Discover Weekly, czyli co się dzieje za kotarą Spotify

Jednym z podziałów dominujących w naszym społeczeństwie jest odwieczna dyskusja, która mierzy ze sobą humanistów i naukowców, sztukę i pojęcia ścisłe. Jakby nie można było połączyć tych dwóch pozornie przeciwstawnych pojęć. Spotify, platforma muzyczna, która za pomocą algorytmów i modeli rekomendacji dopasowuje ofertę do indywidualnych użytkowników, pokazuje nam, że odwieczna walka dziedzin artystycznych i ścisłych kończy się tutaj.

Sophia Ciocca. Software engineer w The New York Times. W 2014 ukończyła studia ekonomiczne na Uniwersytecie w Pensylwanii. W 2016 przez pół roku pracowała dla Korpusu Pokoju jako specjalista do nauczania przedsiębiorczości. Rok później ukończyła kurs JavaScript na Fullstack Academy of Code.
W tym tekście Sophia uchyla rąbka tajemnicy dotyczącej strategii Spotify w tworzeniu spersonalizowanych, cotygodniowych playlist dla swoich użytkowników. Polecamy artykuł każdemu, kogo fascynują mechanizmy stojące za Spotify, ale też każdemu, kto pragnie zobaczyć w jaki sposób muzyka i przedmioty ścisłe mogą ze sobą współpracować. Poniższy tekst został przetłumaczony za zgodą autorki.
W każdy poniedziałek, ponad 100 milionów użytkowników Spotify, na swojej skrzynce pocztowej znajduje nową playlistę zatytułowaną Discover Weekly. To spersonalizowana lista 30 piosenek, których do tej pory dany użytkownik nie miał okazji wysłuchać..
Osobiście jestem wielką fanką Spotify, a w szczególności Discover Weekly. Dlaczego? Bowiem sprawia ona, że czuję się zauważona. Spotify zna moje upodobania muzyczne lepiej niż ktokolwiek inny, a utwory, które mi poleca prawie zawsze przypadają mi do gustu, choć sama pewnie nigdy bym ich nie znalazła.
Dla tych, którzy nigdy nie słyszeli o Spotify – pozwólcie, że przedstawię wam mojego najlepszego wirtualnego przyjaciela:
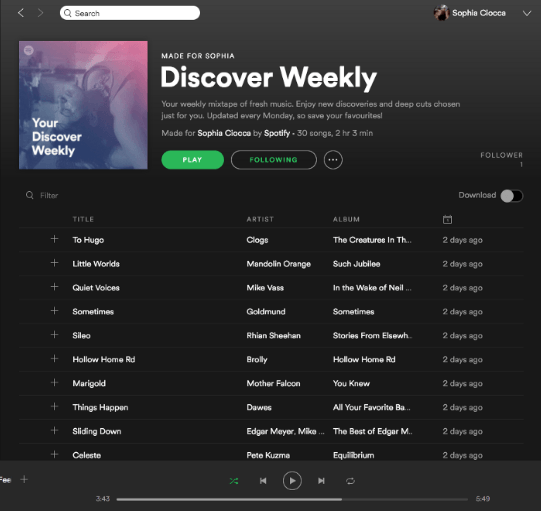
Jak się okazuje, nie tylko ja mam obsesję na punkcie Discover Weekly. Baza użytkowników wręcz za nią szaleje, co doprowadziło Spotify do przemyślenia swojej strategii i zwiększenia inwestycji w playlisty oparte o algorytmy.
Od momentu, w którym w 2015 roku Discover Weekly pojawiło się po raz pierwszy na scenie Spotify chciałam zrozumieć mechanizmy za nią odpowiedzialne. Po trzech tygodniach szaleńczego googlowania mam wrażenie, że wreszcie udało mi się dojrzeć czegoś za kotarą.
Zatem jak to jest, że Spotify jest w stanie wybrać 30 piosenek dla każdego użytkownika każdego tygodnia? Zróbmy krok do tyłu i spójrzmy najpierw jak inne serwisy muzyczne radziły sobie z rekomendacjami, i w jaki Spotify robi to lepiej.
Spis treści
Krótka historia serwisów muzycznych
Jeszcze w latach 2000, Songza zapoczątkowała erę serwisów muzycznych. Serwis ten tworzył playlisty za pomocą “ekspertów muzycznych”, którzy decydowali, które utwory należy na nich umieścić. Sposób ten sprawdzał się dobrze, jednak opieranie się wyłącznie o ekspertów muzycznych nie brało pod uwagę muzycznych upodobań każdego użytkownika.
Podobnie jak Songza, Pandora również była jednym z serwisów oferujących muzykę. Stosowała ona jednak bardziej zaawansowane podejście, opisując każdą ścieżkę dźwiękową i odpowiednio ją tagując. Następnie kod Pandory filtrował konkretne tagi, aby utworzyć playlistę o podobnym brzmieniu.
Mniej więcej w tym samym czasie narodziła się agencja muzycznej inteligencji The Echo Nest. Miała ona radykalne podejście do personalizacji muzyki. The Echo Nest stosował algorytmy do analizowania zarówno dźwięku audio, jak i tekstu danego utworu, co pozwalało na identyfikację muzyki, pozwalając tym sposobem na spersonalizowane rekomendacje, tworzenie playlist i analizę.
Następnym graczem na ówczesnym rynku było Last.fm, które do proponowania muzyki użytkownikom używa procesu zwanego Collaborative Filtering. Więcej na jego temat później. Jakie podejście ma Spotify?
Trzy modele rekomendacji Spotify
Aby stworzyć Discover Weekly, Spotify stosuje mieszankę trzech typów modeli rekomendacji:
- modele Collaborative Filtering, które analizują zarówno zachowanie twoje, jak i innych ludzi,
- modele Natural language Processing, które analizują tekst,
- modele audio, które analizują wyłącznie ścieżki dźwiękowe.
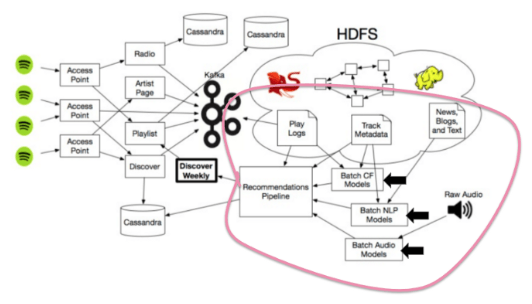
Zobaczmy teraz jak działa każdy z powyższych modeli.
Model Rekomendacji numer 1: Collaborative Filtering
Najpierw małe wprowadzenie: kiedy ludzie po raz pierwszy słyszą pojęcie Collaborative Filtering, z reguły pierwsza myśl, jaka przychodzi im do głowy to Netflix – jedna z pierwszych platform, która zastosowała tę metodę w procesie rekomendowania swoich produktów poprzez używanie ocen filmów.
Po sukcesie Netfliksa Collaborative Filtering szybko się rozprzestrzeniło, obecnie będąc początkowym punktem dla każdego, kto chce stworzyć model rekomendacji.
W przeciwieństwie do Netfliksa, Spotify nie ma gwiazdkowej oceny muzyki. Zamiast tego, bierze pod uwagę takie czynniki, jak na przykład fakt, czy użytkownik zachował ścieżkę dźwiękową do własnej playlisty lub czy odwiedził stronę artysty po wysłuchaniu piosenki.
Czym jest jednak Collaborative Filtering i jak działa?
Przyjmijmy, że mamy dwóch użytkowników. Jednemu podobają się utwory P, Q, R, S, podczas gdy drugiemu podobają się utwory Q, R, S, T. Collaborative Filtering jest w stanie stwierdzić, że oboje użytkowników mają podobny gust muzyczny i sugeruje, aby ta pierwsza osoba odsłuchała ścieżkę T, a ta druga ścieżkę P.
W jaki sposób Spotify używa tej koncepcji, aby zasugerować ścieżki dźwiękowe dla milionów użytkowników w oparciu o preferencje milionów innych użytkowników?
Za pomocą macierzy i bibliotek Pythona!
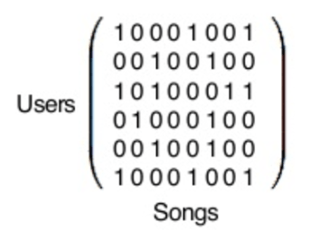
W rzeczywistości macierz, którą widzisz powyżej jest gigantyczna. Każdy rząd reprezentuje jednego ze 140 milionów użytkowników Spotify, a każda kolumna reprezentuje jedną z 30 milionów piosenek w bazie danych Spotify.
Biblioteka Pythona przetwarza poniższe działanie:
![]()
Kiedy jest już to skończone mamy dwa typy wektorów przedstawione tutaj przez X i Y. X jest wektorem użytkownika reprezentującym upodobania pojedynczego użytkownika, a Y jest wektorem piosenki reprezentującym profil pojedynczej piosenki.
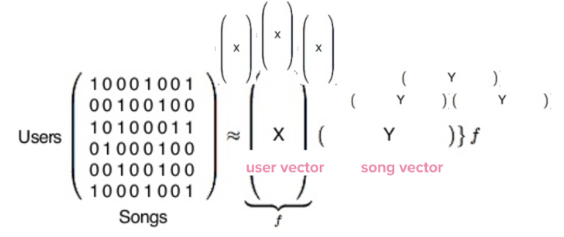
Macierz użytkownik / piosenka produkuje dwa typy wektorów – wektor użytkownika i wektor piosenki. Mamy teraz 140 milionów wektorów użytkowników i 30 milionów wektorów piosenki. Zawartość w tych wektorów to właściwie tylko zbiór liczb, które same w sobie są bez znaczenia, ale są bardzo przydatne, kiedy porównamy je do siebie.
Aby dowiedzieć się, którzy użytkownicy mają podobne upodobania muzyczne Collaborative Filtering porównuje wektory użytkowników aż w końcu znajdzie te, które są do siebie najbardziej zbliżone. Tak samo dzieje się w przypadku wektora Y: możesz porównać wektor pojedynczej piosenki z innymi piosenkami i wybrać tę piosenkę, która jest najbardziej podobna do tej, o którą pytamy.
Collaborative Filtering daje sobie radę całkiem dobrze, ale aby ulepszyć swoją ofertę Spotify dodał kolejny silnik.Jednym z podziałów dominujących w naszym społeczeństwie jest odwieczna dyskusja, która mierzy ze sobą humanistów i naukowców, sztukę i pojęcia ścisłe. Jakby nie można było połączyć tych dwóch pozornie przeciwstawnych pojęć. Spotify, platforma muzyczna, która za pomocą algorytmów i modeli rekomendacji dopasowuje ofertę do indywidualnych użytkowników, pokazuje nam, że odwieczna walka dziedzin artystycznych i ścisłych kończy się tutaj.
Model rekomendacji numer 2: Natural Language Processing
Drugim rodzajem modelu rekomendacji używanego przez Spotify jest Natural Language Processing. Dane źródłowe używane przez te modele, jak sama nazwa wskazuje, to zwyczajne słowa: metadane ścieżek dźwiękowych, artykuły, blogi, oraz wszelkie inne teksty z internetu.
Natural Language Processing, oznaczające umiejętność komputera do rozumienia ludzkiej mowy, jest szerokim pojęciem samym w sobie, zaprzęgniętym na dodatek w tzw. analizę sentymentu (ang. sentiment analysis).
W tym artykule nie będziemy w stanie wyjaśnić dokładnego mechanizmu NLP, ale możemy mniej więcej przedstawić zarys tego procesu. Spotify bezustannie przeszukuje internet, w tym metadane ścieżek dźwiękowych, artykułu, blogi itd, w poszukiwaniu m.in. przymiotników używanych do opisania poszczególnych artystach i piosenek. Poprzez ustalenie, który inny artysta i piosenka jest również opisywany za pomocą podobnego języka, Spotify jest w stanie wybrać utwory, które mogłyby spodobać się danemu użytkownikowi.
Mimo, iż nie wiem w jaki dokładnie sposób dane te są potem przetwarzane przez Spotify mogę zaoferować pewien wgląd w dawną współpracę pomiędzy Echo Nest, a Spotify. Echo Nest pakowało dane Spotify do czegoś, co nazywali wektorami kulturowymi lub też “Top Terms”. Każdy artysta i piosenka mieli tysiące top terms, które zmieniały się codziennie. Każdy “term” miał przypisaną wagę, która korelowała z jego ważnością – prawdopodobieństwo, że ktoś opisze tego artystę lub piosenkę za pomocą tej frazy.
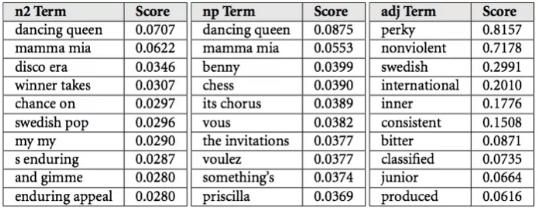
Podobnie jak w przypadku Collaborative Filtering, model NLP używa tych terminów i wagi, aby stworzyć reprezentację wektorową piosenki, która może zostać użyta do zdeterminowania dwóch kawałków muzyki podobnych do siebie. Niezłe, prawda?
Model Rekomendacji numer 3: Raw Audio Models
Możesz sobie myśleć: Sophia, przecież mamy już tyle danych z dwóch pierwszych modeli! Po co mamy analizować również i audio?
Po pierwsze, dodanie trzeciego modelu dodatkowo zwiększa precyzję, z jaką Spotify jest w stanie polecić nowe utwory. Ponadto, ten model jest o tyle lepszy, niż pozostałe dwa modele gdyż pod uwagę bierze nie tylko popularne utwory, ale również nowe piosenki i mało znanych artystów.
Weźmy na przykład piosenkę napisaną przez twojego przyjaciela, która ma tylko 50 odsłuchań – nie ma zatem zbyt wielkiej możliwości, aby przeprowadzić Collaborative Filtering. Na dodatek nie ma o niej żadnej innej wspominki na internecie, więc model NLP jej nie znajdzie. Raw Audio Models nie patrzy na popularność piosenek – dzięki niemu piosenka twojego przyjaciela może wskoczyć do Discover Weekly razem z utworami, które cieszą się większą popularnością.
W jaki sposób Spotify analizuje raw audio data?
Za pomocą głębokich sieci konwolucyjnych (ang. convolutional neural network, CNN). CNN to technologia z reguły używana w oprogramowaniu do rozpoznawania twarzy, jednak w przypadku Spotify, została zmodyfikowana w sposób pozwalający na użytkowanie jej na danych w formacie audio raczej niż w pikselach. Tutaj mamy przykład budowy CNN:
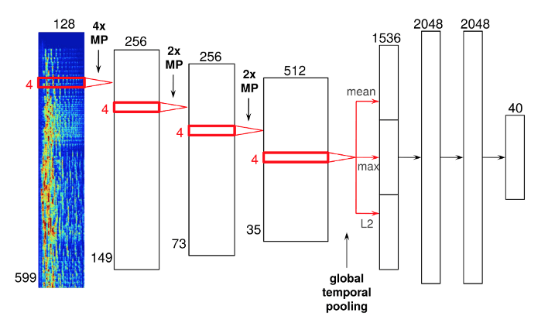
Ta poszczególna sieć neuronowa ma cztery warstwy konwolucyjne, przedstawione jako szerokie słupki po lewej, i trzy gęste warstwy, widziane w formie węższych słupków po prawej. Widoczne są też częstotliwości dźwięku, które następnie są łączone, aby utworzyć spektogram.
Końcowo, ten sposób analizowania kluczowych cech danego utworu pozwala Spotify zrozumieć fundamentalne podobieństwa pomiędzy piosenkami i tym samym, którym użytkownikom spodobają się najbardziej. Ten sposób pokryliśmy całą podstawę trzech głównych typów modeli rekomendacji stosowanych przez Spotify do utworzenia Discover Weekly.
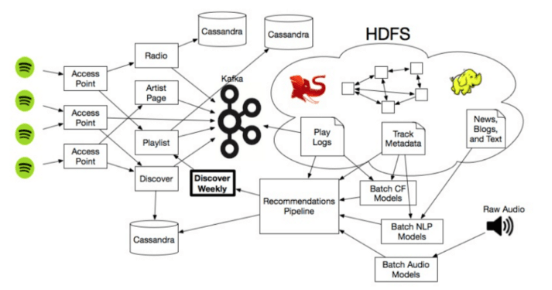
Oczywiście, modele rekomendacji są podłączone do większego ekosystemu Spotify, który zawiera ogromne ilości danych i stosuje wiele zbiorów Hadoop do skalowania rekomendacji i umożliwiania silnikom pracę na wielkich matrycach, niekończących się artykułach muzycznych i plikach audio.
Mam nadzieję, że artykuł ten wzbudził waszą ciekawość w taki sam sposób, w jaki wzbudził moją. Pozostaje mi tylko dalej przedzierać się przez moje własne Discover Weekly w poszukiwaniu nowych faworytów i doceniając tym samym uczenie maszynowe, które ma miejsce za kulisami.
Artykuł został pierwotnie opublikowany na medium.com. Autorką tłumaczenia jest Zuzanna Filipiuk. Zdjęcie główne artykułu pochodzi z unsplash.com.
Podobne artykuły
Podejście do zmniejszania kosztów przetwarzania danych na przykładzie Azure Databricks

Data management, data governance i data modernization - jak okiełznać proces zarządzania danymi w organizacji

Big Data - klęska urodzaju czy złoty Graal? Praktyczne metody wykorzystania potencjału danych
Dane 1,3 mln użytkowników Clubhouse do pobrania? To nie wyciek, to data scraping

Text clustering, czyli jak wyciągnąć realną wartość biznesową z milionów wiadomości tekstowych

Migracja do chmury? Wypełnij ankietę i sprawdź, jak wygląda ten proces u innych!

Analiza infrastruktury i danych IoT. Wybór bazy
