Instagram. W jaki sposób zbierałem dane o opublikowanych zdjęciach

Konto na Instagramie mam od kwietnia 2012 roku, ale nie zajmuje on mojego czasu (nie zaglądam tam wcale). Kiedyś chciałem sprawdzić czy zdjęcia z tagu #warszawa są zrobione w Warszawie, ale nie sprawdziłem… Do dzisiaj.

Łukasz Prokulski. Data analyst / R developer / PMO Manager w PZU. Uwielbia zajmować się liczbami, ich wizualizacją i wyciąganiem wniosków na podstawie ich analizy. Zna doskonale Excela, potrafi przygotować raporty w kilku narzędziach, a jego raporty wykorzystują dane z różnych źródeł. Jest fanem i popularyzatorem języka R.
Przedstawiony sposób może nie zadziałać, gdyż Instagram dodał zabezpieczenia anty-stalkingowe. Mimo to postanowiłem zaprezentować — w celach edukacyjnych — sposób, z jakiego korzystałem.
Tekst How I Eat For Free in NYC Using Python, Automation, Artificial Intelligence, and Instagram sprawił, że wreszcie ruszyłem tyłek i zająłem się tematem. Kilka miesięcy temu widziałem tutorial How to Get Instagram Followers/Likes Using Python, dzisiaj spróbujemy zrobić to samo, ale w R.
Celem będzie sprawdzenie, czy zdjęcia na Instagramie z tagiem #warszawa, rzeczywiście zostały zrobione w Warszawie. Założyłem jednak, że narzędzie powinno być uniwersalne, zatem uniwersalnie do niego podejdziemy.
Z niniejszego wpisu dowiesz się:
- jak pobrać informacje o zdjęciu z Instagrama,
- jak pobrać listę najnowszych zdjęć użytkownika oraz najnowszych i najpopularniejszych zdjęć z tagu,
- jak automatycznie dać like i napisać komentarz do zdjęcia,
- jak podglądać co automat klika w przeglądarce (odpalonej przez Dockera) z użyciem klienta VNC,
- a także zobaczysz kilka podstawowych danych o zdjęciach zebranych z tagów #warszawa i #warsaw.
Spis treści
Pobieranie danych z Instagrama
Zaczniemy od przygotowania funkcji zbierającej informacje o zdjęciu. Wchodzimy na Instagrama przez przeglądarkę WWW, wybieramy dowolne zdjęcie (nie kolekcję i nie wideo!) i zaglądamy w kod strony. Nie musimy mieć konta, nie musimy być na nim zalogowani. Ta część wpisu opiera się o zwykły scrapping strony.
Właściwie pełne informacje znajdziemy w kodzie w postaci JSONa – znakomicie ułatwia to pracę, nie trzeba szukać odpowiednich tagów HTML, wszystko podane jest na tacy. Część elementów jest też w nagłówku strony. Z pomocą selektorów XPath wydobywamy poszczególne fragmenty strony (w tym wspomnianego JSONa), a następnie nieco je przekształcamy jeśli trzeba. Pełna funkcja poniżej (komentarze tłumaczą, co i jak), potrzebne pakiety to: tidyverse, rvest, jsonlite oraz lubridate. Przykładowy wynik dla mojego testowego zdjęcia o ID BvUAaQkFb9_ (zobacz je na Insta, zerknij w kod źródłowy strony) będzie następujący:
get_post_details("BvUAaQkFb9_")
| post_id | post_author | post_title | post_created | post _location |
image_url | hashtags | like _count |
comment _count |
comments |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 1553258410 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | c(“warszawa”, “datascience”, “analiza”, “analizadanych”) | 8 | 2 | list(comment_author = c(“bobiko”, “lemur_78”), text = c(“w pythonie czy w go?”, “@bobiko w R”)) |
Elementy w kolumnach hashtags oraz comments są zagnieżdżone (po to, aby finalnie mieć jeden wiersz dla każdego postu), można je rozwinąć:
get_post_details("BvUAaQkFb9_") %>%
unnest(hashtags, .preserve = comments) %>%
unnest(comments)
| post_id | post_author | post_title | post_created | post _location |
image_url | like _count |
comment _count |
hashtags | comment _author |
text |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | analizadanych | bobiko | w pythonie czy w go? |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | analizadanych | lemur_78 | @bobikow R |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | analiza | bobiko | w pythonie czy w go? |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | analiza | lemur_78 | @bobikow R |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | warszawa | bobiko | w pythonie czy w go? |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | warszawa | lemur_78 | @bobikow R |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | datascience | bobiko | w pythonie czy w go? |
| BvUAaQkFb9_ | lemur_78 | Się inwestyguje instagrama na tagu #warszawa #analiza #analizadanych #datascience | 2019-03-22 13:40:10 | Warsaw, Poland | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 | datascience | lemur_78 | @bobikow R |
Widzimy, że liczba wierszy po rozwinięciu zagnieżdżeń rośnie, a wiele kolumn zawiera zduplikowane informacje. Stąd właśnie zagnieżdżenie w kolumnach.
No i ważna sprawa – informacja o liczbie komentarzy, lajków czy treść samych komentarzy pobierana jest na dany moment – to oczywiście się zmienia i jeśli chcemy mieć najświeższe dane to trzeba dany post pobrać jeszcze raz.
Dobrze, umiemy dobrać się do jednego zdjęcia, a co z pojedynczym użytkownikiem? Kolejna funkcja:
get_account_index <- function(insta_account) {
# budujemy link do strony profilu
index_url <- paste0("https://www.instagram.com/", insta_account, "/")
# próbujemy wczytać stronę z postem
page <- tryCatch(read_html(index_url), error = function(x) NULL)
# jeśli się nie udało to zwracamy pustą ramkę
if(is_null(page)) return(tibble())
script_json <- page %>%
# szukamy JSONa
html_node(xpath = '//body/script[@type="text/javascript"][1]') %>%
as.character() %>%
# jest w kawałku kodu JS przypisany do zmiennej - wywalamy przypisanie
str_replace("<script type="text/javascript">window._sharedData = ", "") %>%
str_replace(";</script>", "") %>%
# parsujemy JSONa
fromJSON(flatten = TRUE)
# składamy sobie ramkę
df <- script_json$entry_data$ProfilePage$graphql.user.edge_owner_to_timeline_media.edges[[1]] %>%
select(post_id = node.shortcode, # id postu
post_created = node.taken_at_timestamp, # data utworzenia postu
image_url = node.display_url, # link do zdjęia
like_count = node.edge_liked_by.count, # liczba lajków
comment_count = node.edge_media_to_comment.count) %>% # liczba komentarzy
# przekształcamy datę do odpowiedniego typu i ustawiamy strefę czasową na lokalną
mutate(post_created = as_datetime(post_created, tz = "Europe/Warsaw"))
return(df)
}
, która w efekcie daje nam:
get_account_index("lemur_78")
| post_id | post_created | image_url | like_count | comment_count |
| BvWcr05FZI3 | 2019-03-23 13:25:43 | https://scontent-waw1-1.cdninstagram.com/ | 13 | 0 |
| BvUAaQkFb9_ | 2019-03-22 14:40:10 | https://scontent-waw1-1.cdninstagram.com/ | 8 | 2 |
| Bs0rDwMF9ct | 2019-01-19 17:34:21 | https://scontent-waw1-1.cdninstagram.com/ | 2 | 0 |
| Bjz4uz1hkFF | 2018-06-09 18:32:02 | https://scontent-waw1-1.cdninstagram.com/ | 1 | 0 |
| Bire6zehmDX | 2018-05-12 15:41:10 | https://scontent-waw1-1.cdninstagram.com/ | 3 | 0 |
| BiXH02TBznR | 2018-05-04 17:54:34 | https://scontent-waw1-1.cdninstagram.com/ | 7 | 2 |
| BXYcuXBHD8- | 2017-08-04 20:31:05 | https://scontent-waw1-1.cdninstagram.com/ | 4 | 0 |
| BVmxlESnRBf | 2017-06-21 16:59:53 | https://scontent-waw1-1.cdninstagram.com/ | 7 | 0 |
| BVXa-Fsn4rB | 2017-06-15 17:53:43 | https://scontent-waw1-1.cdninstagram.com/ | 1 | 0 |
| BU4x5uphkpz | 2017-06-03 20:17:39 | https://scontent-waw1-1.cdninstagram.com/ | 4 | 0 |
| BSVofbMhstl | 2017-04-01 11:39:12 | https://scontent-waw1-1.cdninstagram.com/ | 2 | 0 |
| BOpsLjmgRIO | 2016-12-30 19:30:41 | https://scontent-waw1-1.cdninstagram.com/ | 1 | 0 |
, czyli podstawowe informacje o najnowszych 12 zdjęciach z profilu, w tym:
- id zdjęcia,
- datę jego utworzenia,
- link do zdjęcia,
- liczbę komentarzy,
- liczbę like’ów.
Dlaczego tylko 12 sztuk? Ano dlatego, że strony Instagrama są dynamiczne (i to w dość pokręcony sposób) – kolejne elementy dociągają się przy skrolowaniu strony. Pakiet rvest tego nie obsłuży, trzeba by inaczej do tego podejść jeśli chcielibyśmy ściągnąć całą zawartość profilu.
Pytanie tylko czy jest to potrzebne? Założyłem, że w maszynie, którą przygotowałem na potrzeby zebrania danych do niniejszego wpisu, wystarczy taka liczba. Można odwiedzić profil co jakiś czas (co ile to zależy od profilu – niektóre wrzucają zdjęcia tonami, inne raz na jakiś czas) i gromadzić tylko nowe zdjęcia. Kwestia potrzeby biznesowej.
Mając ID kolejnych zdjęć możemy oczywiście wywołać funkcję get_post_details() dla kolejnych ID i zebrać nieco więcej informacji (np. tagi). Na stronie profilu niestety informacji o tagach poszczególnych zdjęć nie mamy.
Zwróćcie też uwagę, że nie zbieramy informacji opisujących sam profil (liczba wszystkich postów, obrazek profilowy, jakieś dodatkowe opisy). Znowu: w tym zadaniu to nie są potrzebne informacje.
Celem jest sprawdzenie czy zdjęcia z tagu #warszawa są zrobione w Warszawie. Zatem potrzebujemy jeszcze pobrać dane ze strony samego tagu (bo skąd wiedzieć jakie profile publikują na tagu?). Kolejna funkcja, dość podobna do tej pobierającej dane z profilu:
get_tag_index <- function(insta_tag) {
# budujemy urla do strony tagu
index_url <- paste0("https://www.instagram.com/explore/tags/", insta_tag, "/")
# próbujemy wczytać stronę
page <- tryCatch(read_html(index_url), error = function(x) NULL)
# jeśli się nie udało to zwracamy pustą ramkę
if(is_null(page)) return(tibble())
# znajdujemy i parsujemy JSONa
script_json <- page %>%
html_node(xpath = '//body/script[@type="text/javascript"][1]') %>%
as.character() %>%
str_replace("<script type="text/javascript">window._sharedData = ", "") %>%
str_replace(";</script>", "") %>%
fromJSON(flatten = TRUE)
# top posty
df <- script_json$entry_data$TagPage$graphql.hashtag.edge_hashtag_to_top_posts.edges[[1]] %>%
select(post_id = node.shortcode, # id postu
post_created = node.taken_at_timestamp, # data utworzenia
image_url = node.display_url, # adres zdjęcia
like_count = node.edge_liked_by.count, # liczba lajków
comment_count = node.edge_media_to_comment.count) %>% # liczba komentarzy
# zmieniamy datę na "tutejszą"
mutate(post_created = as_datetime(post_created, tz = "Europe/Warsaw"))
# czy są najnowsze posty?
if(!script_json$entry_data$TagPage$graphql.hashtag.is_top_media_only) {
# są - pobieramy najnowsze posty
df_new <- script_json$entry_data$TagPage$graphql.hashtag.edge_hashtag_to_media.edges[[1]] %>%
select(post_id = node.shortcode,
post_created = node.taken_at_timestamp,
image_url = node.display_url,
like_count = node.edge_liked_by.count,
comment_count = node.edge_media_to_comment.count) %>%
mutate(post_created = as_datetime(post_created, tz = "Europe/Warsaw"))
# dodajemy najnowsze do ramki z top-postami, zostawiając tylko unikaty
df <- bind_rows(df, df_new) %>% distinct()
}
return(df)
}
Dlaczego sprawdzamy dwa elementy strony? Na stronie tagu mamy dwie sekcje top zdjęcia i najnowsze zdjęcia, przy czym tej drugiej może w ogóle nie być (sprawdźcie tag #sexy). W helpie napisano, że może nie być też części top posty (przed czym powyższa funkcja nie zabezpiecza).
Wynik działania jest podobny do get_account_index():
get_tag_index("warszawa")
{kind=link}
W sumie mamy jakieś 80 zdjęć (ta liczba się różni dla różnych tagów i w różnym czasie, szczerze mówiąc nie badałem dlaczego).
Niestety nie mamy informacji o autorze zdjęcia, co komplikuje nieco sprawę. Precyzyjniej: ta informacja jest, ale autor jest ukryty pod numerkiem, a nie nickiem. Dlatego nawet jej nie pobieram.
Na koniec możemy mieć ochotę na zapisanie zdjęcia na dysk. To już banalna sprawa – wystarczy po prostu zapisać plik spod adresu image_url. Też funkcja (ta dodatkowo potrzebuje pakietu fs dla użytych funkcji dir_exists() oraz dir_create(), które są też w podstawowym R – odpowiednio dir.exists() i dir.create()):
download_instagrm_photo <- function(post_id, image_url, dest = "") {
if(dest != "") {
if(!dir_exists(dest)) dir_create(dest)
download.file(image_url, paste0(dest, "/", post_id, ".jpg"), mode = "wb", quiet = TRUE)
} else {
download.file(image_url, paste0(post_id, ".jpg"), mode = "wb", quiet = TRUE)
}
}
Funkcja przyjmuje trzy parametry:
- post_id – ID postu z którego pochodzi zdjęcie. Potrzebne tylko po to, aby obrazek na dysku nazwać tym ID,
- image_url – adres zdjęcia,
- dest – folder, do którego obrazek ma zostać zapisany. bo możemy chcieć zapisywać pliki w folderach podzielonych według autorów.
Wszystkie przygotowane funkcje mają swoje zasadnicze ograniczenie – biorą to, co jest widoczne bez przewijania strony. Ma to swoje zalety (działa szybko), ale też sporą wadę – żeby zebrać więcej danych trzeba uruchamiać je co jakiś czas. Można próbować pozbyć się tej niedogodności z użyciem np. Selenium i symulować przeglądarkę, przewijanie strony itd. Do Selenium za chwilę dojdziemy, ale na potrzeby tego postu przygotowałem skrypt, który uruchamiał się co piętnaście minut (na przemian dla tagu #warszawa i #warsaw).
Skrypt zapisywał dane do pliku lokalnego, zbierał wszystko co zwraca funkcja get_post_details() (a zatem też komentarze i hashtagi). Jeśli czegoś nie potrzebujemy to możemy nie zbierać. I o wiele lepszym rozwiązaniem jest zapisywanie wyniku do bazy danych (np. jakiś SQL), niż trzymanie wszystkiego w pliku.
Algorytm działania był następujący:
- co 15 minut wejdź na stronę tagu,
- pobierz informacje o wszystkich zdjęciach jakie są na tej stronie (ich ID) (get_tag_index()),
- dla każdego pobranego zdjęcia:
- wejdź na stronę zdjęcia (get_post_details()),
- zapisz dane do pełnej bazy,
- znajdź autora zdjęcia (kolumna post_author)
- idź na stronę autora i zbierz najnowsze jego zdjęcia (get_account_index())
- dla każdego z zdjęć autora
- sprawdź czy to zdjęcie już mamy w pełnej bazie
- jeśli nie mamy:
- wejdź na stronę zdjęcia
- zbierz informacje o zdjęciu (get_post_details())
- zapisz te informacje do pełnej bazy
- jeśli mamy – idziemy do następnego zdjęcia
- idź do następnego autora
- idź do następnego zdjęcia ze strony tagu,
- koniec
Dzięki takiemu podejściu dostajemy nie tylko najnowsze zdjęcie danego użytkownika z wybranego tagu, ale też kawałek jego starych zdjęć, być może nawet wcześniejszych niż początek zbierania danych (w moim przypadku to i sprzed kilku lat, taki jestem aktywny!).
Na stronie tagu pojawia się wspomniane 80 zdjęć. Niech każde będzie unikalne z unikalnym autorem – musimy więc sprawdzić 80 stron pojedynczego zdjęcia, aby znaleźć 80 autorów. To już 81 zapytań (1 na stronę tagu, 80 na autorów zdjęć z tagu). Teraz dla 80 autorów sprawdzamy ich profil (kolejne 80 zapytań), aby pobrać ich najnowsze zdjęcia (12 na każdego autora, łącznie 80*12 = 960 zapytań). Część będzie się powtarzać (są na stronie tagu, były już wcześniej), ale licząc maksimum mamy do pobrania jedną stronę tagu + 80 zdjęć z tagu + 80 stron autorów + 80*12 ich najnowszych zdjęć co daje 1121 zapytań. Bardzo dużo. Łatwo dostać bana za takie coś. Warto też pomyśleć o optymalizacji (na przykład nie pobierając szczegółów zdjęcia o ile nie potrzebujemy tagów).
Szybka analiza
Przygotowałem odpowiedni skrypt, który działał według powyższego algorytmu przez kilka dni i zebrał (w tym momencie) informacje o 158.4 tys obrazków. Skrypt zbierał zaczynając od tagów #warszawa i #warsaw (ale przecież zgodnie z algorytmem brał też historię autorów zdjęć).
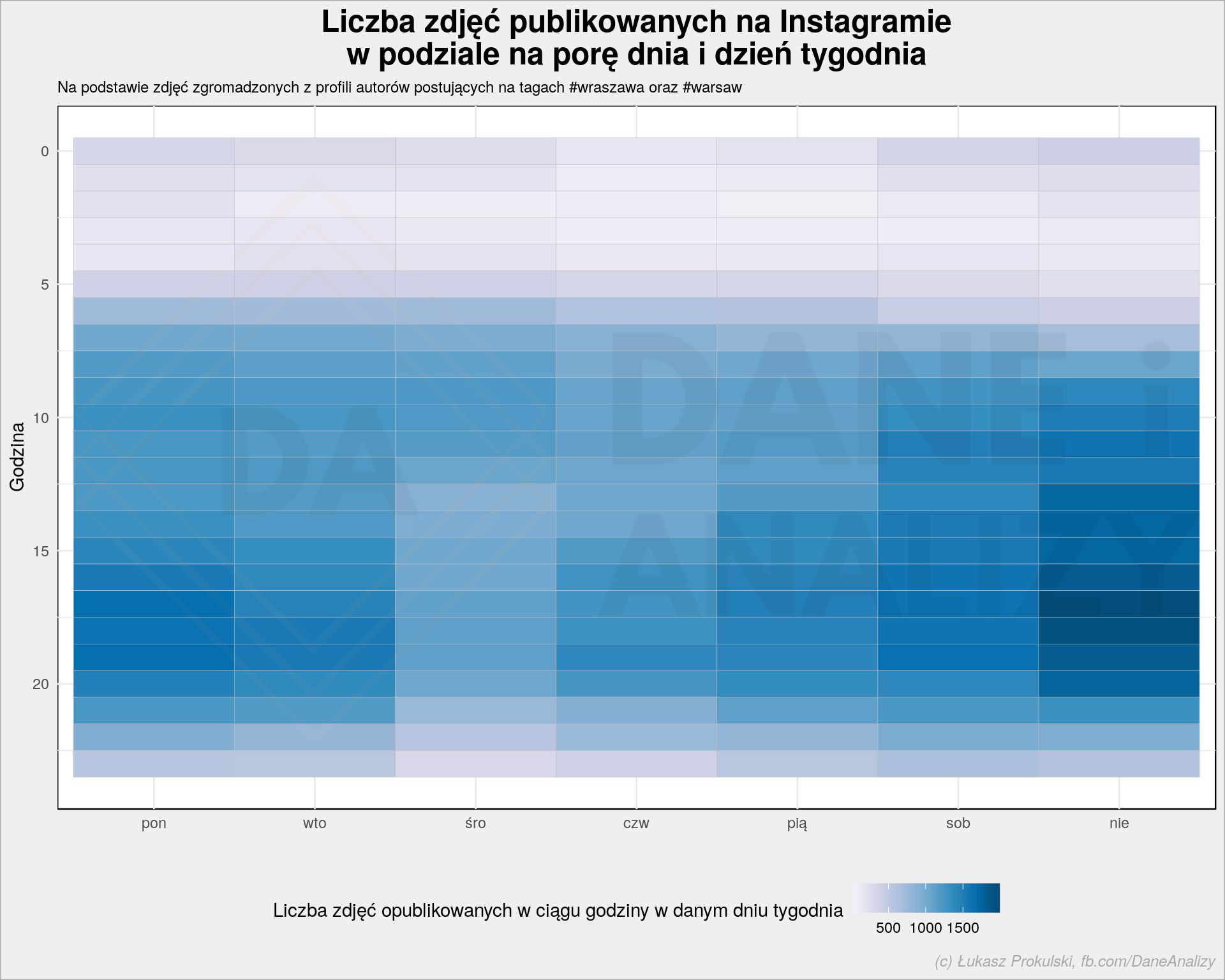
Zobaczmy jak wygląda liczba publikowanych zdjęć w czasie:
all_pics %>%
select(post_created) %>%
mutate(h = hour(post_created),
w = wday(post_created, week_start = 1,
label = TRUE, locale = "pl_PL.UTF-8")) %>%
count(w, h) %>%
ggplot() +
geom_tile(aes(w, h, fill = n), size = 0.1, color = "gray") +
scale_fill_distiller(palette = "PuBu", direction = 1) +
scale_y_reverse() +
labs(x = "", y = "Godzina",
title = "Liczba zdjęć publikowanych na Instagramienw podziale na porę dnia i dzień tygodnia",
subtitle = "Na podstawie zdjęć zgromadzonych z profili autorów postujących na tagach #wraszawa oraz #warsaw",
fill = "Liczba zdjęć opublikowanych w ciągu godziny w danym dniu tygodnia")
Dane zacząłem zbierać około południa 22 marca, stąd dni wcześniejsze są nieco niższe (ale jak widać algorytm dociągnął historię co pozwoliło na ładne wyrównanie). Wyraźnie widać dzień i noc oraz z grubsza rytm internetu w ciągu dnia (pik rano, płasko w południe i więcej wieczorem). 24 marca wieczorem odbył się mecz Polska-Łotwa na Stadionie Narodowym, co zaowocowało zwiększoną liczbą zdjęć z Warszawy.

Możemy też popatrzyć na rozkład liczby zdjęć publikowanych w ciągu tygodnia, chociaż w momencie przygotowywania tego postu nie minął pełny tydzień zbierania danych (sprawne oko zauważy, kiedy post był renderowany do publikacji):
all_pics %>%
select(post_created) %>%
mutate(h = hour(post_created),
w = wday(post_created, week_start = 1,
label = TRUE, locale = "pl_PL.UTF-8")) %>%
count(w, h) %>%
ggplot() +
geom_tile(aes(w, h, fill = n), size = 0.1, color = "gray") +
scale_fill_distiller(palette = "PuBu", direction = 1) +
scale_y_reverse() +
labs(x = "", y = "Godzina",
title = "Liczba zdjęć publikowanych na Instagramienw podziale na porę dnia i dzień tygodnia",
subtitle = "Na podstawie zdjęć zgromadzonych z profili autorów postujących na tagach #wraszawa oraz #warsaw",
fill = "Liczba zdjęć opublikowanych w ciągu godziny w danym dniu tygodnia")
Zobaczmy jeszcze jakie tagi są najpopularniejsze, bo to jest ciekawe (społecznie, wiele mówi o Instagramie):
all_pics %>%
select(hashtags) %>%
unnest() %>%
count(hashtags, sort = TRUE) %>%
top_n(30, n) %>%
mutate(hashtags = fct_reorder(hashtags, n)) %>%
ggplot() +
geom_col(aes(hashtags, n), fill = "lightgreen") +
coord_flip() +
labs(x = "", y = "",
title = "Najpopularniejsze tagi na Instagramie",
subtitle = "Na podstawie zdjęć zgromadzonych z profili autorów postujących na tagach #wraszawa oraz #warsaw")
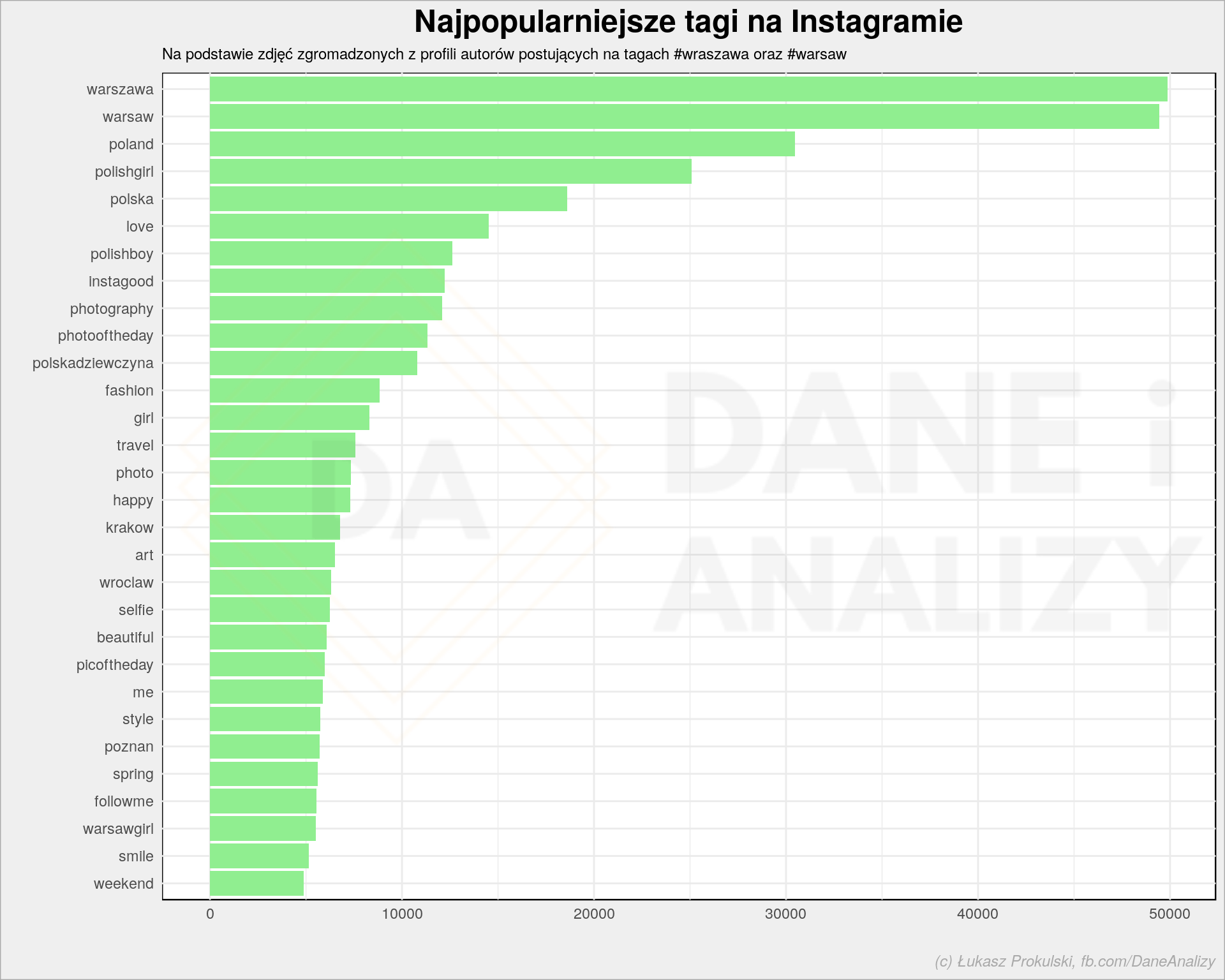
Oczywiście dużo jest tagów warszawskich, bo to one są głową dla zbieranych danych i od nich się zaczyna. Dużo mamy też autolansu, o który chyba na Insta chodzi…
Sprawdźmy teraz gdzie były robione zdjęcia.
Tutaj idealnie byłoby użyć danych EXIF, ale ze względów bezpieczeństwa wszystkie serwisy społecznościowe czyszczą te dane przy uploadzie plików (a jeśli tego nie robią to bardzo źle), więc nie dowiemy się prawdy a jedynie tego co podają użytkownicy. A podają:
# wszystkie zdjęcia
all_photos <- all_pics %>%
select(post_location) %>%
# tylko zdjęcia, które mają lokalizację
filter(!is.na(post_location)) %>%
# korygujemy lokalizacje Warszawy, aby Warsaw i Warszawa to było to samo
mutate(post_location = str_replace_all(post_location, ", Poland", "")) %>%
mutate(post_location = str_replace_all(post_location, "Europe/Warsaw", "Warszawa")) %>%
mutate(post_location = str_replace_all(post_location, "Warsaw", "Warszawa")) %>%
# zliczamy ile zdjęć było w każdej z lokalizacji
count(post_location)
warsaw_photos <- all_pics %>%
# tylko zdjęcia, które mają lokalizację
filter(!is.na(post_location)) %>%
# potrzebujemy rozwinąć kolumnę z tagami
select(post_id, post_location, hashtags) %>%
unnest(hashtags) %>%
# tylko tagi #warszawa i #warsaw
filter(hashtags %in% c("warszawa", "warsaw")) %>%
select(post_id, post_location) %>%
# ale tylko unikalne zdjęcia
distinct() %>%
mutate(post_location = str_replace_all(post_location, ", Poland", "")) %>%
mutate(post_location = str_replace_all(post_location, "Europe/Warsaw", "Warszawa")) %>%
mutate(post_location = str_replace_all(post_location, "Warsaw", "Warszawa")) %>%
count(post_location)
# łączymy informacje o wszysstkich zdjęciach oraz o tych z wybranych tagów
inner_join(all_photos %>% rename(all_n = n),
warsaw_photos %>% rename(waw_n = n),
by = "post_location") %>%
# bierzemy top 30 lokalizacji z puli zdjęć z wybranych tagów
top_n(30, waw_n) %>%
# układamy słupki na wykresie w odpowiedniej kolejności
mutate(post_location = fct_reorder(post_location, all_n)) %>%
ggplot() +
geom_col(aes(post_location, all_n), fill = "gray") +
geom_col(aes(post_location, waw_n), fill = "lightgreen") +
geom_text(aes(post_location, all_n, label = sprintf("%.1f%%", 100*waw_n/all_n)), hjust = -0.1) +
coord_flip() +
labs(title = "Najpopularniejsze lokalizacje podane przy zdjęciach na Instagramie",
subtitle = "Na podstawie zdjęć zgromadzonych z profili autorów postujących na tagach #wraszawa oraz #warsaw",
x = "", y = "Liczba zdjęć")
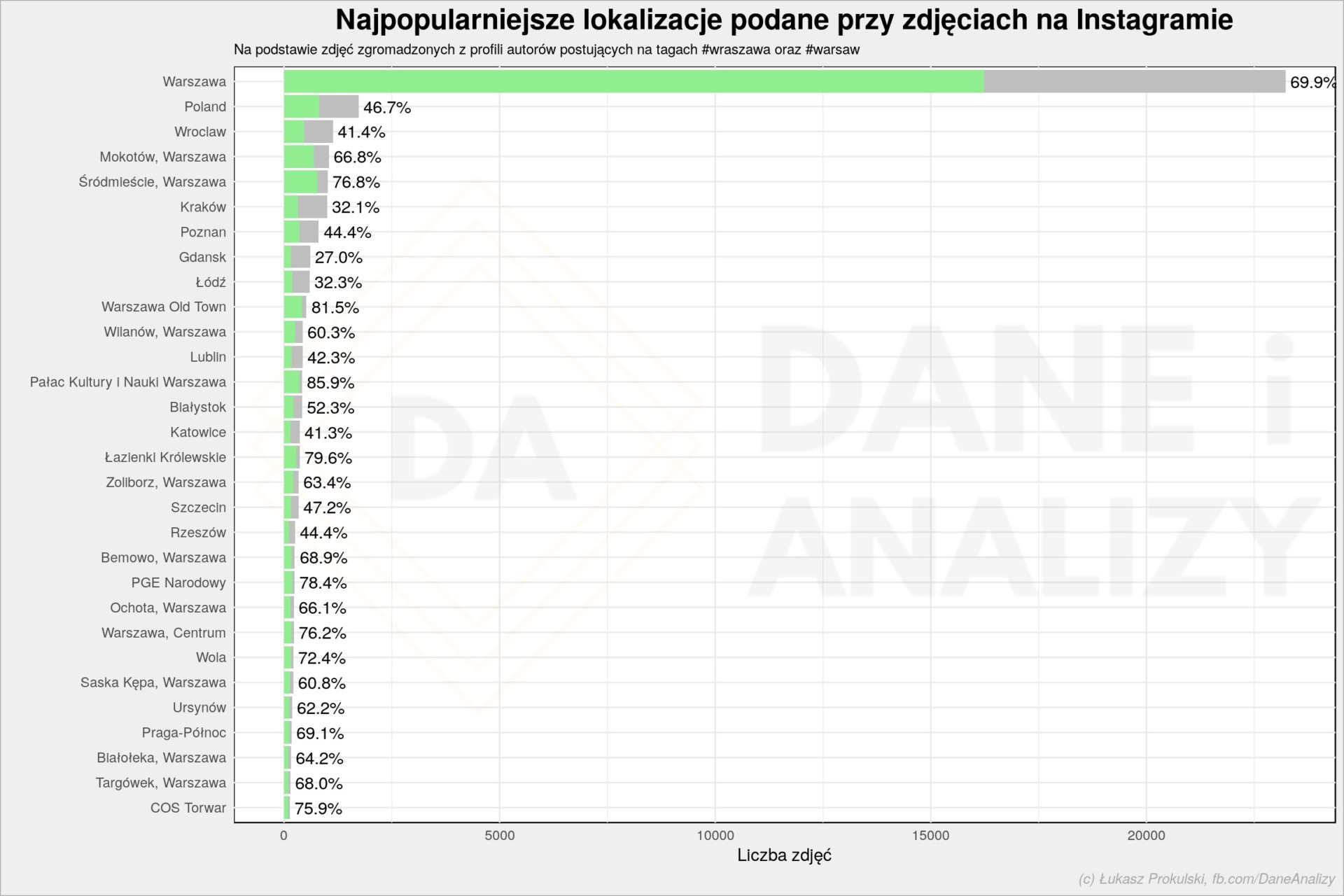
Warszawa dominuje, czasem wskazane są konkretne dzielnice. Szare paski oznaczają wszystkie zdjęcia, zielone – te, które mają tag #warszawa i/lub #warsaw. Liczba przy słupku to procent zdjęć z którymś z tych tagów. Zatem około 70% zdjęć oznaczonych jako zrobione w Warszawie (konkretnie, bez agregacji z dzielnic) ma jeden z wybranych tagów. Lokalizacje, które mają największy udział warszawskich tagów (spośród górnego 2% lokalizacji pod względem popularności):
| Lokalizacja zdjęcia | Liczba wszystkich zdjęć | Liczba zdjęć warszawskich | Procent |
| EXPO XXI Warszawa – Międzynarodowe Centrum Targowo-Kongresowe | 58 | 51 | 87.93 |
| Zamek Królewski w Warszawie | 58 | 51 | 87.93 |
| Pałac Kultury i Nauki Warszawa | 417 | 358 | 85.85 |
| Stadion Miejski Legii Warszawa im. Marszałka Józefa Piłsudskiego | 62 | 51 | 82.26 |
| Warszawa Old Town | 520 | 424 | 81.54 |
| Praga, Warszawa | 115 | 92 | 80.00 |
| Warszawa Stare Miasto | 89 | 71 | 79.78 |
| Łazienki Królewskie | 363 | 289 | 79.61 |
| PGE Narodowy | 241 | 189 | 78.42 |
| klub Stodoła | 68 | 53 | 77.94 |
| Progresja | 74 | 57 | 77.03 |
| Śródmieście, Warszawa | 1010 | 776 | 76.83 |
| Lotnisko Chopina | 76 | 58 | 76.32 |
| Warszawa, Centrum | 227 | 173 | 76.21 |
| Ptak Warszawa Expo | 79 | 60 | 75.95 |
| COS Torwar | 133 | 101 | 75.94 |
| Centrum Praskie Koneser | 71 | 53 | 74.65 |
| Bulwary Wiślane | 84 | 62 | 73.81 |
| Neon Muzeum | 67 | 49 | 73.13 |
| Bielany dzielnica Warszawy | 80 | 58 | 72.50 |
To się zmienia dynamicznie i zależy od puli zgromadzonych zdjęć. W każdym razie wszystkie leżą w Warszawie. Ale tagami warszawskimi oznaczane są też takie lokalizacje jak:
- 3 Warszawa
- Bubbleology Polska
- Centrum
- Cleve, Germany
- Fitness Klub Aplauz
- Jasnochówka
- Jenna JKO Tattoo
- Kondratowicza
- Kreator Mocy
- KROPKA nad ink
- Leonardo Verde
- Lombard Ruska 38 Rynek Wrocław 7 dni w tygodniu 792 038 038
- Miasto Ogród Komorów, Warszawa
- Niezły Mexyk Tattoo
- Plac Narutowicza
- Powisle, Warszawa
- Przestrzeń Tattoo
- Razors Barber Shop
- Restauracja Krasnodwór
- Si Fashion
- Skinissimo
- Stacja Grawitacja Warszawa
- Waves Tattoo
- Zespół Szkół Odzieżowych Poznań
No jak widać niektóre firmy na swoich profilach tagują jak opętane, żeby tylko zwiększyć zasięg.
Zobaczmy jeszcze co ciekawego ludzie piszą w komentarzach. Najprościej będzie na poziomie bi-gramów, bo pojedyncze słowa niewiele wnoszą to takiej informacji (no dobra – sprawdzałem i wiem, że niewiele odbiega to od bi-gramów):
# biblioteki do podziału tekstu na części i rysowania chmurek słów
library(tidytext)
library(wordcloud)
# słownik polskich stop-words
pl_stop_words <- read_lines("~/RProjects/!polimorfologik/polish_stopwords.txt")
# dzielimy komentarze na bigramy
biword_comments <- all_pics %>%
# potrzebne nam same komentarze
select(comments) %>%
unnest(comments) %>%
# rozdzielamy treśc komentarzy na bigramy
unnest_tokens("word", text, token = "ngrams", n = 2) %>%
# bigramy rozdzielamy na pojedyncze słowa
separate(word, c("word1", "word2"), sep = " ") %>%
# usuwaamy polskie stop words w pierwszym słowie
filter(!word1 %in% pl_stop_words) %>%
# usuwamy angielskie stop words w pierwszym słowie
filter(!word1 %in% stop_words$word) %>%
# to samo dla drugiego słowa
filter(!word2 %in% pl_stop_words) %>%
filter(!word2 %in% stop_words$word) %>%
filter(!is.na(word1), !is.na(word2)) %>%
# łączymy słowa
unite(word, word1, word2, sep = " ") %>%
# zliczamy wystąpień
count(word)
# rysujemy chmurkę słów
wordcloud(biword_comments$word,
biword_comments$n,
max.words = 100,
scale = c(2.6, 1.4),
colors = RColorBrewer::brewer.pal(12, "Paired"))
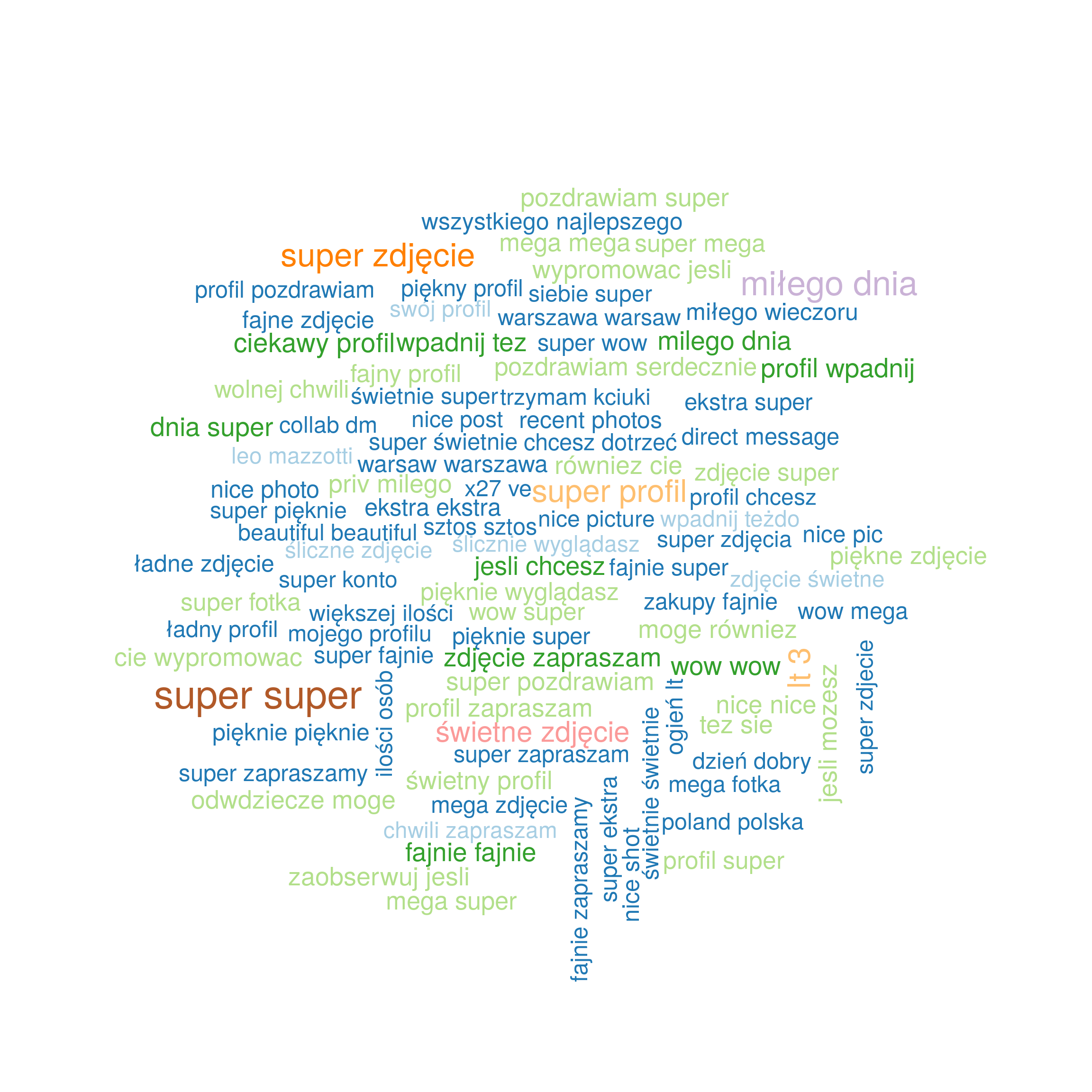
lt 3 to serduszko zapisane jako <3. Poprawnie byłoby poczyścić takie rzeczy (rozkodować znaki UTF i encje). Z kolei warszawa warsaw to zapewne to samo co #warszawa #warsaw, czyli tagi w komentarzach – też można to wyczyścić.
Ogólnie rzecz biorąc szału nie ma. Wszyscy wszystko sobie chwalą i zapraszają do siebie. Ale Instagram to nie jest forum publicystyczne czy miejsce wymiany opinii – tutaj ogląda się zdjęcia dziewczyn, ich paznokci i kosmetyków oraz daje serduszka i wysyła buziaczki. IQ na poziomie chomika wystarczy.
Co jeszcze można zrobić z tymi danymi?
Wiele rzeczy. Można zobaczyć rozkład liczby lajków i komentarzy, można zobaczy kto komu komentuje posty (analiza sieci społecznych). A w prosty sposób można przygotować dokument RMarkdown, który po wyrenderowaniu da nam statyczną stronę z na przykład najnowszymi zdjęciami z danego tagu. Przykładowy dokument:
---
title: "Instagram"
output:
html_document:
self_contained: no
params:
hashtag: "warszawa"
---
```{r include=FALSE}
library(tidyverse)
library(lubridate)
library(glue)
# gdzie trzymamy dane
saved_data_path <- "/home/lemur/RProjects/instagram/grabbed.RDS"
# pobranie strony tagu
all_pics <- readRDS(saved_data_path)
post_data <- all_pics %>%
filter(post_created >= today() - days(7)) %>%
select(post_id, post_author, post_title, post_created, image_url, hashtags) %>%
unnest(hashtags) %>%
filter(hashtags == str_to_lower(params$hashtag)) %>%
select(post_id, post_author, post_title, post_created, image_url) %>%
distinct()
```
<table>
<thead>
<tr>
<th width=400></th>
<th width=200></th>
</tr>
</thead>
<tbody>
```{r, echo=FALSE, results='asis'}
post_data %>%
mutate(post_title = str_replace_all(post_title, "n", "<br/> ")) %>%
mutate(post_title = str_replace_all(post_title, "([^[:blank:]])#", "\1 #")) %>%
arrange(post_created) %>%
mutate(even = if_else(row_number() %% 2 == 1,
"background-color:#ddd;",
"background-color:#eee;")) %>%
mutate(html = glue('<tr style="{even}">
<td style="padding:10px;">
<h4>{post_title}</h4>
</td>
<td style="vertical-align:top; text-align:right; padding:10px">
<strong><a href="https://www.instagram.com/{post_author}">{post_author}</a></strong><br/>
<em><a href="https://www.instagram.com/p/{post_id}/">{post_created}</a></em>
</td>
</tr>
<tr style="{even}">
<td colspan=2 style="text-align:center; padding:10px">
<img src="{image_url}" width=600 />
</td>
</tr>')) %>%
select(html) %>%
pull(html)
```
</tbody>
</table>
, który zapisany jako plik instagram.Rmd można wyrenderować do HTMLa za pomocą:
rmarkdown::render("instagram.Rmd", params = list(hashtag = "warszawa"))
Oczywiście wybór zdjęć do pokazania może być zupełnie inny – tutaj pokazujemy po prostu wszystkie z ostatnich 7 dni z podanym tagiem. Ale można zastosować inne filtry (np. po ilości komentarzy czy lajków, po lokalizacji), co powinno utworzyć plik HTML (razem z kilkoma folderami) z przeglądem zdjęć zgromadzonych z tagu warszawa (zgodnie z podanym parametrem hashtag). Uwaga – im bardziej popularny tag tym więcej zdjęć będzie musiało się załadować przy otwarciu wygenerowanego dokumentu. #Warszawa nie jest więc za mądrym wyborem.
W podobny sposób można przygotować aplikację w Shiny, która pozwoli na filtrowanie (np. po tagu i czasie) zdjęć.
W tego typu rozwiązaniach rozsądniej jednak zbierać dane do bazy danych i na jej poziomie wyszukiwać odpowiednie zdjęcia.
Komentowanie i lajkowanie
Przejdźmy do następnego poziomu zaawansowania, czyli automatyki. Potrafimy pobrać dane o zdjęciach, zdjęcia z tagu i z profilu. Może da się też je automatycznie komentować albo lajkować? Oczywiście!
Do tego potrzebujemy już konta i maszyny, która będzie udawała nasze poruszanie się po stronie. Pisałem o tym już w poście Webscrapping w R, tutaj krótkie przypomnienie.
(R)Selenium
Przede wszystkim potrzebujemy zainstalowanego Dockera i obrazu z przeglądarką. W niniejszym przykładzie skupimy się na obrazie selenium/standalone-firefox-debug z dwóch powodów:
- wersja debug pozwala na podpięcie się przez VNC i podglądanie na żywo jak skrypty sobie radzą (co robią, czasem na reakcję jeśli potrzeba),
- firefox bo można zmienić w prosty sposób User Agenta przeglądarki w tym obrazie (a będziemy udawać przeglądarkę mobilną).
Zatem instalujemy (jeśli nie mamy) Dockera, ściągamy odpowiedni obraz przez docker pull selenium/standalone-firefox-debug z konsoli Shella i uruchamiamy go (też z konsoli) poprzez:
docker run -d -P -p 4444:4444 -p 5900:5900 -v /dev/shm:/dev/shm selenium/standalone-firefox-debug
Na porcie 4444 Docker słucha nas, a na 5900 mamy dostęp po VNC. Po szczegóły odsyłam do rozsianych po sieci przykładów – ten post to nie instrukcja do Dockera.
W R będziemy potrzebować biblioteki RSelenium.
Aby dać like albo napisać komentarz potrzebujemy kilku rzeczy:
- być zalogowanym w Instagramie,
- wejść na stronę zdjęcia,
- kliknąć serduszko – aby dać lajka,
- wpisać komentarz – aby… dodać komentarz.
Zaczynamy zatem od punktu pierwszego.
Logowanie do Instagrama
Pierwsza rzecz to jednak uruchomienie przeglądarki w kontenerze Dockera:
# ustawienie user agenta na mobile - działa tylko w Firefoxie fprof <- makeFirefoxProfile(list(general.useragent.override = "Mozilla/5.0 (Android 4.4; Mobile; rv:41.0) Gecko/41.0 Firefox/41.0")) # przygotowujemy driver dla Selenium remDr <- remoteDriver( remoteServerAddr = "localhost", port = 4444L, extraCapabilities = fprof ) # chwilę czekamy, aby driver wystartował Sys.sleep(3) # 3 sekundy powinny wystarczyć # uruchamiamy przeglądarkę w ramach kontenera Dockera remDr$open() # znowu chwilę czekamy, aby przeglądarka wystartowała Sys.sleep(3)
W tym momencie warto połączyć się przez klienta VNC i zobaczyć co tam się dzieje na serwerku (w Dockerze). Żeby to wszystko działało warto mieć system Linuxowy, najlepiej na jakimś własnym serwerze. O przygotowaniu takiego serwera pisałem już kiedyś, ja używam serwera VPS z Webh.pl.
Zalogujmy się zatem do Instagrama:
insta_login <- "twój login do Instagrama"
insta_pass <- "twoje hasło do Instagrama"
# otwieramy stronę logowania
remDr$navigate("https://www.instagram.com/accounts/login/?source=auth_switcher")
# chwilę czekamy, aby się załadowała
Sys.sleep(5)
# w polu login wpisujemy login
webElem <- remDr$findElement(using = "name", "username")
webElem$sendKeysToElement(list(insta_login))
Sys.sleep(1)
# w polu hasło wpisujemy hasło i zatwierdzamy Enterem
webElem <- remDr$findElement(using = "name", "password")
webElem$sendKeysToElement(list(insta_pass, key = "enter"))
Sys.sleep(1)
# idziemy na stronę główną Instagrama
remDr$navigate("https://www.instagram.com/")
Lajkowanie
Uwaga – przy logowaniu możemy dostać jakieś komunikaty (widać je będzie w VNC, można z tego poziomu je kliknąć) albo i maile o próbie logowania z innego niż zazwyczaj adresu. Pierwszy raz albo i dwa to się zadzieje, ale po potwierdzeniu że to my się logujemy (np. z Chin) dalej już nie będzie takiej konieczności. Jest to nieco upierdliwe, ale to wynik dbania o bezpieczeństwo.
Jesteśmy zalogowani, aby dać lajka trzeba kliknąć w serduszko na stronie zdjęcia. Odpowiednia funkcja otworzy nam stronę zdjęcia (na podstawie ID postu), znajdzie element z serduszkiem i kliknie w niego:
add_like_to_photo <- function(post_id, remote_driver = remDr) {
# idziemy na stronę zdjęcia
remote_driver$navigate(paste0("https://www.instagram.com/p/", post_id, "/"))
# 3 sekundy oczekiwania aż strona się załaduje
Sys.sleep(3)
# dajemy lajka:
# 1. szukamy odpowiedniego elementu na stronie (po klasie CSS)
webElems <- remote_driver$findElements(using = "css", "button.dCJp8.afkep._0mzm-")
# 2. ustawiamy nad nim kursor myszy
remote_driver$mouseMoveToLocation(webElement = webElems[[1]])
# 3. i klikamy
remote_driver$click()
# czekamy chwilę, aż się zadzieje
Sys.sleep(2)
}
W zmiennej remDr mamy driver Selenium, zatem danie lajka zdjęciu o ID BvUAaQkFb9_(to moja fota, pozwalam spamować) sprowadza się do wywołania powyższej funkcji:
add_like_to_photo("BvUAaQkFb9_", remDr)
Komentowanie
Podobnie jest z komentarzem: wchodzimy na stronę postu, znajdujemy element na wpisanie komentarza (pole tekstowe), wpisujemy jego treść i zatwierdzamy Enterem:
add_comment_to_photo <- function(post_id, comment_text, remote_driver = remDr) {
# idziemy do zdjęcia
remote_driver$navigate(paste0("https://www.instagram.com/p/", post_id, "/"))
Sys.sleep(3) # 3 sekundy czekania
# dajemy komentarz:
# 1. szukamy pola na komentarz
webElem <- remote_driver$findElement(using = "css", "textarea")
# 2. wpisujemy komentarz i Enter na koniec
webElem$sendKeysToElement(list(comment_text, key = "enter"))
# czekamy chwilę, aż się zadzieje
Sys.sleep(2)
}
Wywołanie funkcji podobne do add_like_to_photo():
add_comment_to_photo("BvUAaQkFb9_", "Treśc komentarza", remDr)
W ten sposób możemy hurtem lajkować i komentować zdjęcia. Proces jest prosty:
- dla danego ID postu:
- wywołujemy add_like_to_photo(), aby post zalajkować,
- wywołujemy add_comment_to_photo() , aby post skomentować.
Możemy to puścić w pętli dla wszystkich zdjęć wybranych w jakiś sposób (po użytkowniku, tagu, dacie – cokolwiek). Uwaga – lepiej pomiędzy jednym a drugim lajkiem czy komentarzem dać rozsądną chwilę (5-10 sekund, najlepiej losowo) przerwy, aby Instagram nie zorientował się, że ma do czynienia z automatem. Hurtowe działanie w bardzo krótkim czasie nie jest mile widziane w tego typu serwisach i może powodować blokadę konta. Tak na przykład jest przy masowym dodawaniu i usuwaniu obserwowanych na Twitterze (przytrafiło mi się na bocie @IleRoku – swoją drogą, obserwujesz go już na Twitterze, prawda?).
Publikowanie zdjęć
To wyższa szkoła jazdy i szczerze mówiąc nie przeskoczyłem tego problemu. To dla dodawania zdjęć była potrzebna mobilna wersja przeglądarki (precyzyjniej: mobilny User Agent) – w wersji desktopowej nie ma guziczka do dodania zdjęcia (otwórz stronę Instagrama na komputerze i w przeglądarce na telefonie – widzisz różnicę?).
Dodanie zdjęcia z poziomu przeglądarki mobilnej sprowadza się do kliknięcia w odpowiedni przycisk na stronie, wybraniu zdjęcia i… tyle! Czyli powinno wystarczyć:
# wybieramy element "dodaj zdjęcie" webElem <- remDr$findElement(using = "xpath", '//*/span[@aria-label="New Post"]') # ustawiamy się na nim myszką remDr$mouseMoveToLocation(webElement = webElem) # klikamy remDr$click()
Tylko kiedy zobaczycie w VNC co się dzieje to pojawia się problem – otwiera się okno wyboru pliku. I jak z poziomu Selenium wybrać plik? Tutaj jest dobry przykład, ale na innym kodzie strony. W przykładzie tym w pole wyboru pliku można wpisać ścieżkę do pliku, ale w Instagramie nie ma takiego pola! By może ktoś znalazł rozwiązanie? Chętnie wszyscy dowiemy się z komentarza!
Na koniec możemy zamknąć stosownego Dockera – jeśli jest tylko jeden to wystarczy w shellu:
docker stop $(docker ps -q)
Jeśli Ci się podobało to podziel się wpisem ze światem (odpowiednie guziczki poniżej). Wpadnij też na Dane i Analizy na Facebooku – tam więcej takich smaczków (szczególnie dla praktyków). Nieco więcej smaczków znajdziesz też w nie-tak-bardzo cyklicznym newsletterze, którego archiwum tutaj (a na dole guzik do zapisania się na kolejne wydania).To tyle na temat obsługi Instagrama z poziomu języka R. Mam nadzieję, że przedstawione kody są na tyle czytelne, że z łatwością dasz radę przenieść je na przykład na Pythona (o ile potrzebujesz).
Artykuł został pierwotnie opublikowany na blog.prokulski.science. Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły
Podejście do zmniejszania kosztów przetwarzania danych na przykładzie Azure Databricks

Data management, data governance i data modernization - jak okiełznać proces zarządzania danymi w organizacji

Big Data - klęska urodzaju czy złoty Graal? Praktyczne metody wykorzystania potencjału danych
Dane 1,3 mln użytkowników Clubhouse do pobrania? To nie wyciek, to data scraping

Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Migracja do chmury? Wypełnij ankietę i sprawdź, jak wygląda ten proces u innych!

Analiza infrastruktury i danych IoT. Wybór bazy
