Mikroserwisy, wyzwania rozproszonej architektury

Wielu z Was zapewne słyszało o bardzo popularnej ostatnimi laty architekturze tzw. mikroserwisów, będącej przykładem systemu rozproszonego, który składa się z szeregu usług (dziesiątki, setki, a nawet tysiące instancji „niewielkich” aplikacji) nierzadko kolaborujących ze sobą w celu wymiany danych, bądź wykonania pewnego rozbudowanego procesu biznesowego.

Piotr Gankiewicz. Microsoft MVP, trener Bottega IT Minds, inżynier oprogramowania oraz kontrybutor open source. Zwolennik DDD, CQRS, systemów rozproszonych i DevOps. Aktualnie rozwija klienta .NET Core dla Ethereum Blockchain w Nethermind.io.
Dzięki zastosowaniu takiego podejścia można uzyskać wiele ciekawych korzyści m.in.:
- Skalowalność asymetryczna – skalowanie horyzontalne tzn. wszerz poprzez dowolne zwiększanie liczby instancji wybranych usług, które mogę być najczęściej wykorzystywane lub pochłaniające najwięcej zasobów (np. CPU, RAM, czas wykonania).
- Autonomiczność – niezależne od siebie zespoły pracujące nad aplikacjami, gdzie kod źródłowy przetrzymywany jest w dedykowanych repozytoriach, co powoduje znacznie mniejsze oraz łatwiejsze zarówno w zarządzaniu, jak i wdrażaniu projektów, będące składowymi większego systemu.
- Odporność (resiliency) – zwiększenie niezawodności systemu, nie będącego już monolitem (a gdy najmniejsza nawet część monolitu nie działa, to cóż… nic nie działa). Możemy wyobrazić sobie sytuację, w której np. nie jesteśmy w stanie dodać produktu do koszyka, ale nadal możemy je przeglądać, ponieważ są to 2 niezależne od siebie usługi (aplikacje).
Listę potencjalnych benefitów wynikających z zastosowania mikroserwisów można mocno rozszerzyć i nie ukrywajmy – problemy wydajnościowe, zazwyczaj są jednym z głównych powodów, dla których decydujemy się na rozbicie naszej jednolitej aplikacji na mniejsze, w celu wydzielenia właśnie tychże części, pochłaniających najwięcej zasobów.
Osobiście optuję za wspomnianym wyżej podejściem, zwłaszcza w przypadku osób oraz zespołów nie mających wcześniejszej styczności z takim wzorcem architektonicznym. Zacznijmy od klasycznego monolitu, zmierzając w kierunku tzw. monolitu modularnego, czyli takiego, w którym nie boimy się podmieniać komponentów czy np. baz danych, z którymi takie komponenty współpracują – tak, aby w ramach pojedynczej instancji naszej aplikacji, poszczególne jej moduły „myślały”, że są faktycznie ze sobą niepowiązane. Dopiero wtedy spróbujmy je faktycznie wydzielić jako osobne procesy (jeżeli będzie taka potrzeba). Temat ten bardzo dobrze przedstawił w swoim wystąpieniu mój kolega Radek Maziarka w prelekcji pod tytułem „Mikroserwisy – technologiczne piekło”.
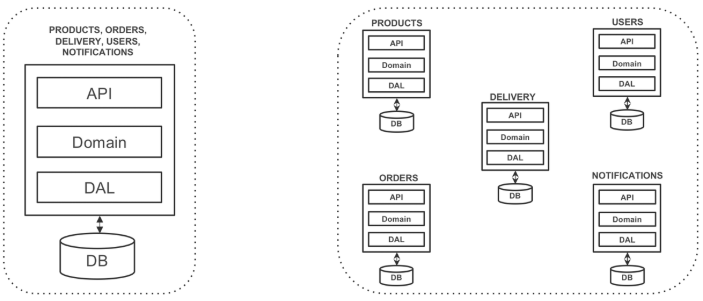
Nie chciałbym natomiast zakończyć artykułu w tym miejscu, gdyż poza samą przestrogą przed używaniem mikroserwisów (czy też innego podejścia, które ma potencjalnie rozwiązać wszystkie nasze problemy), nie niesie on za sobą głębszej treści.
Zanim przejdziemy w konkretne problemy i związane z nim „technikalia”, chcę tylko zaznaczyć, że nie zamierzam się skupiać na kwestiach „miękkich” tzn. dotyczących projektowania lub wydzielania granic naszych usług – jeżeli interesuje Cię jak rozmawiać z „biznesem” i odnaleźć, w którym miejscu dana mikrousługa ma swój początek, a w którym koniec, zachęcam do przestudiowania tematyki Domain Driven Design (DDD) oraz zapoznaniem się z takimi technikami jak np. Event Storming.
Zobaczmy zatem z czym przyjdzie nam się zmierzyć tworząc mikroserwisy (a jest to tak naprawdę tylko wierzchołek góry lodowej).
Spis treści
Niezależne repozytoria
Nie jest to może kwestia aż tak bardzo techniczna, natomiast bardzo istotna. Dążymy do tego, aby nasze aplikacje były utrzymywane w całkowicie niezależnych od siebie repozytoriach. Jest to pewien narzut organizacyjny, jednakże dający szereg wymiernych korzyści – możliwość przypisania konkretnych zespołów do konkretnych repozytoriów, odseparowany od siebie kod źródłowy wielu aplikacji (nie będzie nas kusić dodawanie referencji pomiędzy projektami wchodzącymi w skład większej solucji), a przede wszystkim możliwość definiowania tzw. „pipelinów” związanych z CI & CD naszych „mikro” aplikacji (budowanie, a przede wszystkim wdrażanie).
Pamiętajmy również, że jedną z potencjalnych zalet, o których wcześniej nie wspomniałem jest możliwość tworzenia usług w całkowicie odmiennych technologiach – zazwyczaj wspólnym mianownikiem jest możliwość komunikacji HTTP (ekspozycja Web API) i ewentualne podłączenie do kolejki wiadomości (RabbitMQ, Kafka itp.) czyli coś, co jest obsługiwane przez prawie każdą większą technologię związaną z konkretnym językiem programowania.
API Gateway
Zakładając, że posiadamy zbiór rozproszonych aplikacji, jedno z pierwszych pytań jakie nam się nasunie będzie dotyczyło ich udostępnienia dla świata zewnętrznego. Posiadając N usług, czy faktycznie powinniśmy je wszystkie „wystawić” na świat? Postawmy się teraz w roli użytkownika końcowego (możemy go również rozumieć jako zewnętrzny system, komunikujący się z naszymi usługami w celu integracji) – czy na pewno chcielibyśmy, aby konsument naszych mikroserwisów wiedział o istnieniu ich wszystkich?
Pójdźmy krok dalej – posiadamy pewne mechanizmy uwierzytelniania oraz autoryzacji, które mogą być mocno rozbudowane, a każda z usług może posiadać własne polityki dostępu do danych. Ale to nie wszystko – co jeżeli chcemy pobrać pewien większy zbiór danych wymagający „odpytania” np. kilku usług i następnie agregacji oraz transformacji, przykładowo podejście map-reduce?
Nie wspominając już o tym, że usługi mogą operować na różnych protokołach komunikacji bądź budowy ich API (Web API, JSON RPC, gRPC, SOAP itd.), mając dynamicznie przydzielane adresy IP dodatkowo „przeskalowane” horyzontalnie w wielu instancjach” – jak nasz biedny użytkownik ma się w tym wszystkim odnaleźć?
Owszem, możemy mu dostarczyć bogatą dokumentację opisującą proces pobrania np. szczegółów zamówienia w zaledwie 10 stronach. Możemy również zrobić to, co jako programiści potrafimy zrobić naprawdę dobrze, czyli przenieść poznane przez nas wzorce i dobre praktyki programistyczne „poziom wyżej”. Zastosujmy tutaj dodatkową warstwę abstrakcji poprzez utworzenie dedykowanej usługi tzw. API Gateway będącego fasadą, ukrywającą przed użytkownikiem końcowym złożoność systemu.
Niechaj konsument naszych mikrousług, komunikuje się z nimi wszystkimi przez pojedynczą aplikację (oczywiście możemy mieć dedykowane „bramki” np. dla aplikacji webowych, mobilnych i desktopowych), która ukryje przed nim wszystkie kwestie infrastrukturalne i tzw. cross-cutting concerns (uwierzytelnianie, autoryzacja, routing, load balancing, transformacja danych itp.).
Pozostaje pytanie jak utworzyć Gateway? W celach edukacyjnych można to zrobić samodzielnie, ale prawdopodobnie lepiej skorzystać z gotowych usług – wiele z nich jest komercyjnych choć nie wszystkie np. Kong Gateway (w wersji „community”), który może być dobrym punktem startowym.
Wewnętrzna komunikacja
W poprzednim punkcie napomknąłem o komunikacji, która może odbywać się czy to na poziomie API Gateway –> Usługi czy też pomiędzy usługami, które nierzadko wymieniają pomiędzy sobą dane. W tym miejscu pojawią się dwa fundamentalne pytania – skąd usługa A ma wiedzieć, gdzie aktualnie znajdują się instancja usługi B (zakładając, że A posiada potrzebę komunikacji z B) oraz co jeśli B posiada wiele instancji (która instancja aktualnie jest najmniej „obłożona” pracą).
W świecie systemów rozproszonych i narzędzi do orkiestracji takich jak np. Kubernetes nasze aplikacje będą wdrażane w różnych miejscach, posiadając dynamiczne przydzielane adresy IP w obrębie wirtualnej sieci prywatnej. Nie możemy tutaj polegać na „sztywnej” konfiguracji w kodzie, poza tym, dlaczego nasza aplikacja w ogóle musiałaby posiadać taką wiedzę? Oczywiście istnieje remedium na opisany właśnie problem – potrzebujemy dedykowanego rozwiązania dla tzw. service discovery.
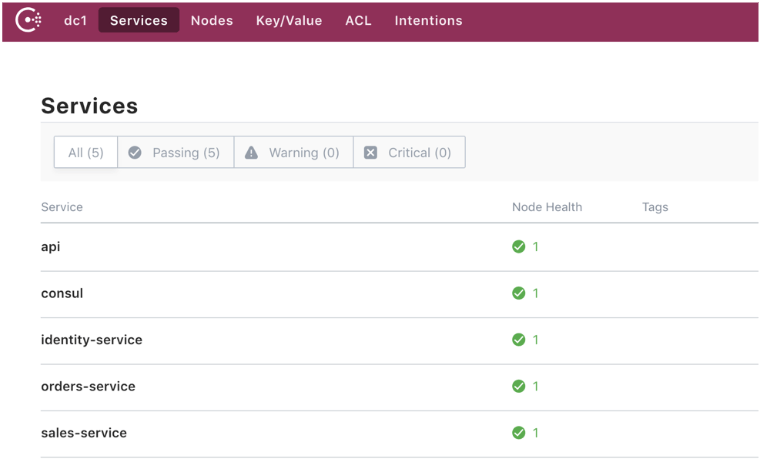
Jednym z takich narzędzi (dodatkowo całkowicie otwartych i darmowych) jest np. Consul. Filozofia działania Consula jest następująca – dostarcza on tzw. service registry, czyli scentralizowany rejestr usług, które rejestrują się w nim samodzielnie przy starcie aplikacji, podając nazwę (np. grupa usług typu products-service) oraz dowolny, unikalny id. Consul za pomocą mechanizmu „health-check” na bieżąco weryfikuje, które instancje są dostępne, a które należy usunąć z rejestru.
Wracając do oryginalnego problemu – posiadamy dwa niezależne od siebie usługi A oraz B, które potrzebują się skomunikować. Zarówno A, jak i B przy starcie zarejestrują się w Consulu (wysyłając żądanie do Web API), a gdy usługa A będzie chciała odpytać usługi B np. o dane, to najpierw poprosi Consula o listę aktualnie dostępnych instancji listy B, wybierze np. pierwszą z nich (w tym przypadku zastosowany jest najprostszy mechanizm dla load balancing czyli round robin) i dopiero wtedy wyśle zapytanie do aplikacji B.
Load Balancing
Poprawna, a przede wszystkim przemyślana dystrybucja ruchu pomiędzy usługami jest kluczowa. Co z tego, że usługa B posiada 10 instancji, skoro ciągle przesyłamy żądania do instancji nr 1, a pozostałe 9 jest praktycznie nieużywanych? Tak jak wspomniałem w przypadku Consul mamy dostępny domyślnie mechanizm round robin, jeżeli potrzebujemy czegoś bardziej wyrafinowanego (np. load balancing bazujący na średniej ważonej obliczanej z czasów odpowiedzi konkretnych instancji) to możemy pomyśleć nad dedykowanym load balancerem, jak np. Traefik. Jednym z ciekawszych rozwiązań, które wykorzystuje Consul jest otwarty projekt stworzony przez eBay nazwany Fabio.
Filozofia jego działania jest bardzo prosta – bazując na usługach zarejestrowanych w Fabio, buduje on dynamiczną tablicę routingu i w zależności od wybranego trybu działania (round robin albo randomized round robin) kieruje ruch do konkretnej instancji wskazanego mikroserwisu. Pozwala również rozbudowaną konfigurację, umożliwiającą wskazanie „wagi” (tzn. jaka część żądań ma zostać przesłana do danych instancji), co jest bardzo przydatne w podejściu A/B testing, gdzie niewielki % żądań przesyłamy do nowej wersji aplikacji, aby zweryfikować na znacznie mniejszym zbiorze użytkowników czy super ficzer spełnia swoje założenia.
Używając Fabio w oparciu o Consul, nie musimy już za każdym razem pytać rejestru o listę dostępnych instancji – po prostu przesyłamy wszystkie zapytania przez Fabio np. http://localhost:9999/products-service, gdzie products-service jest specjalnym znacznikiem (tag) podawanym w trakcie rejestracji usługi w Consul i nie przejmujemy się już niczym więcej – Web API konkretnej mikrousługi jest w pełni dostępne, a ruch zostanie poprawnie rozłożony pomiędzy wszystkie jej instancje.
Asynchroniczność
Czymże byłby system rozproszony, który działałby w pełni synchronicznie? Jedną z zalet tworzenia mikroserwisów jest możliwość uzyskania doskonałej wydajności, właśnie przez skalowanie asymetryczne. Natomiast musimy pamiętać o pewnej bardzo ważnej kwestii – za każdym razem, gdy w sposób synchroniczny komunikujemy się pomiędzy usługami, przykładowo A wysyła żądanie HTTP do B przez Web API, zachodzi „zjawisko” tzw. temporal coupling, czyli tymczasowego powiązania w tym przypadku pomiędzy usługami, gdzie jedna z nich synchronicznie oczekuje na odpowiedź od drugiej (nie mam tutaj na myśli używania Task, Future, Promise, async, await w naszym kodzie tylko powiązania na poziomie komunikacji odrębnych aplikacji).
Jeżeli chcemy, aby nasz system był jak najbardziej stabilny i odporny (resilient) dążymy do tego, aby wspomniany temporal coupling eliminować. Jak możemy to zrobić? Jednym z rozwiązań jest zastosowanie np. kolejki wiadomości, do której będą przesyłane rozkazy (commands) oraz zdarzenia (events). Command stanowi intencje użytkownika – zrób coś np. dodaj produkt (CreateProduct), podczas gdy event opisuje pewien fakt np. produkt został dodany (ProductCreated).
Usługi będą zarówno publikować zdarzenia (przesyłając je do kolejki wiadomości), jak i subskrybować się na rozkazy, które powinny wykonać (np. Products Service będzie nasłuchiwać na komendy związane z zarządzaniem produktami). Wszystko to dzieje się w pełni asynchronicznie i zjawisko temporal coupling praktycznie nie zachodzi. Niezależnie czy wykorzystamy kolejkę wiadomości tylko do obsługi zdarzeń w systemie, czy też będziemy wykonywać rozkazy w sposób asynchroniczny (API Gateway zamiast przekierowując np. HTTP POST do konkretnej usługi, po prostu przekaże wiadomość do kolejki i zwróci użytkownikowi kod 202 Accepted) w taki sposób możemy bardzo mocno wpłynąć (w jak najbardziej pozytywnym znaczeniu) na wydajność oraz niezawodność całego systemu.

Duplikacja kodu
Jako programiści żyjemy w przekonaniu, że powielanie identycznego kodu, to całkowicie niepotrzebna oraz potencjalnie groźna redundancja, którą musimy wyeliminować za wszelką cenę. Zaznajomieni z dobrymi praktykami tworzenia oprogramowania oraz zasadami takimi jak SOLID czy DRY, uwielbiamy dokonywać refaktoryzacji kodu, tworząc zwięzłe metody oraz abstrakcje wykorzystywane w wielu miejscach – podejście jak najbardziej dobre i słuszne, natomiast w przypadku systemów rozproszonych nie zawsze zalecane, gdyż one rządzą się swoimi prawami. Pamiętasz gdy wspominałem o wydzieleniu osobnych repozytoriów dla niezależnych od siebie usług, a dodatkowo w poprzednim punkcie napomknąłem o kolejce wiadomości? Tak, już jestem prawie pewny co Ci świta w głowie.
Stwórzmy współdzielone paczki (Shared/Common/Util/Helper czy inne cudo), które będą wykorzystywane przez wszystkie nasze aplikacje (lub przynajmniej te, które wykorzystują ten sam język programowania lub framework). W tychże paczkach napiszemy kod związany z szeroko pojętymi cross-cutting concerns oraz wszystko inne, co wykorzystujemy w wielu miejscach i robimy to naprawdę często.
W tym momencie jestem w stanie Ci przyklasnąć i zaakceptować takie rozwiązanie.
Mikroserwisowi puryści zazwyczaj stwierdzą, że nie powinno być żadnego współdzielonego kodu, nawet w postaci paczek, ja uważam, że przede wszystkim trzeba być pragmatycznym i jeżeli 10 raz mam pisać ten sam kod do połączenia z kolejką wiadomości, to być może faktycznie go wydzielę i opublikuję jako niewielką paczkę typu NuGet (zakładając, że jestem programistą .NET / .NET Core). Natomiast w tym miejscu powiedziałbym stop i nie szedłbym dalej w kierunku, o którym pewnie myślisz – pojedyncza paczka zawierająca wszystkie kontrakty (typy wiadomości) wykorzystywane w całym systemie. Tutaj bardzo łatwo strzelić sobie w stopę – nagle wszystkie zespoły muszą mieć dostęp do pojedynczego repozytorium (łatwo o potencjalne konflikty i błędy), nietrudno pogubić się w wersjonowaniu paczek (oraz wiadomości), a przede wszystkim, czemu tak naprawdę ma mnie obchodzić jakie dane są wykorzystywane w 99 pozostałych usługach, skoro mnie interesuje tylko 1?
Co zatem możemy zrobić? Rozwiązanie jest bardzo proste – zastosujmy doskonale znany wzorzec „kopiego-pasta” (CTRL+C + CTRL+V) i po prostu w danych usługach zdefiniujmy w postaci plików/klas/struktur typy wiadomości czy DTO jakie nas faktycznie interesują. Używając elastycznego mechanizmu serializacji danych jak np. JSON jesteśmy w stanie poradzić sobie nawet z potencjalnymi problemami wersjonowania danych (zakładając, że nie zmieniamy typów już istniejących właściwości obiektów, dopóki wszystkie usługi nie będą korzystać z najnowszych wersji). Pomóc nam tutaj może Swagger oraz narzędzia do generowania klientów API, dzięki czemu nie będziemy musieli samodzielnie pisać zbyt dużo kodu, a i tak uzyskamy pełną separację pomiędzy mikroserwisami.
Duplikacja danych
Jeżeli podobnie jak ja jesteś absolwentem studiów na kierunku informatycznym, bądź pracujesz z bazami danych typu SQL, zapewne nie jest Ci obce pojęcie postaci nominalnej typu 2NF czy 3NF. Podobnie jak w poprzednim akapicie – normalizacja danych i unikanie duplikacji zazwyczaj jest podejściem wręcz pożądanym. Natomiast znowu, w przypadku systemów rozproszonych sprawa wygląda trochę inaczej. Wspominałem o zjawisku „temporal coupling” i jak możemy je eliminować np. przez asynchroniczną wymianę wiadomości za pomocą kolejki danych. Zastanówmy się teraz nad następującym scenariuszem – potrzebujemy pobrać dane dotyczące szczegółów zamówienia, przyjmijmy trzy usługi: użytkowników (users), produktów (products) oraz zamówień (products). Mamy następujące możliwości:
1. API Gateway odpytuje wszystkie trzy mikroserwisy o dane i następnie transformuje je w pożądany read-model.
2. API Gateway odpytuje orders service, który wysyła żądania do products oraz users service, agreguje dane i zwraca model.
3. API Gateway odpytuje orders service, który posiada wszystkie dane i zwraca obiekt szczegółów zamówienia.
Wszystkie 3 opcje wymagają przynajmniej jednego zapytania typu HTTP GET (chcemy, aby nasze kwerendy, czyli zapytanie dotyczące pobierania danych były synchroniczne), natomiast ostatnia opcja wydaje się najbardziej kusząca – products oraz users service zostały całkowicie wyeliminowane z tego procesu. Pewnie zapytasz, jak to się stało? Pamiętasz, gdy wcześniej wspominałem o zdarzeniach (events), które nasze aplikacje mogą publikować w systemie? Wyobraź sobie, że mikroserwis zamówień nasłuchuje na zdarzenia ProductCreated, UserCreated i zapisuje dane dotyczące produktów oraz użytkownika (dokładnie w takiej postaci w jakiej potrzebuje) w swojej własnej bazie danych.
Dokonujemy zatem pewnej duplikacji danych, natomiast robimy to w „dobrej wierze”. Pamiętaj, że z punktu widzenia Twojej domeny (czy idąc trochę dalej nomenklaturą DDD: subdomen oraz tzw. bounded contexts) pojęcie produktu może oznaczać całkowicie co innego w zależności od tego czy aktualnie mamy na myśli usługę produktów, zamówień czy dział wsparcia klienta.
Jak zapewne widzisz, tworzenie systemów rozproszonych to ogrom wyzwań związanych zarówno z zagadnieniami organizacyjnymi, infrastrukturalnymi czy też zarządzaniem danymi.
Opisałem tylko kilka wybranych zagadnień, a jest ich znacznie, znacznie więcej – do każdego z tych punktów można by napisać osobny, wielostronicowy artykuł. Celowo nie wspomniałem o niektórych kwestiach jak np. spójność ostateczna (Eventual Consistency), teoria CAP (spójność, dostępność, partycjonowanie sieci), rozproszone transakcje (2 Phase Commit, Event Choreography, Saga, Process Manager, Workflow) oraz o tym jak budować, testować, wdrażać, zarządzać czy monitorować mikroserwisy. Mam po prostu szczerą nadzieję, że zanim radośnie rzucisz się z motyką na słońce (nie mając wcześniejszego doświadczenia z systemami rozproszonymi) odpowiednio rozeznasz się w temacie i samodzielnie bądź wspólnie z zespołem/organizacją podejmiecie decyzję czy faktycznie ma to sens (taka analiza SWOT).
Wszystkich zainteresowanych poszerzeniem swojej wiedzy w tematyce mikroserwisów zapraszam do odwiedzenia witryny DevMentors.io gdzie razem z Darkiem Pawlukiewiczem przygotowaliśmy darmowy kurs “Distributed .NET Core” (15 odcinków, łącznie prawie 20 godzin wideo + kod źródłowy na GitHubie), a jeśli interesują Cię warsztaty stacjonarne, to zajrzyj proszę na mikroserwisy.net.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
