Escape from Merge Hell: Why I Prefer Trunk-Based Development Over Feature Branching and GitFlow

Czy kiedykolwiek patrzyłeś na proces developmentu i myślałeś „Musi być lepszy sposób”? Jeszcze półtora roku temu też tak myślałem. Wraz z moim zespołem od ponad roku niemal codziennie odkrywamy kolejne zalety pracy z Trunk-Based Developmentem, tak jak zespoły Facebooka i Google’a. O nim w tym artykule.
Jakie zalety niesie ze sobą Trunk-Based Development oraz jak zaimplementować go w waszych projektach? Na to pytanie postaram się odpowiedzieć. Poniższą treść przygotowałem w języku angielskim.
Spis treści
Feature Branch Development (aka GitFlow)
Before we start detailing the rules of Trunk-Based Development, let’s take a look at its counterpart: Feature Branch Development, also known as the GitFlow model.
The classical approach to the development of a product is to create a new branch for every feature we take care of and maintain this branch until we can merge it with the mainline.
In the meantime, we must check out to a hotfix branch, resolve merge conflicts, remember about our branches, etc.
The Feature Branch Development workflow is illustrated below.
Source: fpy.cz
One-way ticket to merge hell
What you see above is an example flow of just one developer’s work. Could you image how many branches we would have if our company grew to 100 developers? And what would happen if the number of teams grew to 100?
There would probably be continuous merging development. And any merges often would end with conflicts. In other words, you’d be facing merge hell. No one likes a merge conflict. When it occurs, one needs to focus both on his/her part of the code as well as the code of another developer.
Trunk-Based Development
There is a rescue for merge hell. But changes can take some time. Trunk-Based Development rejects any feature branches, hotfix branches, parallel release branches. There is only one branch available to the developers—the Trunk.
This new approach depends on four simple rules:
1. There is one branch called the “trunk” where developers directly commit,
2. A release manager can create release branches and no one can commit to those,
3. Developers commit small changes as often as they can,
4. Commits should be reviewed and tested and must not destroy the mainline.
Please take a look at the picture below. Developers perform commits, as many as they can, on the “trunk” branch. Every commit is a small part of the code, e.g. one function or method with unit tests (green squares).
At some point, when the trunk branch contains every feature that we want, one person creates a new release branch from the trunk. Such a person is called the release manager or the release engineer.

Source: paulhammant.com
Typical cases in a developer’s work
In our job, there are some typical cases such as:
- planning a new feature,
- creating a new feature,
- fixing a bug in production,
- code review,
- testing,
- merging/resolving conflicts,
- and drinking coffee
Let’s take a closer look at all of these in the context of Trunk-Based Development.
Planning a new feature
In my opinion, this case is the most important part of our work as developers. Before we start coding, we should consider how this feature will affect the other modules in our system. We should estimate how complex this task is and what we need to complete it (information, knowledge, testing cases or other resources). At my planning meetings I always ask:
- Can we split this story/feature into smaller tasks?
- Can we develop this story/feature parallel to the team?
- What do we have to write to complete every smaller task in this feature?
Answering these questions helps to visualize in my mind how the code for a feature would look like (classes, objects, functions etc). All my teammates have an idea of what is going to happen in my task as well.
Information sharing is one of the keys to future success and fast code reviews (keep in mind that you will commit as often as you can). You review only the code, not its usage, context or the architecture of the solution.
The planning session is extremely important in Trunk-Based Development. It helps to coordinate work, allows information sharing and it is a great introduction to fast code reviews.
Creating a new feature
After planning, our board should be filled with tasks. They should be quite small and provide a good description of new features. Now, we must remember that every piece of code we write should be well-tested, which is a great opportunity to introduce TDD in your work.
There is one core rule in this process—deploy a new commit to trunk every day. This helps us in two ways:
- it serves as a symbol of progress
- it prevents any possible merge conflicts
So let us try to imagine a typical developer’s day when using the Trunk-Based Development approach.
In the morning, the first thing will be fetching from the origin/trunk and creating a branch locally (creating it is not obligatory, it depends on your Continuous Integration and review process). Now we should consider how to create a commit, as small as possible, which contains a working part of a feature.
Also, keep in mind that no commit can break the mainline (the trunk branch). From every point of history, a release manager should be able to create a release branch. To ensure that, we cannot deliver any code of an unfinished feature and allow a user to enter it.
I propose two clever techniques which can help deal with these problems: branch by abstractionand feature flag.
Branch by abstraction
This technique is extremely useful when a developer must replace components. Let us imagine that in our system we have a Memcached instance as a cache manager. Everything goes well, more and more clients (interfaces) have used the cache and today we have a situation like in the picture below.
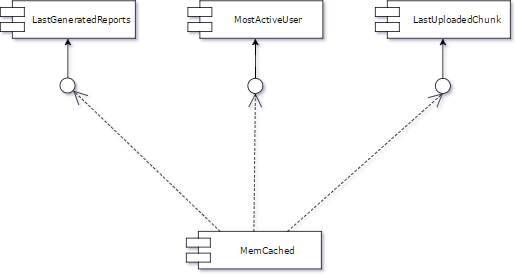
We have only 3 components which depend on Memcached in our system, but in reality, it is possible that the number of components will be huge. The first step is to create an abstraction layer between one client (e.g. LastUploadedChunk) and Memcached (please remember that in everyday committing we must not break the trunk). The current situation is illustrated in the picture below.
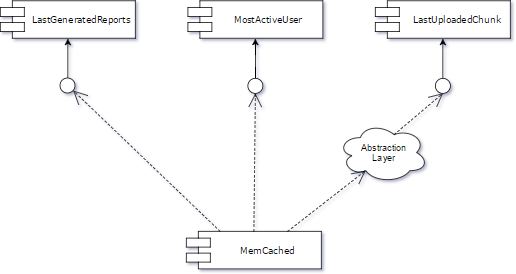
If our trunk is still okay, we can go a step further and move all clients to the abstraction layer. As we do so, we have the opportunity to improve the unit test coverage of our code by implementing tests between the clients and the abstraction layer.
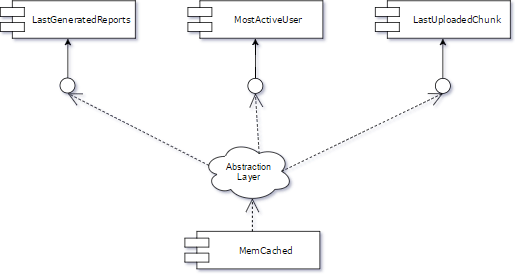
Now we can select one of the clients and start working on the new cache feature. We will still use the same abstraction layer, but in two ways.
First, for the chosen client we develop the new feature and, at the same time, the rest of the clients are supported by the old component (Memcached). In this way, we will still have the trunk working for our client with no difference, ready for a release, but we will be able to develop the new feature.
The main question is how to create a route which is enabled only for development. We can use a simple “if” statement or something more elegant, such as a feature flag (more information about this technique in next section).
In the picture below, we have chosen the “LastGeneratedReports” component for development.

After this most complicated step (I mean creating the new feature and connecting it with one client), we have the well-written component ready to work with Redis.
So the next obvious step will be removing the temporary route (implemented through an “if” statement or a “feature flag”) and connecting Redis with the rest of the clients.
Again, remember that the key point is doing as small commits as possible—the perfect way is one commit per client.
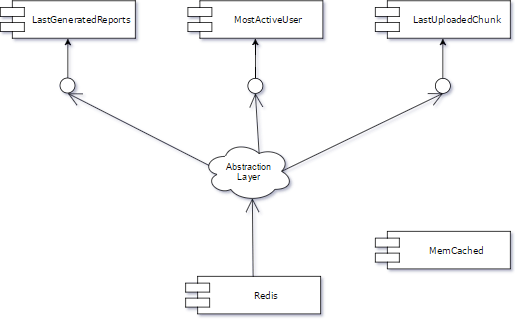
And that is almost the end. Now we can delete the obsolete “Memcached” component along with all of its unit tests. We can also remove the abstraction layer, though it is not obligatory and, in my opinion, leaving the layer could prove useful in the future.
In conclusion, the branch by abstraction technique can be used in a few simple steps:
1. Create an abstraction layer for one client using the old component.
2. Redirect all clients to use the abstraction layer.
3. Create a new component for only one client and connect them via the abstraction layer.
4. Develop the new component and test it.
5. Redirect the abstraction layer to use only the new component.
6. Remove the old component.
With this technique we can easily replace obsolete components with new ones without breaking the trunk line.
Feature flag
The second technique which is often used in Trunk-Based Development is called the feature flag.
One of the most common arguments for Feature Branch Development is that some features are developed longer than one day, over multiple commits, even if they are intended for one release. So how do you bring it together with TBD?
We run into this issue quite a lot and feature flags are a handy tool to deal with it. The basic idea of this approach is to create a config file (or a database table) with a bunch of flags with a unique name.
In such a file, all pending features have their own flags. The simplest example of the config file is a simple map (dictionary) or an object with static members.
In bigger projects, we can store this flags in a database or even use an external library which simplifies this process (you’ll find links to those at the end of this article).
The most popular cases of using feature flags are dealing with a user interface. We just toggle the visibility of a feature. Sometimes we can add a simple ‘if’ statement in a code or, with more advanced cases and doing it a more elegant way, we can use decorators or generators (in Python).
The point where we check the flag is called a toggle point. Everything that is ‘hidden’ behind the “if” is called a toggle test.
There is only one rule about the toggle point and the feature flag in general. We should maintain, as far as possible, the minimum number of toggle points to ensure the new feature is properly hidden.
Let us imagine a situation where we develop a web page generating reports. There may be many places where we display weekly reports on the page but, if there exists only one link redirecting to the page with reports, our toggle test should hide exactly this link. In other words, we should put the minimal amount of toggle tests associated with one flag.
The situation is described in the picture below.

Another popular question about feature flags concerns release testing. Shall we run tests on all possible combinations of flags or just a few of them? For integration tests it is enough to check only two scenarios:
- check if the toggles of all features expected to be in the next release are on,
- check that all toggles on, even in unfinished features.
One important mark: it is a good practice to remove flags of features which are completed and used in production. If we skip this step we will have a number of weird flags in the future and no one will remember who introduced them, when and what they showed or hid.
To summarize, we can introduce the feature flag technique in a few steps:
1. Create a new flag in a config file or a database.
2. Hide a new feature behind the flag.
3. Develop the new feature as long as it is required (it is still covered by the flag).
4. Prepare a list of flags for the current release.
5. Remove flags of features which are in production from the config file/the database.
Fixing bugs in production
It happens. It is sad but possible to catch a bug in a release branch. From the developer’s point of view, we cannot commit directly to the release branch. No one can do it.
What we can do, however, is locate the bug on the trunk branch and try to fix it on the mainline with an additional commit.
Be aware that the mainline and the release branch contain the same code (or similar) so it should not be a problem to reproduce any failure from the release branch on the trunk.
After committing, we will send the commit id to a release manager and he or she will cherry-pick it to the release branch (more on that in a following section).
Code review
As Cory House once said: “Code is like humor. When you have to explain it—it is bad”. Following this rule, the best judge of the clarity of your code will be a code review (or peer review).
Do you remember that in Trunk-Based Development we do small commits with only one function or method, and we plan all features together with the team? Great! So the conclusion can be only one: any review will be a piece of cake. The feature has already been well-described by your team and you have planned how it should be done. It means that every day your team produces a few commits to be reviewed—just a few small commits which need your attention.
It may sound not so great at the beginning, but in practice you do it very quickly – one function and tests. What is more, you are familiar with the contexts of all features after planning, so basically you will check only the technical aspects of the code.
As a reviewer you will have “lost” a maximum of 15 minutes a day. That is all.
Testing
This aspect of TBD is pretty simple. We must cover our feature with tests. There are two possibilities of testing. In the first one, we deliver unit tests for a newly created method or function. Remember, unit tests should cover only the tested function, other functions should be a stub or mock.
Another group of tests covers the integration process. At some point, we might write code which uses functions from a separate module. This connection should also be tested. For a moment, let us try to look at testing from the perspective of a tester. We have a bunch of flags so we can easily turn a feature on and off. It is a great opportunity to introduce A/B testing to our company.
Merging and resolving conflicts
There is only one branch, there are no other branches, so there is no merging. No merging equals no merge conflicts. This is one of the great benefits of Trunk-Based Development.
Typical cases for the release manager
The release manager plays a specific role in Trunk-Based Development. This is the only person (or group of people) who can create release branches and fix bugs in production.
The release manager has only two responsibilities:
- creating a new release branch,
- cherry-picking a possible hotfix.
Let us take a deeper look at those actions.
Creating a new release…
…branch.
I have intentionally skipped the word “branch” in the section title. Why? There are two options how to properly create releases in Trunk-Based Development. A choice should be based on how frequently the releases are made.
For companies where new features are delivered to clients rarely (once a month or less), a release manager should create a release branch for every minor version.
It’s best to keep one release branch alive for a long time because, in the case of a bug, clients cannot wait a month or longer for a fix. This way we can easily increase a version of the release on the release branch with a cherry-picked hotfix.
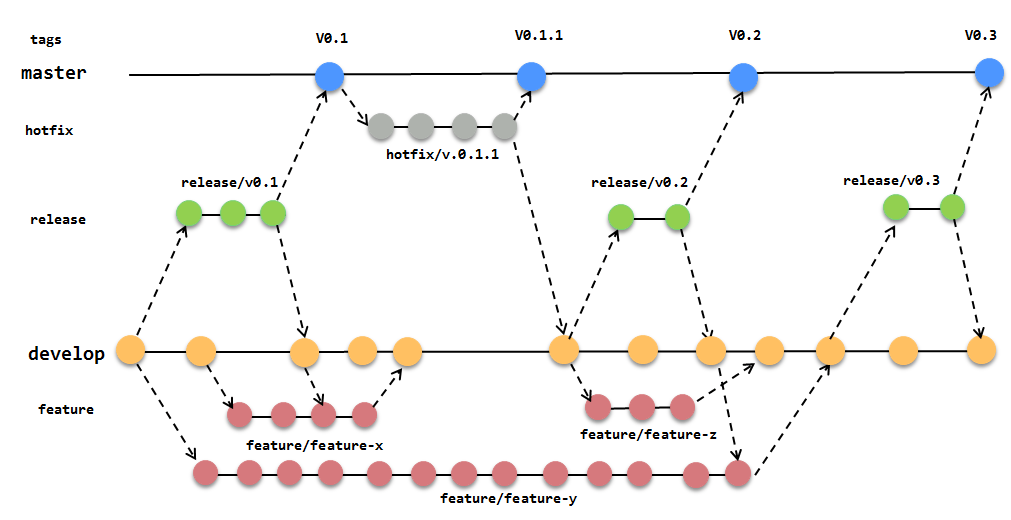
Trunk-Based Development supports semantic versioning (please take a look at the sources section for a great article on this topic). This situation is visualized in the picture below.
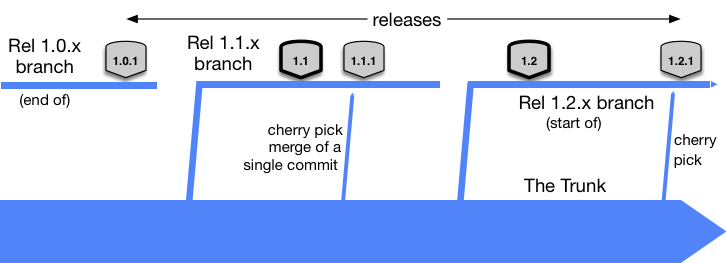
Source: trunkbaseddevelopment.com
Teams with a very high release cadence, on the other hand, do not need release branches. That is why I did not include “branch” in the title above. They can use the trunk to perform a release. Teams often use commit ids or timestamps as versions of releases.
It may also be a good idea to use a version control mechanism such as tags. Bugs can be treated as a normal feature and fixed on trunk. In this way the release becomes very fast. Here is an example flow.
Source: trunkbaseddevelopment.com
Cherry-pick hotfix
One of the most important rules of Trunk-Based Development is: commit directly to the mainline. This means that in the case of a bug on release, we cannot push changes into the release branch.
So the correct way to fix the bug is to reproduce it on the trunk, then perform a fix also on the main branch, after which the release manager can pick this commit into release – this is what we mean by cherry-picking.
Why not commit directly into the release branch and then merge it to the trunk?
First, as we know, one of the main advantages of Trunk-Based Development is that there is no merge hell. If we introduce merging from release branches into the mainline, we would have merge conflicts.
Second, there is a chance you might forget to merge it down, and then there is going to be a regression at the next release.
Summary
Trunk-Based Development is not a new idea, but it has been growing in popularity recently. With projects at major IT companies gaining traction using the TBD approach, now is a great moment for you to introduce Trunk-Based Development at your company.
Let’s sum up how you can benefit:
- TBD saves you from merge hell.
- TBD supports the best developing practices, including feature planning, committing small changes, and writing backward compatible code.
- TBD creates an opportunity to deploy new features faster than using feature branching.
- In the long-term, small commits could help split your big monolith application into neat services.
Personally, I don’t see myself going back.
If you’d like to learn more about Trunk-Based Development, do not hesitate to take a look at the bibliography for further reading. I’ll also be happy to answer any questions you may have in the comments.
For more articles, don’t forget to subscribe to our newsletter using the form on the right (or below on mobile).
Thanks for reading!
Sources
- Trunk-Based Development
- What is Trunk-Based Development?
- Enabling Trunk-Based Development with Deployment Pipelines
- Branch By Abstraction
- Branch By Abstraction by Martin Fowler
- Feature Flags
- Feature Toggles by Martin Fowler
- Feature Flags by Pete Hodgson
- 11 proven practices for peer review
- Semantic Versioning
Artykuł został pierwotnie opublikowany na blog.livingstone-game.com. Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
