Logowanie i monitorowanie kosztu zapytań w CosmosDB w Application Insights

Projektując aplikacje, które używają dokumentowej bazy danych CosmosDB bardzo często stajemy przed wyzwaniem oszacowania ich kosztu oraz ich późniejszej optymalizacji. Zadanie to nie jest trywialne. Jeśli chodzi o koszt to zawsze możemy użyć kalkulatora. Wystarczy, że podamy tam parametry rozwiązania (liczbę nowych dokumentów, odczytów …) oraz wgramy przykładowe dokumenty. Po uzupełnieniu tych informacji otrzymamy estymację kosztu rozwiązania.

Michał Jankowski. Low Code Technical Practice Leader Technical Architect at Objectivity. Microsoft MVP Azure, an architect, designer, team leader and trainer. He began programming in the early ’90s from Basic and Assembler for 8-bit computers. During most of his career, he was delivering .NET platform targeted application for the world’s largest companies. Currently, he is specialising in the development of web applications and Azure environment. In his free time he likes writing a technical blog.
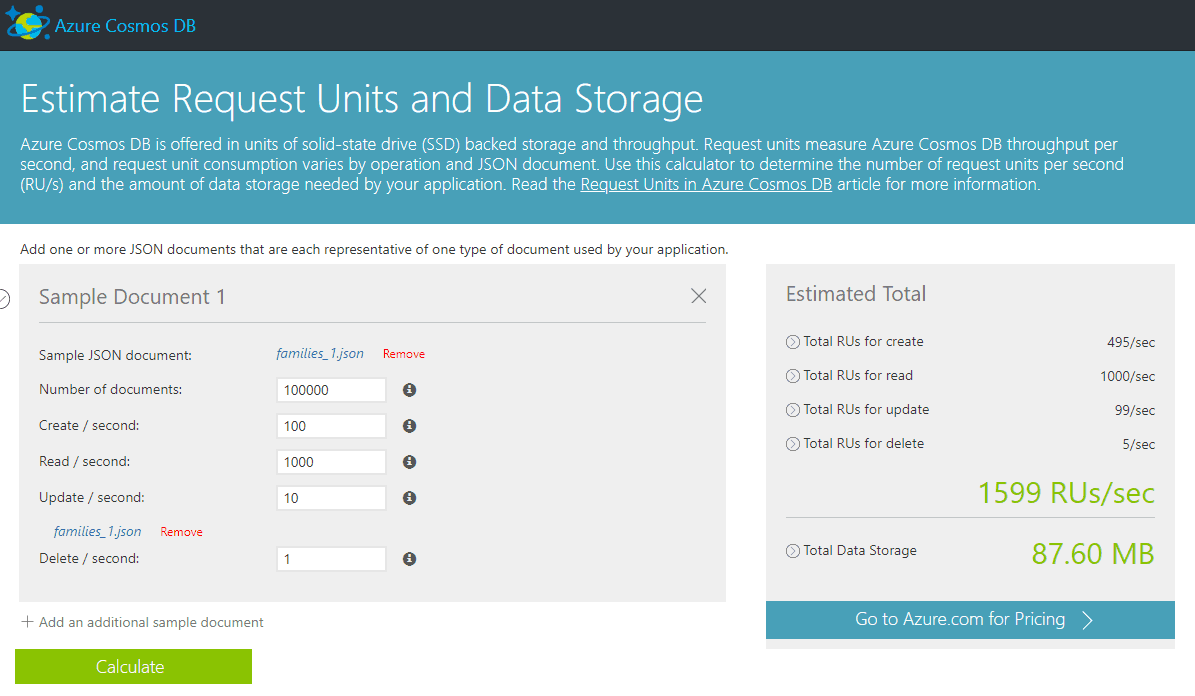
Na podstawie tych informacji możemy zastanowić się, czy chcemy skorzystać z bazy CosmosDB? Czy nas na nią stać, czy może chcemy pomyśleć nad innym rozwiązaniem? Jeśli zdecydujemy się na CosmosDB to z moich obserwacji wynika, że programiści nie mają najmniejszych problemów z wystartowaniem prac z perspektywy użycia bibliotek do komunikacji z bazą danych. Czasami trochę więcej czasu potrzeba na przejście na inne tory myślenia i zaprzestania traktowania bazy CosmosDB jako relacyjnej.
Prędzej, czy później pojawia się potrzeba optymalizacji kosztów zapytań. Powody mogą być różne, a to przekraczamy budżet, a to któreś zapytania zaczynają działać zbyt wolno. Generalnie musimy coś zrobić z naszą bazą danych lub zapytaniami. W takich sytuacjach nigdy nie powinniśmy działać na oślep. Za każdym razem powinniśmy odnieść się do statystyk wykorzystania naszego systemu i z dużym prawdopodobieństwem zacząć optymalizację od najczęściej występujących zapytań.
I w tym przypadku pojawia się drobna przeszkoda. Większość z nas jest przyzwyczajona do bardzo dokładnych statystyk, które są udostępniane przez Azure SQL:
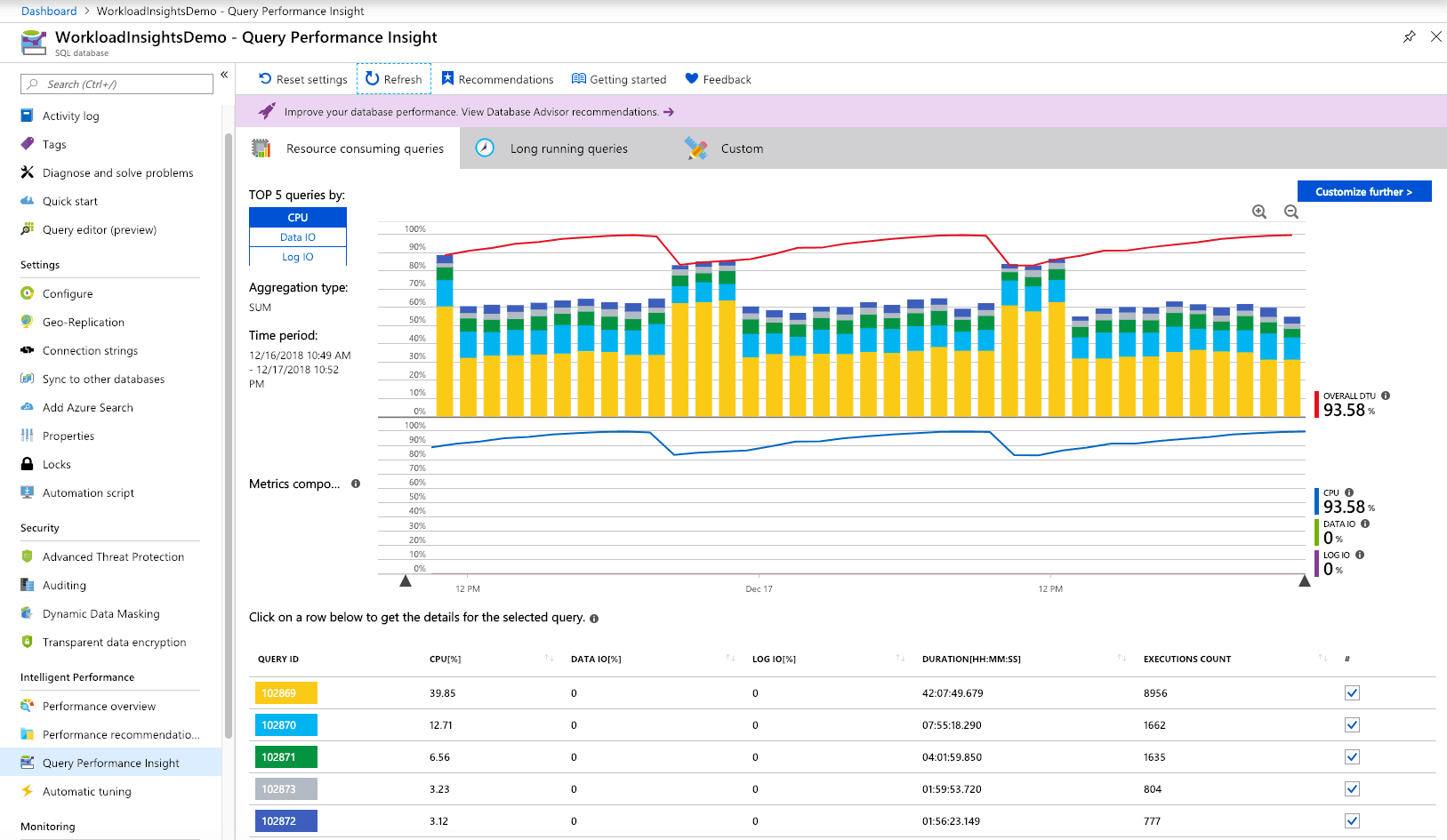
Analiza danych z Query Performance Insight pozwala na rozpoczęcie prac optymalizacyjnych w przypadku Azure SQL
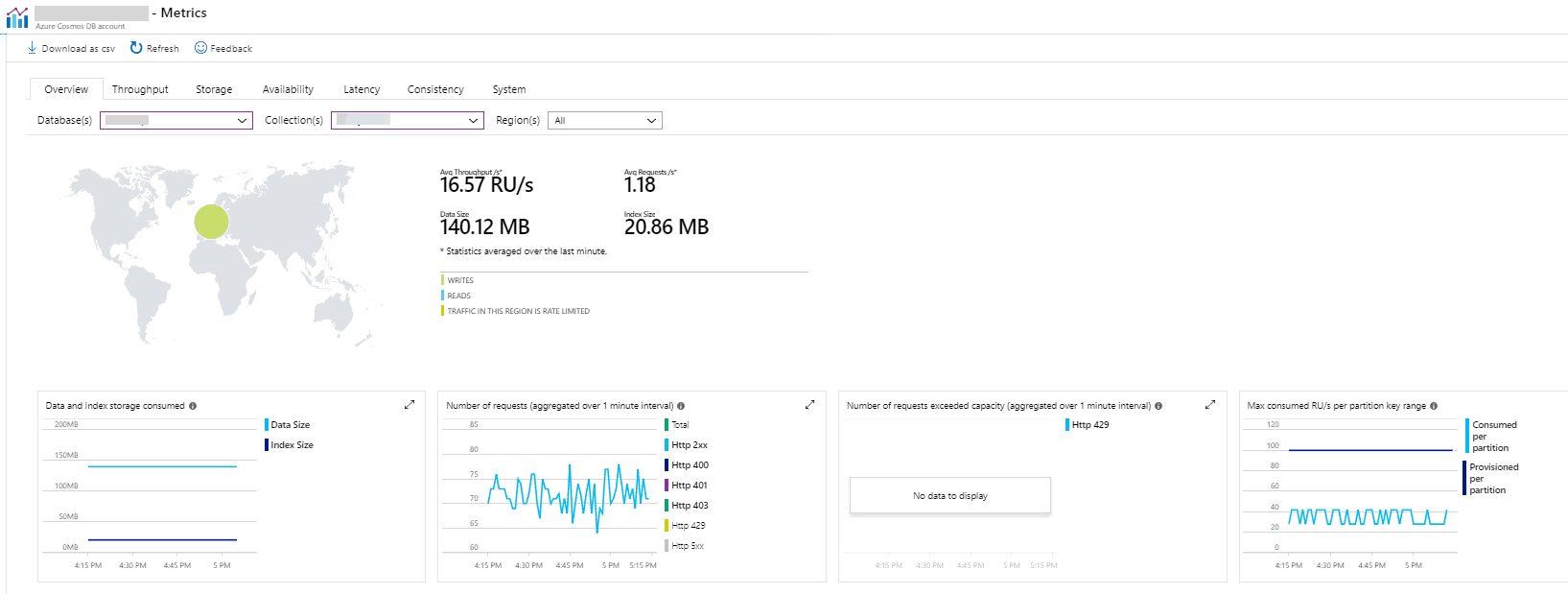
W przypadku CosmosDB nie jest już tak różowo… Dostępnych jest tylko kilka podstawowych charakterystyk. To co możemy sprawdzić pod kątem RU, to tylko ile jednostek RU zużywa nasza baza danych i czy nie przekracza limitu przydzielonego na partycję. Z tych danych ciężko jest wywnioskować, gdzie powinniśmy rozpocząć optymalizację. Możemy natomiast zobaczyć, czy dobrze dobraliśmy poziom RU do naszego rozwiązania.
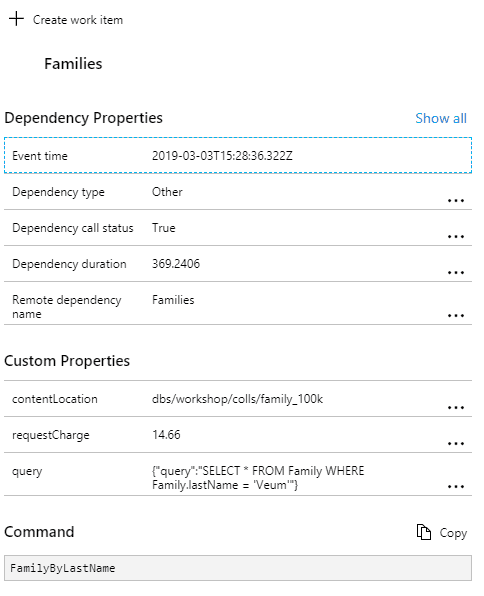
Chciałbym mieć możliwość monitorowania na poziomie każdego zapytania. Z możliwością podejrzenia dokładnie zapytania, które zostało wysłane do bazy danych, jak również na poziomie ogólnym, gdzie możemy zagregować dane na podstawie podanego typu. Tak abym mógł albo uzyskać informację o konkretnym zapytaniu:
lub też w postaci tabelarycznej:
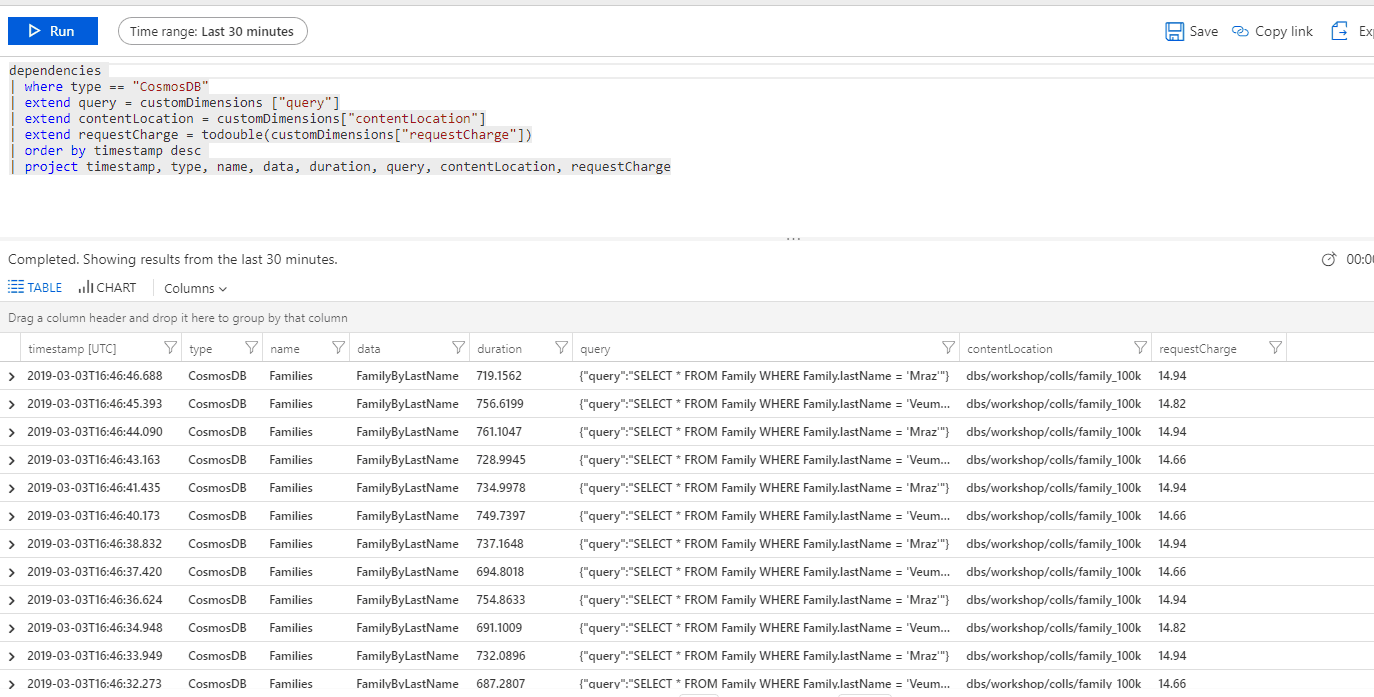
Na podstawie tych danych możemy już spróbować zaplanować optymalizację naszych zapytań. Jak widzicie przechowujemy następujące dane:
- nazwę typu zapytania,
- czas zapytania,
- treść zapytania,
- nazwę kolekcji, której zapytanie dotyczy,
- koszt zapytania.
Najważniejsze, że możemy te dane wyeksportować i przeanalizować je zgodnie z naszymi potrzebami.
Aby to osiągnąć wystarczy napisać rozszerzenie do CosmosDB, które loguje dodatkowe parametry do Application Insights. Kod rozszerzenia wygląda następująco:
public static class ApplicationInsightsQueryTracker
{
private static readonly TelemetryClient TelemetryClient = new TelemetryClient();
public static string DependencyName { get; set; } = "";
public static async Task<FeedResponse<T>> ExecuteWithStatsLogging<T>(this IQueryable<T> queryable, string commandName = null, string operationId = null)
{
var documentQuery = queryable.AsDocumentQuery();
var now = DateTimeOffset.UtcNow;
var stopwatch = Stopwatch.StartNew();
var response = await documentQuery.ExecuteNextAsync<T>();
stopwatch.Stop();
LogStats(now, stopwatch.Elapsed, response.RequestCharge, commandName ?? string.Empty, operationId, response.ContentLocation ?? String.Empty, queryable.ToString());
return response;
}
public static void LogStats(DateTimeOffset start, TimeSpan duration, double requestCharge, string commandName, string operationId, string contentLocation, string query)
{
var dependency = new DependencyTelemetry(DependencyName, commandName, start, duration, true);
if (operationId != null)
{
dependency.Context.Operation.Id = operationId;
}
dependency.DependencyTypeName = "CosmosDB";
dependency.Properties["contentLocation"] = contentLocation;
dependency.Properties["query"] = query;
dependency.Properties["requestCharge"] = requestCharge.ToString(CultureInfo.InvariantCulture);
TelemetryClient.TrackDependency(dependency);
}
}
Następnie wystarczy w momencie wywołania zapytania do CosmosDB wywołać logowanie.
IQueryable<Family> query = client.CreateDocumentQuery<Family>(
UriFactory.CreateDocumentCollectionUri(DatabaseName, CollectionName), "SELECT * FROM ....", queryOptions);
query.ExecuteWithStatsLogging("FamilyByLastName");
Dodatkowo wywołując zapytanie możemy ustawić jego nazwę, aby w przyszłości łatwo można było grupować informacje o zapytaniach tego samego typu.
Artykuł został pierwotnie opublikowany na jankowskimichal.pl. Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
