Jak do analizy sentymentu tweetów wykorzystaliśmy uczenie maszynowe

Rozprzestrzenianie się informacji staje się ostatnio coraz szybsze. W średniowieczu wiadomość o zmianie władcy potrzebowała zapewne kilku lat by dotrzeć do wszystkich poddanych, a teraz najważniejsze wydarzenia możemy obserwować niemal na żywo na ekranach naszych telefonów. Skoro więc dowolna informacja może okrążyć glob w zaledwie kilka sekund, to istotnym z punktu widzenia każdej firmy zdaje się być ciągłe monitorowanie tego, co publikują na jej temat klienci.

Kacper Łukawski. Data Engineer/Tech Lead w Codete od 2013 roku. Aktualnie zaangażowany głównie w projekty z zakresu Big Data i wewnętrzne projekty badawcze w dziedzinie uczenia maszynowego. Entuzjasta stosowania metod związanych z „data science” w różnych branżach. Jeden z autorów firmowego bloga Codete.
Wielu wpadek wizerunkowych udałoby się uniknąć, gdyby w porę udało się rozpoznać kryzysy zaufania i odpowiednio na nie reagować. Dlatego monitorowanie wszelkich treści pojawiających się w mediach społecznościowych na nasz temat, szczególnie negatywnych, wydaje się być kluczowym narzędziem do szybkiego reagowania w przypadku wpadki.
Spis treści
Czym jest analiza sentymentu?
Jako ludzie mamy pewnego rodzaju zdolność do rozpoznawania cudzych emocji na podstawie treści wypowiadanych słów, a także pewnych czynników pozawerbalnych, jak ton głosu czy ogólna ekspresja ciała. Większość z nas potrafi również trafnie rozpoznać ironię. W przypadku treści publikowanych w mediach społecznościowych paleta dostępnych czynników, które możemy wziąć pod uwagę w procesie nazywania uczuć autora, ogranicza się głównie do opublikowanej treści, gdyż w sposób oczywisty nie mamy dostępu do jego stanu emocjonalnego w czasie tworzenie danego wpisu. W takim wypadku rozpoznawanie emocji wydaje się być procesem dość karkołomnym, nawet dla człowieka.
Ograniczając jednak nasze zainteresowanie do prostszego problemu, tj. rozpoznania jedynie ogólnego stosunku autora do opisanej treści, a nie konkretnej emocji, możemy starać się taki proces zautomatyzować — tym właśnie zajmuje się analiza sentymentu. Z jej pomocą możemy określić czy dana treść jest pozytywna, negatywna czy neutralna i jest to bardzo dobrze znany problem, którym zajmuje się gałąź uczenia maszynowego zwana przetwarzaniem języka naturalnego (ang. natural language processing, NLP). Przejdziemy przez cały proces tworzenia systemu sztucznej inteligencji, którego celem będzie określenie sentymentu danego tekstu dla języka angielskiego.
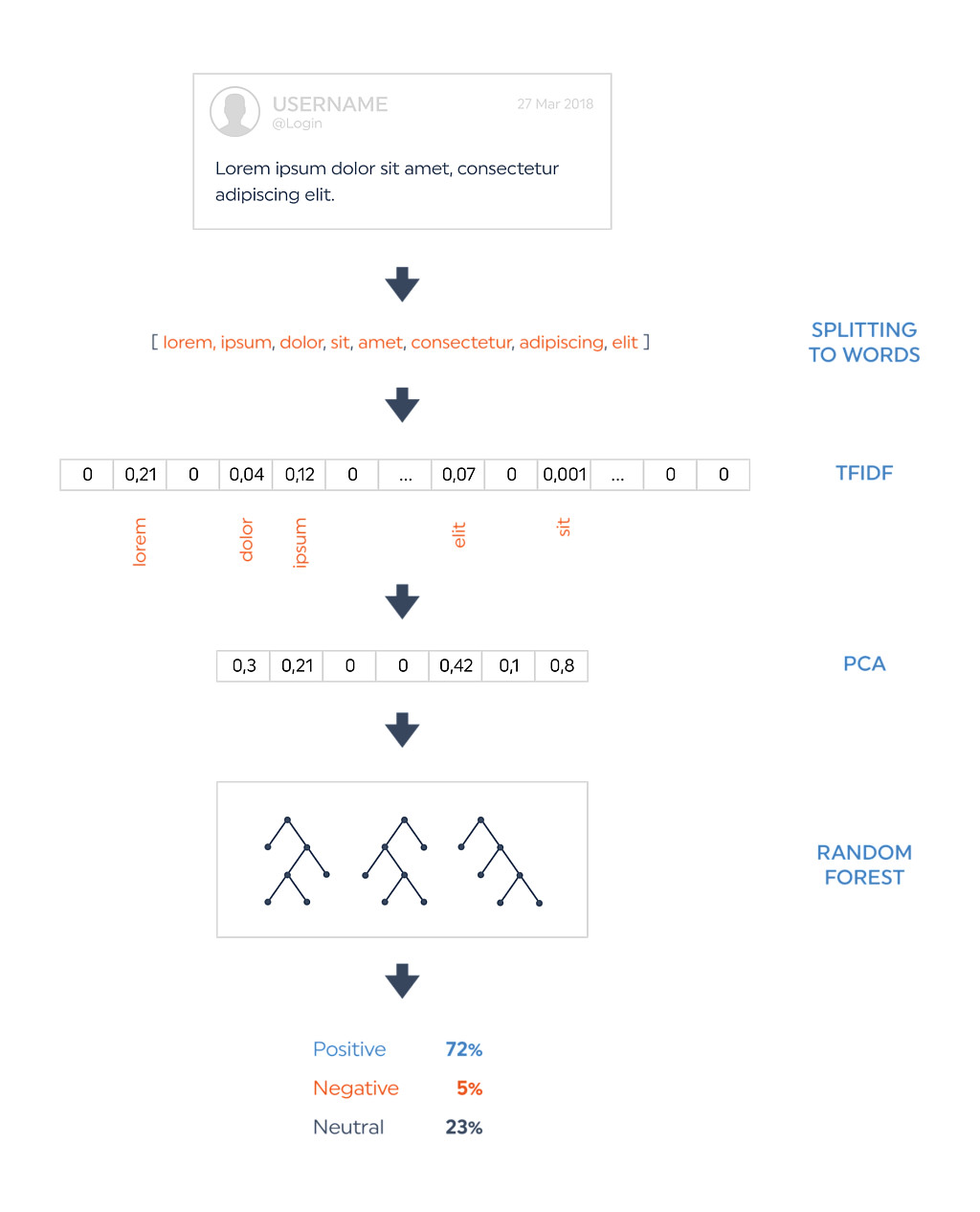
W przypadku naszego eksperymentu skupiliśmy się na monitorowaniu tweetów, ponieważ API Twittera pozwala na otrzymywanie treści powiązanych z żądaną frazą wejściową w czasie niemal rzeczywistym. Ponadto jego użytkownicy w krótkich wiadomościach dzielą się ze sobą informacjami i rozprzestrzeniają je dalej, co idealnie pasuje do naszego celu — monitorowania na bieżąco wpisów na temat wybranego hasła.
Przejście od tekstu do sentymentu
Zautomatyzujemy opisany wyżej proces poprzez system uczenia maszynowego, który uczy się z dostarczonych mu przykładów, dla których sentyment został już określony, i próbuje znaleźć metodę przypisania etykiet podanym obserwacjom — w naszym przypadku szukamy funkcji, która dla zadanego tekstu określi nam jego sentyment. W ostatnich latach obserwujemy gwałtowny wzrost wykorzystania emoji, które zdają się być niczym innym jak tylko bezpośrednimi wyznacznikami emocji autora. W naszym procesie będziemy więc zwracać baczną uwagę na ich wykorzystanie, podobnie jak ludzie zwracają uwagę na czynniki pozawerbalne towarzyszące wypowiedzi.
Ponieważ modele sztucznej inteligencji są modelami matematycznymi, dlatego jako wejście nie podajemy im czystego tekstu, a pewnego rodzaju postać numeryczną — najczęściej wektory. Proces zamiany tekstu na wektory nazywamy wektoryzacją. Dla naszych potrzeb skorzystaliśmy z popularnej metody, którą jest wektoryzacja TFIDF. W skrócie: dzieli ona podany tekst na słowa i każdemu słowu przypisuje numeryczną wagę w zależności od jego istotności dla całego tekstu. Dodatkowo rozszerzyliśmy tę metodę o dodanie kilku cech, które uznaliśmy za istotne, takich jak długość tekstu czy wykorzystanie znaków specjalnych, np. wykrzykników czy znaków wielokropka. Warto nadmienić, iż emoji zostały na początku zamienione na ich tekstowe odpowiedniki, aby były traktowane na równi ze słowami. W procesie testowania naszych modeli sprawdziliśmy także inne metody wektoryzacji, takie jak zliczanie wystąpień każdego ze słów, a także wyciągania jedynie wspomnianych cech dodatkowych, ale wyniki pokazały, że poszerzona metoda TFIDF uzyskuje największą poprawność.
Na potrzeby treningu zebraliśmy razem publicznie dostępne zbiory tweetów, które mają już przypisany sentyment. Łącznie udało się zgromadzić niemal 1,6 mln wpisów, co wydaje się być ilością wystarczającą do stworzenia naszego modelu, jednakże w przypadku systemów sztucznej inteligencji ciężko jest wskazać ilość danych jaka będzie wystarczająca do jego nauczenia i trzeba zdać się na pewnego rodzaju intuicję. W naszym teście okazało się, że ilość unikatowych słów użytych we wszystkich wiadomościach przekracza 250 tys. To oznacza, że każdy tekst zostałby zamieniony w matematyczny wektor o długości przekraczającej 250 000. To sporo za dużo i może powodować znaczące problemy z wydajnością. Istnieją jednak metody, takie jak PCA, które pozwalają na ograniczenie wymiarowości danych.
Skorzystaliśmy z tej możliwości i okazało się, iż użycie wektorów o długości 500 tylko nieznacznie zmniejsza skuteczność naszego modelu, a znacząco przyspiesza jego działanie. W trakcie eksperymentów porównywaliśmy kilka różnych architektur uczenia maszynowego, m.in. regresję logistyczną, k-neighbours, SVM, Adaboost czy sieci neuronowe. Najlepszą architekturą okazał się jednak tzw. Random Forest Classifier, ponieważ oferował najlepszą precyzję wśród tych metod, które można wykorzystywać produkcyjne ze względu na prędkość działania.
Przewaga nad narzędziami dostępnymi na rynku
Biblioteka CoreNLP, tworzona przez Uniwersytet Stanforda, jest przez wielu uważana za punkt odniesienia, jeśli chodzi o algorytmy przetwarzania języka naturalnego. Dostarcza ona już nauczonych metod rozwiązujących popularne problemy NLP i używając jej zasadniczo pomija się etap nauczania — możliwości doboru parametrów są przez to również ograniczone niemal do minimum. Początkowo planowaliśmy wykorzystać ją w naszym narzędziu do monitorowania treści, ale na testowym zbiorze danych osiągnęła precyzję rzędu 50%, co było znacząco poniżej oczekiwań. Narzędzie Stanford’a było projektowane do pracy z dłuższymi i poprawnymi gramatycznie tekstami, a Twitter sam narzuca ograniczenie długości pojedynczego wpisu. Dodatkowo jego użytkownicy rzadko dbają o poprawność językową, a co za tym idzie użyteczność CoreNLP drastycznie spada. Jeśli chodzi o systemy uczenia maszynowego, to ciągle mamy do czynienia z tzw. słabą sztuczną inteligencją, która jest projektowana pod pewne specyficzne zadania. Również w naszym przypadku ciężko jest oczekiwać, że biblioteka rozwiąże problemy, do których nie została zaprojektowana. Dlatego też zdecydowaliśmy się stworzyć własne rozwiązanie dostosowane do naszych potrzeb.
Opisana metoda osiąga precyzję rzędu 75% na tym samym zbiorze danych, na którym testowaliśmy CoreNLP. W Codete stworzyliśmy narzędzie pozwalające na wprowadzenie dowolnej frazy wejściowej, która ma być monitorowana na Twitterze i na późniejszą wizualizację ogólnego, zbiorczego sentymentu dla wszystkich pasujących wiadomości. Narzędzie to można także wykorzystać do monitorowania tweetów dotyczących danej marki. Na tym wideo widać jak aplikacja ta wygląda w praktyce.
Podsumowanie
Opisana metoda wciąż nie jest idealnym systemem rozwiązującym problem analizy sentymentu i staramy się ją ciągle rozwijać. Podstawowym problemem jest tutaj dostarczenie treningowego zbioru danych o wysokiej jakości i w tym obszarze staramy się szukać konkretnych usprawnień. Dodatkowo wstępne poprawienie danych w celu zmniejszenia liczby błędów gramatycznych wydaje się być dobrym kierunkiem zważywszy na charakter danych.
Zdjęcie główne artykułu pochodzi z picjumbo.com
Podobne artykuły

Rok w startupie, to jak trzy lata w tradycyjnej firmie. Wywiad z Mateuszem Gostańskim

Kultura pracy zdalnej. Czym jest, jak ją zbudować i czy w ogóle warto?

W jaki sposób za pomocą UX i UI zwiększyć efektywność i zredukować koszty rozwoju oprogramowania

Wymień Husky na Lefthook i wejdź na nowy poziom znajomości Git Hooków

Modelarz vs. programista. Która profesja jest kluczem do sukcesu w świecie AI?

Nie odpowiadaj za błędy własnym majątkiem, czyli krok po kroku do zabezpieczenia swojej pracy

Dowiedz się, jak polska firma wspiera naukowców w poszukiwaniu alternatywnych źródeł energii
