Machine Learning (prawie) bez kodu z Robertem Kostrzewskim

– Gotowe rozwiązania ML-owe polecam w szczególności startupom, a także większym biznesom dopiero odkrywającym rynek sztucznej inteligencji. Dzięki takiemu podejściu możemy zrealizować cel ML-owy bez konieczności proszenia o pomoc osoby z doświadczeniem z tego zakresu – opowiada nam Robert Kostrzewski, Machine Learning Engineer z Netguru. Dlaczego warto zainteresować się Natural Language Processing API od Google? Jak wykorzystać takie narzędzia? A przede wszystkim – jak rozwijać się w Machine Learningu? Tego dowiecie się z naszej rozmowy z Robertem.
 Jak zaczęła się Twoja przygoda z ML?
Jak zaczęła się Twoja przygoda z ML?
Wszystko zaczęło się 4 października 2016 roku. 🙂 Tego dnia odbyło się pierwsze laboratorium z przedmiotu “Inteligencja obliczeniowa” na moich studiach magisterskich. To był doskonały wstęp do algorytmów genetycznych, sieci neuronowych, podstaw sztucznej inteligencji (pozdrawiam Pana Grzegorza Madejskiego – miał Pan solidny wkład w moją dalszą drogę zawodową). W trakcie oraz po ukończeniu studiów pracowałem (i nadal pracuję) w Netguru, aktualnie na stanowisku senior Ruby on Rails developera. Rok po obronie zdecydowałem, że wkroczę na ścieżkę Machine Learningu komercyjnie.
Medycyna, samochody autonomiczne, ocena zdolności kredytowej… zastosowań ML jest mnóstwo. Postępy, w której gałęzi interesują Ciebie najbardziej?
Dziedzina samochodów autonomicznych jest dla mnie najbardziej ekscytująca. Nie mogę się doczekać czasów, gdy koncepcja samo jeżdżących aut będzie dostępna dla każdego i w pełni bezpieczna. Za najbardziej szlachetne uważam jednak zastosowanie sztucznej inteligencji w medycynie. Chciałbym w przyszłości pracować nad projektami pomagającymi ludzkości i wierzę, że Machine Learning może odegrać w tym zadaniu kluczową rolę. A gdzie bardziej potrzebna jest pomoc ludzkości, jeśli nie w ochronie zdrowia, prawda?
Jakie są dostępne, dobre narzędzia do Machine Learningu, które nie wymagają umiejętności programowania?
Podczas mojej prezentacji na konferencji “Liderferencja” omawiałem narzędzia Google DialogFlow, pakiet Machine Learningowy Google Cloud Processing w formie API oraz pakiet Spacy jako dobry start w programowaniu przetwarzania języka naturalnego. Warto jednak zaznaczyć, że każdy duży gracz IT posiada podobny zestaw udogodnień. Mam tu na myśli rozwiązania Microsoft Azure oraz Amazon Web Services. Choć nie znam w praktyce wszystkich z wymienionych, zaryzykuję stwierdzenie, że użycie ich jest analogiczne. W dalszej kolejności możemy poszukać innych, customowych rozwiązań API. Na samym końcu zachęcam do zainteresowania się konceptem AutoML.
Czy dzięki takim narzędziom jak Dialog Flow pracę programistów ML częściowo będzie mógł przejąć ktoś niezwiązany z IT? Jakie są tego dobre strony dla firm i użytkowników?
Już w tym momencie część pracy związanej z projektami ML mogą wykonywać osoby nietechniczne. Najlepszym przykładem takiej pracy jest adnotacja danych. Polega ona na odczytywaniu porcji danych wejściowych i klasyfikacji ich w określony sposób, zgodny z zadaniem algorytmu. Dzięki temu przygotowujemy dane surowe tak, aby można je było wykorzystać do wytrenowania modeli. Osobiście uważam, że w niedalekiej przyszłości adnotacja danych będzie “najbardziej atrakcyjną” pracą dorywczą.
Natomiast narzędzia takie jak DialogFlow znacząco zmniejszają próg wejścia w inwestycję w tak zaawansowane projekty jak budowa chatbota. Do obsługi tego programu zaryzykowałbym stwierdzenie, że wystarczy jedynie przeszkolenie, a nie specjalistyczna wiedza z przetwarzania języka naturalnego. Takich przykładów jest więcej, dzięki temu tworzenie zaawansowanych konceptów jest łatwiejsze.
A co może pójść nie tak?
Wydaje mi się, że obecnym problemem takich narzędzi jest skalowalność. Bardzo łatwym zadaniem jest zbudowanie prostego chatbota, od którego nie będzie wymagało się perfekcyjnej jakości, na przykład na potrzeby demo dla potencjalnych klientów. W przypadku wejścia w dalsze fazy projektu, budowanie skomplikowanego bota obsługującego wiele scenariuszy może być problematyczne. A to może prowadzić do błędów w działaniu lub zwiększeniu kosztów implementacji.
O co powinna zadbać osoba tworząca firmowego chatbota lub voice bota, żeby interakcja z nim nie była po prostu frustrująca?
Gdy czytam to pytanie, od razu przypominają mi się słowa Agnieszki Stanisławskiej, Project Managerki, z którą pracowaliśmy nad stworzeniem Netgurowego Chatbota w Dialogflow. Od samego początku uczulała mnie, że większość osób interaktujących z nowym botem będzie próbowało go zhackować, zepsuć, zawiesić. To naturalna reakcja człowieka na kontakt z nieznaną technologią bądź produktem, a najczęściej objawia się to przy chatbotach. Dlatego też należy dołożyć wszelkich starań, aby pierwsze kilka minut interakcji z produktem nie było decydujące w negatywnym tego słowa znaczeniu. DialogFlow posiada moduł “Small Talk”, który pozwala na automatyczną instalację reakcji na typowe powitalne wiadomości użytkowników. Z pomocą tego możemy zaoszczędzić sobie sporo czasu i nerwów. 🙂
Pokazałeś Natural Language Processing API od Google. Dlaczego warto zainteresować się takim rozwiązaniem?
Przede wszystkim, dlatego że Google NLP API w szybki sposób umożliwia otrzymanie szczegółowej analizy. Te same zadania zaimplementowane samodzielnie zajmują więcej czasu. Może to być szczególnie dobra decyzja w sytuacji gdy nie mamy zasobów obliczeniowych do obsługi własnych rozwiązań NLP. Z drugiej strony to najszybszy sposób na sprawdzenie potencjału danych tekstowych, z którymi mamy do czynienia, według mnie. Korzyści jest naprawdę sporo. A tu przykład:

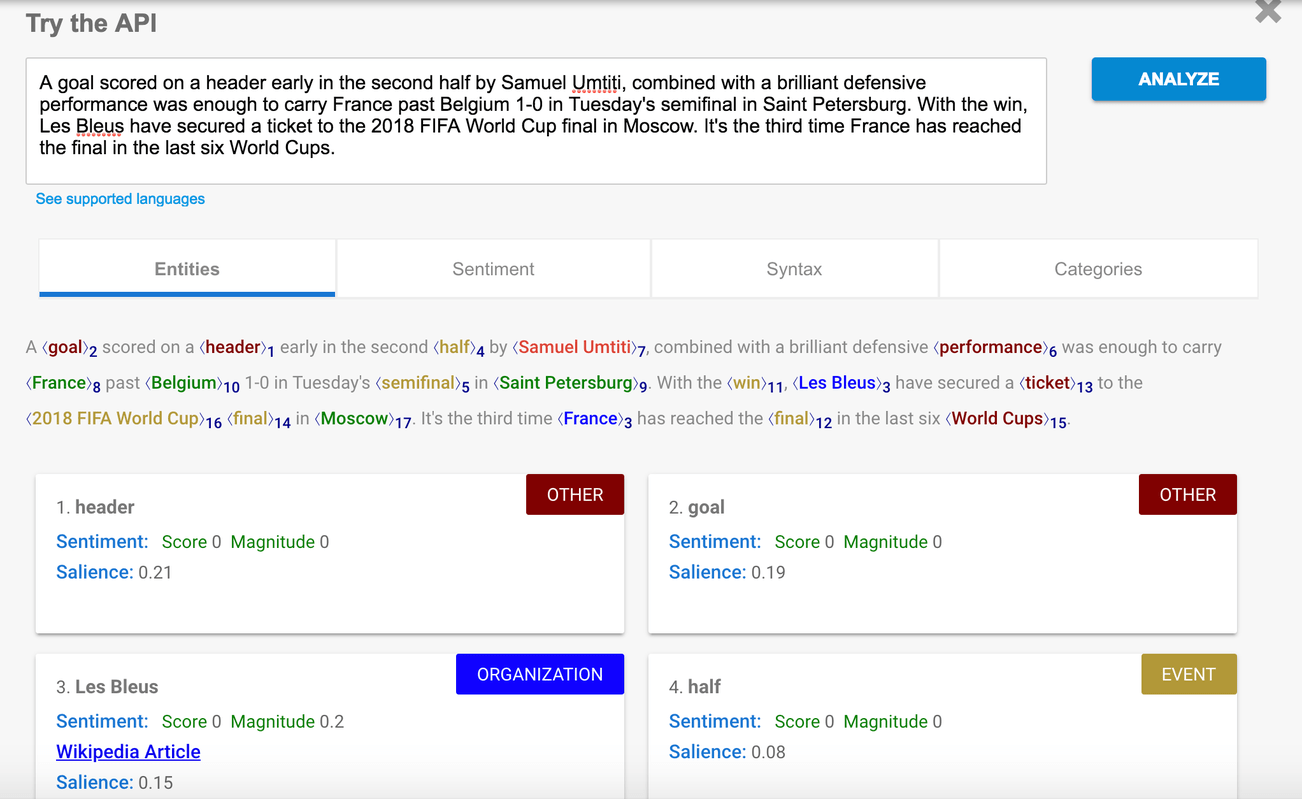

Jak biznesy mogą wykorzystać takie narzędzia?
Gotowe rozwiązania ML-owe polecam w szczególności startupom, a także większym biznesom dopiero odkrywającym rynek sztucznej inteligencji. Dzięki takiemu podejściu możemy zrealizować cel ML-owy bez konieczności proszenia o pomoc osoby z doświadczeniem z tego zakresu. Oczywiście w dalszej perspektywie czasowej polecam zatrudnienie inżyniera Sztucznej Inteligencji, natomiast z doświadczenia wiem, że fazy Proof of Concept nie zawsze pozwalają na taki krok.
Jakie ryzyko niesie za sobą używanie takich narzędzi w kontekście biznesowym?
Przede wszystkim ryzyko wycieku danych poufnych. Wszelkie kwestie związane z anonimizacją danych, RODO, bezpieczeństwem. A jak duże jest to ryzyko? Tutaj już każdy zespół musi to określić indywidualnie. To wszystko kwestia tego na, ile ufamy serwisom trzecim, np. narzędziom Google. Z drugiej strony wysyłając wrażliwe dane ze swoich serwerów na serwery firm trzecich, zawsze musimy zadbać o szczelność takiej integracji.
Możesz polecić źródła, kursy, tutoriale z zakresu ML dla osób nietechnicznych?
Na samym wstępie zaznaczę, że Machine Learningu znacznie łatwiej jest się nauczyć, posiadając podstawowe umiejętności programowania, znajomość na przykład języka programowania Python. Znajomość matematyki na poziomie pierwszego roku studiów polskich uczelni technicznych będzie również ogromnym ułatwieniem.
Na szczęście nic straconego. Perełki dla osób nietechnicznych można znaleźć na konferencjach, w kursach internetowych oraz na portalach typu Medium lub Towards Data Science.
Portal Coursera pozwolił już czterem milionom początkujących wziąć udział w kursie Machine Learningu od podstaw, realizowanego we współpracy ze Stanford University.
Artykuły na Medium to pojedyncze porcje nowinek technologicznych. Niektóre z nich tłumaczą wszystko od A do Z, na przykład.
Na koniec moja prezentacja z Liderferencji, która wprowadzi Was w ML bez potrzeby programowania.
A dla osób, które mają trochę pojęcia o ML i chcą się dalej rozwijać?
W tym momencie wierzę w cztery rzetelne źródła wiedzy o Machine Learningu.
Pierwszy źródłem są publikacje naukowe na portalu Arxiv. Jest to porcja wiedzy o najnowszych trendach w ML. W moim zespole ML w Netguru omawiamy te materiały raz w tygodniu.
Druga część rozwoju to konferencje Machine Learningowe. W Polsce szczególnie polecam konferencje PyData, Data Science Summit i ML in PL. Prelekcje wymagają wiedzy wejściowej, ale są świetnym sposobem na przyswojenie świeżych nowinek z branży.
Poza artykułami Arxiv oraz konferencjami chciałbym polecić książki, oraz kursy online. Materiały czytane, które mogę zarekomendować to:
- Deep Learning by Ian Goodfellow,
- Deep Learning with PyTorch,
- Hands-on Machine Learning with Scikit-Learn, Keras & Tensorflow.
Na koniec kursy internetowe, które darzę szczególną sympatią. To dlatego, że łatwo zaplanować czas nauki, systemy e-learningowe skutecznie motywują do systematycznej pracy, zawartość jest interaktywna. Najbardziej podobała mi się oferta specjalizacji kursów o nazwie Deeplearning.ai. Kursy dostępne są na platformie Coursera. Sam jestem absolwentem ścieżki Natural Language Processing i nie żałuję ani złotówki. 🙂
Robert Kostrzewski. Absolwent informatyki na Politechnice Wrocławskiej i Uniwersytecie Gdańskim. Wcześniej backend developer w Ruby on Rails, od 2019 komercyjnie związany z Pythonem i Machine Learningiem, zwłaszcza w obszarze Natural Language Processing. Po pracy: norweski kryminał, stare polskie kino, wycieńczający crossfit oraz niebanalny city break w weekend. 🙂

Zdjęcie główne artykułu pochodzi z unsplash.com. Z Robertem Kostrzewskim rozmawiała Kinga Marszałkowska.
Podobne artykuły

Jak się nie pozabijać? O współpracy analityka z programistami i klientem

Talent Pool pozwala oszczędzić czas i daje możliwość zbudowania bezpiecznej alternatywy. Wywiad z Magdą Bagińską

Przed falą zwolnień łatwiej było o awans. Wywiad z Grzegorzem Witkiem

W Polsce musimy bezwzględnie wykorzystać globalny trend związany z Big Data oraz AI. Wywiad z Rafałem Tadasiewiczem

Nie zaczynaj od pracy zdalnej. Historia Andrzeja Rośka

Jak wygląda praca Software System Engineera w intralogistyce?

Co z tym eldorado w IT — skończyło się czy trwa nadal? Wywiad z Jeroenem Fossaert
