Optymalizowanie kodu. Przedwczesna optymalizacja oraz konwencje nazewnicze w Javie
Są co najmniej trzy znane cytaty odnośnie optymalizacji:
More computing sins are committed in the name of efficiency (without necessarily achieving it) than for any other single reason — including blind stupidity — William A. Wulf.
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil — Donald E. Knuth.
We follow two rules in the matter of optimization: Rule 1. Don’t do it. Rule 2 (for experts only). Don’t do it yet — that is, not until you have a perfectly clear and unoptimized solution — M. A. Jackson.

Marcin Lasota. Java Developer w Transition Technologies. Programowania uczył się na własną rękę. Zaczął od technologii webowych, a obecnie skupia się na Javie i jej ekosystemie, od czasu do czasu wracając do frontendu. Pierwsze kroki zaczął stawiać pod koniec trzeciego roku technikum informatycznego, w którym jednak programowania nie było (tylko prosta webówka). Programowanie spodobało mu się na tyle, że chciałem z tym wiązać przyszłość. Po technikum zamierzałem dalej studiować informatykę, jednak po analizie plusów i minusów postanowił zrezygnować ze studiów w tym kierunku i jak na razie jest zadowolony z tego wyboru.
Wszystkie trzy cytaty poprzedzają język programowania Java o co najmniej dwie dekady, jednak nadal są aktualne i mówią świętą prawdę o optymalizacji – łatwiej narobić nią szkód niż przynieść korzyści, szczególnie jeśli mowa o przedwczesnej optymalizacji.
Nie warto poświęcać dobrego designu na rzecz wydajności – lepiej pisać dobre programy niż szybkie. Jeśli dobry program nie jest wystarczająco wydajny, jego architektura pozwoli go później zoptymalizować. Dobre programy przestrzegają zasady enkapsulacji danych, więc pojedyncze decyzje mogą być zmienione bez wpływu na pozostałą część systemu.
Nie znaczy to też, że powinniśmy ignorować problemy wydajnościowe, dopóki nie skończymy programu. Problemy implementacyjne mogą być naprawione późniejszą optymalizacją, ale wszechobecne wady architektury ograniczające wydajność mogą nie być możliwe do naprawy bez przepisywania całego systemu od nowa.
Najtrudniej wprowadzić zamianę w komponentach, które zawierają interakcje pomiędzy komponentami, a światem zewnętrznym np. API czy formaty przesyłania danych. Mogą też narzucić znaczne ograniczenia wydajności, dlatego te części systemy trzeba zaprojektować z największą starannością.
Więc nie możemy całkiem przestać myśleć o optymalizacji. Zawsze trzeba rozważać konsekwencje naszych wyborów np. tworząc typ mutowalny, możemy wymuszać na kliencie wiele zbędnych kopii defensywnych. Podobnie, używając dziedziczenia w publicznej klasie zamiast kompozycji, zszywamy daną klasę z nadklasą na zawsze, co może skutkować ograniczeniami podklasy. Tak samo używając w API typu implementacji zamiast interfejsu, wymuszamy tylko jedną konkretną implementację, mimo to, że w przyszłości mogłaby być napisana bardziej wydajna wersja. Jeśli system jest używany tylko wewnętrznie i możemy całkowicie przebudowywać kod, to nie ma to aż takiego znaczenia, ale po co sobie utrudniać życie?
Na szczęście zazwyczaj dobry design idzie w parze z dobrą wydajnością lub z łatwą możliwością na jej poprawę. Kiedy zaprojektowaliśmy czysty i dobrze ustrukturyzowany kod, to wtedy może być czas na rozważanie optymalizacji, która w dobrze zaprojektowanym systemie jest łatwa do wprowadzenia. Nigdy nie powinniśmy skupiać się na optymalizacji kosztem spaczonego designu.
W określeniu, gdzie powinniśmy skupić naszą uwagę podczas optymalizowania systemu, mogą pomóc nam profilery. Te narzędzia dają takie informacje jak np. czas, w jakim każda metoda się wykonuje i jak wiele razy miało to miejsce. Innym narzędziem, o którym warto wspomnieć, jest framework do benchmarków JMH, którym możemy zmierzyć wydajność poszczególnych kawałków kodu. Warto skorzystać z tego narzędzia, aby porównać zoptymalizowany kod, czy aby na pewno wydajność jest lepsza, czy tylko nam się tak wydaje.
Konwencje nazewnicze w Javie
Ten temat jest dosyć rozwlekle opisany w książce, jednak myślę, że tu nie ma co się rozdrabniać – podam same konkrety. W Javie (jak i w każdym innym języku) mamy powszechnie uznawane konwencje nazewnicze, których należy się trzymać. Można powiedzieć, że dzielą się na dwie grupy – typograficzne i gramatyczne.
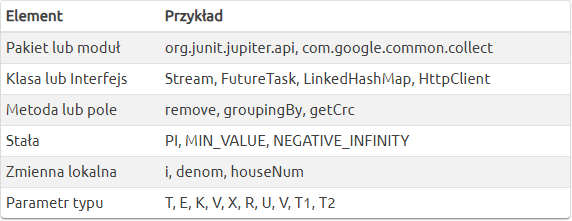
Nazwy pakietów i modułów powinny być zwięzłe i składać się wyłącznie z małych liter. Zalecane też są opisowe skróty np. util zamiast utilities lub akronimy. Nazwa pakietu, który będzie używany poza naszą organizacją, powinna zaczynać się od odwróconej nazwy domeny np. com.google.
Klasy i interfejsy włączając w to enumy i adnotacje powinny zaczynać się wielką literą i dalej CamelCase. Często dyskusji podlega problem, czy akronimy powinny być całe pisane wielkimi literami, czy nie. Według mnie nie – tylko pierwsza litera powinna być pisana z dużej, szczególnie gdy mamy w nazwie dwa akronimy. Wolałbyś widzieć klasę nazwaną HTTPURL czy HttpUrl?
Metody i pola obowiązują te same zasady tyle, że zaczynamy małą literą. Wyjątkiem od tej zasady są pola stałe (static final + niemutowalne), które powinny być zapisane dużymi literami, a poszczególne słowa oddzielone podłogą. Stałymi są również wartości enumów.
Zmienne lokalne mają już większą dowolność co do nazwy, ale powinny być opisowe i oczywiście zaczynać się z małej litery. Nazwy parametru typu składają się z jednej dużej litery. Najczęściej używa się:
Tdla jakiegoś typu (jeśli jest więcej niż jeden, to kolejnoT,U,VlubT1,T2,T3),Edla typu elementu kolekcji,KiVdla typu klucza i wartości mapy,Xdla typu wyjątku,Rdla typu zwracanego przez funkcję.
Podsumowując:
Odnośnie konwencji gramatycznych, które nie są już tak bardzo konieczne jak te typograficzne, to zazwyczaj nazwy klas instancjonowalnych są rzeczownikiem w liczbie pojedynczej jak np. Thread, PriorityQueue czy ChessPiece. Z kolei nazwy nieinstancjonowalnych klasy typu utility często są w liczbie mnogiej np. Collectors czy Collections. Interfejsy zazwyczaj nazywane są tak jak klasy np. Collection czy Comparator, ale też z końcówkami able lub ible np. Runnable, Iterable czy Accessible.
Metody, które:
- wykonują jakieś akcje standardowo są czasownikami np.
appendlubdrawImage, - zwracają
booleanzazwyczaj zaczynają się odislubhas+ rzeczownik np.isDigit,isProbablePrime,isEmpty,isEnabledlubhasSiblings, - zwracają jakąś daną zazwyczaj zaczynają się od
getlub bezpośrednio nazwa tej danej np.size,hashCodelubgetTime, - konwertują obiekt w inny zazwyczaj nazywają się
toTypenp.toStringlubtoArray, - zwracają inny widok zazwyczaj nazywają sie
asTypenp.asList, - są statycznymi fabrykami zazwyczaj nazywają się
from,of,valueOf,instance,getInstance,newInstance,getTypelubnewType.
Artykuł został pierwotnie opublikowany na devcave.pl. Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
