Elasticsearch to idealne narzędzie do wyszukiwania wzorca w tekście

Jednym z najbardziej oklepanych obecnie twierdzeń w dziedzinie IT jest to, że żyjemy w epoce danych. Fakt ten poruszają zarówno programiści (i inni pracownicy branży) podczas rozmów przy kawie, jak i przebija się do ogólnej świadomości, zwykle przy akompaniamencie krzykliwych nagłówków serwisów informacyjnych (np. dotyczących afer związanych z naruszeniem prywatności). Niestety, bardzo często z ogólnymi stwierdzeniami występuje zasadniczy problem – nie do końca są prawdziwe.

Bartłomiej Boruta. .NET Developer w Omada. Z wykształcenia elektronik, z powołania programista. Przygodę w branży IT rozpoczął od pracy w obszarze Quality Assurance, skąd jego zamiłowanie do testowalności i utrzymywalności kodu. Fan uporządkowanych procesów, jasnej komunikacji i automatyzowania wszystkiego. Po godzinach rozwija wiedzę z zakresu AI, podróżuje z żoną i kibicuje AS Roma.
O dziwo w przypadku „życia w epoce danych” tego problemu nie ma – należy przyznać, że rzeczywiście żyjemy w epoce danych. Jedyną wątpliwość może budzić zrozumienie samego stwierdzenia, sugerującego, iż dane dopiero teraz zaczęły istnieć, choć tak naprawdę wytwarzane są od zawsze – zmienił się, wraz z rozwojem technologicznym, sposób oraz skala ich pozyskiwania i przechowywania.
W parze z popularyzacją serwisów internetowych, społecznościowych czy smartfonów, zaczęto zbierać dane o ich użytkownikach. Aby dane takie miały jakąkolwiek wartość (oprócz wszelakich możliwości zaspamowania ich właścicieli, o ile dane zawierały dane teleadresowe), należy je odpowiednio przetworzyć i zinterpretować. Konieczność ta, połączona ze wzrostem dostępnej mocy obliczeniowej, spowodowała obecny renesans zagadnień związanych z AI.
Jednym z takich zagadnień jest analiza tekstu, mająca dość szerokie zastosowanie na przykład w wyszukiwarkach lub systemach rekomendacji. W niniejszym artykule chciałbym odrobinę przybliżyć Elasticsearch – najbardziej znany „kombajn” do analizy tekstu oraz pokazać, dlaczego jest fajniejszy niż niektóre sposoby wyszukiwania tekstu.
Spis treści
Czym jest Elasticsearch?
Elasticsearch (autorstwa firmy Elastic NV) jest silnikiem zajmującym się wyszukiwaniem oraz analizą danych tekstowych. Jest to serce całego stacku Elastic, wokół którego zbudowane są inne dostępne rozwiązania, takie jak Kibana (narzędzie do wizualizacji danych pochodzących z Elasticsearcha i powiązanych z nim narzędzi), Logstash (zbieranie, przetwarzanie i przesyłanie logów), Security (zarządzanie dostępami do modułów Elastica) i wiele innych. Niektóre z komponentów (w tym nasz główny bohater) są produktami open-source, stąd dość wysoka ich popularność.
Technicznie rzecz ujmując, Elasticsearch jest niezwykłą bazą danych. Na jego wyjątkowość wpływa kilka czynników:
- dane przechowywane są w tzw. indeksach, czyli zbiorach dokumentów (całość oparta jest na bibliotece Lucene),
- dane można wydobywać za pomocą zapytań Elasticsearch DSL wysyłanych za pomocą REST API,
- jest systemem rozproszonym i bardzo dobrze skaluje się horyzontalnie – możemy dokładać kolejne node’y, zaś Elasticsearch zajmie się resztą (np. odpowiednim rozszerzeniem klastra i podziałem danych pomiędzy serwery) i przyspieszy działanie.
Czytelnik zaznajomiony z zagadnieniem analizy tekstu mógłby w tym momencie zapytać: “zaraz, jeśli to jest oparte na Lucene to w czym jest to lepsze?”. Sama zasada działania jest bardzo podobna, jednak twórcy Elasticsearch udostępnili nam potężne narzędzie — wspomniane już API RESTowe, które w bardzo łatwy sposób pozwala wykonywać wszelakie wyszukiwania oraz analizy. W oryginalnej implementacji Lucene jest ograniczona do jednej technologii — Javy (i ewentualnych wrapperów innych języków).
Elasticsearch ma gotowe biblioteki w kilku językach (m.in. Java, .NET, Python), a nawet brak takowej biblioteki niczego nie przekreśla (bo jest REST). Nawet nie wspominam o prostocie instalacji i konfiguracji (poprawna instalacja wrappera Lucene w Pythonie — PyLucene — na Windows 10 wymaga pewnych skłonności autodestrukcyjnych), którą zaraz będziemy mogli podziwiać.
Instalacja
Zagadnienie instalacji Elasticsearch jest niejednoznaczne — może być bardzo proste (przy instalacji jednego node’a; tutaj skupimy się na drugim najprostszym sposobie) jak również trudne (przy wielu instancjach).
Najprostszym sposobem na rozpoczęcie naszej przygody jest używanie Elasticsearch w modelu SaaS, z czym niestety wiąże się jedna niedogodność — jest to rozwiązanie płatne (nie licząc okresu próbnego). Stąd też posłużę się drugim najprostszym sposobem — użyciem kontenera dockerowego (choć w sumie instalacja z pliku instalacyjnego jest równie prosta, ale bardziej brudzi system). Wykonujemy jedną komendę:
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.0.1
Uwaga 1: tag latest niestety nie działa i wersję trzeba wpisać ręcznie.
Uwaga 2: wersja komendy pull z docker.hub czasami nie działa i nie polecam jej stosować.
Następnie tworzymy i uruchamiamy kontener:
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" --name elasticsearch_test docker.elastic.co/elasticsearch/elasticsearch:7.0.1
Który po chwili powinien być gotowy:
> docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES bcf4254b8fd5 docker.elastic.co/elasticsearch/elasticsearch:7.0.1 "/usr/local/bin/dock…" 2 minutes ago Up 2 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elastic_test
W tej chwili mamy gotowy jeden node i możemy zacząć działać. Oczywiście możliwe jest stworzenie wielu node’ów i podzielenie ich na wiele klastrów, temat ten nie będzie poruszany w ramach artykułu. Kontener nie jest oczywiście jedyną opcją uruchomienia: jeśli ktoś jest zainteresowany czymś więcej niż tylko testową instalacją, odsyłam do dokumentacji.
Mając gotową instancję ES, możemy przejść do “nakarmienia” jej danymi. Najpierw konieczny będzie mały wstęp teoretyczny, wyjaśniający czym i jak takie karmienie przeprowadzić.
Indeksować, kategoryzować, dokumentować
Jak w każdym systemie przechowującym dane, muszą być one przetrzymywane w określonym porządku. W ES nie ma znanych innych rozwiązań bazodanowych tabel, widoków czy nawet baz samych w sobie. Od ogółu do szczegółu wygląda to następująco:
1. Największym zbiorem jest klaster (cluster). Posiada on unikatową nazwę, dzięki czemu możemy przypisać do niego jeden lub więcej node’ów.
2. Jak wyżej wspomniałem, klaster posiada wiele węzłów (nodes). Odpowiadają one za przeprowadzanie operacji na indeksach, oczywiście muszą mieć unikatową nazwę. Do klastra możemy utworzyć i przypisać dowolną liczbę węzłów. Kontener który uruchomiliśmy wcześniej jest najzwyczajniejszym, pojedynczym węzłem.
3. Tutaj dochodzimy do istotnej części — indeksów (o dziwo, po angielsku jest to index). Jest to kolekcja dokumentów i najlepiej, aby dokumenty w obrębie indeksu były ze sobą w jakiś sposób logicznie powiązane, np. indeks movies_index przechowuje dane filmów, natomiast users_index dane użytkowników serwisu filmowego. Uwaga: indeks musi mieć nazwę składającą się z małych liter. To na indeksie przeprowadzamy wszelkie działania wyszukiwania, dodawania, usuwania, edycji dokumentów w jego obrębie.
4. Typ. Począwszy od wersji 7.0.0 został on usunięty, ponieważ wprowadzał pewne nieścisłości jeśli chodzi o przechowywanie i kategoryzowanie dokumentów. Zamiast tego, zalecane jest podejście opisane w punkcie 3 — podzielić dokumenty na odpowiednie “typy” na poziomie indeksów.
5. Dokumenty — czyli najważniejsza część, ponieważ są to niejako pojedyncze “rekordy” naszej bazy danych. Są one przechowywane według zdefiniowanego schematu w formacie JSON.
6. Shards i Replicas (tłumaczenia z powodu słówka shards nie zastosowałem, chociaż Czerep i Repliki brzmi bardzo fajnie; dość podobnie sprawa wygląda z Okruchy i Repliki… polecam sprawdzenie innych tłumaczeń tego słowa) — bardzo ciekawa koncepcja, która w przypadku bardzo dużego rozmiaru danych pozwala na podział indeksu na poszczególne kawałki (shards), dzięki czemu pozwala na lepszą skalowalność systemu. Każdy shard jest oddzielnym podindeksem — podczas tworzenia indeksu możemy podać na ile kawałków (shards) ma on zostać podzielony. W praktyce ten podindeks jest oddzielną instancją indeksu Lucene, który odpowiada za operacje dyskowe oraz analizę tekstu. Repliki są z kolei specjalnym rodzajem sharda, mającym za zadanie duplikowanie istniejących danych, na przykład na wypadek problemów ze sprzętem albo łącznością. Wielką zaletą tego rozwiązania jest fakt, iż na zewnątrz nie widać żadnej różnicy pomiędzy indeksem zawierającym 1 a 5 shardów — wszystkim zajmuje się Elasticsearch. W praktyce wszystko “dzieje się samo”, chociaż ilość shardów i replik musi zostać dobrana doświadczalnie, w zależności od scenariusza użycia.
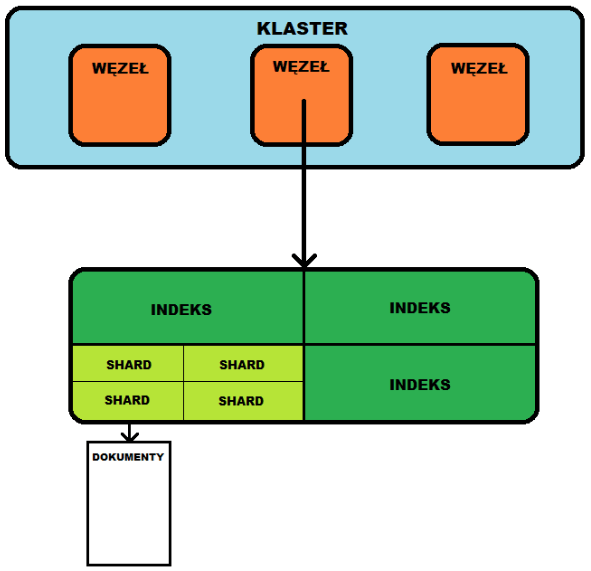
Poglądowa architektura pojedynczego klastra Elasticsearch
Zakładając, że znamy już ogólny zarys działania, przechodzimy do pracy. Po więcej informacji odsyłam oczywiście do dokumentacji.
Za mamusię, za tatusia
Nawet najlepiej przemyślany system analizy danych niewiele zrobi bez danych, dlatego w kilku krokach “nakarmimy” ES i jego indeks jakimiś dokumentami. Do komunikacji z serwerem ES każdy sposób wysyłania requestów (curl, Postman, SoapUI, z kodu) jest równie dobry.
Zacznijmy od sprawdzenia, czy nasz serwer w ogóle działa:
curl -X GET "localhost:9200/_cat/health?v"
Odpowiedź sugeruje, że działa (wszystkie shardy są aktywne):
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent1556995078 18:37:58 docker-cluster green 1 1 0 0 0 0 0 0 - 100.0%
Pierwszym krokiem jest utworzenie indeksu:
curl -X PUT "localhost:9200/test_index"
Jak widać nie jest to zbyt skomplikowane. Jeżeli indeks został pomyślnie utworzony, naszym oczom powinna ukazać się odpowiedź:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test_index"
}
Jest to domyślny typ indeksu, czyli pięć shardów i jedna replika. Usunięcie indeksu jest równie proste:
curl -X DELETE "localhost:9200/test_index"
Polecenie tworzenia indeksu można również nieco rozbudować:
curl -X PUT "localhost:9200/games_test" -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
Co utworzy indeks składający się z trzech shardów i dwóch replik. Mając już gotowy indeks (o nazwie games_test), możemy zacząć dodawać do niego dokumenty:
curl -X PUT "localhost:9200/games_test/_doc/1" -H 'Content-Type: application/json' -d'
{
"name": "Killzone"
}'
W requeście należy tylko podać nazwę indeksu oraz id dokumentu (pogrubione). Jeśli indeks nie istnieje, Elasticsearch utworzy nowy z odpowiednią nazwą, taki jest elastyczny! Dokument możemy oczywiście pobrać z indeksu za pomocą jego id:
curl -X GET "localhost:9200/games_test/_doc/1"
{
"_index": "games_test",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "Killzone"
}
}
W odpowiedzi otrzymujemy dokument wraz ze wszystkimi polami (w tym przypadku jest to tylko name). Aby dodać więcej dokumentów, możemy zapętlić pojedynczy request, co rzecz jasna nie wydaje się najlepszym rozwiązaniem. Na szczęście istnieje wygodniejsza metoda, udostępniona przez API zwane bulk, która pozwala na dodawanie wielu dokumentów w jednym requeście:
curl -X POST "localhost:9200/_bulk" -H 'Content-Type: application/json' -d'
{ "create" : { "_index" : "games_test", "_id" : "2" }}
{ "name" : "Hitman"}
{ "create" : { "_index" : "games_test", "_id" : "3" }}
{ "name" : "Gran Turismo GT"}
{ "create" : { "_index" : "games_test", "_id" : "4" }}
{ "name" : "Ratchet and Clank"} '
W przypadku poprawnego utworzenia dokumentów, powinniśmy w odpowiedzi otrzymać ich dane (analogicznie, jak przy pojedynczym dodawaniu). Dość podobnie wygląda usuwanie wielu dokumentów: zamiast słówka “create” należy użyć “delete” — jeśli dokument istnieje, to zostanie usunięty.
DSL – gonna catch them all (if they match the query)
Po dodaniu dokumentów do indeksu, możemy zacząć na nich pracować. Zacznijmy od wylistowania wszystkich:
curl -X GET "localhost:9200/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
} '
W odpowiedzi powinniśmy znaleźć wcześniej dodane dokumenty (w sekcji ‘hits’):
{
"took": 51,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "games_test",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"name": "Killzone"
}
},
{
"_index": "games_test",
"_type": "_doc",
"_id": "2",
"_score": 1,
"_source": {
"name": "Hitman"
}
},
{
"_index": "games_test",
"_type": "_doc",
"_id": "3",
"_score": 1,
"_source": {
"name": "Gran Turismo GT"
}
},
{
"_index": "games_test",
"_type": "_doc",
"_id": "4",
"_score": 1,
"_source": {
"name": "Ratchet and Clank"
}
}
]
}
}
W opisie dokumentu pojawił się tajemniczy parametr _score. Co on oznacza? Otóż opisuje on dopasowanie danego dokumentu do naszej query, wyliczone przez indeks Lucene. Ale hola hola, przecież wcześniej nic nie mówiłem o żadnej query!
Pora więc wspomnieć o Query DSL (Query Domain Specific Language) — jest to format (oparty o JSON) służący do wyciągania odpowiednich dokumentów według zadanych kryteriów — match_all zwraca wszystkie dokumenty z danego node’a.
Zapytanie wyszukujące dokumenty może mieć dwa konteksty:
1. Query context — oblicza dopasowanie istniejących dokumentów do zadanego zapytania. To tutaj “pod kopułą” Elasticsearcha dokonuje się analiza dopasowania wyników.
2. Filter context — zwraca tylko idealnie dopasowane dokumenty bez obliczania ich wyniku, odpowiadając za pomocą tak lub nie (bez żadnych wyników) — czyli działa bardziej “klasycznie” — jeśli coś nie jest pasujące w 100% do zapytania, to zostaje pominięte w wynikach.
Spróbujmy teraz znaleźć grę Killzone:
curl -X GET "localhost:9200/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"name": "Killzone"
}
}
} '
Jest to tzw. match query, które pozwala nam wyszukać dokumenty w zależności od wartości pola (w tym przypadku pola name). W odpowiedzi otrzymujemy:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.5135659,
"hits": [
{
"_index": "games_test",
"_type": "_doc",
"_id": "1",
"_score": 1.5135659,
"_source": {
"name": "Killzone"
}
}
]
}
}
Widać, że zwrócony został dokument o nazwie Killzone (id=1), należący do indeksu games_test. Wyszukiwanie możemy zawęzić także do jednego indeksu (url requestu: localhost:9200/games_test/_search).
Warto zapoznać się też z bool query, która pozwala na bardziej precyzyjny dobór warunków wyszukiwania. Dodajmy do naszego indeksu kolejny dokument:
curl -X PUT "localhost:9200/games_test/_doc/5" -H 'Content-Type: application/json' -d'
{
"name": "Killzone: Shadow Fall"
}'
Bool query pozwala nam na użycie dodatkowych kryteriów, takich jak:
- must — klauzula musi pojawić się w wyszukiwanym polu,
- should — jeśli klauzula pojawi się w wyszukiwanym polu, to otrzyma ona “podwyższenie” swojego score; jednak dokument nie zostanie pominięty w wynikach jeśli nie spełnia kryterium should,
- must_not — klauzula nie może znaleźć się w danym polu,
- filter — klauzula musi pojawić się w wyszukiwanym polu, jednak nie będzie wpływała dodatnio na score.
Dzięki tym kryteriom możemy tworzyć bardziej zaawansowane zapytania. Wyciągnijmy teraz dokumenty, których tytuł zawiera (must) słowo Killzone i powinno (should) zawierać słowo Shadow:
curl -X GET "localhost:9200/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": {
"match": {
"name": "Killzone"
}
},
"should": {
"match": {
"name": "Shadow"
}
}
}
}
} '
Kryteria must i should muszą znajdować się “nad” match query — mamy tutaj dosyć sporą dowolność jeśli chodzi o tworzenie zapytań (zamiast match query możemy równie dobrze stosować inne). Oto dokumenty, jakie zwrócił ES:
"hits": [
{
"_index": "games_test",
"_type": "_doc",
"_id": "5",
"_score": 1.9688729,
"_source": {
"name": "Killzone: Shadow Fall"
}
},
{
"_index": "games_test",
"_type": "_doc",
"_id": "1",
"_score": 1.1269331,
"_source": {
"name": "Killzone"
}
}
]
Jak widać oba dokumenty o nazwie Killzone zostały zwrócone, jednak Killzone: Shadow Fall ma wyższy wynik ponieważ spełnia kryterium should.
Oczywiście jest to tylko ułamek możliwości Elasticsearch, choć nawet mała ilość opcji daje nam dość szerokie pole do popisu. Naturalnie możliwości wyszukiwania (i analizy poprzez wyliczanie dopasowania) działają także dla o wiele większych objętościowo dokumentów. Dodając do tego możliwość łatwego skalowania wydajności, zyskujemy naprawdę wydajne narzędzie. I to wszystko w zasadzie za darmo (jak sobie sami skonfigurujemy oczywiście)!
Panie, bo mi się te literki ciągle mylą!
Udało nam się już odrobinę “podrapać po powierzchni” Elasticsearcha, pora więc na trochę inny praktyczny przykład. Załóżmy, że w pewnej bazie danych przechowujemy tytuły gier wideo:
Id Name 5 The Legend of Zelda: Ocarina of Time 6 Tony Hawk's Pro Skater 2 7 Grand Theft Auto IV 8 Soul Calibur 9 Super Mario Galaxy 10 Super Mario Galaxy 2 11 Red Dead Redemption 2 12 Grand Theft Auto V 13 The Legend of Zelda: Breath of the Wild 14 Metroid Prime
Załóżmy scenariusz, gdzie użytkownik chce znaleźć dany tytuł w hipotetycznej wyszukiwarce gier (pomijam cały aspekt webowy, skupię się na prostych querach SQL). Jeśli wpisze w pasek wyszukiwania tytuł “Red Dead Redemption 2”, zapytanie SQL:
SELECT [Id]
,[Name]
FROM [JustJoinFun].[dbo].[VideoGames]
WHERE Name LIKE 'Red Dead Redemption 2'
Zwróci nam oczywiście poprawny wynik:
Id Name 11 Red Dead Redemption 2
Jednak co jeśli użytkownik z pośpiechu (albo braku wprawy w pisaniu na klawiaturze) wpiszę nazwę gry z literówką? Na przykład “Red Daed Redemption 2”? Oczywiście powyższe zapytanie SQL zwróci nic — zapewne zaprzęgnięcie odpowiednio rozbudowanej logiki (czy to po stronie bazy danych, czy po stronie aplikacji) pozwoliłoby nam zabezpieczyć się na takie sytuacje, niestety ryzykujemy niepotrzebną komplikacją kodu. Może warto w takiej sytuacji skorzystać z faktu, że Elasticsearch jest… elastyczny? Po dodaniu wszystkich dokumentów do indeksu, wystarczy posłużyć się prostym query (w międzyczasie w ramach ćwiczeń można dodać sobie nowy index oraz tytuły gier, polecam oczywiście bulk):
curl -X GET "localhost:9200/i_cant_write/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"name": "Red Daed Redemption 2"
}
}
} '
W odpowiedzi uzyskujemy ostatecznie tytuł, o jaki nam w zamyśle chodziło:
"hits": [
{
"_index": "i_cant_write",
"_type": "_doc",
"_id": "8",
"_score": 4.101935,
"_source": {
"name": "Red Dead Redemption 2"
}
}
]
ES zatem w prosty sposób pozwala nam na dodanie funkcji typu “czy miałeś na myśli” lub “wyświetlam wyniki dla” (podobnie, jak przy wyszukiwaniu w google, gdy zrobimy literówkę) lub proponowanej autokorekty.
Podsumowanie
Mam nadzieję, że choć trochę udało mi się przybliżyć czym jest i jak działa Elasticsearch. Jak już uprzednio wspomniałem, jest to bardzo rozbudowane narzędzie, czynnie rozwijane, z masą możliwości, które bardzo ciężko przedstawić w jednym wpisie. Osobiście używam go dość intensywnie do analizy tekstów, liczba przypadków użycia które można pokryć za jego pomocą jest naprawdę duża (do inspiracji polecam przejrzeć https://www.elastic.co/use-cases/). Obecnie chyba największą furorę robi jako narzędzie do analizy logów, jednak zachęcam do kreatywnego podejścia — możliwości jest naprawdę sporo!
W tym miejscu, celem poparcia tezy przedstawionej w tytule, powinienem też odpowiedzieć na pytanie: dlaczego Elasticsearch to idealne narzędzie do wyszukiwania wzorca w tekście?
- bardzo dużo rzeczy upraszcza (zarządzanie indeksami, pamięcią, shardy),
- ma fajne RESTowe API (oraz biblioteki do coraz większej liczby języków),
- pozwala robić rzeczy niemożliwe (albo ciężkie do zrobienia) za pomocą klasycznych zapytań lub regexpów,
- jest bardzo wydajny i prosty w instalacji.
Nie dziwi więc duża popularność, która z biegiem czasu (i rozrostem całego stacku Elastic) jeszcze będzie rosnąć.
Źródła:
Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły

Wykorzystujesz w projekcie AI? Wyznacz dedykowany zespół do kontroli jej jakości

Czy da się rozmawiać o AI bez magii i fantastyki? Podsumowanie debaty Tech Talk

Golang w rozwoju aplikacji AI. Najlepsze praktyki i studia przypadków

Dlaczego nie powinniśmy powstrzymywać rozwoju AI? Opinie ekspertów z Capgemini

Na rynku wciąż widać stabilną pozycję języka Java. Jaka będzie przyszłość Javy?

Czy programistów zastąpi sztuczna inteligencja? Ponad ⅓ badanych twierdzi, że tak

Portret lidera AI. Fragment książki pt. "Sztuczna inteligencja w biznesie"
