Historia metodyki DevOps. Założenia i przełomy w jej rozwoju

DevOps jako metodyka z obszaru inżynierii oprogramowania uzyskała w ostatniej dekadzie opinię najnowocześniejszego podejścia do tematu produkcji i utrzymania systemów informatycznych. Niniejszy artykuł jest pomyślany jako wstęp opisujący tę metodykę – opisuje jej zasady, ale również proces, który doprowadził do powstania DevOps. Niebawem opublikujemy jeszcze dwie części artykułu.
Spis treści
Historia, czyli jak do tego doszło
Trudno wskazać jeden moment, kiedy temat procesu produkcji oprogramowania pojawił się jako samodzielny przedmiot analiz i opracowań. W końcówce lat sześćdziesiątych i później w latach siedemdziesiątych istniały już systemy o na tyle dużej skali i ważności, że sama kwestia ich wytworzenia funkcjonowała jako przedmiot badań. Właśnie po analizach bazy danych dot. efektów prac przy wytwarzaniu oprogramowania, zaczęto mówić o tzw. “kryzysie w produkcji oprogramowania” (ang. software crisis).
Kryzys powszechnie wiązano z rosnącą złożonością rozwiązań sprzętowych, jak i oprogramowania. Obie te rzeczy były oczywiście prostymi konsekwencjami z jednej strony rozwoju technologicznego, a z drugiej rosnących oczekiwań użytkowników napędzanych możliwościami dawanymi przez rozwiązania sprzętowe. Objawami tego kryzysu były problemy z realizacją projektów informatycznych takie jak: notoryczne przekraczanie budżetów i niedotrzymywanie terminów realizacji, błędne realizowanie wymagań klientów.
Jednym z najważniejszych problemów była też słaba jakość oprogramowania, co najczęściej skutkowało dużymi trudnościami w utrzymywaniu stabilnego działania systemów informatycznych udostępnianych użytkownikom.
W związku z dużym skokiem rozpowszechnienia systemów informatycznych, które nastąpiło szczególnie w latach osiemdziesiątych, problem ten stawał się coraz bardziej palący. Przez dwie ostatnie dekady dwudziestego wieku trwały poszukiwania jego rozwiązania. Prowadziły one praktycznie zawsze do opracowywania nowych metodyk zarządzania rozwiązaniami informatycznymi (nie chodziło tu wyłącznie o wytwarzanie oprogramowania, ale również o szeroko rozumiane udostępnianie usług informatycznych) bądź adaptowania gotowych metodyk funkcjonujących w innych obszarach przemysłu.
Lata osiemdziesiąte i częściowo dziewięćdziesiąte pod względem różnorodności i braku standardów w procesach produkcji oprogramowania nie różniły się znacząco od sytuacji mającej wtedy miejsce na rynku mikrokomputerów. Każda firma miała własne rozwiązania, najczęściej niekompatybilne z innymi. Z czasem z tych chaotycznych poszukiwań zaczęły wyłaniać się rozwiązania, które dzięki swoim zaletom, a w konsekwencji rozpowszechnieniu, stawały się de facto standardami. Często były przekształcane w formalne standardy przez powołane do tego instytucje.
Warto tutaj wymienić kilka rozpowszechnionych rozwiązań powstałych w tym okresie.
- RUP (ang. Rational Unified Process) – opracowany w drugiej połowie lat dziewięćdziesiątych przez firmę Rational Software Corporation przejętą później przez IBM. Metodyka oparta była na iteracyjnym modelu wytwarzaniu oprogramowania i cechowała się dużymi możliwościami dostosowania do warunków konkretnego projektu i przedsiębiorstwa. Była również wspierana przez opracowany przez tę firmę pakiet oprogramowania. Z metodyki RUP wyewoluował później Open Unified Process rozwijany przez fundację Eclipse.
- Prince2 (ang. Projects in Controlled Environments) – ogólna metodyka zarządzania projektami opracowana na zamówienie brytyjskiego rządu. Przeznaczona do zarządzania w zasadzie dowolnym rodzajem projektu, nie wyłącznie projektami informatycznymi. Funkcjonuje do dnia dzisiejszego w praktycznych zastosowaniach poza-informatycznych. Cechuje się dużym stopniem formalizacji przy jednoczesnych dużych możliwościach dostosowania do konkretnych warunków projektowych. Ze względu na swój charakter, w projektach informatycznych preferuje model kaskadowy produkcji oprogramowania (ang. waterfall model).
- XP (ang. Extreme Programming) – metodyka produkcji oprogramowania oparta na zupełnie innych założeniach niż dwie wyżej wymienione. Opracowana około połowy lat dziewięćdziesiątych stawiała nacisk na zupełnie inne aspekty realizacyjne niż dwie wyżej wymienione metodyki. Dużo mniejszy nacisk kładziono na planowanie i kontrolę procesu, natomiast dużo większy na jego iteracyjność i kontakt z klientem. Choć metodyka ta miała swoje wady i niezwykłe cechy (przykładowo, jej charakterystycznym wymogiem była zasada programowania parami), stanowiła jedną z “pierwszych jaskółek” nadchodzącego przełomu w podejściu do produkcji oprogramowania.
- ITIIL (ang. Information Technology Infrastructure Library) – biblioteka dobrych praktyk zarządzania infrastrukturą informatyczną. Pierwsze, mające inne nazwy, wersje opracowano w latach osiemdziesiątych na zamówienie rządu brytyjskiego. Rozwijane intensywnie w wersji drugiej i trzeciej w pierwszej dekadzie lat dwutysięcznych. Funkcjonuje jako najbardziej rozpowszechniony praktyczny standard realizacji usług informatycznych. Nie koncentruje się na wytwarzaniu oprogramowania, lecz właśnie na przygotowywaniu, uzgodnieniu z klientem, wdrażaniu, świadczeniu i rozliczaniu usług informatycznych. Częstym nieporozumieniem jest traktowanie ITIL jako metodyki, podczas gdy jest ona opartą na zgromadzonych doświadczeniach biblioteką dobrych praktyk – więc z samego założenia; należy z niej wybierać konkretne elementy do zastosowania.
Stosowanie wyżej wymienionych oraz innych mniej znanych metodyk do uporządkowania i kontrolowania procesu produkcji oprogramowania, doprowadziło do zmniejszenia skali większości problemów przy realizacji projektów informatycznych. Jednocześnie doprowadziło to do nasilenia niektórych specyficznych klas problemów, z których wymienić należy:
- Znaczący wzrost komplikacji i zbiurokratyzowania projektów informatycznych charakterystyczny szczególnie dla projektów realizowanych zgodnie z RUP, PRINCE2 bądź metodykami na nich opartymi. Pociągało to za sobą wzrost kosztów administracyjnych przy realizacji oprogramowania, a tym samym spadek efektywności takich projektów.
- Wzrost ryzyk związanych z terminami, skalą zmian i innymi konsekwencjami braku szerszej perspektywy w projektach realizowanych zgodnie z metodyką XP.
- Częste stosowanie “lekarstwa” na problemy etapu realizacji oprogramowania w postaci przenoszenia czaso- lub pracochłonnych działań na inne etapy życia systemów informatycznych, co wiązało się z powstawaniem tzw. “długu technologicznego”
Dług technologiczny to kumulująca się grupa zmian, usprawnień, poprawek niekoniecznych w krótkiej perspektywie, a więc stale odkładanych na później. Jednak w pewnym momencie bez ich realizacji dalsze realizowanie prac projektowych staje się niemożliwe albo bardzo utrudnione. Bardzo dobrą ilustracją tego pojęcia jest rosnący stos naczyń odkładanych do umycia na później – zobacz].
Z tych i innych powodów, pojęcie kryzysu oprogramowania wcale nie wyszło z użycia nawet w momencie, gdy świat informatyczny usilnie pracował nad wyeliminowaniem domniemanego ryzyka wystąpienia zabójczych konsekwencji objawienia się “pluskwy milenijnej”.
DevOps a metodyki zwinne
Większy przełom przyszedł dopiero kilka lat później wraz z pojawieniem się metodyk zwinnych (ang. agile software development). Pierwsze próby stosowania elastycznego podejścia do produkcji oprogramowania miały miejsce relatywnie wcześnie (można nawet o nich mówić w latach sześćdziesiątych). W latach dziewięćdziesiątych opisana wyżej metodyka XP stała się jednym z szeroko rozpowszechnionych podejść do produkcji oprogramowania – obecnie jest ona uznawana za jeden z typów podejścia zwinnego.
Dopiero jednak po roku dwutysięcznym powstały całościowe rozwiązania oparte na pojęciu “zwinności” w produkcji oprogramowania, co łącznie z kolejnymi dowodami na skuteczność tych rozwiązań przyczyniło się do ich rozpowszechnienia. Intensywna ewolucja zasad programowania zwinnego trwała całą pierwszą dekadę lat dwutysięcznych (choć można też powiedzieć, że wciąż trwa) i zaowocowała wydaniem “Manifestu Programowania Zwinnego” zawierającego dwanaście zasad zwinnego tworzenia oprogramowania.
Należy dodać, że zasady te miały charakter przewrotu o charakterze niemalże kopernikańskim w stosunku do założeń, na jakich zbudowane były projekty realizowana we wcześniejszych latach. Jako przykład można choćby podać zasadę: “Bądźcie gotowi na zmiany wymagań nawet na późnym etapie jego rozwoju.”
Metodyki zwinne, w szczególności najpowszechniejsze z nich, czyli Scrum i Kanban, przyczyniły się do odejścia w przeszłość wszechobecnych problemów z produkcją oprogramowania identyfikowanych z “kryzysem oprogramowania”, o którym mowa na początku. Oczywiście opisane tam problemy nadal występowały i występują (niestety, wciąż częściej niż w innych dziedzinach przemysłu), ale stopień ich rozpowszechnienia zdecydowanie zmalał.
Z drugiej strony, wzrost ogólnej efektywności procesu produkcji oprogramowania uwidocznił negatywny wpływ tych jego elementów, które nadal niedomagały – głównie dlatego, że nie zostały w żaden sposób uwzględnione w zmianach wprowadzonych przez dotychczas opracowane metodyki zwinne. Problem długu technologicznego wcale nie został całkowicie rozwiązany – co więcej, w niektórych przypadkach stał się bardziej palący, szczególnie gdy w parze ze zwinnością w realizacji wymagań klienta nie szła zdolność przewidywania i planowania architektury tak, aby była ona użyteczna również w dalszej perspektywie.
Szczególnie zauważalne stały się w tej sytuacji konsekwencje ustalonych historycznie zasad współpracy między działami rozwoju a działami operacji IT i istniejącego od zawsze, we wszystkich organizacjach IT, wewnętrznego konfliktu interesów między tymi jednostkami. Był to temat praktycznie pomijany przez pierwsze metodyki zwinne. I to właśnie prace nad eliminacją problemów w tej współpracy doprowadziły do powstania metodyki DevOps.
Definicja, czyli o czym tak naprawdę mówimy
Nieusuwalny, wydawałoby się, konflikt między działem rozwoju oprogramowania a działem operacji IT ma swoje źródło w samym charakterze i wymogach stawianym tym dwóm grupom specjalistów.
Od zespołów pracujących przy wytwarzaniu oprogramowania (lub jego zmianach) wymaga się szybkiego realizowania wymagań klienta, dostosowywania rozwiązań do zmieniających się warunków zarówno biznesowych jak i technicznych. Jednym słowem – oczekuje się realizacji zmian w przewidywalnych, najczęściej krótkich terminach.
Od zespołów pracujących w dziale operacji IT (przy utrzymywaniu działającego “produkcyjnie” oprogramowania i wdrażaniu jego nowych wersji) wymaga się przede wszystkim zapewnienia stabilności i wydajności systemu udostępnianego użytkownikom. Idealny z punktu widzenia użytkowników system powinien cechować się stuprocentową dostępnością oraz zerową ilością występujących błędów. Z tego punktu widzenia każde wdrożenie jakiejkolwiek zmiany (nieważne, czy jest to poprawka błędu, czy nowa wersja oprogramowania) to dodatkowy czynnik ryzyka wystąpienia błędów oraz w zależności od architektury, konieczność odcięcia użytkowników od dostępu do systemu na czas wdrażania zmiany.
Opisane wyżej sprzeczne interesy tych dwóch grup wraz z rozpowszechnioną praktyką częstego stosowania tworzenia długu technologicznego jako lekarstwa mającego na celu ich pogodzenie prowadzą do czegoś, co można nazwać spiralą śmierci projektu informatycznego. Składa się ona z cyklu trzech następujących po sobie zjawisk zaprezentowanych na rysunku poniżej:
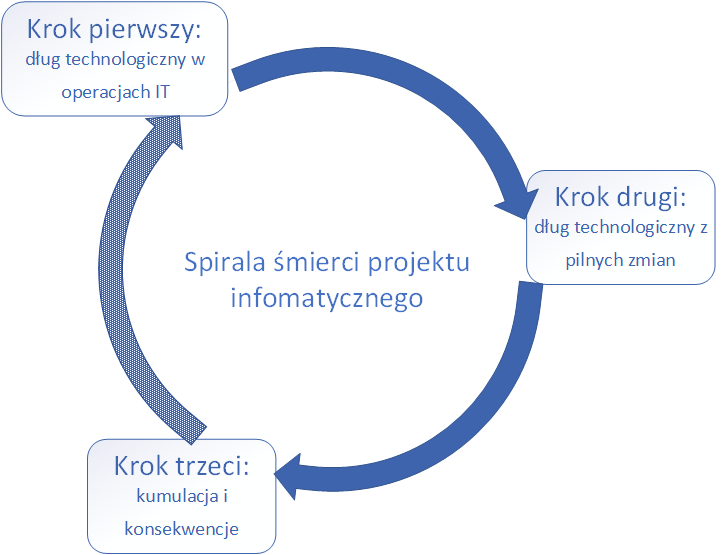
Krok pierwszy to zaciąganie długu technologicznego przez dział operacji IT, który nie może na czas obsłużyć wszystkich stawianych mu zadań. Rozwiązuje ten problem, tworząc dług technologiczny np. poprzez tworzenie tymczasowych, nieoptymalnych rozwiązań infrastrukturalnych, braki w dokumentacji, zabezpieczeniach itp. Efektem jest bardziej skomplikowana i trudniejsza do utrzymania infrastruktura. Z tym w parze idzie jej większa awaryjność.
Dług technologiczny w dziale operacji IT nie bez przyczyny jest definiowany jako krok pierwszy, ponieważ z badań i doświadczenia projektowego wynika, że to on najczęściej inicjuje proces wpadania w spiralę śmierci. Przyczyny, dlaczego dział operacji jest bardziej podatny na to zjawisko, zostaną do pewnego stopnia naświetlone w dalszej części artykułu.
Krok drugi zdarza się w momencie, gdy od klienta przychodzi zamówienie na pilną zmianę (tzw. “wrzutka”), której nie da się zgodnie ze sztuką zrealizować w oczekiwanym przez klienta czasie, ale jednocześnie z jakichś (zwykle pozamerytorycznych) powodów nie można jej odrzucić. Może być to np. rodzaj rekompensaty dla klienta za wcześniejsze kłopoty, bądź presja działów biznesowych. Prowadzi to do realizacji zmiany w sposób generujący dług technologiczny tym razem w obszarze samej aplikacji. Najczęściej “oszędność” sprowadza się do zaniechania testów, nietworzenia dokumentacji, skrócenia czasu na prace architektoniczne.
W kroku trzecim organizacja musi zmierzyć się z konsekwencjami dwóch poprzednich kroków. W związku z pogorszoną jakością zarówno infrastruktury, jak i samego oprogramowania podlegającego rozwojowi i utrzymaniu, zaczynają się pojawiać nowe problemy. Trudniej jest wprowadzać zmiany, są one obarczone większym ryzykiem, pojawia się więcej błędów produkcyjnych, pozyskiwanie wiedzy od jej depozytariuszy staje się bardziej czasochłonne. Wszystko to razem prowadzi do tego, że zespół realizacyjny i zespół operacji IT zużywają coraz większy procent swojego czasu na uzgodnienia i działania naprawcze. Oczywiście wpływa to natychmiast na pracę zespołu operacji IT w sposób opisany w kroku pierwszym spirali śmierci – inicjując kolejny obieg spirali z większym już tym razem natężeniem problemów.
Z czasem, po pewnej liczbie obrotów takiej spirali, powszechną praktyką stają się “gaszenie pożarów”, “procedury obejściowe”, “zaślepianie wyjątków”, “panic development”, “heroiczne wdrożenia”. Wiedza na temat wytwarzanego rozwiązania informatycznego staje się w coraz większym stopniu wiedzą tajemną i rozwiązanie nawet prostych problemów z systemem wymaga zaangażowania wielu różnych specjalistów – nie tylko “po prostu” posiadających wiedzę z danej dziedziny, ale znających dany system od podszewki.
W takiej sytuacji nikt już nie myśli o realizowaniu tematów, z których składa się dług technologiczny. Pozostaje tylko walka o utrzymanie jako-takiego funkcjonowania systemu.
Ale prawdziwe problemy dla firmy zaczynają się, gdy niektóre kluczowe z perspektywy projektu osoby powiedzą “mam dość, odchodzę”…
Każda z osób pracujących jakiś czas w IT, może sypnąć jak z rękawa opowieściami ilustrującymi opisany wyżej mechanizm. Autor artykułu też pamięta ze swojego doświadczenia historie o fizycznym niewypuszczaniu administratorów z firmy (bo co to jest 16 godzin w pracy – są teraz potrzebni!), o pracownikach pracujących pięć weekendów pod rząd (cóż z tego, że płatnych), o pracownikach śpiących pod biurkiem czy w szafie, o 48-godzinnych maratonach programistyczno-wdrożeniowych, czy wdrożeniach wykonywanych z autobusu jadącego na wyjazd integracyjny.
DevOps – inspiracja i powstanie
Właśnie świadomość istnienia i relatywnej powszechności opisanego w poprzednim rozdziale mechanizmu doprowadziła osoby zajmujące się metodykami zwinnymi (bo to właśnie w tych gremiach pod koniec pierwszej dekady pojawiła się idea objęcia “zwinnością” również operacji) do zajęcia się tematem współpracy obszarów rozwoju i operacji IT.
Nie obyło się jednak tak zupełnie bez inspiracji poza-informatycznych.
Inspiracją tą była metodyka Lean (nie ma dobrego polskiego tłumaczenia, najczęściej tłumaczy się ją jako “szczupłe zarządzanie”). Metodyka ta nie pochodzi z obszaru IT i w czasach, kiedy powstała w zasadzie nie była w nim używana. Od czasu jej wynalezienia w Japonii w dekadach po drugiej wojnie światowej, jej zastosowanie w przemyśle motoryzacyjnym, przyniosło zwiększenie efektywności produkcji, przekładające się na znaczące skrócenie czas realizacji zlecenia (niektóre badania mówią o około dwukrotnym) i bardzo znaczące zmniejszenie ilości nieterminowo realizowanych zleceń (mowa o przypadkach nawet sześciokrotnego).
Z czasem, gdy metodyka ta stała się powszechna w przemyśle i udowodniono, że jej stosowanie przyczynia się do wszechstronnej poprawy parametrów procesu produkcyjnego, idee przez nią promowane przyczyniły się również do ewolucji podejścia do tworzenia oprogramowania. Podejścia, które z niej czerpią to oczywiście metodyki zwinne (ang. Agile), a w szczególności DevOps.
Nawet pobieżne omówienie głównych tematów metodyki Lean dalece wykracza poza ramy tego artykułu, w związku z tym zaprezentuję tylko jedno z kluczowych dla niej pojęć, które ma równie duże znaczenie w DevOps i którego zastosowanie odróżnia tę metodykę od “niezwinnych” metodyk produkcji oprogramowania opisanych wcześniej w tym artykule.
Centralną koncepcją metodyki Lean bezpośrednio zapożyczoną przez DevOps jest pojęcie “strumień wartości” (ang. value stream), który w przypadku DevOps nazywany jest najczęściej “strumieniem wartości technologii”.
Formalna definicja tego pojęcia w metodyce Lean jest następująca: “strumień wartości to sekwencja działań podejmowanych przez organizację w celu realizacji zamówienia klienta (dostarczenia mu wartości)”. DevOps stosuje definicję opisującą specyficzny przypadek strumienia wartości – dla oprogramowania. Zwykle jest ona następująca: “strumień wartości technologii jest to zbiór czynności niezbędnych do przekształcenia założeń biznesowych w korzystającą z technologii IT usługę, która dostarcza wartości dla klienta”.
Pojęcie to jest kluczowe dla DevOps dlatego, że metodyka ta stawia sobie za cel zwiększanie “efektywności przepływu” tego strumienia wartości. W przypadku tej metodyki miarą sukcesu realizacji zleceń klienta jest to, w jakim stopniu sprawnie i bez przeszkód/opóźnień strumień ten przepływa od początku do końca procesu produkcji. Innymi słowy, DevOps zawiera rekomendacje, jak sprawić by wszystkie czynności związane z produkcją i udostępnianiem rozwiązania IT klientowi przebiegały sprawnie i bez opóźnień.
Aby zrozumieć szczegóły pojęcia strumienia wartości i cechy, jakie powinien on posiadać, żeby realizacja prac przezeń opisanych mogła być uznana za sukces najłatwiej posłużyć się przykładami z “materialnej” produkcji przemysłowej. Później poprzez analogię możliwa jest analiza sytuacji dla produkcji oprogramowania.
Przykładowo, w fabryce części do samochodów strumień wartości rozpoczyna się od otrzymania zamówienia klienta i dostarczenia półproduktów do miejsca produkcji (czyli hali produkcyjnej). Zaś kończy się, gdy gotowe elementy są dostarczane do lokalizacji klienta, bo dopiero wtedy zaczynają stanowić dla niego realną wartość (mogą być użyte do produkcji samochodu). Z punktu widzenia klienta ważne są oczywiście trzy standardowe aspekty wykonania zamówienia:
- Czas jego realizacji.
- Koszt jego realizacji.
- Jakość dostarczonych elementów.
Elementy te przekładają się na podane niżej przykładowe pożądane cechy procesu produkcji – tym razem z punktu widzenia wykonawcy:
- Czas:
- wykonawca chce unikać długiego czasu oczekiwania między złożeniem zamówienia a rozpoczęciem jego realizacji – mówiąc krótko, kolejkowania całości prac ze względu na konieczność zakończenia wcześniejszych prac,
- wykonawca chce unikać przestojów również w procesie realizacji samego zamówienia,
- z punktu widzenia zadowolenia klienta z czasu realizacji zwykle lepiej jest zacząć dostarczać mniejsze partie szybciej i równomiernym strumieniem niż dostarczyć całość na raz po długim czasie oczekiwania.
- Koszt:
- wykonawca chce unikać długiego (a najlepiej jakiegokolwiek) składowania materiałów, półproduktów, jak i gotowych produktów w magazynach – bo to generuje dodatkowe koszty składowania i zamrożonego kapitału,
- wykonawca chce unikać długotrwałych (a najlepiej jakichkolwiek) bezczynności różnych elementów procesu produkcji, bo nieużywana infrastruktura generuje koszty, a nie przynosi zysku.
- Jakość:
- wykonawca woli, żeby wady produkowanych elementów wykrywane były na możliwie wczesnych etapach produkcji, bo to umożliwia szybsze i tańsze ich wyeliminowanie,
- jeśli zdarza się poważna awaria na jakimś etapie produkcji, zwykle lepiej przeznaczyć na krótko wszystkie siły na jej rozwiązanie, niż przez zaniedbanie problemu doprowadzić do zakłóceń w całym procesie,
- najgorszym scenariuszem dla wykonawcy jest ujawnienie się wad dopiero w momencie gdy cała partia produktów została dostarczona klientowi.
W oczywisty sposób punkty wymienione powyżej nie odnoszą się wyłącznie do wspomnianego wyżej przykładu części samochodowych, ani nawet wyłącznie do produkcji przemysłowej – można łatwo zauważyć, że są równie ważne także w produkcji oprogramowania.
Zarówno metodyka Lean, jak i metodyki zwinne (w tym DevOps) rekomendują, aby opisane wyżej wymogi w stosunku do procesu produkcji realizować poprzez pracę z małymi partiami materiału (rozmiarami zmian w przypadku oprogramowania) oraz dbać przede wszystkim o płynność procesu produkcji jako całości, co jest ważniejsze od koncentrowania się na efektywności jego pojedynczych elementów. Dla zapewnienia jakości ważne jest też jak najszybsze propagowanie informacji zwrotnej o wszystkich ewentualnych problemach (bądź o ich braku) z późniejszych etapów procesu produkcji do tych wcześniejszych.
Analizy oparte na opisanych wyżej BARDZO skrótowo cechach procesu produkcji doprowadziły do sformułowania trzech tzw. “dróg DevOps”, czyli zbiorów zasad, z których wywodzą się wszystkie rekomendowane przez tę metodykę praktyki.
–
W kolejnych częściach artykułu zostanie przedstawiony szczegółowy opis wspomnianych wyżej zasad składających się na „trzy drogi DevOps” oraz ogólny opis technicznego aspektu DevOps i wspierających go narzędzi. Na zakończenie Autor opisze także skrótowo funkcjonowanie DevOps w organizacji oraz omówi kilka rozpowszechnionych mitów na temat DevOps.
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Auto DevOps z GitLab. Rozszerzone funkcje GitLab 11

Buddy, czyli nie taki DevOps straszny, jak go malują

Ciemna strona mikroserwisów
