Command Query Responsibility Segregation — pierwsze kroki
O wzorcu CQRS – Command Query Responsibility Segragation – wytworzyło się wiele nieprawdziwych treści i mitów. Chciałbym w tym krótkim artykule podać prostsze wytłumaczenie tego wzorca. Pozwoli on na wdrożenie CQRS przy minimalnym nakładzie czasu i energii, jednocześnie mając z tego wymierne korzyści.

Radek Maziarka. Development Guild Evangelist w Objectivity. Przeszedł ścieżkę od programisty przez team leadera po development managera, który dba o rozwój działu programistycznego w kontekście skalowania wiedzy w firmie i attractu developerskiego. Bloguje na radblog.pl, gdzie opisuje zarówno tematy techniczne, jak i tematy miękkie. Możecie go złapać na Twitterze, pod adresem @RadekMaziarka, gdzie udziela się w dyskusjach i wrzuca ciekawe materiały.
Spis treści
Dlaczego miałbym się przejmować?
Trochę przewrotne pytanie na początek artykułu, jednak celowe. Zbyt rzadko zadajemy sobie to pytanie zachłystując się nowymi technologiami i wzorcami. Dodajemy nowe warstwy do naszych aplikacji, wciskamy kolejne biblioteki, przez co zrozumienie naszej aplikacji z każdym dniem maleje. Poszczególny wzorzec jest dobry, gdy rozwiązuje konkretne problemy. Gdy tego nie robi jest tylko kolejnym problemem, który sobie narzuciliśmy na barki.
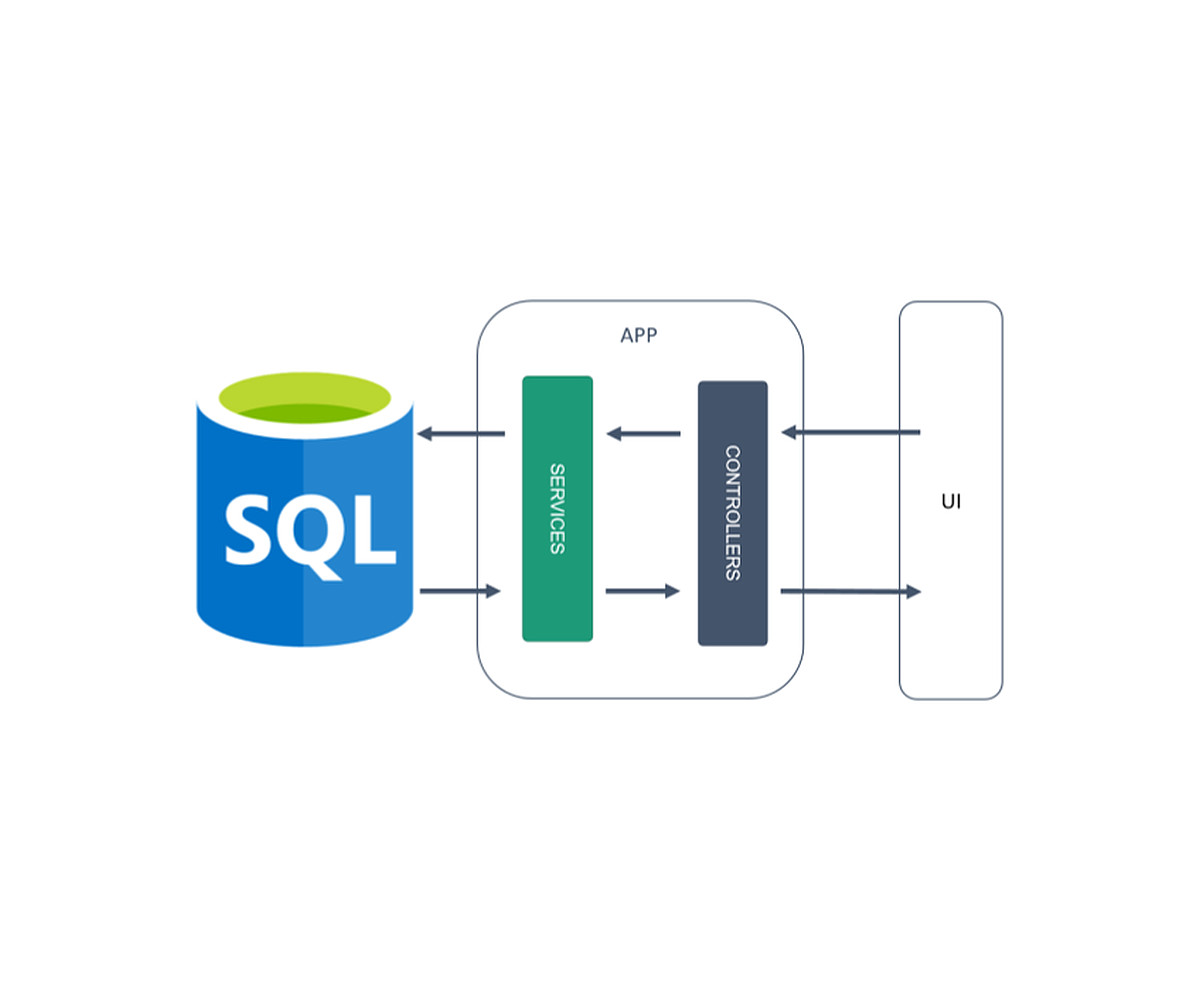
Załóżmy, że tworzysz nową aplikację webową. Prawdopodobnie zaprojektujesz ją w standardowy sposób, jaki jest opisywany w Internecie dla takich aplikacji – warstwowo:

Warstwa prezentacyjna będzie się kontaktowała z kontrolerami, kontrolery z serwisami (nie można mieć logiki domenowej w kontrolerach!), a serwisy z bazą danych. Jak Pan Bóg przykazał. Biorąc za przykład sklep internetowy może to wyglądać następująco:

Twój kontroler produktów będzie się kontaktować z serwisem, aby pobrać produkty oraz zmienić konkretne pole danego produktu. Kontroler zamówień będzie się kontaktować z serwisem zamówień, aby pobrać zamówienie lub zmienić adres zamówienia. Jasno i zrozumiale. Do czasu…
Niestety taki sposób tworzenia aplikacji jest słabo skalowalny. Możesz się przekonać o tym sprawdzając repozytoria najpopularniejszego open-sourcowego sklepu internetowego w technologii .NET – nopCommerce. Bardzo dobry kawałek oprogramowania, niestety bardzo trudny w utrzymaniu (wiem to z własnego doświadczenia).


Serwis do obsługi zamówień ma 3144 linii kodu, serwis do obsługi produktów ma 2142 linie kodu. Logika zmian w bazie danych miesza się z obsługą pobierania danych dla widoków. Ogromna ilość parametrów w konstruktorach klas uniemożliwia sensowne przetestowanie takiego kodu.
Taki sposób tworzenia oprogramowania utrudnia jego zrozumienie i rozwój. Tutaj musi być lepsza droga. I jest – CQRS.
Command Query Responsibility Segregation
CQRS – Command Query Responsibility Segragation został pierwszy raz opisany przez Grega Younga w swoim dokumencie „CQRS Documents by Greg Young” w 2010 roku. Opisuje on typowe problemy jakie mogą powstawać przy architekturze warstwowej i proponuje remedium w postaci owego wzorca.

Greg proponuje rozdział serwisów na te, które zajmują się tylko odczytami lub tylko zapisami. Taki, teoretycznie prosty rozdział daje następujące możliwości:
- oddziela logikę modyfikacji (z reguły bardziej skomplikowaną) i pobierania danych (z reguły prostszą),
- ułatwia skupienie się na optymalizacje zapytań w części odczytu,
- pozwala na bardziej skomplikowane wzorce w części zapisu,
- premiuje używanie innych obiektów w części odczytu/zapisu, co skutkuje bardziej zrozumiałym kodem.
Można pójść poziom dalej (czego jestem zwolennikiem) i podzielić serwisy odczytu / zapisu na pojedyncze klasy – każda odpowiedzialna za jedno żądanie z poziomu użytkownika:

Dokonuje się tutaj zmiana nazw obiektów przychodzących do aplikacji. Obiekty, które są wysyłane, aby zmienić stan nazywamy komendami (Command), a te wysyłane by pobrać dane nazywamy zapytaniami (Query). Następnie, w kontrolerze komendy i zapytania kierujemy do odpowiednich klas zajmujących się obsługą komend / zapytań (Command / Query Handler).
Poza zaletami opisanymi powyżej dochodzą tutaj jeszcze:
- pojedyncza odpowiedzialność – każda klasa odpowiada za jedno żądanie,
- jasno określone zależności danej klasy,
- prostota pisania testów jednostkowych,
- niższy próg wejścia do projektu – każda komenda / zapytanie ma swoją klasę obsługującą,
- bardziej zrozumiała struktura projektu.

Warty zaznaczenia jest fakt, że nie musisz od razu przechodzić w 100% w ten model. Możesz dzień po dniu, tydzień po tygodniu, wydzielać kolejne metody z serwisów, zachowując przy tym utrzymywalność twojej aplikacji.
Show me the code
Poniżej przedstawiłem przykład implementacji wzorca CQRS, na podstawie kodu w języku C#. Jest to na tyle czytelne, że będzie zrozumiałe dla osób używających dowolnych języków programowania.
Poprzedni schemat obsługi produktów wygląda teraz następująco:
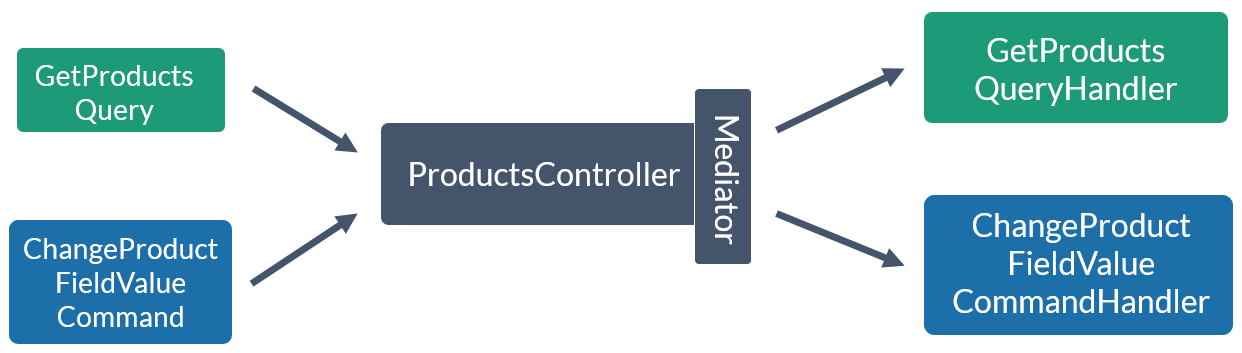
Obiekty, które przychodzą do systemu zostały zmienione na komendy / zapytania. Następnie, w kontrolerze, Mediator wrzuca przychodzące obiekty do odpowiednich klas obsługujące je. Można się spytać – w jaki sposób Mediator wie jaka klasa odpowiada za obsługę danego żądania?
Mediator jest implementacją wzorca Dispatcher, która odpowiada za przesyłanie żądań do klas obsługujących te żądania. Możemy taką implementację napisać samemu (przykładowa implementacja z bloga Future Processing) lub wybrać już gotową bibliotekę. Jestem dużym fanem biblioteki MediatR, ponieważ nie posiada ona dodatkowych zależności i jest bardzo prosta w użyciu.
Kontroler, posiadający nasz Mediator, będzie wyglądać następująco:
public class ProductsController : ApiController
{
private readonly IMediator mediator;
public ProductsController(IMediator mediator)
{
this.mediator = mediator;
}
[HttpGet]
public IEnumerable<Product> GetProducts(GetProductsQuery query)
{
return this.mediator.Send(query);
}
[HttpPut]
public void ChangeProductFieldValue(ChangeProductFieldValueCommand command)
{
this.mediator.Send(command);
}
}
Widzimy dwie metody – jedną pobierającą produkty, a drugą modyfikującą pole danego produktu. Na wejściu każdej z nich mamy obiekty opisujące, czy chcemy odczytać dane, czy je zmienić. Te obiekty trafiają do obiektu Mediatora. I to jest cała logika – nie musimy wstrzykiwać dodatkowych zależności, jedynym naszym parametrem w kontrolerze jest Mediator. Następnie te żądania są obsługiwane w dedykowanych klasach. Najpierw przykładowa implementacja kodu odpowiedzialnego za modyfikację danych:
public class ChangeProductFieldValueCommandHandler
:IRequestHandler<ChangeProductFieldValueCommand>
{
private IProductDatabase database;
private IProductFieldHelper productFieldHelper;
private IFieldValidatorFactory fieldValidatorFactory;
public void Handle(ChangeProductFieldValueCommand command)
{
this._categoryFieldService.ValidateIfFieldCanBeAssignedToProduct
(command.FieldId, command.ProductId);
var fieldValidator = this._fieldValidatorFactory(command.FieldId);
fieldValidator.Validate(command.FieldValue);
// more business logic
_database.SaveChanges();
}
}
Klasa ta nie ma żadnych niepotrzebnych parametrów wejściowych – wszystkie są wymagane, by spełnić dany cel biznesowy. Upraszcza to znacznie zrozumienie wymogów i rezultatów klasy – wszystko jesteśmy w stanie zobaczyć na jednym ekranie. Zmniejsza to czas na pisanie testów jednostkowych, bo lista danych potrzebnych, by uruchomić taki test, będzie mniejsza.
Następnie klasa odpowiedzialna za pobieranie danych:
public class GetProductsQueryHandler
: IRequestHandler<GetProductsQuery, IEnumerable<Product>>
{
private readonly IProductDatabase _database;
public IEnumerable<Product> Handle(GetProductsQuery query)
{
var products = this._database
.Products
.Include(p => p.Category)
.Include(p => p.FieldValues)
.Include(p => p.FieldValues.Select(fv => fv.Field));
// filter products by query values
return products
.OrderBy(p => p.CreationDate)
.Skip((query.Page - 1) * query.Take)
.Take(query.Take)
.ToList();
}
}
Widzimy, że mamy jeden parametr wejściowy – bazę danych. Nie mamy tutaj na wejściu serwisów odpowiedzialnych za modyfikacje produktów, przez co czytelność naszej klasy znacznie się zwiększa. Możemy modyfikować pobieranie danych, dodawać klasy pomocnicze, zejść na poziom zapytań SQL – w żaden sposób nie zmieni nam to reszty systemu.
Podsumowanie
Na podstawie powyższego przykładu widać, że nasz kod po wprowadzeniu CQRS jest bardziej jednostkowy – podzielony na klasy. Część osób mogłaby to uznać za wadę, jednak po wielu przygodach z różnymi systemami jednoznacznie uznaję to za zaletę. System pisany w ten sposób jest bardziej zrozumiały i łatwiej utrzymywalny. Możemy w danej klasie posłużyć się takim wzorcem, jakim potrzebujemy, wdrażać potrzebne optymalizacje, co w rezultacie nie rzutuje na resztę systemu.
Część osób powie, że nie ma CQRS bez asynchronicznej szyny wiadomości, więcej niż jednej bazy danych, budowania bazy danych w oparciu o zdarzenia itd. Niestety to błąd. Sam twórca wzorca wielokrotnie podkreślał:

CQRS jest znakomitym wstępem do kolejnych rozwiązań – Domain Events, Event Sourcing, korzystanie z kolejnych baz danych. Te rzeczy są możliwe bez CQRS, ale ten wzorzec świetnie się z nimi integruje. CQRS sam w sobie daje duże możliwości, dlatego odradzałbym go jedynie w systemach, w których mamy 100% pewność, że nie będziemy mieli skomplikowanej logiki biznesowej. W pozostałych przypadkach jestem zwolennikiem używania tego wzorca.
Podobne artykuły

Python podstawy - kursy, tutoriale online - 10 rekomendacji

Data Analytics, Data Science, Machine Learning – co wybrać?

12 wniosków i dobrych praktyk z refaktoryzacji kodu

Nie jesteś przekonany do code review? Oto kilka porad na start
Jak Slack dba o każdego użytkownika? Stosuje accessible technology
6 kroków do przebranżowienia się na programistę. Plan nauki IT

10 rad dla początkujących programistów od seniora
