Jak działa mechanizm wyszukiwania w silniku Sitecore

W miarę przyrostu elementów, nawigowanie oraz odnajdowanie szukanego contentu staje się coraz trudniejsze. Naprzeciw temu wymaganiu staje bardzo powszechna funkcjonalność jaką jest wyszukiwanie. Właśnie ten temat z wykorzystaniem silnika Sitecore chciałbym wam trochę przybliżyć.

Mateusz Januszek. Sitecore Developer w KMD Poland (Charlie Tango). Lubi rozwiązywać trudne i skomplikowane problemy. Właśnie dlatego zdecydował się na Sitecore’a.
Podczas pisania aplikacji biznesowych opartych o systemy CMS, musimy liczyć się z ciągle rosnącą ilością elementów (strony, pliki, ustawienia itp.). Właściwie, możliwość rozbudowywania systemu CMS to jego główna cecha. Właśnie dlatego Sitecore jest tak potężnym narzędziem — jest to system zarządzania treścią, który dostarcza o wiele większe możliwości niż zwyczajne dodawanie stron i zarządzanie nimi (ale nie o tym dzisiejszy artykuł).
Spis treści
Item i Template
Aby zrozumieć mechanizm wyszukiwania w Sitecore, należy przybliżyć, w jaki sposób przechowuje on elementy oraz jak nimi zarządza.
Elementy systemu możemy podzielić na template’y oraz item’y. Template jest naszym szablonem — zawiera pola, ich typ oraz opisuje podstawowe zachowania. Item tworzymy na bazie template’u, jest on jednak oddzielną instancją (w uproszczeniu template możemy porównać do klasy — znanej nam z obiektowych języków programowania, item natomiast do obiektu).
Właściwie wykorzystując te dwa pojęcia jesteśmy w stanie opisać cały system, ponieważ każdy element w Sitecore jest itemem, a każdy item przechowywany jest w jednej z baz (core, master lub web).
O tym, czy item jest stroną, ustawieniem, źródłem zawartości czy jakąś akcją, decyduje tylko template (oraz jego implementacja w kodzie).
Warto również wspomnieć, że przykładowa strona demo pochodząca z projektu Habitat posiada blisko 6500 item’ów. Co prawda nie wszystkie z nich są użytkowymi stronami, którymi potencjalnie zainteresowany może być użytkownik, należy jednak zdawać sobie sprawę z ich ilości -– tym bardziej, że mówimy tu nadal o niemalże pustej stronie demonstracyjnej. W trakcie rozbudowywania strony przez edytorów (tzw. content edytor), dodatkowo dodawane są kolejne wersje językowe, a niekiedy również kolejne strony. Tym samym liczba itemów bardzo szybko rośnie. (Sam pracowałem przy projektach, które posiadały co najmniej dziesięciokrotnie więcej itemów niż opisany powyższej projekt).
Czysto teoretycznie, moglibyśmy pozwolić sobie na przeszukiwanie bazy pod kątem konkretnych predykatów — przy 6 tys. itemów nie powinno to być dla bazy za bardzo obciążające.
Ale co w przypadku gdy:
- naszych itemów jest znacznie więcej?
- okazuje się, że (mimo iż każde zapytanie jest dość skomplikowane i zawiera dodatkowe join’y i selecty) zapytania są niemalże identyczne, a różnią się tylko parametrem?
- naszą stronę odwiedza liczne grono odbiorców i chcielibyśmy, aby każdy z nich otrzymał wyniki wyszukiwania natychmiast, jednocześnie nie obniżając wydajności strony dla reszty użytkowników (no bo przecież wyszukiwania uruchamiane są w kontekście tej samej bazy, która służy do wyświetlania zawartości systemu),
- jednym z wymagań są sugestie możliwych zakończeń właśnie wpisywanej frazy (Przecież nikt nie będzie czekał na podpowiedzi, powinny pojawiać się natychmiast i dostosowywać do wpisywanego tekstu)?
W takiej sytuacji znacznie obciążylibyśmy bazę danych, co tym samym zmniejszyłoby jej wydajność i sprawiło, że użytkowanie systemu stałoby się dla użytkowników utrudnione.
Silniki indeksujące
Właśnie z tego powodu powstało wiele systemów indeksujących oraz platform ułatwiających wyszukiwanie. Również Sitecore daje nam możliwość do wykorzystania kilku z nich. Mamy do dyspozycji Lucene (który jest na chwilę obecną nierekomendowany i prawdopodobnie zostanie usunięty w przyszłych wersjach), Azure Search oraz Solr (jak i SolrCloud). Wszystkich tych dostawców cechuje możliwość dzielenia tekstu pod kątem słów, znaków przystankowych, jak i możliwość wyszukiwania opartego na wcześniej przygotowanych indeksach. Co więcej przechowują one dostarczone informacje (w naszym wypadku opisy item’ów) w oddzielnej bazie. Przeszukiwanie jej nie korzysta z podstawowej bazy Sitecore co implikuje brak obniżenia wydajności strony.
W swoim projekcie wybrałem właśnie Solr, ponieważ jest jednym z rekomendowanych rozwiązań, jest darmowy i dość prosty do uruchomienia na lokalnym komputerze. Spełnia również wymogi bezpieczeństwa — połączenie może odbywać się szyfrowanym kanałem. Solr to oprogramowanie napisane w języku Java, dostarczane przez organizację Apache Software Foundation w ramach projektu Apache Lucene, wykorzystujące właśnie bibliotekę Lucene do zapewnienia swojej podstawowej funkcjonalności, czyli wyszukiwania pełnotekstowego, indeksowania real-time, przechowywania dokumentów itp. Dodatkowo jest systemem skalowalnym tak więc nie powinniśmy się martwić ograniczonymi zasobami (z drugiej strony nie powinniśmy być rozrzutni, bo nie do tego skalowalność służy). Solr dostarcza również wyszukiwanie oparte o facet’y — kategoryzację wyników wyszukiwań. Nie będę ich używał w swoim przykładzie, tak więc zainteresowanych odsyłam do dokumentacji w celu zgłębienia tematu.
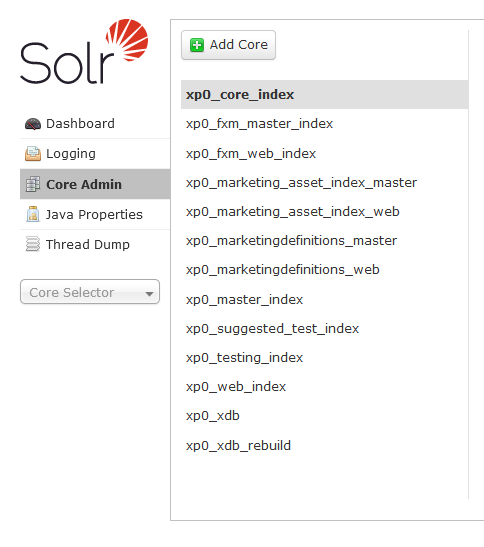
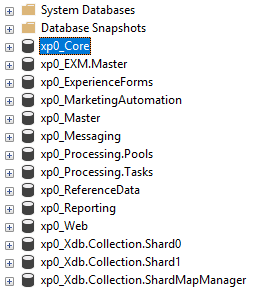
Jak widać na poniższym zdjęciu, nazwy części indeksów są analogiczne do nazwy baz na których operuje Sitecore (chodzi tu o bazę master I web które są w kręgu naszych zainteresowań). Wszystkie zostają stworzone podczas jego instalacji. Oczywiście nie jesteśmy ograniczeni do istniejących, jeżeli zajdzie taka potrzeba nic nie stoi na przeszkodzie by dodać kolejny.
Habitat
Podstawą funkcjonalności jest Habitat — przykładowy projekt stworzony w oparciu o zasady projektowania i konwencję Helix. W prostych słowach Helix to zbiór reguł, dzięki którym unikniemy robienia z solucji istnego coco jumbo. Dodatkowo pozwala on również na reużywalność (przy minimalnym nakładzie pracy polegającym na wpasowanie projektu do innego systemu) komponentów w innych solucjach.
Wprawdzie Habitat dostarcza już funkcję szukania, jednakże nie do końca pokrywa się ona z naszymi wymaganiami, oraz dostarcza o wiele więcej funkcjonalności niż jest nam potrzebne (nadmiarowy kod, który finalnie zwiększa rozmiar projektu oraz ilość zależności nie jest najlepszym wyjściem dla rozwiązań stosowanych na produkcji).
Spotkałem się również z dwiema konwencjami ustawiania stron i ich zawartości w drzewie Sitecore. Jedną z nich wykorzystuje standardowa strona demonstracyjna w Habitacie — konfiguracje oraz źródła umieszczone są bezpośrednio na stronie.
![]()
Zdecydowanym plusem takiego rozwiązania jest łatwość w poruszaniu się po systemie dla edytorów. Minusem jest brak współdzielenia zawartości między kilkoma stronami — przypadek gdy więcej niż jedna strona powinna posiadać np. ten sam tekst.
I tu właśnie przydaje się druga konwencja, która pozwala na umieszczanie wszystkich źródeł zawartości strony wprost pod nią tzw. local datasources:
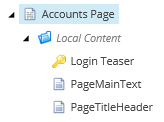
Rozwiązanie trochę bardziej skomplikowane, jednak pozwala na ułatwienia takie jak właśnie używanie tego samego źródła tekstu w kilku miejscach czy również możliwości personalizacji wyświetlanej zawartości strony pod kątem profilu osoby odwiedzającej.
W swoim projekcie z ww. powodów wybrałem drugie rozwiązanie i właśnie pod takim kątem będę implementował wyszukiwanie.
Przed przystąpieniem do technicznego opisu rozwiązania chciałbym wspomnieć, że proponowana implementacja dostosowana została do przedstawionych wymagań. Nie jest jedyną słuszną drogą — w pewnych konkretnych przypadkach inne rozwiązanie może okazać się o wiele bardziej korzystne.
Dla przypomnienia, wymagania dla naszego wyszukiwania to:
- sugestywne dokańczanie słów do aktualnie wpisywanej frazy oraz dynamiczne działanie bez opóźnień,
- możliwość dostosowywania przez edytorów co może być szukane, oraz co powinno zostać wyświetlone jako opis rezultatów tego działania,
- wyszukiwanie nie powinno obniżać wydajności strony dla reszty użytkowników.
Tak więc od czego zacząć?
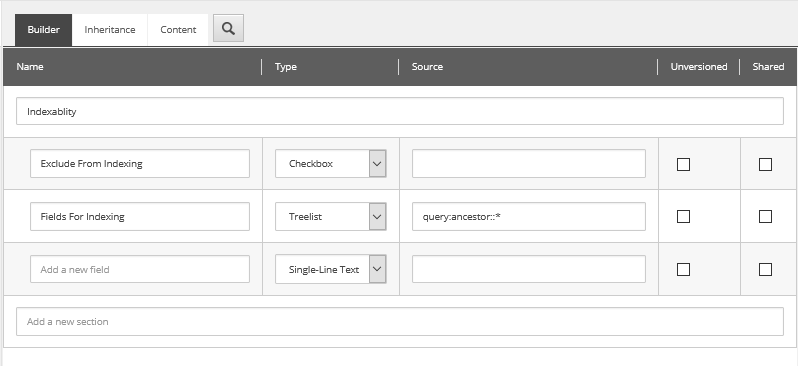
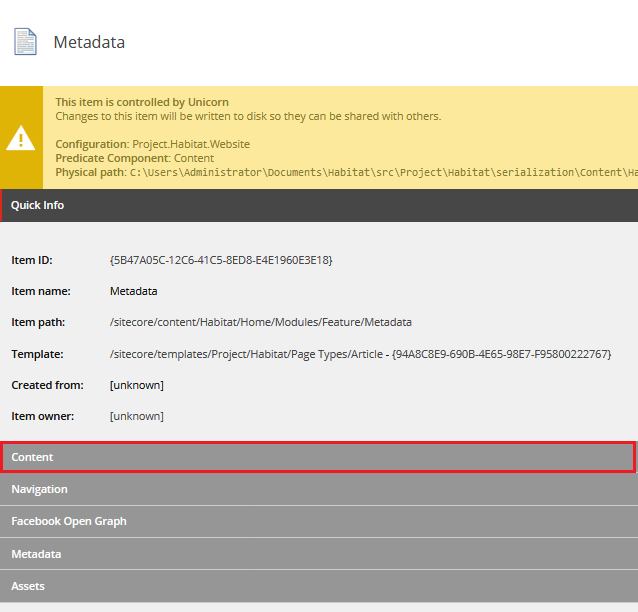
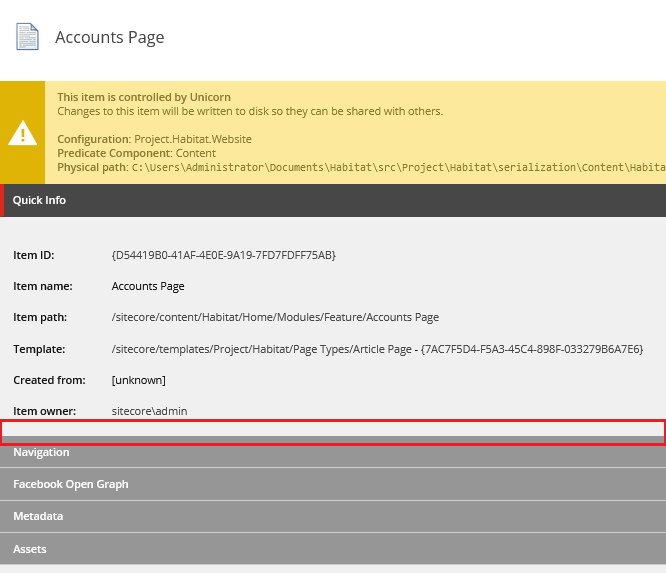
Po pierwsze, zaczynamy od utworzenia niezbędnych template’ów. Dzięki nim dostarczymy edytorom możliwość wyboru, które itemy mogą być wyszukiwane. Do tego celu tworzymy interfejs _Searchable (interfejsem nazywamy templaty, które posiadają tylko dane, bez warstwy prezentacji). Jednakże nie dodajemy do niego żadnych pól, ma on tylko pełnić rolę informacyjną. Kolejny interfejs _Indexable posiada dwa pola: „Exclude from indexing”, które pozwala na ominięcie pojedynczego modułu podczas indeksowania oraz „Fields for indexing”, które wskazuje na listą pół stanowiących źródło opisu. Datasource dla tego drugiego zostało uzupełnione w taki sposób, aby wskazywać na rodzica, co znacząco ułatwia proces ich wyboru (zdjęcie poniżej).
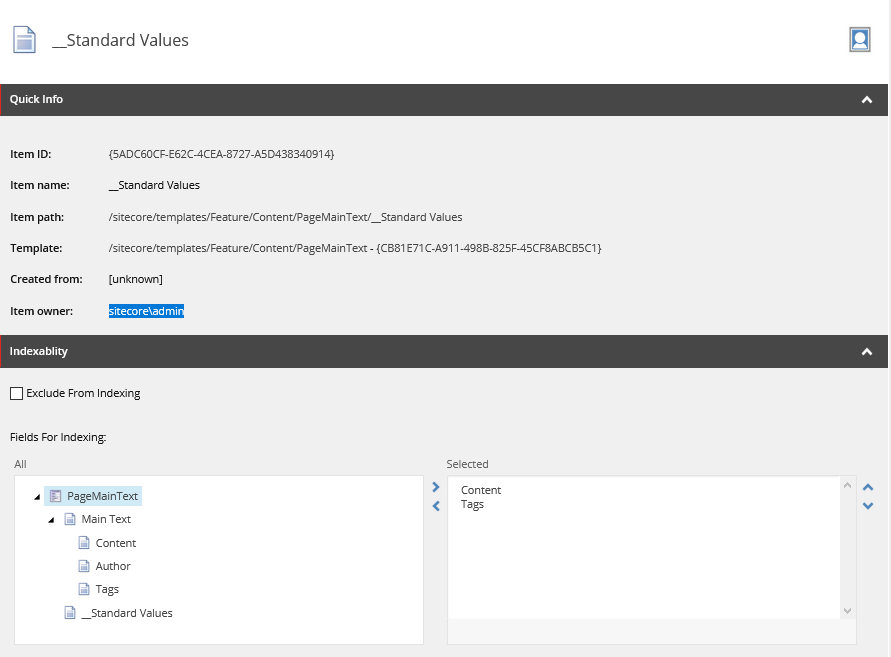
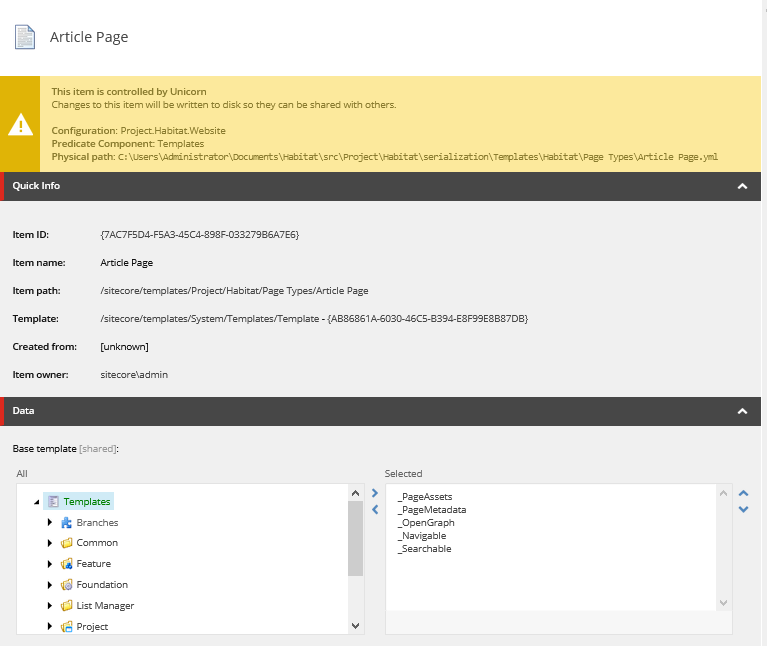
Teraz wybieramy moduł, który ma być brany pod uwagę podczas indeksowania. W moim wypadku to komponent PageMainText, ze wskazaniem na pola „Content” i „Tags”. Przykładowo template strony „Article Page” dziedziczy po interfejsie _Searchable, tak więc tylko tego typu strony poddane będą procesowi wyszukiwania.
Computed fields
Po drugie, implementacja, która pozwoli odpowiednio obsłużyć konfigurację stworzoną przez edytora. Jej podstawa to mechanizm computed fields, czyli dodatkowe pola dodane do rekordu w indeksie. Składa się na to deklaracja pól w plikach konfiguracyjnych oraz kod odpowiadający za uzupełnianie go. Podczas wyszukiwania używamy go jak reszty standardowo dostępnych pól.
Konfiguracja Computed Fields
<contentSearch>
<indexConfigurations>
<defaultSolrIndexConfiguration>
<documentOptions>
<fields hint="raw:AddComputedIndexField">
<field fieldName="_suggestivesearchdescription"
indexType="tokenized" returnType="text" storageType="no"
type="Sitecore.Feature.SuggestiveSearch.ComputedFields.SuggestiveSearchDescription,
Sitecore.Feature.SuggestiveSearch" />
<field fieldName="_searchable"
indexType="untokenized" returnType="bool" storageType="no"
type="Sitecore.Feature.SuggestiveSearch.ComputedFields.Searchable,
Sitecore.Feature.SuggestiveSearch" />
</fields>
</documentOptions>
</defaultSolrIndexConfiguration>
</indexConfigurations>
</contentSearch>
Pole _suggestivesearchdescription zostało oznaczone jako tokenized. Potrzebujemy użyć tej opcji, aby zostało podzielone przez analizator na pojedyncze słowa. Tak więc przykładowo tekst „Testowy artykuł” zostanie podzielony na „testowy” oraz „artykuł”. Oczywiście możemy rozszerzać funkcjonalność analizatorów oraz dodawać swoje własne, aczkolwiek w tym wypadku jest to w zupełności wystarczające.
SuggestiveSearchDescription.cs – Implementacja pola SuggestiveSearchDescription
public override object ComputeFieldValue(IIndexable indexable)
{
var rootItem = indexable as SitecoreIndexableItem;
if (rootItem == null || !rootItem.Item.Paths.IsContentItem)
{
return null;
}
var searchableItem =
rootItem?.Item?.Template.BaseTemplates.Any(baseTemplate => baseTemplate.ID
== Templates.Searchable.ID) ?? false;
if (!searchableItem)
{
return null;
}
var dataSourcesFolderTemplate = new
ID(Sitecore.Foundation.LocalDatasource.Settings.LocalDatasourceFolderTemplate);
var dataSourceItems = rootItem.Item?.Children?
.FirstOrDefault(x => x.TemplateID == dataSourcesFolderTemplate)?
.Children?
.Where(IndexableModule)
.Select(dataSourceItem => new SitecoreIndexableItem(dataSourceItem));
if (dataSourceItems == null)
{
return string.Empty;
}
var fullTextValues = dataSourceItems.SelectMany(GetTextFieldValues);
var description = string.Join(" ", fullTextValues);
var itemTitleField = rootItem.Item?.Name;
if (itemTitleField != null)
{
description = string.Concat(description, " ", itemTitleField);
}
return description;
}
W pierwszej kolejności sprawdzamy czy dany item dziedziczy interfejs _Searchable. Dzięki temu nie wykonujemy zbędnego pobierania danych oraz indeksowania itemów, które nie są przeznaczone do wyszukiwania. Następnie przeglądamy wszystkie dzieci folderu datasources i sprawdzamy je pod kątem możliwości indeksowania. Jak już wspomniałem wyżej, pole “Exclude from index” pozwala edytorom na wyłączanie konkretnego modułu z tego procesu.
SuggestiveSearchDescription.cs – Implementacja metody IndexableModule
private bool IndexableModule(Item item)
{
if (!item.Paths?.IsContentItem ?? false)
{
return false;
}
bool inheritIndexabilitySettings =
item?.Template?.BaseTemplates?.Any(x => x.ID ==
Templates.IndexabilitySetting.ID) ?? false;
if (!inheritIndexabilitySettings)
{
return false;
}
var excludedFromIndex = (CheckboxField)item.Fields.FirstOrDefault(x => x.ID == Templates.IndexabilitySetting.Fields.ExcludeFromIndexing);
if (excludedFromIndex == null)
{
return true;
}
else
{
return !excludedFromIndex.Checked;
}
}
Gdy moduły zostały już wybrane pozostała tylko iteracja po wybranych polach i wyciągnięcie ich wartości w odpowiednim formacie (w moim wypadku to pozbycie się wszelkich tagów html).
SuggestiveSearchDescription.cs — Implementacja metody GetTextFieldValues
private IEnumerable<string> GetTextFieldValues(SitecoreIndexableItem indexableItem)
{
indexableItem.LoadAllFields();
var indexableFields = indexableItem?.Fields?.FirstOrDefault(x =>
(ID)x.Id == Templates.IndexabilitySetting.Fields.FieldForIndexing);
if (indexableFields != null && indexableFields.Value != null)
{
var indexableFieldsSplited =
indexableFields.Value.ToString().Split('|');
var fields = indexableItem.Fields.Where(x =>
indexableFieldsSplited.Contains(x.Id.ToString()));
return fields.Select(field => GetFieldValue(indexableItem,
field)).Where(value => value != null);
}
else
{
return new List<string>();
}
}
Funkcjonalność indeksowania jest już niemalże skończona. Jako że podczas zmiany jakiegokolwiek itemu, indeksowanie jest uruchamiane automatycznie tylko dla niego, należy poinformować system, aby również poddał temu procesowi stronę dla której jest źródłem. Aby tego dokonać, należy użyć standardowego pipeline dostarczonego w bibliotece Sitecore.ContentSearch, który będzie rozszerzał kolejkę elementów o strony zależne.
GetLocalDatasourceDependencies pipeline
<pipelines>
<indexing.getDependencies>
<processor type="Sitecore.ContentSearch.Pipelines.GetDependencies.GetDatasourceDependencies, Sitecore.ContentSearch" />
</indexing.getDependencies>
</pipelines>
Jego działanie jest całkiem trywialne, wyszukuje wszystkie strony, które się do niego odwołują i dodaje je do kontekstu danego procesu indeksowania.
Pozostało już tylko odpowiednio zaimplementować dwie funkcje:
- zwracającą podpowiedzi do wpisanej frazy
- zwracającą wyniki wyszukiwania dla danej frazy
Wyszukiwanie sugestii do podanej frazy
SearchService.cs – Implementacja metody GetSearchSuggests
public IEnumerable<string> GetSearchSuggests(string query)
{
ISearchIndex index = IndexHelper.GetSearchIndex();
using(IProviderSearchContext context = index.CreateSearchContext())
{
var foundTokens =
context.GetTermsByFieldName("_suggestivesearchdescription", query);
return foundTokens.Select(x => x.Term);
}
}
Przeszukujemy wszystkie znalezione terminy dla pola _suggestivesearchdescription i zwracamy je użytkownikowi. Warto wspomnieć, że metoda GetTermsByFieldName zwraca je w kolejności podyktowanej częstością występowania danego słowa (malejąco).
Na dodatkową uwagę zasługuje również GetSearchIndex, która zwraca różne indeksy w zależności od bazy, z której korzysta strona. Rozwiązanie jest całkiem proste I stosowane już od dłuższego czasu. Nazwa bazy zostaje pobrana z kontekstu i przetłumaczona na nazwę indeksu, który następnie jest zwracany.
Po co tego potrzebujemy? Podczas publikowania itemy przenoszone są z bazy master do web i automatycznie update’owany jest również indeks. Indeksy są utworzone dla każdej z baz oddzielnie. Gdybyśmy użyli “na sztywno” któregoś z nich, to środowisko korzystające z drugiego, posiadałoby inne dane.

Wyszukiwanie stron na podstawie frazy
Aby móc w jakikolwiek sposób pracować z kodem na wynikach wyszukiwania, należy najpierw przygotować klasę, na którą będą rzutowane. W tym celu tworzymy klasę ContentSearchResultItem, która dziedziczy po SearchResultItem. Co ciekawe, wcale nie musimy niczego dziedziczyć ani implementować. Jedyne warunki jakie musi spełnić nasza klasa to:
- posiadać pusty konstruktor
- dostarczyć publiczne właściwości klasy posiadające gettery i settery
W praktyce jednak, znacznie prościej użyć poniższej konstrukcji, która również udostępnia nam wiele ciekawych właściwości.
ContentSearchResultItem.cs
public class ContentSearchResultItem : SearchResultItem
{
[IndexField("_suggestivesearchdescription")]
public string suggestivesearchdescription { get; set; }
[IndexField("_searchable")]
public bool Searchable { get; set; }
}
Skoro posiadamy już typ, na który rzutować będziemy wyniki, pozostało napisać metodę realizującą zapytanie. Do budowy predykatu posłużyłem się PredicateBuilderem, który znacznie ułatwia obsługę frazy składającej się z wielu słów (im więcej słów szukanych użytkownik dostarczy, tym bardziej celny wynik powinien otrzymać).
SearchService.cs – Implementacja metody GetSearchResults
public SearchResultsViewModel GetSearchResults(string query, int page, int pageSize)
{
var viewModel = new SearchResultsViewModel();
ISearchIndex index = IndexHelper.GetSearchIndex();
using (IProviderSearchContext context = index.CreateSearchContext())
{
var queryArray = query.Split(' ');
var predicate = PredicateBuilder.True<ContentSearchResultItem>();
foreach(var phrase in queryArray)
{
predicate = predicate.And(p => p.Name.Contains(phrase).Boost(2f) || p.Suggestivesearchdescription.Contains(phrase).Boost(1f));
}
predicate = predicate.And(p => p.Searchable);
predicate = predicate.And(p => p.Language == Sitecore.Context.Language.Name);
var results = context.GetQueryable<ContentSearchResultItem>().Where(predicate).Page(page, pageSize).GetResults();
viewModel.Results = ConvertToSearchResults(results);
viewModel.TotalResults = results.TotalSearchResults;
return viewModel;
}
}
Zastosowanie LINQ to Sitecore udostępnia nam dodatkowo bardzo pomocne rozszerzenie — Boost. Dzięki niemu jesteśmy w stanie zmieniać wagę naszych filtrów. Np. w powyższym wypadku zwiększamy dwukrotnie wagę wyniku jeżeli trafienie nastąpi w nazwie itemu, natomiast fraza znaleziona w zindeksowanym opisie pozostaje ze standardową wartością 1.
Działanie
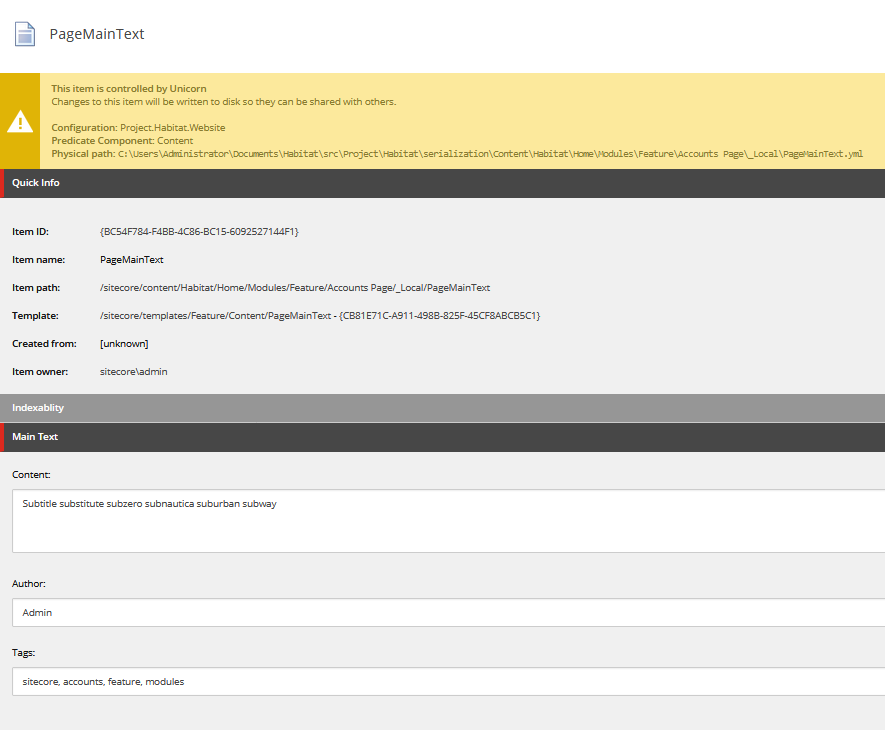
Pora podpiąć rozwiązanie i przetestować je w akcji. Jako content dodałem kilka słów zaczynających się od tych samych ciągów liter, aby wszystkie pojawiły się w podpowiedziach. Uzupełniłem również pozostałe pola, których wartość powinna pojawić się jako opisy wyniku szukania.
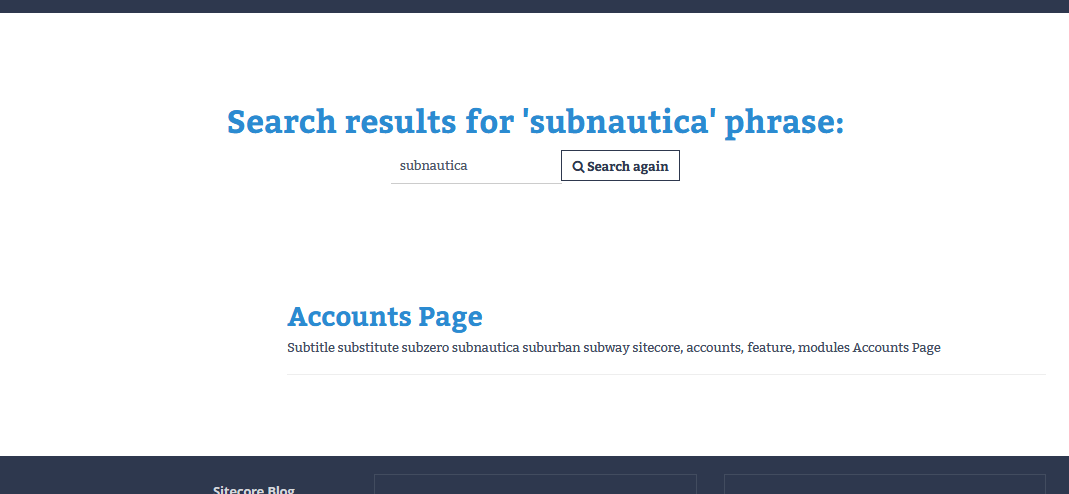
Poniżej rezultat podpowiedzi po wpisaniu frazy

A tutaj wynik wyszukiwania
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
