Azure Search. Jak stworzyć zaawansowaną wyszukiwarkę w kilku krokach (cz.1)

Wyszukiwarki to stały element większości stron internetowych. W nagłówku każdej strony widnieje pole „Wyszukaj”. Wydawać by się mogło, że skoro jest to wszędzie – jest to bardzo proste do zrobienia. Jeżeli tworzymy to sami – nic bardziej mylnego. Jeżeli korzystamy z gotowych rozwiązań, takich jak Azure Search – to prawda.

Kacper Świsłocki. .NET Developer w białostockiej firmie Elastic Cloud Solutions. Młody programista, początkujący prelegent. Występował m.in. podczas wydarzenia Śląska Grupa Microsoft Meetup, gdzie opowiadał o tym, jak stworzyć zaawansowaną wyszukiwarkę za pomocą Azure Search.
Przykładowy scenariusz: chcemy zrobić przeglądarkę, która będzie umożliwiała podpowiadanie, wyszukiwanie po kilku polach, filtrowanie, wypisywanie wyników nawet, gdy użytkownik popełni dany błąd. Mogłaby też przeszukiwać pliki tekstowe i zdjęcia. Pisząc to samodzielnie zajęłoby to nam bardzo dużo czasu. Należałoby implementować algorytmy, liczyć wyniki dla zwracanych rekordów, aby je posortować, itd. Napocilibyśmy się dość mocno. Z pomocą przychodzi nam Azure i usługa Search. Zapewnia on nam wszystkie wyżej wymienione funkcjonalności (a to nie wszystko co ma do zaoferowania). W artykule pokażę, jak stworzyć przeglądarkę, opiszę problemy i przedstawię ciekawe przypadki wykorzystania Searcha.

Jedyne co musimy zrobić, aby stworzyć taką zaawansowaną wyszukiwarkę, to stworzyć usługę, przekazać jej dane, na których ma przebiegać wyszukiwanie oraz odpowiednio ją skonfigurować. Azure Search tworzy na danych indeks, który odpowiednio konfigurujemy – definiujemy, po których kolumnach ma być realizowane wyszukiwanie, które mogą być filtrowane, itd. Więcej o tym będzie w dalszej części artykułu.
No to zaczynamy. Tworzymy usługę na Searcha na portalu. Należy wybrać darmową wersję, która na potrzeby zapoznania się z nią jest w pełni wystarczająca.
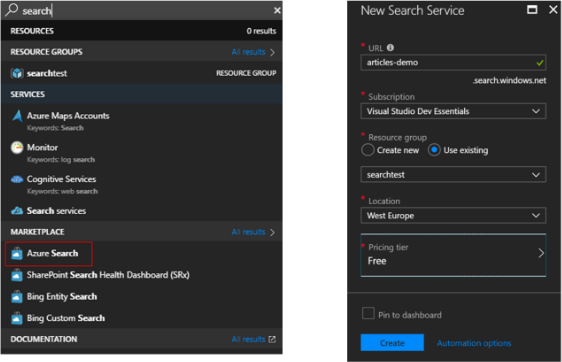
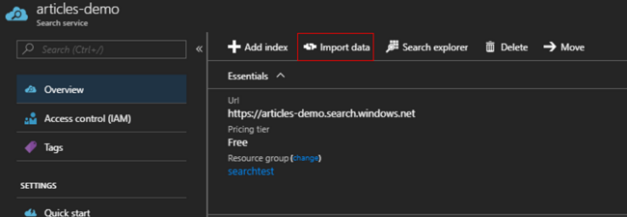
Możemy teraz stworzyć nasze źródło danych. Klikamy przycisk „import data” i przechodzimy przez wszystkie kroki, jak poniżej. Na potrzeby artykułu wykorzystamy zwykłą bazę SQL. Myślę, że ta wersja jest najlepsza, aby zrozumieć zależności, jakie występują w usłudze.
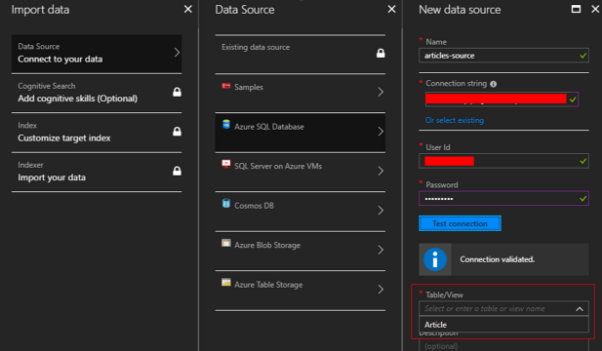
Wybieramy nasze źródło danych — wpisujemy connection string do naszej bazy oraz logujemy się. Po kliknięciu przycisku test connection – o ile autoryzacja przebiegła pomyślnie, pojawi się lista rozwijana, w której będziemy mogli wybrać tabelę (lub widok) źródłową. Klikamy ok i przechodzimy dalej.
Kolejnym krokiem będzie zdefiniowanie naszego indeksu. Wszystkie pola z bazy danych zostaną zrzutowane na odpowiednie typy udostępniane przez Searcha. Tylko pole Id zawsze będzie stringiem. Taki jest wymóg tej usługi. Na potrzeby artykułu stworzyłem bazę danych z jedną tabelą – artykuł zawierający dwa pola — tytuł i zawartość.
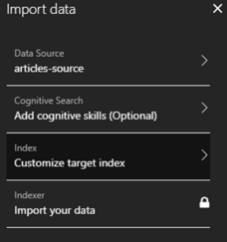
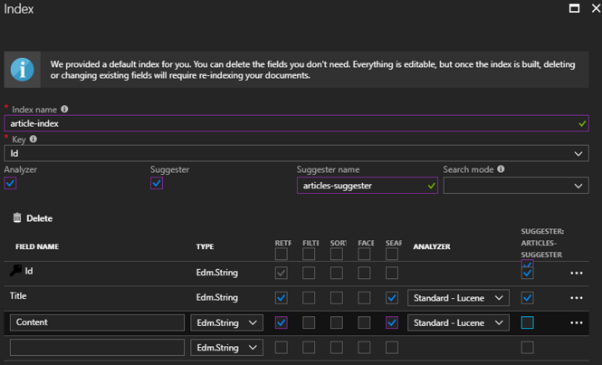
Możemy teraz wybrać, które pola będą przeszukiwane, które filtrowane, itd.
We wstępie pisałem o możliwości podpowiadania. Tą funkcjonalność tworzy się również w tym kroku. Wybieramy pole suggester a następnie zaznaczamy pole, po którym ma przebiegać wyszukiwanie podczas wpisywania frazy w wyszukiwarkę. Klikamy ok i przechodzimy dalej.
Jakiś czas temu dodano do usługi cognitive serach. Jest ogromne narzędzie, jeśli chodzi o przeszukiwanie, zwłaszcza plików. Zwraca ono w kolumnie specyficzne dane, jak dane osobowe znajdujące się w danym rekordzie, lokalizacje, itd. Pozwala również na przeszukiwanie zawartości zdjęć. Ale o tym później. Na razie przejdźmy przez tworzenie usługi najmniejszą linią oporu. Pomijamy tę opcję.
Ostatnim krokiem jest stworzenie indeksera, czyli narzędzia, które będzie ściągać dane z bazy do naszego indeksu. Możemy go uruchamiać ręcznie, lub ustawić mu czas uruchamiania raz na dany okres. Ja preferuję uruchamianie ręczne. Mamy wtedy większą kontrolę nad tym, co dzieje się w naszym indeksie.
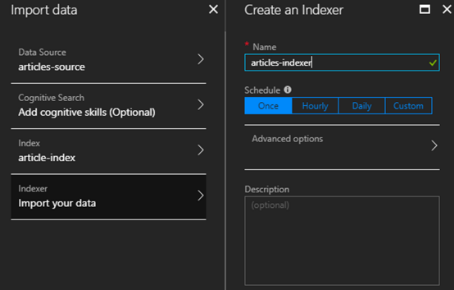
Klikamy ok i mamy skonfigurowaną usługę. Nic tylko pisać zapytania. Na początek dobrym narzędziem jest Search Explorer znajdujący się na portalu.
Popiszemy teraz jakieś przykładowe zapytania.
W mojej bazie w tym momencie znajdują się tylko dwa artykuły. Mają takie same zawartości i inne tytuły. Poszukamy „new article”.
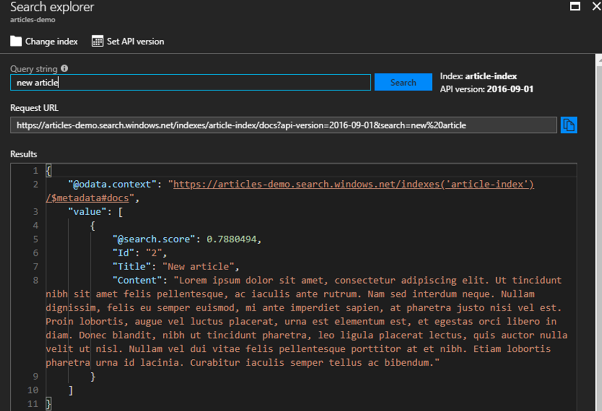
Wynikiem zapytania jest artykuł, którego szukaliśmy. W wyniku zwracany jest @search.score, który określa, jak rekord jest dopasowany do naszego zapytania. Wyniki domyślnie są sortowane właśnie po tym atrybucie. Kolejne dane to id, tytuł i zawartość.
W kolejnym zapytaniu wykorzystamy atrybut count. Zwraca on ilość wyników pasujących do zapytania. Nie będziemy wpisywać żadnej frazy. W takim przypadku zapytaniem jest SELECT *. Zwrócone są dwa wyniki, czyli wszystko co jest obecnie w bazie.
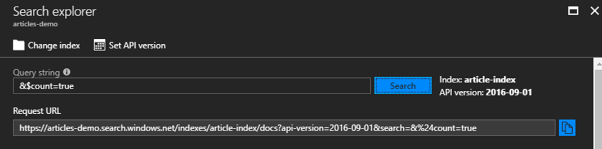

Wyszukiwanie przebiega teraz po dwóch atrybutach (tytuł i zawartość artykułu). Myślę, że tytuł jest ważniejszy od zawartości artykułu, więc odnajdywane frazy w tytule powinny być ważniejsze od tych znalezionych w zawartości artykułu. Zwracanie wyników opiera się na scoringu. To znaczy, że jeżeli dana fraza wystąpi w zawartości artykułu dwa razy, a w tytule raz, to wynik, gdzie wystąpiło to dwa razy będzie wyżej. Aby nad tym zapanować należy skorzystać ze scoring profile. Możemy tutaj stworzyć profil wyszukiwania, z którego będziemy korzystać. Dodajemy go i nadajemy wagi odpowiednim polom.

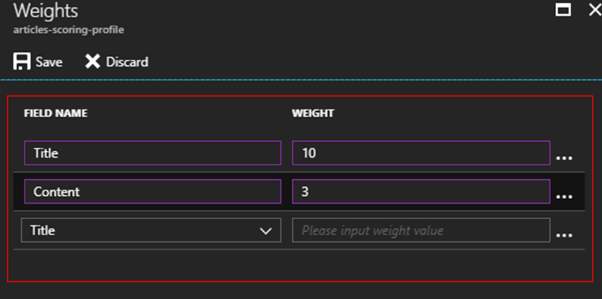
Teraz wyniki z tytułu są ważniejsze niż te z zawartości. Dodam jeszcze artykuł z innym tytułem i zawartością „lorem ipsum” wypisane kilka razy, oraz tytułem „lorem ipsum” i inną zawartością. Ponadto, aby wyniki były wrzucone do indeksu, należy uruchomić indekser. W sekcji indexers wybieramy nasz indekser i klikamy Run.
Przejdźmy do search explorera, aby to zweryfikować.
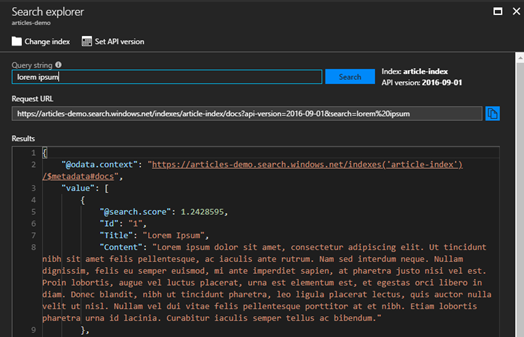
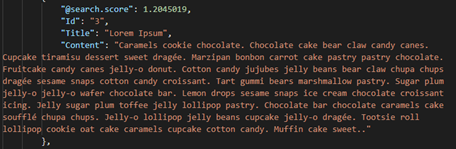

Należy zwrócić uwagę na score. W stworzonym przeze mnie scoring profilu odnalezienie frazy w tytule ma wagę 10, a w treści 3. Wyniki są zgodne ze stworzonym scoringiem.
Pozostaje jeszcze jeden problem. We wstępie potrzebowaliśmy wyszukiwać frazy podobne do tych, czyli nawet gdy użytkownik nieznacznie się pomyli, powinien otrzymać wyniki. To leży po stronie pisania zapytania. Poniżej pokażę przykład takiego zapytania.

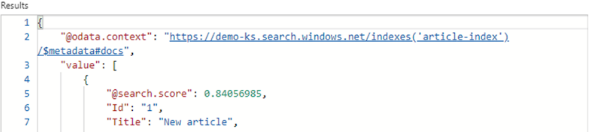
“~1” na końcu słowa oznacza, że szukany wyraz może się różnić jedną literą. Jak widać wyszukiwarka zwróciła dane.
No i już. Ile to nam zajęło? Pół godziny? Może nawet mniej. Implementując to od zera walczyli byśmy z tym bardzo długo. Tutaj mamy wszystko z pudełka.
Podsumowanie
Przeszliśmy przez podstawową konfigurację przez wyklinanie wszystkiego. Ale co jeżeli będzie trzeba stworzyć takich usług więcej, np. dla wielu klientów? Klikając można się łatwo pomylić, nie zaznaczając któregoś z pól, itp. Co jeżeli dane, których potrzebujemy znajdują się w kilku źródłach?
Podobne artykuły

Krytyczne spojrzenie na kod jest kluczowy dla jego skutecznej analizy. Jak analizować systemy legacy

Sieci neuronowe. PyTorch i praktyczny projekt od początku do końca

Od czego zacząć swoją przygodę w branży IT? Rozmowa z Jackiem Hrynczyszynem, Java Developerem

Kim jest Software Architect? Obowiązki, specjalizacje, kariera

Co nowego w Javie? Przegląd zmian, które przyniosło JDK 20

Efektywne zarządzanie Protocoll Buffers z “Buf”. Wszystko, co powinieneś wiedzieć

Czy Scala to wciąż dobry język dla programistów w 2023 roku?
