Machine learning dla frontend developerów. Na przykładzie Flappy Bird

Czy frontend developerzy mogą wykorzystywać machine learning w projektach? Przy pomocy TensorFlow.js, JS-owej biblioteki do tworzenia i uczenia modeli, jest to możliwe. Postanowiłem przetestować to rozwiązanie korzystając z projektu stworzonego w HTML5 na podstawie gry Flappy Bird. Moim celem było zastąpienie biblioteki Synaptic przez TensorFlow.js.
Zanim przedstawię krok po kroku mój eksperyment, uporządkujmy najważniejsze zagadnienia związane z tematem.

Daniel Capeletti. Senior Frontend Developer w Apptension. Jego zainteresowania zawodowe obejmują zarówno frontendowe innowacje, jak i zagadnienia związane z bezpieczeństwem. Poza pracą realizuje swoje artystyczne pasje — od pisania, przez fotografię, po granie na gitarze. Daniel jest także autorem kilku wpisów na firmowym blogu Apptension.
Spis treści
Uczenie maszynowe, uczenie głębokie i sztuczne sieci neuronowe
Uczenie maszynowe (machine learning) pozwala systemom doskonalić swoje działanie na podstawie przykładów i danych. Maszyny uczą się metodą “prób i błędów” — jeśli zadaniem jest przeskoczenie przez przeszkodę, wystarczy przeprowadzić serię testów, żeby być w stanie ustalić zależność między wielkością przeszkody, prędkością i mocą potrzebną do jej pokonania.
Uczenie maszynowe
Istnieją różne kryteria podziału metod uczenia maszynowego. Jeśli weźmiemy pod uwagę informacje, jakie dostarczamy systemowi, zasadny będzie podział na:
- uczenie nadzorowane (supervised learning) — uczymy maszynę dostarczając jej zbiór punktów wejścia wraz z oczekiwanymi punktami wyjścia. System spróbuje odnaleźć funkcję, która najlepiej łączy oba zbiory danych.
- uczenie nienadzorowane (unsupervised learning) — w tym przypadku dane wejściowe i wyjściowe nie są ze sobą bezpośrednio powiązane. Taka metoda przydaje się zwłaszcza wtedy, kiedy próbujemy odnaleźć w danych nieznane nam jeszcze powiązania.
Możemy wymienić różne rodzaje zadań uczenia maszynowego (machine learning tasks), czyli problemów, które przy pomocy ML można rozwiązać:
- klasyfikacja (classification) — pozwoli przyporządkować dane do różnych klas na podstawie przykładów dostarczonych do systemu. Możemy więc stworzyć maszynę, która będzie w stanie rozróżnić zdjęcia psów od zdjęć kotów na podstawie przykładowych wizerunków, które zostały poprawnie oznaczone.
- regresja (regression) — będzie dążyć do stworzenia zoptymalizowanej funkcji pozwalającej obliczyć przewidywane dane wyjściowe. Wracając do przykładu dotyczącego przeskakiwania przez przeszkodę, regresja pozwoli nam przewidzieć czy skok będzie udany na podstawie odległości i wymiarów przeszkody oraz naszej prędkości.
Inne rodzaje zadań uczenia maszynowego to np. klasteryzacja (clustering), estymacja gęstości (density estimation) i redukcja wielowymiarowości (dimensionality reduction).

Uczenie głębokie i sztuczne sieci neuronowe
Wykorzystując algorytm zadaniowy otrzymamy wyjście, które dostarczy nam jakąś informację. W uczeniu głębokim, ten feedback będzie służył jako wejście dla kolejnej warstwy funkcji. Często odbywa się to przy wykorzystaniu sztucznych sieci neuronowych, w których każda ukryta warstwa otrzymuje dane od poprzedniej. Ich koncepcja (i nazwa) pochodzi od sieci neuronowych znajdujących się w mózgu.
Neurony
Neuron przetwarza otrzymane dane poprzez pomnożenie ich przez inną wartość. Ta wartość to waga (weight), która na początku może być randomizowana. Aby neuron dostarczył nam dane wyjściowe, należy go aktywować poprzez zastosowanie funkcji aktywacji.
Wracając do problemu przeskakiwania przeszkody załóżmy, że nie wiemy, kiedy jest najlepszy moment na wykonanie skoku. Nasza sieć neuronowa na początku zastosuje zrandomizowaną wagę do danych wejściowych i poda informację czy należy skakać czy nie, mimo że system nie nauczył się jeszcze tego określać.
Kolejnym elementem funkcji aktywacji jest przesunięcie (bias), czyli wartość, która wpływa na przekształcenie wykresu naszej funkcji. W przypadku funkcji, która zwraca wartości pomiędzy 0 a 1, możemy spodziewać się, że dane wyjściowe będą zawierać się w tym zbiorze. Co jeśli wzór będzie miał rację bytu dla wartości pomiędzy 2 i 3? Z tego powodu możemy uwzględnić przesunięcie.
Warstwy
Warstwy znajdujące się pomiędzy warstwami wejściową i wyjściową to tzw. warstwy ukryte (hidden layers), gdzie liczba neuronów i sposób, w jaki są połączone, zależy od nas.
Warstwy mogą być połączone na różne sposoby, ale często spotyka się sieci, w których wszystkie neurony jednej warstwy są połączone ze wszystkimi neuronami warstwy następnej.
Tym, którzy chcą zagłębić się w temat sztucznych sieci neuronowych, polecam film autorstwa 3Blue1Brown na YouTube.
Czym jest TensorFlow.js i skąd zainteresowanie nim?
TensorFlow to open source’owy framework przydatny do implementowania uczenia maszynowego, początkowo stosowany w Pythonie. Rodowód Google (stworzyli go tamtejsi specjaliści od AI) i zaangażowana społeczność skupiona wokół tego frameworku zaowocowały jego popularnością. Obecnie z TensorFlow pracuje chociażby NASA.
TensorFlow.js to biblioteka przystosowana do pracy w JavaScript, która zainspirowała mnie do wypróbowania uczenia maszynowego na frontendzie. Warto jednak zauważyć, że istnieją jeszcze inne narzędzia do pisania rozwiązań ML w JavaScript, np Synpatic i Brain.js.
Tensor API pozwala nam na tworzenie i edytowanie tensorów (tensor jest obiektem matematycznym przypominającym macierz i wektor, mogącym posiadać dowolną liczbę wymiarów), na przykład:
tf.tensor2d([[1, 2], [3, 4]]).print();
//output
Tensor
[[1, 2],
[3, 4]]
Jak stworzyłem moją pierwszą sieć neuronową?
Po przeanalizowaniu kilku tutoriali dotyczących TensorFlow.js, poczułem, że mogę spróbować swoich sił w budowaniu prostej sieci neuronowej.
Zacznijmy od stworzenia warstwy ukrytej przy pomocy layers API (tworzymy warstwę dense czyli całkowicie połączoną).
const NEURONS = 8;
const hiddenLayer = tf.layers.dense({
units: NEURONS,
inputShape: [3],
activation: 'sigmoid',
});
Warto zwrócić uwagę, że nie stworzyliśmy warstwy wejściowej, ale ustaliliśmy, że warstwa ukryta otrzyma 3 wartości wejściowe. Funkcją aktywacji jest sigmoid, o następującym wykresie:
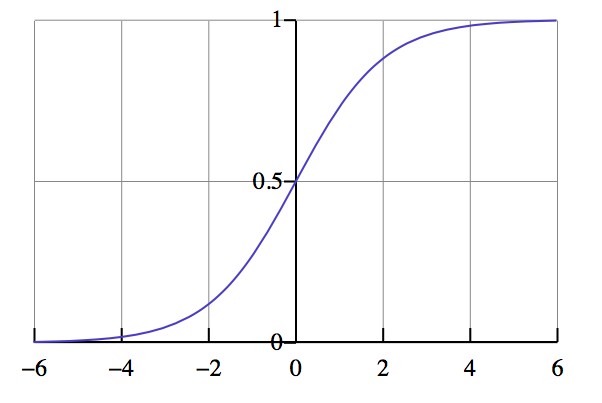
Dzięki temu wiadomo, że wartości wyjściowe będą zawierać się między 0 a 1.
W sieci brakuje jeszcze warstwy wyjściowej, dodajmy ją:
const outputLayer = tf.layers.dense({
units: 1,
});
W ten sposób stworzyliśmy sieć neuronową! Chociaż nie do końca — brakuje modelu, który sprecyzuje, jak połączone są zdefiniowane zmienne.
const model = tf.sequential(); model.add(hiddenLayer); model.add(outputLayer);
Przed skompilowaniem należy uzupełnić model o funkcję straty (loss function) i optymalizacji (optimizer function). Funkcja straty poinformuje nas o tym, jak bardzo dane wyjściowe różnią się od zadanych, a funkcja optymalizacji używana jest do minimalizacji funkcji straty poprzez zmianę wartości wag i przesunięć.
model.compile({ loss: 'meanSquaredError', optimizer: 'sgd' });
O czym jeszcze należy pamiętać?
Frontend developerzy muszą zawsze być świadomi ograniczeń w wydajności przeglądarek, praca z TensorFlow.js nie stanowi wyjątku. Ta biblioteka przetwarza dane używając GPU, co oznacza, że każdy błąd może obniżyć płynność naszej gry. Na szczęście można sobie z tym poradzić korzystając z narzędzi, jakie oferuje TensorFlow API. Jedną z nich jest funkcja tidy, której warto używać przy operacjach manualnych (np. dodawaniu wartości do tensora):
return tf.tidy(() => {
return tensor.add(tf.randomUniform(tensor.shape, min, max));
});
Tidy usunie tensory użyte w funkcji oprócz tych, które zostały zwrócone. Uwaga — tidy działa na operacjach synchronicznych, nie należy jej używać z Promise.
Flappy Bird przy pomocy TensorFlow.js
Szukając pomysłu na pierwszy projekt z TensorFlow.js, przypomniałem sobie o wersji gry Flappy Bird wykorzystującej uczenie maszynowe i algorytm genetyczny. Postanowiłem zaadaptować jej kod, wykorzystując TensorFlow.js zamiast biblioteki Synaptic.
Repozytorium projektu Srdjana Susnica bardzo dobrze opisuje poczynione przez niego kroki. Autor użył sieci neuronowej z dwoma wejściami, warstwą ukrytą składającą się z 6 neuronów i 1 wyjściem:
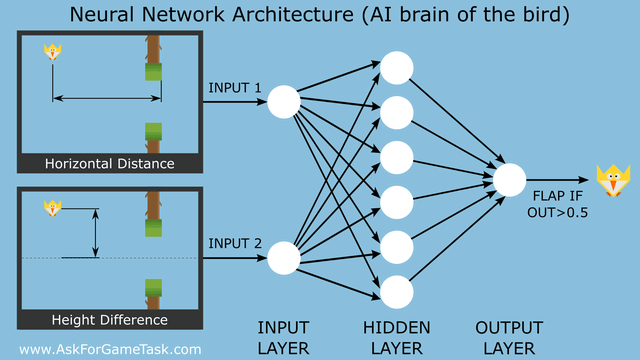
Postanowiłem więc odtworzyć tę strukturę przy pomocy TensorFlow.js:
const NEURONS = 6;
const hiddenLayer = tf.layers.dense({
units: NEURONS,
inputShape: [2],
activation: 'sigmoid',
kernelInitializer: 'leCunNormal',
useBias: true,
biasInitializer: 'randomNormal',
});
const outputLayer = tf.layers.dense({
units: 1,
});
Logika decydująca czy ptak zamacha skrzydłami:
if (output > 0.5) {
bird.flap();
}
Wybrałem takie wartości początkowe (kernel initialiser i bias initialiser), które zwrócą wartość wyjściową zbliżoną do 0.5. Z gotowym modelem możemy zacząć tworzyć populację ptaków, korzystając z genetycznego algorytmu.
Algorytm Genetyczny
Tego typu algorytmy wykorzystują selekcję naturalną na danej populacji do wygenerowania kolejnej, opartej na najlepiej przystosowanych jednostkach. Należy więc w jakiś sposób ustalać, które jednostki są tymi najlepszymi — w kontekście Flappy Bird za najsilniejsze możemy uznać te, które “doleciały” najdalej.
Pierwotna wersja projektu definiuje to jako fitness i oblicza w następujący sposób:
fitness = całkowity przemierzony dystans – odległość do pierwszej przeszkody
Przy pomocy TensorFlow.js wybierzemy 4 najlepsze jednostki na bazie ich wyniku, a następnie stworzymy krzyżówki. W tym momencie nasza implementacja nieco zaczyna odbiegać od tej stworzonej przez Susnica.
evolvePopulation: function() {
const Winners = this.selection();
const crossover1 = this.crossOver(Winners[0], Winners[1]);
const crossover2 = this.crossOver(Winners[2], Winners[3]);
const mutatedWinners = this.mutateBias(Winners);
this.Population = [crossover1, ...Winners, crossover2, ...mutatedWinners];
}
Nowa populacja składa się z 4 poprzednich zwycięzców, 2 krzyżówek i 4 zmutowanych zwycięzców. Do stworzenia krzyżówki korzystamy z następującej funkcji:
crossOver: function(a, b) {
const biasA = a.layers[0].bias.read();
const biasB = b.layers[0].bias.read();
return this.setBias(a, this.exchangeBias(biasA, biasB));
},
Zwróci ona tensor z wagami dla warstwy.
const biasA = a.layers[0].bias.read();
Korzystając ze wspomnianej wcześniej funkcji tidy operujemy na tensorach z funkcji crossOver.
exchangeBias: function(tensorA, tensorB) {
const size = Math.ceil(tensorA.size / 2);
return tf.tidy(() => {
const a = tensorA.slice([0], [size]);
const b = tensorB.slice([size], [size]);
return a.concat(b);
});
},
Nie chcę zmieniać pierwotnej wagi więc kopiuję ją. Warto zwrócić uwagę, że obiekty w TensorFlow.js są niezmienne, funkcja write zwróci nowy tensor.
setBias: function(model, bias) {
const newModel = Object.assign({}, model);
newModel.layers[0].bias = newModel.layers[0].bias.write(bias);
return newModel;
},
Chcemy stworzyć zmutowane jednostki, a zatem funkcja mutate zwróci nowy model z losową wagą.
mutateBias: function(population) {
return population.map(bird => {
const hiddenLayer = tf.layers.dense({
units: NEURONS,
inputShape: [2],
activation: 'sigmoid',
kernelInitializer: 'leCunNormal',
useBias: true,
biasInitializer: tf.initializers.constant({
value: this.random(-2, 2),
}),
});
return this.createModel(bird.index, hiddenLayer);
});
},
W tym przypadku randomizujemy wagę w zakresie od -2 do 2. Być może istnieje na to lepsze (i bardziej logiczne) rozwiązanie — można na przykład ustalić, że im dalej dotrze ptak, tym mniejsza jest losowa wartość.
W ten sposób udało się stworzyć podstawę naszego algorytmu genetycznego.
Jak trenować model?
Zainspirowany przykładami, jakie znalazłem w różnych tutorialach, postanowiłem trenować model bez poważniejszej analizy tego procesu.
Aby przetestować model wykorzystamy fit API:
trainPopulation: function(population) {
return population.map(async model => {
await model.fit(tf.tensor2d(model.history), tf.tensor1d(model.outputHistory), {
shuffle: true,
});
});
},
Zwróć uwagę, że trenowanie modelu to proces asynchroniczny, stąd async/wait w przykładzie. Przewidywanie rezultatu nie jest operacją asynchroniczną, ale uzyskanie outputu jest.
tf.tidy(() => {
const outputs = this.Population[bird.index].predict(tf.tensor2d([ inputs ]));
outputs.data().then(output => {
if (output > 0.5) {
bird.flap();
}
});
});
Jakie elementy danych powinniśmy trenować? Jak widać użyliśmy model.history jako pierwszego parametru, model.outputHistory jest drugim parametrem. Zdecydowałem się na to, aby zebrać wartości wejściowe i wyjściowe z modelu i zobaczyć, czy można w jakiś sposób przyspieszyć ewolucję populacji — sam nie byłem pewien, czy to pomoże.
Efekt? Zauważyłem, że trenowanie modelu jest bardzo powolne. I cóż — nie jest to proste zadanie. Co z przyspieszoną ewolucją? Trenowanie modelu w tym przypadku nie okazało się pomocne.
Trenowanie modelu będzie zazwyczaj wymagało posiadania poprawnych danych wejściowych i oczekiwanych danych wyjściowych — w ten sposób można nauczyć model, jak ma się zachować, kiedy takie dane napotka. Nasz problem dotyczył znalezienia najlepszego rezultatu gry i dalszego ewoluowania populacji.
Trenowanie modelu nie pomogło, bo nie posiadaliśmy na starcie odpowiednich danych wejściowych i oczekiwanych wyjść.

Rezultaty
Udało nam się osiągnąć wyniki opisane w pierwotnym projekcie. Czy zrobiliśmy to lepiej? Można powiedzieć, że tak, bo zwycięska jednostka pojawiła się już w 19 pokoleniu. Dałoby się to również osiągnąć modyfikując tempo uczenia się w pierwotnym algorytmie.
Analizowanie algorytmu i eksperymenty z modyfikowaniem warstw, neuronów itd. okazały się bardzo interesujące. Moim celem nie było ulepszenie istniejącego rozwiązania, a raczej sprawdzenie, czy zastosowanie nowszej technologii pozwoli na uzyskanie podobnych rezultatów.
Materiały i pomysły
Poniżej wklejam linki do materiałów, które zainspirowały mnie do zabawy z TensorFlow.js:
- Bogata lista przykładów użycia TF.js w oficjalnym repozytorium na GitHubie.
- Playlista filmów od The Coding Train na YouTube.
- MPJ z Fun Fun Function niedawno rozpoczął serię filmów o sieciach neuronowych.
- Świetne materiały video na temat sieci neuronowych z kanału 3Blue1Brown.
- Dobre źródło artykułów i najnowszych informacji.
Podsumowanie
Rozpocząłem ten eksperyment, aby pobawić się trochę z TensorFlow.js i wypróbować uczenie maszynowe na frontendzie. Oba te cele udało się spełnić. Muszę przyznać, że uczenie maszynowe zmusiło mnie do przejścia przez wiele artykułów, filmików, książek — o wiele więcej, niż się spodziewałem. Nie jest to jednak zarzut — cieszę się, że jesteśmy w posiadaniu narzędzi frontendowych, które pozwalają nam rozwiązywać coraz trudniejsze zagadnienia.
Jeśli chodzi o samą technologię, o której mowa w tym artykule, TensorFlow.js daje frontend developerom możliwość pracy nad jeszcze inteligentniejszymi rozwiązaniami w prowadzonych projektach. Jestem przekonany, że społeczność skupiona wokół TF będzie w dalszym stopniu maksymalizować potencjał tego narzędzia.

Artykuł został pierwotnie opublikowany na blog.apptension.com.
Podobne artykuły

O krok przed innymi. Ericsson współpracuje z Instytutem Telekomunikacji AGH

Rola cyfryzacji we wdrażaniu gospodarki o obiegu zamkniętym. Wywiad z Dariuszem Doberem

Optymalizacja pamięci. Jak zredukować rozmiar wektorów

Samodiagnozowanie stanu zdrowia przy użyciu AI będzie możliwe już niedługo? Wywiad z Przemkiem Jaworskim z MX Labs

W poszukiwaniu podobnych. Od wyzwania do produktu – machine learning w praktyce

Data Analytics, Data Science, Machine Learning – co wybrać?

Stworzył terminal Linux wspierany przez AI. Jak działa?
