Infrastructure as Code. Czym jest biblioteka AWS CDK – wady i zalety

Niektóre firmy zatrudniają pracowników zajmujących się wyłącznie infrastrukturą, które wyklikują, konfigurują środowiska na jakich stawiane są systemy. Jednak teraz dzięki takim bibliotekom jak AWS CDK, programiści mogą napisać kod, który stworzy i skonfiguruje całe środowisko, na którym stanie ich system. Każda zmiana jest zapisana w historii repozytorium i przechodzi przez review reszty zespołu.
Kod, który można napisać w paru językach, tworzy szablon CloudFormation. Całą infrastrukturę można postawić za pomocą komend z terminala i także z łatwością ją usunąć. Warto wspomnieć, że kod można pisać za pomocą jednego z wybranych przez siebie języków, takich jak Python, TypeScript, JavaScript, C#, Java oraz niedługo Go.
Chciałabym opisać swoje wrażenia po korzystaniu z powyższej biblioteki po współtworzeniu przez parę miesięcy projektu Data Lake. Data Lake można w skrócie nazwać repozytorium danych, gdzie przechowuje się je w surowym i wybranym formacie.
Spis treści
Dlaczego AWS CDK?
AWS CDK z początku wydawała nam się biblioteką bardzo dobrze udokumentowaną i z wieloma przykładami. Nie wymagała przejmowania się przechowywaniem stanów deploymentów, jak przy Terraformie. Poza tym do niedawna tworzenie szablonów w Terraformie odbywało się tylko za pomocą HashiCorp Configuration Language (HCL). Wcześniej obawialiśmy się, że trudno będzie odwzorować nasz skomplikowany projekt.
Poniżej dodałam przykład kodu do stworzenia roli i nadawania jej uprawnień do czytania danych z bucketa. Kod wydaje się z mojej perspektywy dosyć przejrzysty i za pomocą komendy cdk synth byłam w stanie stworzyć szablon dla CloudFormation i podejrzeć, co ten kod generuje.
Kod AWS CDK
from aws_cdk import aws_iam, aws_s3, core
class MyStack(core.Stack):
def __init__(
self,
scope=None,
id=None,
**kwargs
):
super().__init__(scope=scope, id=id, **kwargs)
bucket_arn = "arn:aws:s3:::fooo"
user_arn = "arn:aws:iam::123456789:user/MyUser"
role = aws_iam.Role(
self,
"newRole",
role_name="newRole",
assumed_by=aws_iam.ArnPrincipal(user_arn)
)
foo_bucket_policy = aws_iam.Policy(
self,
"PolicyName",
statements=[
aws_iam.PolicyStatement(
actions=[
"s3:GetObject*",
"s3:GetBucket*",
"s3:List*"
],
effect=aws_iam.Effect.ALLOW,
resources=[
bucket_arn,
f"{bucket_arn}/*"
],
),
],
)
role.attach_inline_policy(foo_bucket_policy)
Wygenerowany schemat CloudFormation
Resources:
newRole3F295E4D:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Action: sts:AssumeRole
Effect: Allow
Principal:
AWS: arn:aws:iam::123456789:user/MyUser
Version: "2012-10-17"
RoleName: newRole
Metadata:
aws:cdk:path: my-stack/newRole/Resource
PolicyName2EBC7934:
Type: AWS::IAM::Policy
Properties:
PolicyDocument:
Statement:
- Action:
- s3:GetObject*
- s3:GetBucket*
- s3:List*
Effect: Allow
Resource:
- arn:aws:s3:::fooo
- arn:aws:s3:::fooo/*
Version: "2012-10-17"
PolicyName: PolicyName2EBC7934
Roles:
- Ref: newRole3F295E4D
Metadata:
aws:cdk:path: my-stack/PolicyName/Resource
Gdy mamy już kod infrastruktury i skonfigurowane zmienne środowiskowe naszego konta to za pomocą komendy cdk deploy mogliśmy wszystko stworzyć w chmurze.
Stworzyłam także przykład kodu tworzącego stacki. Stack pozwala w AWS rozdzielić zasoby według własnych upodobań. Poniższy kod pokazuje przykładowe przekazywanie zasobów między stackami. Ze stacku “MainStack” przekazuję do “ETLStack” rolę. Przy takiej operacji ważne jest także, by obsłużyć w kodzie, który stack ma się stworzyć jako pierwszy. Po to w konstruktorze stacka dodałam parameter depends_on_stacks który trzeba samodzielnie obsłużyć w kodzie.
app = core.App()
main_stack = DataLakeSetupStack(
app,
f"{PREFIX}-main",
env={"region": AWS_REGION},
)
ETLStack(
app,
f"{PREFIX}-etl",
stack_name=f"{PREFIX}-etl",
env={"region": AWS_REGION},
depends_on_stacks=[main_stack],
role=main_stack.datalake_role
)
app.synth()
W wygenerowanym pliku głównego stacka pojawił się eksport roli, którą później używam w kodzie stacka Etl.
"Export": {
"Name": "DL-FOO:ExportsOutputRefroleC7B7E775984233C4"
}
A tak wygląda wygenerowany import w drugim stacku.
"Roles": [
{
"Fn::ImportValue": "DL-main:ExportsOutputRefroleC7B7E775984233C4"
}
]
Samo przekazanie w parametrach konstruktora nie powoduje wyeksportowanie zasobu, musi on być użyty w danym stacku.
Jak korzystaliśmy z AWS CDK?
Nasz zespół składał się głównie z programistów Pythona, więc oczywistym wyborem było pisanie projektu w tym języku. Z początku kod rozdzielaliśmy po prostu według użytych modułów np. dotyczących uprawnień, tworzący job-y do przetwarzania danych. Wraz z rozwojem projektu skorzystaliśmy z możliwości rozdzielenia kodu na stacki. Najlogiczniej z naszej perspektywy było podzielić kod na stacki per źródła danych zewnętrznych. Czyli każde źródło danych miało osobny:
- workflow (kroki uruchamiane periodycznie lub na żądanie w celu przetworzenia danych),
- joby (skrypty przetwarzające dane do określonego formatu),
- buckety (foldery z danymi),
- tabele w Glue (metadane pozwalające odpytywać buckety za pomocą SQL).
Poza tym potrzebowaliśmy stack główny do konfiguracji VPC (wirtualnej sieci), w którym znajdowała się reszta stacków. Do tego doszła nam potrzeba wydzielenia stacka z monitoringiem, gdzie trzymaliśmy skonfigurowane metryki dla Cloudwatcha (repozytorium metryk dla różnych serwisów). Z czasem pojawiła się potrzeba stworzenia stacka z rolami oraz do trzymania kompatybilności wstecznej.
Dane otrzymywaliśmy do odpowiednich bucketów przez role, które udostępnialiśmy klientowi. On nadawał tym rolom uprawnienia do ściągania danych. Zdarzyło nam się przez przypadek usunąć role, przez co traciły uprawnienia. Na przykład przy reorganizacji kodu w stackach, rola była usuwana i tworzona na nowo. Dlatego stworzyliśmy jeden stack z rolami, z którego korzystały wszystkie branche i stacki. Nie dzieje się tam dużo, więc łatwiej nam pilnować, by role nie tworzyły się na nowo przy zmianach kodu.
Poniżej zamieściłam print-screen naszego projektu, jednak by nie zdradzać zbyt wiele pousuwałam foldery z nazwami źródeł danych i dałam dla przykładu “source_name”. Nie ujęłam w tej strukturze Dockera i plików konfiguracyjnych do kontrolowania jakości kodu, by skupić się tylko na omawianej bibliotece. Warto jednak podkreślić, że korzystaliśmy z mypy, flake, isort oraz black-a w naszym projekcie.
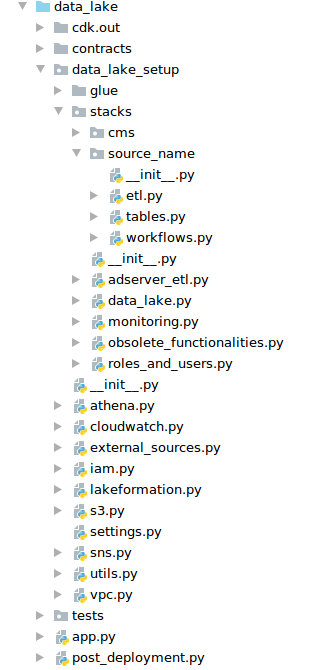
Dzięki podzieleniu kodu na stacki łatwiej się z nimi pracowało, np. nie musieliśmy przebudowywać całego projektu z powodu nowej roli.
Warto wspomnieć, że w naszej pracy korzystaliśmy z metodologii GitOps, każdy z programistów wraz z nowym branchem, by móc pracować stawiał swoją własną infrastrukturę. Były branche, które miały uprawnienia do ściągania danych, które nazwaliśmy data-access oraz master. Gdy ktoś potrzebował sprawdzić integrację z zewnętrznym źródłem, to korzystał z brancha data-access. Master oczywiście też wymagał posiadania uprawnień do danych, ponieważ to jest nasza produkcja.
Oczywiście jak każdy szanujący się programista pisaliśmy testy. Sprawdzały one szablon CloudFormation. Dzięki nim mieliśmy pewność, czy tworzone są odpowiednie zasoby przy odpowiednich stackach.
Jakie problemy napotkaliśmy?
- Jest mała część opcji jak na przykład niektóre ustawienia tabel Glue, który musieliśmy ustawić inną biblioteką po deploymencie CloudFormation. Używaliśmy do tego skryptu w boto (biblioteka do komunikacji z AWS za pomocą API),
- Są rzeczy, których nie da się ustawić przez metody AWS CDK i pewne parametry trzeba ręcznie wpisywać za pomocą metody override, by stworzony szablon był taki, jak wymaga CloudFormation,
- Gdy zasoby są tworzone przez nadpisywanie templatek, mogą się tworzyć w nieodpowiedniej kolejności (np. deployment najpierw będzie chciał nadać uprawnienia a potem stworzyć zasób do którego chce dać uprawnienia roli),
- Przy naszym podejściu każdy branch tworzył swoją własną infrastrukturę, więc trzeba było pilnować, by zasoby miały unikalne nazwy. Jeżeli dany zasób już istniał na koncie AWS to deployment rzucał błędem i nie tworzył dalej zasobów,
- Przy pracy wielu deweloperów i wielu deploymentów naszej infrastruktury nie raz napotkały nas ograniczenia AWS-owe. Na szczęście przy większości starczy przez panel wyklikać prośbę o zwiększenie limitów i poczekać na zatwierdzenie. Niestety czasem trzeba podać uzasadnienie swojej prośby i to trwa, a deployment nowych zasobów jest zablokowany,
- W teorii z łatwością stworzona infrastruktura powinna się usunąć za pomocą jednej komendy, jednak przy niektórych zasobach nie jest to tak proste, jak np. przy bucketach z plikami. Najpierw trzeba usunąć zawartość, inaczej będziemy mieli błędy o nieudanej próbie usunięcia,
- Stworzyliśmy rolę dla klienta, przez które on wrzucał nam pliki, jednak zdarzało się, że na masterze rola została usunięta i postawiona na nowo, przez co traciła uprawnienia, które nadał jej klient,
- Przeniesienie zasobu do innego stacku powoduje usunięcie go (dlatego postanowiliśmy stworzyć osobny stack dla roli),
- Gdy ktoś coś wyklika może zepsuć deployment branchy – np. dodanie admina do Data Lake, który później jest usunięty przez usunięcie stacka, powoduje błędy przy innych deploymentach (fizycznie nie istnieje, ale jest na liście adminów),
- Musieliśmy stworzyć skrypt do usuwania deploymentów z branchy nocą, przez ogrom zasobów jakie tworzyliśmy (nie każdy programista pamiętał, by sprzątać po sobie),
- Mała dokumentacja do pewnych części lub jej brak jak np. przykłady jak postawić bazę Neptune. O wiele lepiej udokumentowana jest część AWS CDK w JavaScriptcie i czasem wzorowaliśmy się na niej zamiast na Pythonowej, by dojść do tego, jak coś napisać,
- Wiele osób w zespole miała pierwszy raz tak bliską styczność z AWS. Najpierw musieliśmy zrozumieć, że wszędzie potrzebne są uprawnienia, bo błędy jakie pojawiały się przy stawiania środowiska nie zawsze były oczywiste. Z czasem wyrobiliśmy sobie nawyk, że jak coś nie działało to najpierw trzeba sprawdzić “permissiony”,
- Przy naszym podejściu każdy mógł stworzyć swoją własną infrastrukturą i nie przejmować kompatybilnością, ponieważ jego deployment był często usuwany i stawiany na nowo. Jednak przy zmergowaniu z branchem mastera, który pracował cały czas trzeba było mieć na uwadze, że coś może się sypnąć.
Podsumowanie
Biblioteka AWS CDK jest banalna przy tworzeniu prostych rzeczy. Jednak, gdy programista zagłębia się w jej czeluściach, zaczyna widzieć braki w swojej wiedzy. Wyklikanie czegoś w konsoli AWS wydaje się trywialne, jednak, gdy ma stworzyć kod, który tworzy daną funkcjonalność to pojawiają się schody. Trzeba poznać jak coś działa, by wiedzieć jakich komponentów wymaga, by to napisać. Na pewno jest to świetna okazja dla rozszerzenia swojej wiedzy.
Świetny tutorial wprowadzający pokazuje zalety tej biblioteki. Niestety są jeszcze zasoby, których nie stworzymy ze wszystkimi parametrami. Biblioteka bardzo szybko się rozwija i często ją aktualizujemy w naszym projekcie. Mamy więc nadzieję, że z czasem będzie bez ‘dziur’. Prostota stawiania i zmieniania infrastruktury na pewno powinna zachęcić każdego, kto ma infrastrukturę opartą na usługach AWS. My z chmury AWS korzystamy już od wielu lat, jesteśmy nawet jej partnerami, dlatego kierunek ten był dla nas naturalny.
Polecam ten tutorial oraz zapoznanie się z dokumentacją.
Zdjęcie główne artykułu pochodzi z unsplash.com.

Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
