogą patrzeć przed siebie, sprawdzając czy nie trzeba dokonać korekcji trasy, aby ominąć przeszkodę.
Ponieważ ten algorytm jest bezstanowy, czyli między uaktualnieniami, nie są przechowywane żadne dane. Każdy agent oblicza sobie co pewien czas jak wygląda sytuacja. Dzięki takiemu zachowaniu, nie tylko oszczędzamy pamięć, ale też pozwalamy boidom reagować w czasie rzeczywistym.
Jak to wykorzystać w grach? Można zoptymalizować ruch wielu jednostek na raz, np. w grach RTS. Dodatkowo, możemy pozwolić w realistyczny sposób włóczyć się zombie po lochu czy innym podziemiu. Do takich zastosowań wykorzystano tą technologię w grach takich jak Half-Life, Unreal czy Enemy Nations (RTS).
W zasadzie tyle. Nie ma tutaj czego za bardzo optymalizować.
Wykrywanie przeciwnika – Sensory
Sensory to jeden z często pomijanych elementów sztucznej inteligencji, który ma na nią ogromny wpływ. Co z tego, że postać umie podjąć decyzję, jeśli nie docierają do niej żadne bodźce? Pierwszą grą, która poważniej podeszła do tego tematu był Thief, gdzie jako złodziej skrywaliśmy się w cieniu i staraliśmy się zachować cicho, tylko dlatego, że przeciwnik nie mógł nas dostrzec w ciemności, a gdy byliśmy głośno, to mógł nas usłyszeć.
Do dziś, głównie w grach skradankowych, ten koncept mocno się rozwinął. Nie ma tutaj tak naprawdę bardzo wyrafinowanych rzeczy, modelujemy rzeczywistość w czystej postaci. Stożek naszego wzroku, czy sfera słyszalności to bardzo naturalne pojęcia, które rozumiemy odruchowo. Wykorzystując logikę rozmytą, możemy urzeczywistnić efekt. Tzn. przeciwnik zauważa nas słabiej i potrzebuje chwili, żeby nas zauważyć, kiedy jesteśmy na skraju jego stożka widoczności, a zauważy nas od razu, kiedy jesteśmy w centrum.
Ważne jest, że nie tylko ludzkie zmysły zaliczają się do sensorów. Kiedy kreujemy robota, to może on wykorzystać kamerę podczerwieni, albo radar. To też będą sensory i tylko od nas zależy jak je zaprogramujemy. Nic nie stoi na przeszkodzie stworzenia kosmity, który ma zasięg wzroku 360 stopni.
Druga istotna rzecz w tym temacie, to fakt, że czasami możemy oszukiwać. Myśląc o realistycznym podejściu, oczekujemy, że przeciwnik wie tyle, ile widzi. Ale! Czasami danie mu dostępu do wiedzy, do której nie powinien mieć dostępu, czyli np. dokładna odległość od gracza, albo stanu życia gracza, pozwala podjąć bardziej skomplikowane i realistyczne decyzje. Jeżeli przeciwnik zna stan życia gracza, może zadecydować, że skoro jest bardzo ranny to trzeba go szukać i dobić. Ma to faktyczne uzasadnienie. Widząc ranną osobę, widzimy cieknącą po niej krew albo że kuleje. Dając agentom dostęp do wiedzy o punktowym stanie życia gracza, możemy symulować właśnie fakt, że ranę dało się zauważyć.
Samo uczący się przeciwnik
Tym samym przebyliśmy wszystkie podstawowe techniki tworzenia sztucznej inteligencji. Jednak człowiek zawsze poszukuje czegoś lepszego. Wymyślono, że fajnie by było, gdyby agenci potrafili uczyć się w czasie gry, czy to od gracza, aby dynamicznie podnosić swój poziom. Takie coś, głównie stosują boty w grach sieciowych, które podkradają sposób przemieszczania się graczom. Pierwsze takie systemy pojawiły się w grach Unreal, czy Colin McRae Rally 2.
Sieci Neuronowe
Sieci neuronowe to system oparty o budowę ludzkich komórek mózgowych, czyli właśnie neuronów. Z biologicznego punktu widzenia (w uproszczeniu) działa to tak, że ciało neuronu otrzymuje pewną informację od dendrytu. W ciele wykonywane są obliczenia i następnie informacja jest przesyłana dalej przez aksony, które łączą się z dendrytami kolejnego neuronu. Tutaj mamy elektroniczny model tego zjawiska.
Od razu trzeba zaznaczyć, że sieci neuronowe to dużo wyższa szkoła jazdy. Połączone z logiką rozmytą i innymi technikami, potrafią dać nam naprawdę potężną, sztuczną inteligencję. Jednak ich implementacja nie jest ani prosta, ani przyjemna. Co możemy sobie wymodelować w ten sposób? W zasadzie wszystko. Narzędzie jest naprawdę potężne i pozwala na generowanie różnych rozwiązań, zależnych od potrzeb i umiejętności.
Cytując Andre LaMonte kilka przykładowych rozwiązań to:
- Skanowanie i klasyfikacja środowiska – Możemy sieć neuronową karmić wiedzą, którą potem wykorzystamy do wybierania odpowiedzi lub uczenia sieci. Sieć może się uczyć w czasie rzeczywistym, a tym samym ciągle optymalizować sieć,
- Pamięć – Sieć można wykorzystać jako swojego rodzaju pamięć. Uczyć ją nowych rzeczy, a wtedy gdy pojawi się nieprzewidziana sytuacja, sieć zareaguje inteligentnie,
- Sterowanie zachowaniem – Jako wejście możemy podać różne dane, a wtedy dane wyjściowe posłużą do sterowania zachowaniem postaci,
Wdawanie się w szczegóły implementacji może tutaj być bezcelowe, jednak posłużę się wiedzą Jeffa Hannana z Codemasters, który pracował nad sztuczną inteligencją w Colinie.
W ich przypadku sieć opierała się o dwie dane “Racing Line” i “Driving Model”. Czyli linia jazdy i model jazdy. Linia reprezentowała wiedzę na temat trasy. Szerokość trasy, zakręty do ścięcia, zakręty, których nie należy ścinać itd. Model jazdy składał się na informację na temat samochodu: jego pozycja, prędkość. Wtedy pojawia się problem przed jakim często stają ludzie, którzy chcą samo uczących się systemów. Dane treningowe.
Sieci neuronowe mogą uczyć się i podejmować decyzję, ale muszą mieć podstawową bazę wiedzy, na której się oprą. Dlatego w przypadku Colina, również przygotowano takie dane, czyli wejściowe informacje o trasie i pojeździe. Aby wygenerować te dane, autor musiał po prostu wyjeździć po torze odpowiednią liczbę razy. Jaka to liczba? Dla różnych sieci neuronowych, będzie ona inna. W przypadku Colina było to kilka tysięcy rajdów.
Późniejszy rozwój sieci neuronowej to próby, sukcesy i błędy. Dodawanie kolejnych danych wejściowych, różne rodzaje obliczeń, aż dostajemy efekt wyjściowy. W przypadku gry od Codemasters, wyjściem były flagi włączony/wyłączony reprezentujące różne klawisze na klawiaturze. Więc dostawaliśmy np. flagę włączony dla przycisku hamowania, przez co symulowaliśmy sytuację, gdzie kierowca naciska hamulec.
Jakie dane należy uwzględnić w sieci neuronowej? Wg. Hanana należy pilnować, aby było ich jak najmniej i nie dodawać redundantnych informacji. Warto eksperymentować z wprowadzaniem kolejnych informacji, aż otrzymamy najlepszy wynik.
Dysponująca sporą wiedzą sieć neuronowa, nie potrzebowała nauki dla każdej nowej trasy. Mając zebraną wiedzę, potrzebowała otrzymać tylko nowy “driving line” dla trasy i komputer był w stanie ją sam pokonać – i właśnie o to chodzi w sieciach neuronowych.
Sieć neuronowa to tylko jeden z przykładów szerszej dziedziny jaką jest uczenie maszynowe, jednak nie słyszałem, aby w grach wykorzystywano inne techniki, dlatego omawianie tego zagadnienia skończę na tym jednym przykładzie.
Sztuczna Inteligencja vs Unity3d
Jak już wiemy, sztuczna inteligencja to skomplikowany temat, a czasami wręcz bardzo trudny. Dlatego czasami warto wykorzystać gotowe rozwiązania, aby pracę sobie ułatwić, bądź nie wynajdywać koła na nowo. Dlatego przygotowałem krótkie zestawienie tego, co daje nam Unity, aby pracę ze sztuczną inteligencją przyspieszyć.
Mecanim
Nie do końca jest to narzędzie do sztucznej inteligencji, a bardziej kreowany był z myślą o zarządzaniu animacjami. Tak się jednak składa, że genialnie nadaje się do tworzenia maszyn stanów skończonych. Mamy tam konkretne stany, które mają między sobą przejścia oparte o różne zasady.
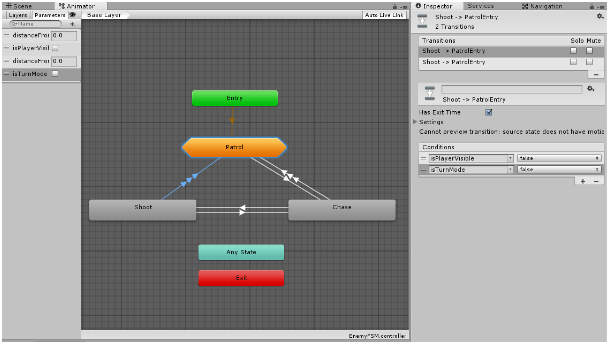
Wykorzystanie mecanima jako maszyny stanów skończonych
NavMesh
Genialne narzędzie do znajdowania ścieżki. Dzieli automatycznie teren na trójkątne obszary, oblicza za nas ścieżkę, potrafi omijać przeszkody i innych agentów, wyznacza koszt trasy, przez co można uwzględnić bagna, wodę czy drogę i zachęcać postać do korzystania z drogi. Dodatkowo mamy mechanizmy, które pozwolą przeskakiwać obszary, przy braku 100% spójności.

NavMesh w akcji
Collider i Rigidbody
To połączenie może wydawać się typowe i nic nie znaczące, jednak dodając oba komponenty do obiektu i pisząc odrobinę skryptu, możemy stworzyć sobie algorytm standy bez zbędnego rozpisywania się.
RAIN AI
RAIN AI to jeden z najpopularniejszych pluginów do tworzenia sztucznej inteligencji w grach, który wykorzystuje drzewa decyzyjne. Jest w 100% darmowy i również wykorzystuje Mecanima do wizualizacji tego jak wygląda nasze drzewo.
Apex Utility AI
Gdy wspomniałem o Utility AI padła nazwa firmy Apex, która również dostarcza darmowy plugin do Unity, pozwalający wprowadzić ich technologię. Wersja free ma pewne ograniczenia względem pełnej wersji, ale i tak warto sprawdzić to rozwiązanie.
Reaction AI
Kolejny darmowy plugin, tym razem realizujący sieć neuronową. Też darmowy. Można się nim pobawić, jeśli ktoś chce zgłębić tę tematykę. Problemem może być brak dokumentacji.
Dodatek A
Jako ciekawostkę dodam, że Unral Engine dysponuje narzędziem tworzenia drzew decyzyjnym domyślnie.
Jako ostatnie słowo dodam jedną ciekawostkę. Do dziś za najbardziej rozbudowane AI w grach komputerowych uznaje się to wykorzystane w F.E.A.R 3. Programiści wykazali się sporą kreatywnością i sprytem, ponieważ połączyli kilka technik tworzenia sztucznej inteligencji. Tego przypadku nie omówiłem w tym artykule, ale zrobię to przy kolejnej okazji.
Artykuł został pierwotnie opublikowany na blogu mwin.pl. Bardzo polecamy do niego zajrzeć, ponieważ autor porusza wiele ciekawych aspektów związanych z tworzeniem gier.
Podobne artykuły

PIN-UP.TECH: innowacyjny zespół wyznacza trendy w branży iGaming i rośnie z każdym dniem

Sztuczna inteligencja w grach - o rozwoju i największych wyzwaniach. Wywiad z Rafałem Tylem

Oto dlaczego naprawdę musisz nauczyć się Unreal Engine 5 w 2023 roku. Wywiad z Volodymyrem Ivanovem

Wgląd w animację gier wideo i rolę kombinezonu Xsens. Wywiad z Mykołą Kozak

Jak deweloperzy z Room 8 Studio pomogli stworzyć Metal: Hellsinger, jedną z najbardziej niezwykłych gier wydanych w 2022 roku

Dlaczego wszyscy przesiadają się na Unreal Engine 5 i Ty też powinieneś

Jak wygląda codzienność w studiu, które pracowało nad Call of Duty? Wywiad z Oleną Kycha
