Kiedy warto wdrożyć grafową bazę danych?

Pracując przy jakimkolwiek większym projekcie trudno uniknąć kontaktu z bazami danych. Ta wiedza przyda się każdemu specjaliście z branży IT, dlatego przygotowałem pewnego rodzaju wprowadzenie do baz grafowych. Z artykułu dowiecie się, z jakimi typami baz możemy się spotkać najczęściej. Omówię je według rosnącej złożoności struktury przechowywanych danych.

Dominik Kozaczko. Senior Backend Developer w Clearcode. Od 2005 roku równolegle pracował jako nauczyciel informatyki oraz programista; uczył Pythona w liceum zanim to stało się modne, zapoczątkował akcję „Python na maturze”, przez 8 lat organizował konferencję „Dni Wolnego Oprogramowania”; od 2016 niemal całkowicie poświęcił się programowaniu.
Spis treści
Bazy klucz-wartość
Bazy tego rodzaju działają jak ogromna tablica asocjacyjna (w Pythonie mówimy “słownik”): wprowadzamy wartość i opatrujemy ją kluczem – etykietą pozwalającą na późniejsze szybkie odszukanie. Ze względu na prostą strukturę i sposób użycia, bazy te pozwalają na bardzo szybki dostęp do danych, więc najczęściej stosuje się je jako cache. Przechowanie złożonej struktury danych jest możliwe dopiero po jej serializacji. W związku z tym w zasadzie nie ma możliwości, by zlecić bazie wykonanie jakichkolwiek operacji odwołujących się do przechowywanej treści. Jednym z najpopularniejszych reprezentantów tej grupy jest Redis.
Bazy obiektowe/dokumentowe
W bazach dokumentowych można przechowywać różnorakie struktury danych zachowując ich układ w obrębie danego obiektu. Jednocześnie baza nie narzuca dokumentom określonego schematu, ale umożliwia przeszukiwanie i edycję wartości w polach. Problematyczne natomiast może okazać się definiowanie i pilnowanie wzajemnych relacji pomiędzy przechowywanymi danymi. Bazy dokumentowe nawet jeśli pozwalają na definiowanie relacji pomiędzy obiektami, to najczęściej nie wymuszają żadnej integralności danych – trzeba o nią dbać samodzielnie. Przykładem tego rodzaju baz jest MongoDB.
Bazy tabelaryczne (tzw. “relacyjne”)
To obecnie najczęściej wykorzystywany rodzaj baz. Dane rozmieszczone są w tabelach ze ściśle określoną strukturą i typami danych. Kolumny odpowiadają polom, a wiersze poszczególnym obiektom. Ogromnym plusem są ścisłe mechanizmy integralności danych: Jeśli chcemy skasować jakiś obiekt, baza sprawdza, czy odwołują się do niego inne obiekty i – w zależności od “twardości” połączenia oraz domyślnego sposobu ich traktowania – może albo skasować powiązane obiekty, albo zlikwidować powiązania, albo w ogóle zabronić jakiegokolwiek kasowania. Ze względu na istotną rolę relacji pomiędzy obiektami, bazy te najczęściej nazywa się właśnie relacyjnymi. Najpopularniejszymi przedstawicielami tej gałęzi są: MySQL/MariaDB i PostgreSQL.
Bazy grafowe
Po takim wstępie możemy przejść do opisania kolejnego etapu – baz grafowych. Pomysł wziął się ze spostrzeżenia, że relacje między przechowywanymi danymi można przedstawić w postaci grafu. Jeśli ktokolwiek przygotowywał graficznie schemat bazy danych, to zapewne pamięta tego rodzaju obrazki:
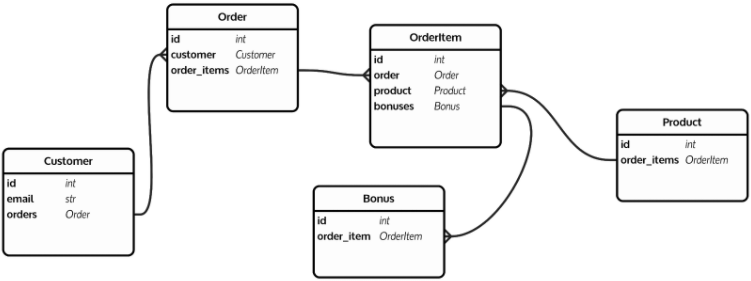
Szczególną uwagę należało tutaj poświęcać relacjom wiele-do-wielu z tabelami pośrednimi, gdzie mogliśmy zdefiniować dodatkowe parametry takiej relacji. A skoro relacje możemy parametryzować, to możemy zacząć korzystać z algorytmów grafowych do wyliczania interesujących nas zależności pomiędzy danymi.
Weźmy np. taki scenariusz:
Chcemy dostać listę wszystkich użytkowników mających między 21 a 30 lat, którzy w ciągu ostatnich 30 dni dokonali jednorazowego zakupu w naszym sklepie na kwotę większą niż 100 zł, łącznie w tym okresie zrobili co najmniej dwa zakupy i jednocześnie większość niż połowa kupionych przez nich produktów należała do jakiejś konkretnej kategorii.
Rozumiecie do czego zmierzam? Tego rodzaju zapytania mogą okazać się dość pracochłonne dla tabelarycznych baz danych. Do tego zaraz może okazać się, że warunków będzie jeszcze kilka, a czas oczekiwania na odpowiedź z bazy przestanie się mieścić w krytycznej granicy 300 ms. Trzeba zmienić podejście.

W tym momencie wkraczają bazy grafowe posiadające nie tylko pełną parametryzację relacji (wstęp do tego mieliśmy już przecież w bazach tabelarycznych), ale też implementację algorytmów grafowych po stronie bazy.
Kluczowe elementy
W bazach grafowych dane zapisujemy używając dwóch podstawowych elementów: Reprezentacją fizycznych obiektów są wierzchołki (węzły, ang. “node” lub “vertex”). Relacje pomiędzy obiektami zapisujemy tworząc krawędzie (ang. “edge”). Bardzo istotnym aspektem jest tutaj fakt, że wierzchołki i krawędzie mogą posiadać dowolną liczbę atrybutów, z których najważniejszy nazywamy etykietą – określa ona typ danego elementu. Najłatwiej będzie pokazać to na przykładzie.

Jak widać, atrybuty możemy przypisywać zarówno do wierzchołków, jak i do krawędzi.
Poza tym łatwo zauważyć, że jedną z najlepszych cech baz grafowych jest to, że są niesamowicie intuicyjne. Możemy rozmawiać o strukturze danych, narysować jej schemat i potem 1:1 przełożyć ją do bazy już na konkretne obiekty.
Korzyści
- intuicyjność – wspomniałem o tym przed chwilą. Możliwość reprezentowania danych w naturalny dla (przeciętnego) ludzkiego umysłu sposób. Zwykle analizując problem myślimy grafami nawet sobie tego nie uświadamiając.
- brak migracji – ponieważ dane nie mają sztywno narzuconej struktury, możemy w bardzo łatwy sposób uzupełniać obiekty o nowe dane. Zapytania uwzględniające nowe atrybuty będą po prostu pomijać obiekty, które ich nie posiadają.
- łatwość odpytywania – tutaj jest to często kwestia wybranego języka zapytań, aczkolwiek w przypadku deklaratywnych języków typu Cypher czy SparQL, możemy w kilku linijkach napisać zapytanie, które w SQL (też zresztą deklaratywnym, ale na innej warstwie) zajęłoby kilkadziesiąt linijek.
- szybkość – dzięki specyficznej implementacji i specjalnemu indeksowaniu, w wielu przypadkach można uzyskać przyspieszenia nawet o pięć rzędów wielkości (od minut do milisekund).
Zastosowania
Przejdźmy teraz do najpopularniejszych zastosowań. Oczywistym jest, że najlepszym polem wykorzystania takich baz są problemy, które możemy określić jako “mocno grafowe”. Jak je jednak zidentyfikować? Spróbujmy ścieżki “nie wprost” – odrzućmy tematy, do których baza grafowa nie nadaje się najlepiej.
Wyobraźmy sobie, że prowadzimy kawiarnię. Mamy listę produktów z cennikiem i zapisujemy transakcje. Jeśli interesują nas informacje na temat obrotów czy najpopularniejszych produktów, to baza grafowa nie jest dobrym wyborem – agregację informacji (sumowanie, wyliczanie średnich itp.) lepiej zostawić bazie tabelarycznej. Jeśli jednak spojrzymy nieco głębiej, znajdziemy zagadnienia o typowo grafowym rodowodzie: jakie produkty najczęściej kupowane są razem? W jakich godzinach i/lub w jakie dni dany produkt sprzedaje się najlepiej?
W rzeczywistości najlepszymi scenariuszami użycia baz grafowych są:
- systemy rekomendacji – im bardziej sprofilowany użytkownik, tym skuteczniej możemy polecać inne produkty,
- logistyka – jak najbardziej optymalnie dostarczać przesyłki, planowanie wycieczek, przelotów itp.,
- zarządzanie – jakie mamy zależności między komponentami infrastruktury? który element naszej infrastruktury jest najbardziej krytyczny?
- wykrywanie oszustw – jeśli mamy środki wychodzące z jednej instytucji do wielu różnych miejsc, ale kontrolowanych ostatecznie przez inną instytucję, to może warto przyjrzeć się bliżej, czy nie są naruszane przepisy o praniu pieniędzy.
Popularne implementacje
- Apache TinkerPop – ustanowił jeden ze standardów baz grafowych i jest wzorcem dla wielu pokrewnych baz, np. AWS Neptune czy Azure Cosmos DB. Oprócz samego silnika bazy zapewnia zaawansowane mechanizmy analizy danych. Językiem używanym w tych bazach jest Gremlin.
- Neo4j – jeden z najpopularniejszych silników baz grafowych. Językiem jest Cypher.
Jeśli zainteresował Cię ten temat, to gorąco zapraszam na meetup IT Depends, który odbędzie się online 31 marca 2021 o godz. 18:00 – opowiem tam nieco więcej o tematyce baz grafowych. Później będziesz mieć możliwość uczestniczenia w warsztatach, gdzie poznasz bliżej język Cypher i bazę Neo4j. Warsztaty poprowadzą Noemi Kowalewska i Tomek Klemens.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły
Podejście do zmniejszania kosztów przetwarzania danych na przykładzie Azure Databricks

Data management, data governance i data modernization - jak okiełznać proces zarządzania danymi w organizacji

Big Data - klęska urodzaju czy złoty Graal? Praktyczne metody wykorzystania potencjału danych
Dane 1,3 mln użytkowników Clubhouse do pobrania? To nie wyciek, to data scraping

Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Migracja do chmury? Wypełnij ankietę i sprawdź, jak wygląda ten proces u innych!

Analiza infrastruktury i danych IoT. Wybór bazy
