Budowanie niezawodnego i skalowalnego systemu na przykładzie harmonogramu zadań
Dzisiaj można znaleźć wiele rozwiązań dostarczających kompletny system do automatyzacji zadań działających w tle. Mogą być wbudowane w projekt jak Hangfire, Quartz.NET czy FluentScheduler, chmurowe jak Azure WebJobs czy ostatnio modne rozwiązanie nie wymagających serwerów (ang. serverless) jak Azure Functions i AWS Lambda.

Piotr Czech. .NET Developer w HURO, gdzie buduje systemy oparte o RODO. Poprzednio pracował dla londyńskiej firmy, gdzie budował mobilny system telemetryczny zbierający i przetwarzający dane o nowych kierowcach w celu obniżenia ubezpieczeń, między zadaniami na poprawianie bugów. Entuzjasta podejść architektonicznych w systemach oraz budowania wydajnych rozwiązań opartych o platformę .NET poprzez eksploracje nowych technik oraz uczenia innych… i gonienia ich, jeśli nie przykładają do kodu.
System do automatyzacji zadań, poza takimi aspektami jak harmonogram i obsługa zadań, prosty i intuicyjny interfejs dla programistów czy GUI dla administratorów, powinien spełnić kilka dodatkowych wymagań.
Między innymi system powinien:
- Być idempotentny, czyli wykonać zadanie w każdej aplikacji tak samo z takim samym efektem.
- Cechować się wysoką niezawodnością. System powinien automatycznie wstać, replikować się bez ingerencji człowieka i wykonać ostatnio zlecone zadania przez aplikacje.
- Przetrwać przypadłości IIS, czyli reset IIS’a, recykling puli aplikacji, braku ustawień AlwaysRunning czy zmianami wprowadzonymi przez administratorów.
- Być skalowalny.
- Posiadać system obsługi wszystkich zadań dla wszystkich aplikacji z jednego miejsca.
- Zrównoważyć wykonywanie zadań między aplikacjami (ang. load balancing).
- Być kompatybilny z projektami na SharePoint, IIS, Azure.
Jeśli kiedykolwiek poczujesz, że Twojego problemu nie da się rozwiązać, wyobraź sobie, że ktoś kiedyś wymyślił łatwe i proste w obsłudze narzędzie, które rozwiąże każdy biznesowy problem.
Spis treści
Analiza wymagań
Hangfire’er dla różnych typów baz potrafił wykonać to samo zadanie dwukrotnie (stan na 30.12.2018 r — nierozwiązany błąd w architekturze). Marginalizując fakt utraty zasobów serwerowych, czyli pieniędzy klienta, jak i własnych to co w wypadku zadań, których wykonanie powoduje różne wyniki (czyt. nie są idempotentne)?
Utworzenie dwóch identycznych użytkowników czy przelanie dwukrotnie tej samej sumy pieniędzy NIE wchodzi w grę. Wychodząc z założenia, że rozwiązania powinny być idiotoodporne, czyli nawet jak posiadamy mechanizm transakcji czy klauzuli strażniczej (ang. guard clause) na niższych poziomach abstrakcji to i tak wyższe poziomy również powinny zabezpieczać i posiadać mechanizmy ochronne.
Tylko bez przesady, trzeba równoważyć między systemem, który da się rozwijać a tym, w którym bugi przepraszają, że wystąpiły.
Co do idempotentności, czyli punktu drugiego, system sam w sobie nie decyduje o powodzeniu lub niepowodzeniu wykonanego zadania, tylko o jego uruchomieniu i ukończeniu. Zadanie zawsze powinno się rozpocząć i zakończyć, bez różnicy na to czy system działa czy właśnie padł. Rolą programisty jest zapewnienie odpowiedniej implementacji, która wykona poprawnie kod.
Dlatego drugi i trzeci punkt mają bardzo dużo wspólnego, dobrym przykładem są właśnie rozwiązania nie wymagające serwerów (ang. serverless).
Wysoką niezawodność osiągają poprzez zdjęcie z nas obsługi serwerów, infrastruktury jak i samej implementacji takiego mechanizmu. Naszym zadaniem jest tylko napisanie wycinka kodu, który będzie wykonywany w określonych przez nas warunkach.
Nawet jak napiszemy kod, który powoduje wyrzucanie wyjątków, to sam w sobie mechanizm będzie działał dalej jakby nic się nie zostało, czyli rozpocznie i zakończy zadanie. Po zakończeniu zadania zostawi nam informacje, że coś poszło nie tak. Taką cechę można nazwać układem zamkniętym według teorii sterowania, czyli ciągłym otrzymywaniem informacji zwrotnej.

Jest to bardzo przydatna właściwość w częściach systemu, która jest krytyczna z punktu widzenia całej infrastruktury (steruje systemem), ponieważ jej padnięcie powoduje efekt domina.
Zresztą aplikacje monolityczne należą do grupy, w której efekt domina zbiera żniwo, elementy są ze sobą synchronicznie połączone co powoduje, że nieważne co byśmy zrobili to osiągnięcie dostępności na poziomie 99,99999% czasu będzie graniczyć z cudem.
Sam IIS domyślnie co 29h wykonuje recykling puli aplikacji (jest to najmniejsza liczba pierwsza, która jest większa niż 24 czyli przysłowiową dobę, ponieważ podczas projektowania IIS 6 architekci chcieli wykorzystać wzorzec, który jest zmienny, niepowtarzalny i zarazem nie występuje częściej niż raz dziennie).
Recykling puli aplikacji można porównać do mostu, na którym znajdują się samochody, a sam w sobie mechanizm do nagłego usunięcia z mostu wszystkich samochodów tj. usunięcia danych podręcznych, sesji itd. Zarazem bardziej znany IISRESET (czyt. reset serwera IIS) jest mechanizmem, który buduje drugi most obok pierwszego, czeka, aż wszystkie samochody zjadą (skończą pracę) z pierwszego a następnie burzy go.
Oznacza to, że jeśli nie zadbamy o zapisywanie i zwracanie poprawnego stanu aplikacji może nas czekać pewnego dnia niemiła niespodzianka. W tym wypadku, najlepszym rozwiązaniem będzie całkowite wyeliminowanie pobocznych usług. Tutaj dochodzimy do momentu naszej niezawodności systemu.
Eliminujemy serwery, budujemy jeden mechanizm, najlepiej, który sam się replikuje, jak padnie to sam wstanie. Jako, że musi być skalowalny to musimy zadbać, aby każda aplikacja otrzymała swoją część tortu i najważniejsze, musi wspierać trzy różne rodzaje infrastruktur, które bazują na IIS tj. SharePoint, Azure i czystym IIS.
Do tego celu posłuży nam mechanizm nazwany klastrowaniem (czyt. grupowaniem).
Klastry można podzielić według trzech zastosowań tj:
- klaster wydajnościowy — łączymy ze sobą wiele komputerów, aby zwiększyć moc obliczeniową.
- klaster niezawodnościowy — w momencie padnięcia węzła, inny węzeł przejmie jego zadania.
- klaster równoważenia obciążenia — problem można rozbić na wiele małych problemów, które rozwiązują osobne węzły i “składają” te małe rozwiązania w pełne rozwiązanie.
W naszym wypadku wykorzystamy drugą i trzecią właściwość. Klaster niezawodnościowy posłuży nam jako replikacja węzłów (w naszym wypadku po prostu instancji harmonogramu zadań) oraz miejsca, z którego będą brane zadania, na przykład bazy danych, z której w momencie padnięcia usługi będzie można odczytać aktualny stan, od którego ma rozpocząć pracę.
Klaster równoważenia obciążenia posłuży do wykonywania zadań, które są zapisane w bazie danych. Rozdzieli zadania per aplikacje oraz zadba o mechanizm równoległego dostępu do bazy danych.
Warto pamiętać, że w większości przypadków budujemy aplikacje biznesowe, więc częstym wyborem są bazy w oparciu o SQL, które ze względu na swoją budowę ciężko “zrównoleglić”, dlatego stosuje się rozwiązania oparte o semafory czy monitory. Nie ułatwia tego sam mechanizm transakcyjność.
Takie zabawy można skrócić do jednego stwierdzenia.

Dlaczego Quartz.NET?
Sam w sobie Quartz.NET jest .NETową implemetacją java’owej wersji, w której klastrowanie jest zaimplementowane. Rozwiązuje to z miejsca wymagania związane ze skalowalnością i load balancing’iem.
Za brak niezawodność w tym wypadku odpowiedzialny jest IIS, a dokładnie recykling puli aplikacji, w momencie tej czynności instancja quartza zostaje usunięta. Trzeba ją replikować za każdym razem, a w tym konkretnym wypadku wykorzystać prosty singleton. Quartz jest w stanie działać jako osobna aplikacja, jednak dodatkowo może działać na zasadzie symbiozy
Oznacza to tyle, że współpracuje z aplikacją poprzez pobieranie jej zasobów co pozwala jej wykonać pracę, którą zleci mu aplikacja. Zarazem aplikacja chroni quartza przed światem zewnętrznym tj. IISem czy systemem operacyjnym. Jest to bardzo potężna właściwość z punktu widzenia bezpieczeństwa, ponieważ informacje szczególnie wrażliwe nie wypływają poza obręb aplikacji, więc takie zagadnienia jak CORS, OAuth 2.0, OIDC czy Identity Provider nie są potrzebne na tym poziomie.
Musimy jednak pamiętać o fakcie, że w momencie, gdy uzależniamy system od aplikacji to padnięcie aplikacji oznacza padnięcie systemu. W moim wypadku akurat to była świadoma decyzja, ponieważ zadania nie mają sensu bez aplikacji, więc jej padnięcie nie zmieniłoby nic z zadaniami. W innym wypadku trzeba byłoby rozważyć mikroserwisy oraz zagadnienia związane z bezpieczeństwem wymienione powyżej.
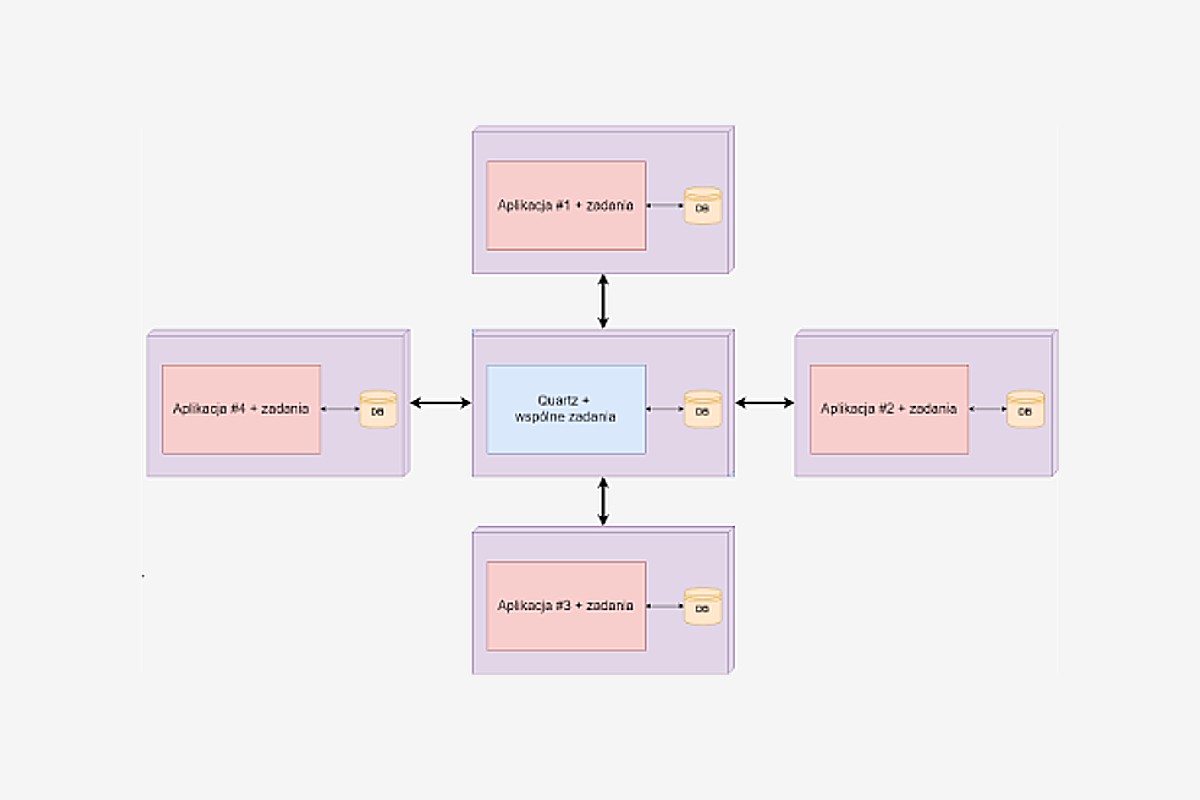
Szkic rozwiązania

To co widać na obrazku jest prostym przykładem klastrowania, jedna biblioteka (tj. Quartz) udostępnia API oraz wspólne zadania, a sama aplikacja jest odpowiedzialna za rejestracje oraz uruchomienie harmonogramu zadań według własnych wytycznych.
Trzeba zwrócić uwagę na to, że harmonogram jest unikalny dla każdej aplikacji, więc w momencie, gdy padnie aplikacja nr. 1 nie wpłynie to na resztę, zarazem pomoże wstać tej aplikacji i podłączyć się pod system na nowo, to jest właśnie siła klastrowania.
Quartz ma bezpośredni dostęp do swojej bazy, w której trzyma zadania dla wszystkich aplikacji i swoim API udostępnia innym aplikacjom manewrowanie po niej. Pośredni dostęp do bazy aplikacji mają zadania, które jako programiści implementujemy.
Klastrowanie niesie za sobą duże zyski, jednak musimy pamiętać również o ograniczeniach, a w tym wypadku jest nią sama baza a dokładniej jej skalowalność.
Używanie klastrowania w wypadku quartza jest zalecane do 3 aplikacji per pulę aplikacji, dlatego jeśli chcemy grupować zadania to najlepiej te czasochłonne, ponieważ synchronizacja krótkich zadań zabije każdą relacyjną bazę danych. Najkosztowniejsze w tym wszystkim jest stworzenie połączenia z bazą danych a potem synchronizacja odczytu.
Sama w sobie baza quartza nie przetrzymuje danych, których nie da się odtworzyć, każda aplikacja jest w stanie odtworzyć stan swoich zadań, tylko w tym wypadku poświęcając poprzedni stan (np. przez uszkodzenie bazy danych lub jej utratę), przykładem takiej implementacji jest przetrzymywanie danych jako zasób RAM’u.
Jednak jeśli ktoś potrzebuje również wysokiej niezawodności bazy danych to quartz udostępnia zdalne połączenia z bazą danych. Dzięki temu implementacja teorii CAP (lub inaczej teorii Brewer’a) jest możliwa.
Można pójść nawet o krok dalej i wykorzystać mikroserwisy. Przy implementacji rozwiązania opartego o chmurę obliczeniową możemy wykorzystać na przykład Azure Service Fabric, który pozwoli nam skalować ilość instancji danej aplikacji, utrzymywać jej wysoką niezawodność i skalować bazę danych quartza według teorii CAP przy wykorzystaniu Redis’a lub innego podobnego rozwiązania.
Jednak patrząc przez pryzmat, tego, że mamy gotowe rozwiązania jak AWS Lambda lub Azure Functions jest to sztuka dla sztuki.
Jeśli naszym zadaniem jest wykonywanie dużych ilości krótkich zadań (np. 100k/h) to w takim wypadku trzeba będzie poświęcić wspólne GUI, klastrowanie i bazę przenieść jako zasób RAMu. Java’owa implementacja posiada płatne rozwiązanie jakim jest Terracotta, które rozwiązuje ten problem.
Rozwiązanie oparte o RAM jest ponad 1000x szybsze niż tradycyjna baza, jedynie co nas ogranicza to moc obliczeniowa naszego serwera(czyt. CPU).
Budowanie rozwiązania
Wykorzystałem .NET Standard jako podstawę przy budowie biblioteki quartza oraz dwie aplikacje webowe do demonstracji, kolejno dla .NET Core i .NET Framework. Za GUI posłużyła biblioteka CrystalQuartz. Sama w sobie biblioteka zawiera konfigurację oraz wspólne zadania. Konfiguracja zawiera w sobie API, które będziemy udostępniać aplikacjom, na przykład instancje harmonogramu. Zarazem konfiguracja posiada klasę definiującą kształt zadania oraz mechanizm do łapania wyjątków, który jest nam potrzebny, aby zaimplementować klaster niezawodnościowy.
Najważniejsze w tym wszystkim są ustawienia serwera (czyt. instancji harmonogramu):
["quartz.scheduler.instanceName"] = "Task Runner Server", ["quartz.scheduler.instanceId"] = "AUTO", ["quartz.serializer.type"] = "json", ["quartz.threadPool.type"] = "Quartz.Simpl.SimpleThreadPool, Quartz", ["quartz.threadPool.threadCount"] = "10", ["quartz.threadPool.threadPriority"] = "Normal", ["quartz.jobStore.clustered"] = "true", ["quartz.jobStore.misfireThreshold"] = "60000", ["quartz.jobStore.driverDelegateType"] = "Quartz.Impl.AdoJobStore.SqlServerDelegate, Quartz", ["quartz.jobStore.type"] = "Quartz.Impl.AdoJobStore.JobStoreTX, Quartz", ["quartz.jobStore.useProperties"] = "true", ["quartz.jobStore.tablePrefix"] = "QRTZ_", ["quartz.jobStore.dataSource"] = "default", ["quartz.jobStore.lockHandler.type"] = "Quartz.Impl.AdoJobStore.UpdateLockRowSemaphore, Quartz", ["quartz.dataSource.default.connectionString"] = ConfigurationManager.ConnectionStrings["Quartz"].ConnectionString, ["quartz.dataSource.default.provider"] = "SqlServer"
Jeśli chcemy używać klastrowania to instanceId powinno być unikalne dla aplikacji, więc najprościej ustawić pole typu AUTO. Pula wątków decyduje, ile mamy mieć równocześnie wykonywanych zadań oraz jaki priorytet mają one mieć na tle całej aplikacji.
MisfireThreshold definiuje po jakim czasie system ma uznać, że zadanie nie zostało uruchomione. Dzieje się tak, gdy mamy przeciążone wątki i nie jest w stanie wykonać następnych zadań lub gdy system padł. Pozwala to uruchomić zadania natychmiast po ustaniu problemu.

DriverDelegateType definiuje typ sterowników jakie ma wykorzystać podczas operacji na bazie danych, wykorzystywanie sterowników napisanych pod daną bazę przyspiesza ogólną wydajność całego systemu. JobStore.Type definiuje jaki system interakcji z bazą danych będziemy wykorzystywać, w tym wypadku ADO.NET.
DataSource definiuje po jakim kluczu ma szukać ustawień w celu połączenia się z bazą danych (czyt. connectionString) czy określić dostawcę (czyt. provider’a). LockHandler.Type definiuje jakiego typu zrównoleglenia będziemy korzystać, aby synchronizować dostęp do bazy danych, w tym wypadku semafor.
Ostatnim elementem jest klasa abstrakcyjna, dzięki której będziemy implementować zadania.
public abstract class JobBase : IJob
{
public abstract Task PreExecute(IJobExecutionContext context);
public async Task Execute(IJobExecutionContext context)
{
try
{
await PreExecute(context).ConfigureAwait(false);
}
catch (Exception e)
{
Debug.WriteLine(e);
}
}
}
Stworzyłem dodatkową abstrakcję, chociaż mógłbym od razu pisać zadania poprzez implementacje interfejsu IJob. Takie podejście ma na celu nie dopuścić, aby w przypadku porażki, wyrzucenia wyjątku system był w stanie działać dalej, dlatego każda klasa, która będzie dziedziczyć po JobBase będzie musiała zaimplementować metodę PreExecute.
Pozwala to sterować zadaniami i zbierać użyteczne informacje (pamiętasz o teorii sterowania?) zarazem usuwając z samych zadań powtarzający się kod.
Podsumowanie
Mam nadzieję, że nawet jak nie będziesz potrzebował takiego rozwiązania to dałem Ci jakąś wartość, na przykład na temat budowania rozproszonych rozwiązań i ich bolączek. Jeśli będziesz chciał przetestować moje rozwiązanie to demonstracyjny projekt znajdziesz na moim github’ie, na który oczywiście zapraszam. W razie jakichkolwiek pytań, pisz śmiało. A tymczasem, do następnego!
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
