Podejście monolityczne przy budowie rozwiązań opartych o DDD

Na grupie Devstyle Community pojawił się wątek z pytaniami: jak budować system oparty o DDD? y a serwCzy podejście “turbo pascal for enterprise” to jedyny wybór? Podejście monolityczne towarzyszy nam od zarania dziejów, ponieważ z założenia wszystko wtedy jest “prostsze”. Programista nie musi rozumieć do końca połączeń między usługami, jak każdy oddzielny komponent oddziałuje na inny i w jakiej kolejności, tak jak to jest w przypadku mikroserwisów. Czyli encje to rekordisy to procedury, więc powrót do starego dobrego Turbo Pascala. Chociaż…

Piotr Czech. Konsultant w firmie VLOG, gdzie wspiera rozwój oprogramowania u klientów. Budował systemy oparte o RODO oraz mobilne systemy telemetryczne zbierające i przetwarzający dane o kierowcach w celu obniżenia ubezpieczeń, między zadaniami na poprawianie bugów. Entuzjasta podejść architektonicznych w systemach oraz budowania wydajnych rozwiązań opartych o platformę .NET poprzez eksplorację nowych technik oraz uczenie innych… i gonienie ich, jeśli nie przykładają się do kodu.
Wzorce projektowe, SOLID, CQS i inne akronimy stwierdzają, że powinniśmy budować rozwiązania, które z założenia są małe, niezależne i można łączyć je jak klocki lego.
Dzisiaj opiszę jak można zapanować na rozgardiaszem, kiedy wszystko jest w jednym worku, zarazem jak oddolne ograniczenia pozwolą zapanować nad architekturą, kiedy projekt się rozrasta, terminy gonią a programiści lubią chodzić na skróty i co drugi commit ma w dopisku “hack” lub “fix”.
Spis treści
Struktura projektu
Przykładowy projekt i zarazem szablon, który opiszę dzisiaj znajdziecie na githubie pod nickiem xeinaemm. Szablon jest rozwinięciem architektury znanej pod nazwą Clean Architecture, którą stworzył m.in Steve “ardalis” Smith.
Architektura posiada w sobie zaimplementowane funkcjonalności do budowy aplikacji typu SPA (ang. Single Page Application) razem z HATEOAS REST API oraz DDD, przy użyciu .NET Framework i .NET Core.
Zaczynajmy!
“Cebulowa” architektura
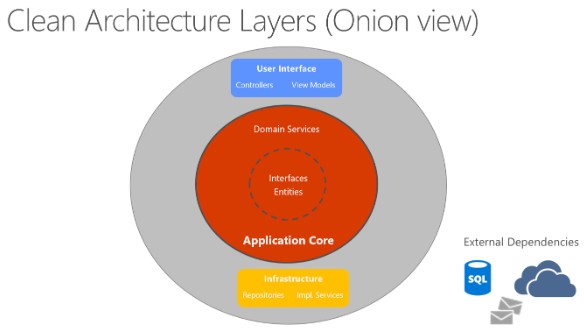
“Cebulowa” architektura jest prostym przykładem architektury wielowarstwowej, która pozwala zbudować projekt tak, że wewnętrzny okrąg nie ma pojęcia o tym zewnętrznym, więc z miejsca usuwamy cyrkulacje zależności. Każda warstwa ma inną odpowiedzialność, więc jesteśmy w stanie segregować odpowiednie komponenty i rozwiązania.
Core
Zadaniem tej warstwy jest zdefiniować “co?” szkielet rozwiązania biznesowego będzie zawierać. Oznacza to tyle, że będzie w sobie zawierać interfejsy, agregaty, kontekst związany, rozwiązania pomocnicze (np. implementacje HATEOAS).
Co najważniejsze w tym wszystkim, to jest ten rodzaj miejsca, w którym nie ma żadnych zależności do usług zewnętrznych. W .NETcie łatwo to spełnić, wystarczy posiadać projekt oparty o .NET Standard, w którym nie ma żadnych zależności poza samym .NET Standardem.
Takie podejście pozwala zdefiniować potrzebę biznesową bez martwienia się o rodzaj bazy, szyny danych czy jaki typ ORMa użyjemy, ponieważ z punktu widzenia biznesu i DDD są to szczegóły implementacyjne, które tworzą zewnętrzne zależności i nie powinny zaśmiecać tego miejsca.
Infrastructure
Druga warstwa definiuje “jak?” ostatecznie rozwiązanie będzie wyglądać, to oznacza, że w tym miejscu decydujemy o wyborze bazy danych, implementacji repozytoriów czy naszej domeny, która potrzebuje rozwiązań firm trzecich.
Te rozdzielenie odpowiedzialności pozwala na jedno bardzo fajne następstwo, w momencie, gdy będziemy chcieli usunąć część rozwiązania, zastąpić bazę danych to z punktu widzenia biznesu nic się nie zmieni.
Dzięki temu wymiana jednego komponentu na inny nie spowoduje efektu domina, ponieważ zależności są zbudowane na poziomie interfejsów(Core) a nie implementacji(Core + Infrastructure).
To co muszę nadmienić, najlepszym rozwiązaniem będzie stan, w którym uda Ci się zaimplementować potrzebę biznesową, która nie będzie posiadała zewnętrznych usług i będzie można ją umieścić w core.
Web(UI)
Zadaniem trzeciej warstwy jest po prostu wyświetlić wynik lub zebrać go, jeśli budujemy aplikacje typu SPA to zdefiniować dodatkowo API, modele do odczytu i zapisu danych.
Co najważniejsze, to jest ten rodzaj miejsca, który nie definiuje “jak?” model biznesowy będzie wyglądać tylko “gdzie?” go umieścić, aby użytkownik był w stanie z niego skorzystać.
Struktura widoku
Gdy korzystamy z tradycyjnego podejścia przy budowanie widoków (np. Razora dla .NETu) to faktycznie jesteśmy w stanie korzystać z interfejsów, implementacji bez zbędnego zastanawiania się jak coś działa, po prostu jedna kolekcja tu, druga kolekcja tam i prosty widok został stworzony.
Przy podejściu SPA tworzymy API (punkt zaczepienia), który wysyła i odbiera dane, pozwala to rozdzielić odpowiedzialność, aby widok nie wiedział nic nt. infrastruktury. Proste, dopóki założenia projektu się nie zmienią.

HATEOAS — święty graal REST API
Model dojrzałości Richardsona definiuje HATEOAS jako ostatni, trzeci poziom dojrzałości. Najcięższy, wymagający dyscypliny, dlatego przez wielu znienawidzony. Sam twórca Roy Fielding stwierdził kiedyś, że, “Unfortunately, people are fairly good at short-term design, and usually awful at long-term design”.
Nasz święty graal wymaga tej drugiej opcji, czyli dodatkowego nakładu pracy, tylko po co?
Dynamicznie odkrywane API pozwala rozwiązać kilka bolączek:
- Brak potrzeby konfigurowania punktów dostępu do API, dostajemy je razem z początkowym zapytaniem.
- Posiadamy samo dokumentujące się API.
- Brak zbędnej konfiguracji usuwa problem “magic stringów” i szukania mało widocznych błędów.
- Zmiany wprowadzone po jego upublicznieniu są mniej inwazyjne, łatwiej zmienić ścieżkę niż ręcznie zapisane punkty dostępu, ponieważ model pobierania danych jest identyczny dla każdego systemu.
Zarazem, źle zaprojektowanie API w tym modelu może wprowadzić:
- Słabą wydajność przez “nieskończoną” ilość zapytań o jedną informację, tak jak w urzędzie, gdzie przechodzimy z okienka do okienka bez oczekiwanego rezultatu.
- Patrząc na fakt, że frywolnie tworzone punkty dostępu mogą posiadać te same informacje, gdzie programista tak naprawdę wybiera swoją ścieżkę. Tylko komplikuje kod i jego użycie.
Pierwszy problem na ogół idzie rozwiązać przy pomocy pamięci podręcznej nagłówków, która nie wykonuje tego samego zapytania n-razy do serwera, ponieważ posiada już identyczne dane i przy standaryzacji punktów dostępu te dane na ogół będą już w pamięci podręcznej serwera.
Dzięki temu każdy jest w stanie korzystać z tych samych ścieżek, tylko w innej kolejności co zwiększa wydajność całego systemu. Trochę jak chodzenie wydeptanymi ścieżkami, które znamy na pamięć.
Drugi problem jest właśnie tym czym nie można nazwać HATEOAS. HATEOAS wymaga standaryzacji ścieżek dostępu do danych, dzięki czemu deweloperzy, którzy korzystają z API są w stanie zrozumieć jego działanie (samo odkrywanie) zarazem deweloperzy, którzy budują takie API muszą rozumieć jak działa ich dziedzina i w jaki sposób rozmieścić dane, aby dostęp do nich był jak na mniej inwazyjny i zarazem szybki.
Dlaczego takie podejście wybieram? Przecież często jest tak, że dostosowujesz API do widoku? Dla mnie jest to nierozsądne podejście, ponieważ domena jest jedna i znajduje się w Core, a UI ją odwzorowuje, więc posiada te same interfejsy, przez co nie zaciemniamy domeny. Jedyny mankament, na który trzeba zwrócić uwagę to tak zbudować domenę, aby infrastruktura oraz UI miały w miarę łatwy dostęp do danych i zarazem ich obróbki.
Wracając do rysunku wyżej, uważny czytelnik zauważy, że infrastruktura i UI są na tym samym poziomie, więc oba muszą umieć się ze sobą dogadać, ponieważ jedno implementuje, a drugie wyświetla, ale częścią wspólną i najważniejszą jest domena (Core) i tego trzeba się trzymać.
UI nie ma pojęcia o implementacji jaka znajduje się w infrastrukturze, więc nie jest w stanie nic zmienić, kontrolery jedynie wywołują konkretne metody zdefiniowane przez interfejs serwisu, a część widokowa pobiera dane według nadanych przez core encji(lub bardziej fachowo, DTO).
W .NETcie takie podejście rozwiązujemy za pomocą braku referencji projektu infrastruktury do weba lub budujemy osobną aplikację dla API i osobną dla SPA.
Jednak w tym drugim wypadku wchodzą aspekty związane z zabezpieczeniem punktów dostępu i całą otoczką uwierzytelniania konkretnych użytkowników. W idealnym świecie nawet osobne API nie powinno mieć dostępu do implementacji w infrastrukturze. Wynika to z faktu, że kontroler ma być głupi, nie posiada żadnej zależności do usług zewnętrznych poza zdefiniowanymi interfejsami serwisów w Core.
Czasami może to wyglądać tak, że budujesz adapter do własnej fasady…. aby ukryć metody rozszerzające, które zostały zdefiniowane w infrastrukturze lub inne mechanizmy pomocnicze.
Aby to wymusić całkowicie usuwamy referencje infrastruktury do API, a system podczas wdrożenia “skleja” biblioteki m.in dowiązując bibliotekę infrastruktury. Przy tym podejściu mamy pewność, że żaden programista nie zawróci kijem wisły i wszystkie zależności zostaną zdefiniowane na poziomie core’a, ponieważ tylko on jest udostępniany widokowi.
SPA
Tak jak wspomniałem wyżej, UI odwzorowuje domenę, ale co to znaczy?
Web ma być głupi, więc jego zadaniem jest podążać za corem, posiadać taki sam zestaw encji wyrażonych za pomocą interfejsów, jest to bardzo ważne ponieważ ten model automatyczne sprawdza poprawność naszych danych, interfejs w TypeScript nie przyjmie Ci danych, które nie są zgodne z interfejsem. Oznacza to tyle, że musimy trzymać domenę identyczną w dwóch miejscach.
Samą strukturę projektu SPA opisałem na Just Geek IT i znajdziecie ją pod tytułem: Jak zbudować własną bibliotekę w oparciu o Angulara. Znajduje się tam szczegółowo opisana architektura projektu oparta o Angulara i TypeScript.
DDD w teorii
Tyle razy wspominałem o DDD (ang. Domain Driven Design), domenie i pochodnych. Jednak po co to nam? DDD oznacza, że budujemy system tak, aby zaspokoić biznes, ale w taki sposób, że w idealnym świecie jesteśmy “rękoma” ekspertów w danej dziedzinie (np. logistycznej, bankowej). Oni nam mówią, że z ich strony wygląda to tak i my to odwzorowujemy, kalka w kalkę.
Tym sposobem, my rozumiemy kod, ekspert rozumie pojęcia i połączenia w systemie, dlatego takie ważne jest, aby wydzielić domenę (Core), ponieważ jest to miejsce, które musi rozumieć osoba niezwiązana z IT, bo ona patrzy i widzi te same połączenia jak w swojej codziennej pracy.
Co oznacza, że implementacja niezwiązana z domeną (infrastrukturą) jest im niepotrzebna i nie muszą jej znać. DDD to nie Scrum, nie trzeba używać wszystkich elementów. Tak naprawdę wykorzystanie encji, wartości i agregatów potrafi wiele uprościć.
Entity
Encje są podstawowym budulcem w DDD, ten typ posiada swoją tożsamość, nie jesteś w stanie porównać dwóch różnych encji na podstawie tylko atrybutów. Trzeba posiadać jej tożsamość (na przykład ID), które powie Ci czy masz przed sobą dwa identyczne obiekty.
Encję można porównać do nas samych, każdy z nas ma swój unikalny zestaw cech, gdybyśmy mieli się z kimś porównać to nie dalibyśmy rady powiedzieć, że jesteśmy identyczni, nawet gdybyśmy porównywali bliźniaki.
Jednak, gdybyśmy byli w stanie przenieść się w czasie i spotkać samego siebie to bez względu jak byśmy się różnili, dalej byśmy byli tą samą osobą, tą samą “encją”.
Value Object
Wartości ze względu na swoje zadanie, nie posiadają tożsamości, ich zadaniem jest porównać czy wszystkie pola są identyczne, trochę jak z pieniędzmi, 2 zł jest większe od 1 zł.
Aggregates
Agregaty są “obiektami na sterydach”, wiele podobnych obiektów domenowych można połączyć w “jeden” obiekt, za pomocą którego komunikuje się ze światem. Dobrym przykładem jest uczelnia.
Studenci, wykładowcy, dziekanat, egzaminy, przedmioty, wydział. Wszystkie obiekty i encje można połączyć w agregat znany jako uczelnia. Co w tym wszystkim jest najważniejsze? Jako osoba z zewnątrz nie masz dostępu do studentów, to uczelnia (aggregate root) decyduje jakie informacje zostaną Ci udostępnione (hermetyzacja).
Kolejną ważną rzeczą jest zastanowienie się nad wielkością agregatu, pakowanie wszystkiego do jednego agregatu jest tak samo bezsensowne jak stworzenie agregatu z jednego obiektu. W naszym wypadku, agregat jako uczelnia jest za duży i warto byłoby go podzielić na mniejsze agregaty jak wydział, kadra akademicka czy grupy naukowe.
To co chciałbym Ci powiedzieć, nie ma prawidłowej odpowiedzi na to pytanie jakiej wielkości powinny być agregaty, jest to element wyczucia i intuicji, zmniejszasz lub zwiększasz ilość elementów do takiego momentu aż krzykniesz “Aha! Tak ma być!”.
Dobrym wyznacznikiem czy coś można połączyć w agregat jest moment, w którym widzisz, że dwa obiekty domenowe komunikują się ze sobą w ciągły sposób.
Domain Event
Nie zdałeś kiedykolwiek egzaminu przez co zawaliłeś przedmiot? Jeśli tak, to doświadczyłeś zdarzenia domenowego (ang. Domain Event). Zadaniem zdarzeń jest odpowiedzieć na konkretne zdarzenie innym zdarzeniem w sposób automatyczny lub przesłać informacje z jednego kontekstu związanego do innego.
Shared Kernel
Uważny czytelnik zauważy, że w agregatach użyłem sformułowania “[…]studenci, wykładowcy[..]” jako różne obiekty.
Tak faktycznie dla mnie jest to ta sama encja, zadaniem współdzielenia obiektów w domenie jest wydzielić takie elementy, który dla kontekstów związanych (ang. Bounded Context) są wspólne, w tym przypadku osoba jako encja jest takim przypadkiem, który będziemy używać w całej domenie.
Częścią wspólną dla bankomatu i automatu z przekąskami jest pieniądz, a dla uczelni i organizacji studenckiej jest człowiek.
Gdy część wspólna się rozrasta, można pomyśleć o jej wydzieleniu, najlepiej w postaci prywatnego nugeta (jeśli mówimy o rozwiązaniach w .NET) i włączeniu jej jako referencji do Core, to jest jedyny wypadek, gdy pozwalamy na zewnętrzną zależność. Kolejną rzeczą jest to, że nawet jeśli obiekt nadaje się do wydzielenia jako część wspólna to nie znaczy, że powinien tam trafić.
W naszym wypadku jak mówimy o człowieku to zarazem może to być zbawienie jak i utrapienie. W momencie zmiany założeń każdy kontekst związany będzie musiał być zmieniony i może to oznaczać równie dobrze niespełnienie wymagań innego kontekstu.
Z drugiej strony, jeśli używamy takich rozwiązań jak Active Directory, systemu uprawnień i pozwoleń to wydzielenie osoby jako bytu o podstawowych cechach pozwoli nam zintegrować ze sobą usługi, ale zawsze trzeba się zastanowić czy przyniesie to oczekiwany zysk, dlatego z założenia konteksty związane nie dzielą między sobą encji.
Bounded Context
Kontekst związany łączy wiele agregatów, encji połączonych ze sobą w spójny sposób za pomocą odpowiednich mechanizmów jak repozytoria, serwisy czy specyfikacje. Sam w sobie jest niezależnym bytem, który może działać samoistnie.
Przykładami kontekstów związanych jest bankomat, automat z przekąskami, uczelnia czy organizacja studencka. Tak jak wspominałem wcześniej, agregat jako uczelnia jest zbyt duży, ponieważ można go rozbić na mniejsze agregaty, encje, wartości i obiekty, więc w tym wypadku można go nazwać kontekstem związanym.
Aby posiąść wiedzę domenową musimy przysiąść do książek z danej dziedziny i uczyć się jak ona działa. Chcesz zbudować system logistyczny do transportu towarów? Najpierw musisz zostać logistykiem, kod w tym momencie schodzi na dalszy plan.
Specification
Specyfikacja jest wzorcem projektowym, który wywodzi się ze wzorca kompozytu. Jego zadaniem jest definiowanie złożonych modeli biznesowych.
Oddziela implementacje zapytania od faktycznego wykonania, dzięki temu jesteśmy w stanie zbudować generyczne zapytanie, w którym podajemy szkielet zapytania, a faktyczna implementacja będzie zależeć od wymagań biznesowych.
Przykładowy interfejs będzie wyglądał tak:
public interface ISpecification<T>
{
Expression<Func<T, bool>> Criteria { get; }
List<Expression<Func<T, object>>> Includes { get; }
List<string> IncludeStrings { get; }
}
Pobieranie kolekcji w tym wypadku przez repozytorium będzie wyglądać tak:
public List<TEntity> GetCollection<TEntity>(ISpecification<TEntity> specification = null) where TEntity : BaseEntity
{
if (specification == null) return _dbContext.Set<TEntity>().ToList();
var queryableResultWithIncludes = specification.Includes
.Aggregate(_dbContext.Set<TEntity>().AsQueryable(),
(current, include) => current.Include(include));
var secondaryResult = specification.IncludeStrings
.Aggregate(queryableResultWithIncludes,
(current, include) => current.Include(include));
return secondaryResult
.Where(specification.Criteria).ToList();
}
A sama w sobie implementacja specyfikacji tak:
public sealed class CourseSpecification : BaseSpecification<Course>
{
public CourseSpecification(Guid studentId) : base(course => course.StudentId == studentId)
{
AddInclude(b => b.Student);
}
public CourseSpecification(Guid studentId, Guid courseId) : base(course =>
CourseCriteria(course, studentId, courseId))
{
AddInclude(b => b.Student);
}
private static bool CourseCriteria(Course course, Guid studentId, Guid courseId)
{
if (course == null) return false;
if (studentId != Guid.Empty && courseId != Guid.Empty)
return course.StudentId == studentId && course.Id == courseId;
if (studentId != Guid.Empty) return course.StudentId == studentId;
return false;
}
}
Zmiana wymagań biznesowych pociąga za sobą tylko zmianę specyfikacji zamiast przebudowywania repozytorium.
Podsumowanie
Mam nadzieję, że wyniosłeś z tego artykułu jakąś ciekawą lekcję. Jeśli jesteś głodny wiedzy to Steve przygotował ebook pod tytułem Architecting Modern Web Applications with ASP.NET Core and Microsoft Azure. Opisuje w niej dokładnie na co zwracać uwagę przy budowie architektury oraz jakie inne wzorce projektowe można wykorzystać podczas budowy oraz ewangelizacji programistów. A tymczasem, do następnego!
Zdjęcie główne artykułu pochodzi z stocksnap.io.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
